簡介:對於維護數據的一致性和完整性而言,有效並且健壯的事務策略至關重要。API Layer 事務策 略易於實現,並且非常適合用於大部分業務應用程序。 事務策略 系列文章的作者 Mark Richards 借助 Enterprise JavaBeans (EJB) 3.0 規范的示例,解釋了事務策略的含義,以及如何在 Java™ 平台 上實現它。
不論您是在 EJB 2.1 或 3.0 中使用容器環境,還是使用 Spring Framework 環境, 或者是 Tomcat 和 Jetty 等帶有 Java Open Transaction Manager (JOTM) 的 Web 容器環境,都需要一 種事務策略來確保數據庫的一致性和完整性。Java Transaction API (JTA) 指定了與事務處理有關的語 法和接口,但是並沒有描述如何將這些構建塊組合起來。正如建築工人需要根據一張設計圖來將一堆木材 建造成一棟房子一樣,您需要一種策略來描述如何 將事務構建塊組合在一起。
關於本系列
事務可以改善數據的質量、完整性和一致性,並使您的應用程序更加健壯。在 Java 應用程序中實現 成功的事務處理並非易事,它涉及到設計和編碼。在這個 系列文章 中,Mark Richards 將指導您為從簡 單應用程序到高性能事務處理等各種用例設計有效的事務策略。
我將在本文介紹的策略名為 API Layer 事務策略。它是最健壯、最簡單並且是最容易實現的事務策略 。但是其簡單性也帶來了一些限制和一些需要考慮的因素,我將對此加以解釋。我在代碼示例中使用 EJB 3.0 規范;同樣的概念也適用於 Spring Framework 和 JOTM。
基本結構
API Layer 事務策略的命名基於這樣一個事實:所有事務邏輯包含在邏輯應用程序架構的 API 層。這 個層是一個邏輯層 — 有時也被稱為應用程序的域層(domain layer)或 facade 層,它以公共方法或接 口的形式向客戶機(或表示層)公開功能。之所以說是邏輯 層,是因為可以從本地訪問域層(通過直接 實例化和調用),或通過 HTTP、遠程方法調用(RMI)、通過 EJB 使用 RMI over Internet Inter-Orb Protocol (RMI-IIOP),甚至通過 Java Message Service (JMS) 進行遠程訪問。
圖 1 展示了大多數 Java 應用程序的典型邏輯應用程序層堆棧:
圖 1. 架構層和事務邏輯
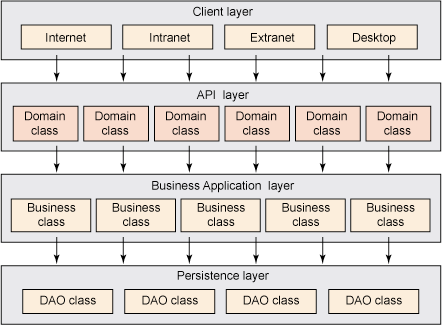
圖 1 中的架構實現了 API Layer 事務策略。包含事務邏輯的類使用紅色背景表示。注意,這些只包 含應用程序架構的域類(API 層)。客戶機層、業務層和表示層沒有包含事務邏輯,意味著這些層並不能 開始、提交或回滾事務,也不會包含事務注釋,比如 EJB 3.0 中的 @TransactionAttribute 注釋。整個 應用程序架構中用於啟動、提交和回滾事務的惟一方法就是 API 層的域類中包含的公共方法。這就解釋 了為什麼 API 層是最健壯、最簡單的事務策略。
不要局限在圖 1 所示的 4 個層上。應用程序架構可以包含更多的層,也可能包含比這更少的層。可 以將表示層和域層結合放到單個 WAR 文件中,或將域類單獨放到一個 EAR 文件中。您可能將域類中包含 的業務邏輯作為一個層,而不是兩個。這都不會影響事務策略的工作方式或實現方式。
這個事務策略非常適合擁有粗粒度 API 層的應用程序。並且由於表示層並未包含任何事務邏輯(甚至 更新請求),因此此策略非常適合那些必須支持多客戶機通道的應用程序,包括 Web 服務客戶機、桌面 客戶機和遠程客戶機。但是這種靈活性需要付出一定代價 — 即客戶機層僅限於對給定事務工作單元的單 一請求。我將在本文後面解釋這一限制的必要性。
策略設置和特征
以下規則和特征將應用到 API Layer 事務策略:
只有包含在應用程序架構的 API 層中的公共方法包含事務邏輯。其他方法、類或組件都不應包含事務 邏輯(包括事務注釋、編程式事務邏輯和回滾邏輯)。
API 層中的所有公共寫方法(包括插入、更新和刪除)都應當使用事務屬性 REQUIRED 加以標記。
API 層中的所有公共寫方法(包括插入、更新和刪除)都應當包含回滾邏輯,以標記對檢查出的異常 執行回滾的事務。
API 層中的所有公共讀方法默認情況下都應使用事務屬性 SUPPORTS 加以標記(參見 “事務策略:了 解事務陷阱” 中的 事務策略:了解事務陷阱 側邊欄內容)。這將確保在一個事務范圍的上下文內調用 讀方法時,該方法被包括在事務范圍內。否則,它將在事務上下文之外運行,並假設它是惟一一個在邏輯 工作單元(LUW)內得到調用的方法。我在這裡假設這個讀操作(作為 API 層的入口點)不會反過來對數 據庫調用寫操作。
API 層的事務將傳播到在事務所有者 內調用的所有方法(如 下一小節 定義的那樣)。
聲明式事務(Declarative Transaction)模型通常用於這種模式,並假設 API 層類由一個 Java EE 容器環境管理,或由另一個框架(比如 Spring)管理。如果不是這樣的話,那麼很可能需要使用編程式 事務(Programmatic Transaction)模型。(參見 “Transaction strategies: Models and strategies overview” 了解更多有關這些事務模型的信息)。
根據上面列出的幾條規則,如果您仔細觀察的話,可能會注意到這個策略有些小問題。由於執行服務 之間的通信,一個公共 API 層更新方法可以調用另一個公共 API 層更新方法。由於這兩個更新方法都是 公共方法,並且從客戶機層的角度看被公開為 API 層入口點,因此它們包含了回滾邏輯。然而,如果其 中一個公共更新方法調用了另一個,那麼事務所有者在某些情況下可能無法控制回滾邏輯。因此,事務所 有者在重新提交事務或采取糾正操作時,必須萬分小心。遇到這些情況時,需要重新構造結構和處理邏輯 以避免發生此類問題。
限制和約束
事務策略的其中一個限制,就是客戶機層(或表示層)類對任何給定事務工作單元只能發出單一的 API 層調用。這使得這種策略不太適合 “聊天” 應用程序。不幸的是,這是一種全有或全無(all-or- nothing)式的思想,並且在某些情況下需要對應用程序進行重構(本節後面將詳述)。讓我解釋一下它 對事務策略的重要性(和必要性)。
我將對整個事務策略 系列中描述的所有事務策略應用的兩條黃金法則(秘訣)是:
啟動事務的方法被指定為事務所有者
只有事務所有者可以回滾事務
如果不遵守這些法則的話,事務策略將不能正常工作。您很可能會遇到問題,導致不一致的數據和糟 糕的數據完整性。第二條法則非常重要,原因有兩點。首先,如果某個方法沒有啟動事務,那麼它就不需 要管理事務(例如,將其標記為回滾)。其次,如果調用鏈中較低級別的方法調用回滾事務,那麼事務所 有者不能采取糾正操作來修復並重新提交事務;一旦被標記為回滾,那麼這是惟一可能的結果。您無法對 事務 “撤銷回滾”。
回到原點:對於 API 層事務策略,客戶機絕對 不能在涉及事務的單一工作單元中對 API 層發出多個 調用。如果客戶機對給定的 LUW 發出多個 API 調用,那麼必須在客戶機啟動和終止事務工作單元。在這 種情況下,API 層方法必須擁有一個事務屬性 MANDATORY,而不應包括任何回滾邏輯。記住剛才的兩條黃 金法則:調用 API 層方法的客戶機方法是事務所有者,只有事務所有者才負責執行回滾。
考慮圖 2 所示的例子,其中一個客戶機(客戶機 A)向 API 層(域模型)發出一個請求,請求將一 個股票交易插入到數據庫:
圖 2. 使用 MANDATORY 屬性
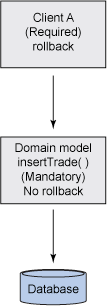
在這種情況下,客戶機啟動事務;因此使用 REQUIRED 事務屬性。注意客戶機還負責執行回滾,遵守 剛才提到的兩條黃金法則。域類屬性有一個事務屬性 MANDATORY,因為客戶機正在啟動事務,而域模型( insertTrade())不負責執行回滾。
該策略適合圖 2 所示的場景。然而,假設您有另一個客戶機應用程序(客戶機 B)需要使用同一個域 模型(insertTrade()),如圖 3 所示:
圖 3. 非事務性客戶機問題
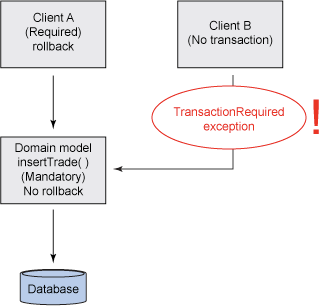
注意,客戶機 B 並沒有啟動事務(它可以是一個遠程 HTTP 客戶機、消息傳遞客戶機、或其他無法使 用事務的 Java 應用程序)。由於域模型方法被標記為 MANDATORY,客戶機 B 將得到一個 TransactionRequiredException,表示事務需要調用該方法。
如果沒有提供合適的事務策略,那麼通常解決此問題的辦法就是將域模型(insertTrade())中的事務 屬性修改為 REQUIRED。現在,如果返回到客戶機 A 的調用,將注意到您並沒有影響到任何內容;客戶機 A 啟動了一個事務,然後將事務上下文傳遞給域模型方法。由於域模型方法現在被標記為 REQUIRED,因 此它將使用現有的事務上下文。注意,域模型方法並沒有包含回滾邏輯。執行了域模型後(不管是否出現 異常),控制權將返回給客戶機。這些操作都可以在客戶機 A 中正確地執行。然而,如果觀察一下客戶 機 B,則出現了一個問題:由於沒有提供任何事物上下文,域模型方法(insertTrade())啟動了一個新 事務,但是在出現被檢測到的異常後,由於域模型方法不負責執行回滾,因此沒有執行任何回滾。圖 4 解釋了這一錯誤條件:
圖 4. 使用 REQUIRED 屬性而未執行回滾
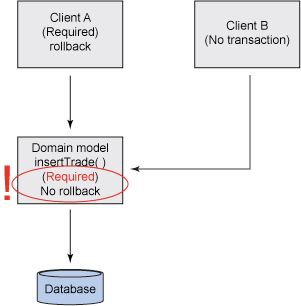
在為提供合適事務策略的情況下,解決這一問題的慣用方法是向域模型方法添加回滾邏輯,以滿足來 自客戶機 B 的調用。然而,如圖 5 所示,這將在客戶機 A 中引發問題:
圖 5. 客戶機回滾問題
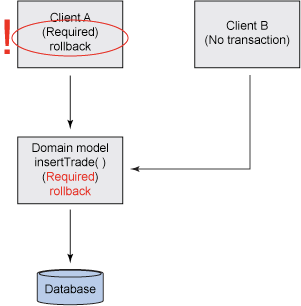
客戶機 A 在嘗試回滾事務時,不僅會收到一個異常,而且客戶機 A 還不能采取糾正操作,因為事務 已經被標記為回滾。
如此反復……
這解釋了事務策略為什麼如此重要,以及為什麼它們必須是絕對的。如前所述,您會發現對於 LUW 請 求,應用程序使用 85% 的單 API 層調用和 15% 的多 API 層調用。如果是這樣的話(或類似的情形), 那麼有兩種選擇:不要協調事務工作單元中的多個調用(這不是個好主意),或者(更好的方法)是使用 一個聚合 API 層方法將多個 API 調用重構為一個單一的 API 調用。
為了解釋這種重構技巧,我假設您擁有兩個 API 層方法 insertTrade() 和 updateAcct(),如清單 1 所示:
清單 1. 多個 API 層方法
@Stateless
@Remote(TradingService.class)
public class TradingServiceImpl implements TradingService {
@PersistenceContext(unitName="trading") EntityManager em;
@Resource SessionContext ctx;
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public long insertTrade(TradeData trade) throws Exception {
try {
em.persist(trade);
return trade.getTradeId();
} catch (Exception up) {
ctx.setRollbackOnly();
throw up;
}
}
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public void updateAcct(TradeData trade) throws Exception {
try {
//update account balance based on buy or sell...
} catch (Exception up) {
ctx.setRollbackOnly();
throw up;
}
}
}
假設這些方法都可以作為獨立的操作運行。然而,如清單 2 所示,很多時候客戶機可以在相同的 LUW 中同時調用這兩種方法:
清單 2. 在同一個客戶機方法中執行多個表更新
public TradeData invokeClientRequest(TradeData trade) throws Exception {
try {
insertTrade(trade);
updateAcct(trade);
return trade;
} catch (Exception up) {
//log the error
throw up;
}
}
在這裡,並沒有將事務放在客戶機層而搞亂所有內容,更好的辦法是通過在 TradingServiceImpl 類 和相應的 TradingService 接口中創建新的聚合方法來移除多 API 層調用。清單 3 展示了這個新的聚合 方法(為簡單起見,沒有顯示接口代碼):
清單 3. 添加一個公共聚合方法
@Stateless
@Remote(TradingService.class)
public class TradingServiceImpl implements TradingService {
@PersistenceContext(unitName="trading") EntityManager em;
@Resource SessionContext ctx;
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public TradeData placeTrade(TradeData trade) throws Exception {
try {
insertTrade(trade);
updateAcct(trade);
return trade;
} catch (Exception up) {
ctx.setRollbackOnly();
throw up;
}
}
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public long insertTrade(TradeData trade) throws Exception {
...
}
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public void updateAcct(TradeData trade) throws Exception {
...
}
}
重構後的客戶機代碼如清單 4 所示:
清單 4. 重構後的客戶機代碼只發出一個 API 層調用
public TradeData invokeClientRequest(TradeData trade) throws Exception {
try {
return placeTrade(trade);
} catch (Exception up) {
//log the error
throw up;
}
}
注意,客戶機方法現在對名為 placeTrade() 的 API 層中的新聚合方法發出了一個調用。 insertTrade() 和 updateAcct() 方法仍然是公共方法,因為它們可以彼此獨立調用,而不用考慮新的聚 合方法。
盡管我使用了一個簡單的示例進行說明,但是我並沒有要刻意忽略這項重構技巧的復雜性。在某些情 況下(特別是使用 HTTPServletRequest 或 HTTPSession 等基於 Web 的對象的客戶機代碼)重構可以非 常復雜並涉及到大量的代碼修改。您需要在重構客戶機和服務器代碼所需的工作量和對數據完整性、一致 性的需求之間做出權衡。就是說,現在需要考慮到實用性。要實現朝向可靠事務策略(比如本文描述的 API 層事務策略)的漸進式推進,可以臨時向客戶機代碼添加事務邏輯,從而在同一個事務工作單元中保 持兩個 API 層調用互相協調(確保 API 層仍然具有 REQUIRED 屬性設置)。然而,您應當理解執行以下 操作的含義:
您需要在客戶機方法中使用編程式的事務(參見 “事務策略:模型和策略概述”)。
當 API 層方法被標記為回滾事務時,需要將事務回滾封裝到 try/catch 塊中。
不能夠對異常采取糾正操作。
客戶機和 API 層使用的通信協議受到了限制(例如,沒有 HTTP、沒有 JMS 等等)。
注意,通過 漸進式地實現這個事務策略,您將不會得到一個可靠和健壯的事務策略,除非您完成了重構工作。
事務策略實現
API Layer 事務策略的實現相當簡單。因為包含事務邏輯的惟一的一個層是 API 層,我將只展示該層 的域模型類中的事務邏輯。
回憶一下 策略設置和特征 小節,對於寫操作(更新、插入和刪除),公共 API 層方法應當有一個事 務屬性 REQUIRED 並包含事務回滾邏輯。任何公共讀方法在默認情況下都應該有一個事務屬性 SUPPORTS ,其中不包含回滾邏輯。下面的清單 5 解釋了這一事務策略實現:
清單 5. 實現 API Layer 策略
@Stateless
@Remote(TradingService.class)
public class TradingServiceImpl implements TradingService {
@PersistenceContext (unitName="trading") EntityManager em;
@Resource SessionContext ctx;
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public long insertTrade (TradeData trade) throws Exception {
try {
em.persist(trade);
return trade.getTradeId();
} catch (Exception up) {
ctx.setRollbackOnly();
throw up;
}
}
@TransactionAttribute (TransactionAttributeType.SUPPORTS)
public TradeData getTradeOrder(long tradeId) {
return em.find(TradeData.class, tradeId);
}
}
實現這一策略的一種更優化的方法是利用 EJB 3.0 中的 @TransactionAttribute 注釋的 TYPE 作用 域,並且在默認情況下將整個類中的所有方法設為 REQUIRED,同時只將讀操作覆蓋為 SUPPORTS。清單 6 展示了這一技巧:
清單 6. 優化 API Layer 策略的實現
@Stateless
@Remote(TradingService.class)
@TransactionAttribute(TransactionAttributeType.REQUIRED)
public class TradingServiceImpl implements TradingService {
@PersistenceContext (unitName="trading") EntityManager em;
@Resource SessionContext ctx;
public long insertTrade(TradeData trade) throws Exception {
try {
em.persist(trade);
return trade.getTradeId();
} catch (Exception up) {
ctx.setRollbackOnly();
throw up;
}
}
@TransactionAttribute(TransactionAttributeType.SUPPORTS)
public TradeData getTradeOrder(long tradeId) {
return em.find(TradeData.class, tradeId);
}
}
我建議使用這種方法,而不是將所有內容默認設置為 SUPPORTS,因為如果您忘記編寫 @TransactionAttribute 注釋的話,那麼擁有一個事務總比什麼都沒有強。
結束語
API Layer 事務策略將良好地應用於大多數業務應用程序。它很直觀、簡單、易於實現,並且很健壯 。您可能需要進行一些應用程序重構來實現這一策略,但從長遠來看,付出這些努力來獲得高度的數據一 致性和完整性是非常值得的。記住,本文所描述的是一種事務策略。它所涉及的不僅僅是一個簡單的實現 任務。團隊中的每位開發人員都應當知道並理解所使用的事務策略,能夠描述它,並且最重要的是能夠執 行它。
盡管 API Layer 事務策略是最常見的一種策略,但它也許正是您的應用程序所需要的策略。例如,有 些時候,單個 LUW 中的單一 API 調用和多個 API 調用之間的分割百分比是顛倒的(假設,20% 的單一 API 層調用,80% 的多 API 層調用)。對於這類情況,可能不希望進行重大的重構。這時應當使用 Client Orchestration 事務策略,這是我將在本系列下一篇文章中介紹的內容。否則,在 API Layer 事 務策略中實現事務的時間會變得很長,從而導致數據庫並發性問題,降低了吞吐量,需要連接等待,甚至 出現數據庫死鎖。這些症狀經常出現在高並發性環境中,在這種環境中,應用程序必須處理龐大的用戶量 或負載。遇到這種情況,需要使用 High Concurrency 事務策略 — 本系列第 5 篇文章的主題。最後一 種情況,您發現自己面對的是專門針對高速需求的標准應用程序架構,每一毫秒的處理時間都非常重要。 對於這些情況,您將需要使用 High Speed 事務策略,我將在本系列的第 6 篇文章中進行討論。