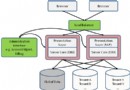
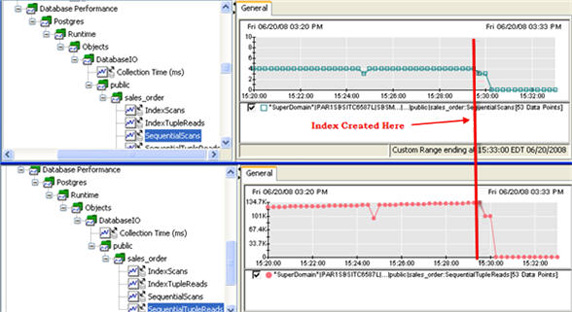
在這個場景中,我構造了一個有用的例子,而沒有在 sales_order 表上創建索引。因此,監控將會揭示更多的順序掃描(按照數據庫用語來說為表掃描),它是一個低效的檢索數據的機制,這是因為它要讀取表中的每一行。順序元組讀取 — 主要指使用順序掃描讀取的行的數量 — 也一樣。行和元組之間有一個很大的差別,但是在這裡沒有關系。要弄清楚這個差異,您可以查看 PostgreSQL 文檔網站(參見 參考資料)。看一看 APM 顯示的這些統計信息,很明顯我的數據庫遺漏了一個索引。如圖 11 所示:
圖 11. 順序讀取
注意到了這一點後,我趕緊觸發了兩個 SQL 語句來索引表格。隨後的結果是兩個順序操作都降到了零,而本來為零的索引操作現在卻運行起來。如圖 12 所示:
圖 12. 索引後
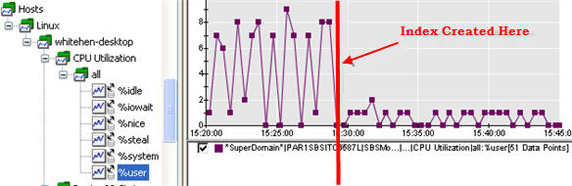
這個索引的創建在整個系統中發生了連鎖反應。另一個明顯穩定下來的指標是數據庫主機上的 User CPU %。如圖 13 所示:
圖 13. 索引後的 CPU
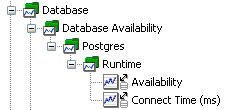
數據庫可用性
我要介紹的有關 JDBC 的最後一個方面是數據庫可用性。數據庫可用性的最簡單的形式是選擇標准 JDBCCollector。如果收集器被配置了一個 availabilityNameSpace 值,那麼收集器將兩個指標跟蹤到配置的名稱空間:
可用性:可以連接到數據庫的話,值為 1,無法連接到數據庫的話,值為 0
連接時間:獲取連接消耗的運行時間
當用數據源或連接池來獲取連接時,連接時間通常都是很快的。但大多數 JDBC 連接池系統都能在分發連接前執行一個可配置的 SQL 語句,所以測試是合法的。在重負載的情況下,連接的獲取會有一個非零的運行時間。此外,可以為用於測試可用性的 JDBCCollector 設置單獨的數據源。這個單獨的數據源可以配置為不共享連接,所以每一個輪詢周期都會啟動一個新的連接。圖 14 顯示了我的 PostgreSQL 運行時數據庫的可用性檢查 APM 樹。請參考 清單 14,查看使用 availabilityNameSpace 屬性的例子。
圖 14. 運行時數據庫可用性檢查
我見過需要多個連鎖查詢來決定一個特定狀態的情況。例如,一個最終的狀態需要對 Database A 進行查詢,但它所需的參數只有對 Database B 進行查詢才可以確定。這種情況可以用兩個 JDBCCollector 來解決,但要特殊考慮如下幾點:
按時間先後排列的第一個查詢(針對 Database B)被配置為惰性的,因為它沒有進行調度(收集的頻率為零就意味著無調度)。JDBCCollector 的實例同樣實現了 IBindVariableProvider,這意味著它也能夠給另一個收集器提供綁定變量和綁定。
第二個收集器把第一個收集器定義為一個綁定,該綁定將會在第一次查詢後實現。
我對數據庫監控的論述就到此為止了。我必須補充說明一下,這一節重點介紹的是數據庫監控,尤其是通過 JDBC 接口的數據庫監控。完成一個典型的數據庫監控還要監控數據庫所在的 OS、單個數據庫進程或數據庫進程組、還有一些有必要訪問數據庫服務的相關的網絡資源。
監控 JMS 和消息傳遞系統
本節將描述監控消息傳遞服務的健康狀況和性能的技巧。消息傳遞服務,如實現 JMS — 同樣指面向消息的中間件(message-oriented middleware,MOM)— 的服務,在很多應用程序中都起著至關重要的作用。它們和其他應用程序依賴項一樣也需要監控。通常,消息傳遞服務提供同步的或者說是 “即發即棄(fire-and-forget)” 調用點。監控這些點的難度要大一些,因為從很多角度來看,該服務看起來都運行得很好,服務的調用被頻繁地分配,並且運行的時間也很短。仍然保持神秘的是上游瓶頸,消息要經過這裡被轉發到下一個目標,但消息在這裡的傳輸速度很慢或者根本無法通過。
由於大多數消息傳遞服務都存在於 JVM 中,抑或是作為一個或多個本機進程而存在於一個主機(或一組主機)上,監控點包括一些與目標服務有關的相同的點。這些目標服務可能包括標准 JVM JMX 屬性、支持主機上的監控資源、網絡響應,以及諸如內存大小和 CPU 使用這樣的服務進程特征。
我將概述消息傳遞服務監控的四個范疇,它們當中的三個都是專用於 JMS 的,另一個則涉及到專有的 API:
為了度量一個服務的吞吐性能,收集器會定時向該服務發送一組綜合的 測試消息,然後等待它們的返回。發送、接收和整個往返過程的總運行時間都被度量、跟蹤,同時被度量和跟蹤的還有所有失敗或超時事件。
很多基於 Java 的 JMS 產品都通過 JMX 公開指標和監控點,所以我將簡短地回顧一下如何使用 Spring 收集器實現 JMX 監控。
有些消息傳遞服務為通信代理的管理提供了一個私有的 API。這些 API 通常包含提取運行中服務的性能指標的能力。
如果缺少上述選項中的任意一個的話,都可以使用諸如 javax.jms.QueueBrowser 這樣的標准 JMS 構造來檢索有用的指標。
通過綜合測試消息來監控消息傳遞服務
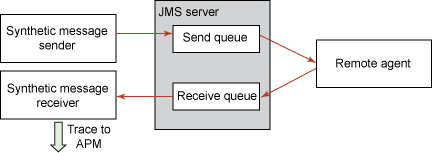
綜合消息的前提是將測試消息的發送和接收安排到目標消息傳遞服務並度量消息的發送、接收和整個往返過程的運行時間。為了設計消息的返回並准確地度量從遠程位置發送消息的響應時間,最佳的解決方案就是部署遠程代理,它的任務是:
監聽中央監控器的測試信息
檢索它們
給每一個收到的消息添加一個時間戳
重新將它們發送回消息傳遞服務,目的是返回到中央監控器
然後中央監控器可以分析返回的消息,得出進程中的每一個跳躍點(hop)的運行時間並跟蹤到 APM 系統。如圖 15 所示:
圖 15. 綜合消息
雖然這個方法涉及到了監控的大多方面,但它還是有一些缺點:
它需要部署和管理一個遠程代理。
它需要在消息傳遞服務上為測試消息傳輸創建其他的隊列。
有些消息傳遞服務允許自動動態創建一級隊列,但很多消息傳遞服務都需要通過管理接口或管理 API 來手動創建隊列。
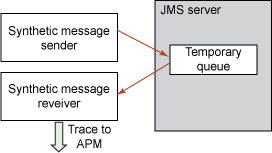
這裡介紹的另一個專用於 JMS(但可能在其他消息傳遞系統中有等效體)的選擇是使用臨時隊列或主題。臨時隊列可以由標准 JMS API 自動創建,所以不需要介入任何管理。這些臨時構造有很多額外的優勢,但只有最初的創建者可以看到,其他所有 JMS 參與者都無法看到。
在這個場景中,我將使用 JMSCollector,它可以在啟動時自動創建一個臨時隊列。當調度器提示時,它會將很多測試消息發送給目標 JMS 服務上的臨時隊列,然後再收回它們。這就有效地測試了 JMS 服務器的吞吐量,而無需創建具體隊列或部署遠程代理。如圖 16 所示:
圖 16. 帶有臨時隊列的綜合消息
這個場景的 Spring 收集器類為 org.runtimemonitoring.spring.collectors.jms.JMSCollector。配置依賴項相當的簡單明了,而且大多數依賴項已經在前面的例子中設置過了。JMS 連通性需要一個 JMS javax.jms.ConnectionFactory。我用來獲取它的 Spring bean 與在 Windows WPM 收集的例子中用來獲取 JMS 連接工廠的 Spring bean 相同。在這裡重新修改一下,它需要 org.springframework.jndi.JndiTemplate 類型的 Spring bean 的一個實例,該類型的 Spring bean 可以給我的目標 JMS 服務提供一個 JNDI 連接;它還需要 org.springframework.jndi.JndiObjectFactoryBean 類型的 Spring bean 的一個實例,該類型的 Spring bean 可以使用 JNDI 連接來查找 JMS 連接工廠。
為了使綜合消息負載的組成靈活一些,JMSCollector 被配置了名為 org.runtimemonitoring.spring.collectors.jms.ISyntheticMessageFactory 的接口的一組實現。實現這個接口的對象提供了一組測試消息。收集器會調用每一個配置的工廠,並使用所提供的消息來執行往返測試。用這種方式,我就能夠測試我的 JMS 服務器上的吞吐量,因為負載會隨著消息大小和消息計數的變化而變化。
每一個 ISyntheticMessageFactory 都有一個可配置的、任意的名稱,JMSCollector 把它添加到跟蹤名稱空間。清單 15 展示了完全的配置:
清單 15. 綜合消息 JMSCollector
<!-- The JNDI Provider -->
<bean id="jbossJndiTemplate" class="org.springframework.jndi.JndiTemplate">
<property name="environment"><props>
<prop key="java.naming.factory.initial">
org.jnp.interfaces.NamingContextFactory
</prop>
<prop key="java.naming.provider.url">
localhost:1099
</prop>
<prop key="java.naming.factory.url.pkgs">
org.jboss.naming:org.jnp.interfaces
</prop>
</props></property>
</bean>
<!-- The JMS Connection Factory Provider -->
<bean id="RealJMSConnectionFactory"
class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiTemplate" ref="jbossJndiTemplate" />
<property name="jndiName" value="ConnectionFactory" />
</bean>
<!-- A Set of Synthetic Message Factories -->
<bean id="MessageFactories" class="java.util.HashSet">
<constructor-arg><set>
<bean
class="org.runtimemonitoring.spring.collectors.jms.SimpleSyntheticMessageFactory">
<property name="name" value="MapMessage"/>
<property name="messageCount" value="10"/>
</bean>
<bean
class="org.runtimemonitoring.spring.collectors.jms.ByteArraySyntheticMessageFactory">
<constructor-arg type="java.net.URL"
value="file:///C:/projects3.3/RuntimeMonitoring/lib/jta26.jar"/>
<property name="name" value="ByteMessage"/>
<property name="messageCount" value="1"/>
</bean></set>
</constructor-arg>
</bean>
<!-- The JMS Collector -->
<bean id="LocalJMSSyntheticMessageCollector"
class="org.runtimemonitoring.spring.collectors.jms.JMSCollector"
init-method="springStart">
<property name="scheduler" ref="CollectionScheduler" />
<property name="logErrors" value="true" />
<property name="tracingNameSpace" value="JMS,Local,Synthetic Messages" />
<property name="frequency" value="5000" />
<property name="messageTimeOut" value="10000" />
<property name="initialDelay" value="3000" />
<property name="messageFactories" ref="MessageFactories"/>
<property name="queueConnectionFactory" ref="RealJMSConnectionFactory"/>
</bean>
清單 15 實現了兩個消息工廠,它們是:
javax.jms.MapMessage 工廠,它將當前 JVM 的屬性載入到每一條消息的負載中,並被配置為每個周期發送 10 條消息
javax.jms.ByteMessage 工廠,它將 JAR 文件中的字節載入到每一條消息的負載中,並被配置為每個周期發送 10 條消息
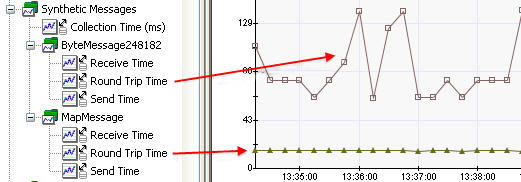
圖 17 顯示了綜合消息監控的 APM 樹。注意字節負載大小被附加到 javax.jms.ByteMessage 消息工廠名稱的末尾。
圖 17. 帶有臨時隊列的綜合消息的 APM 樹
通過 JMX 監控消息傳遞服務
諸如 JBossMQ 和 ActiveMQ 這樣的消息傳遞服務通過 JMX 公開了一個管理接口。我曾在 第 1 部分 中介紹過基於 JMX 的監控。下面我將簡短地回顧一下這種監控,然後我將介紹基於 org.runtimemonitoring.spring.collectors.jmx.JMXCollector 類的 Spring 收集器以及使用它來監控 JBossMQ 實例的方法。由於 JMX 是一個恆定的標准,所以可以使用同一過程來監控任何公開 JMX 的指標,而且它的應用范圍很廣。
JMXCollector 有兩個依賴項:
一個名為 LocalRMIAdaptor 的 bean 為本地 JBossMQ 提供了一個 javax.management.MBeanServerConnection。在這種情況下,連接是通過發出一個對 JBoss org.jboss.jmx.adaptor.rmi.RMIAdaptor 的 JNDI 查找來獲取的。假定可以提供任何可用的驗證憑證,並且 Spring org.springframework.jmx.support 包提供了很多工廠 bean 來獲取 MBeanServerConnection(參見 參考資料)的不同實現,這樣的話其他的提供者通常很容易獲取。
JMX 收集屬性的一個配置文件,它打包在包含 org.runtimemonitoring.spring.collectors.jmx.JMXCollection 的實例的收集 bean 中。這些是對 JMXCollector 發出的關於要收集哪些屬性的指令。
JMXCollection 類展示了一些常見於 JMX 監控器的屬性。基本的配置屬性有:
targetObjectName :它是旨在收集的 MBean 的完整 JMX ObjectName 名稱,但它也可以是一個通配符。收集器為所有與通配符模式相匹配的 MBeans 查詢 JMX 代理,然後從每一個代理中收集數據。
segments :它是 APM 跟蹤名稱空間的一個片斷,收集到的指標被跟蹤到了這個 APM 跟蹤名稱空間。
metricNames :它可以是一組指標名稱,每一個 MBean 屬性都要被映射到該指標名稱;也可以是一個 * 字符,它指導收集器使用 MBean 提供的屬性名。
attributeNames :它是一組必須從每一個目標 MBean 中收集的 MBean 屬性名。
metricTypes 或者 defaultMetricType :前者是必須用於每一個屬性的一組指標類型,後者是必須應用於所有屬性的某個指標類型。
MBean ObjectName 通配符功能非常強大,因為它可以有效地發現監控目標,而無需為每一個目標配置監控器。對於 JMS 對列,JBossMQ 為每一個隊列創建了一個單獨的 MBean,所以如果我想監控每一個隊列中的消息數(稱為隊列長度),我只需要指定諸如 jboss.mq.destination:service=Queue,* 這樣的通用通配符,JMS 隊列 MBean 的所有實例都是從其中收集到的。但是,由於這些對象是自動發現的,所以如何動態確定隊列名就成了另一個難題。在本例中,我知道被發現的 MBean 的 ObjectName name 屬性值就是隊列的名稱。例如,一個被發現的 MBean 的對象名可能是 jboss.mq.destination:service=Queue,name=MyQueue 。因此,我需要一種將被發現的對象的屬性映射到跟蹤名稱空間的方式,這樣就可以從每一個源中劃分出被跟蹤的指標。方法就是以與 JDBCCollector 中的 rowToken 相類似的形式來使用標記。JMXCollector 支持的標記有:
{target-property:name} :該標記用源自目標 MBean 的 ObjectName 的命名屬性來取代。例子:{target-property:name}。
{this-property:name} :該標記用源自收集器的 ObjectName 的命名屬性來取代。例子:{this-property:type}。
{target-domain:index} :該標記用目標 MBean 的 ObjectName 域的索引片斷來取代。例子:{target-domain:2}。
{this-domain:index} :該標記用收集器的 ObjectName 域的索引片斷來取代。例子:{target-domain:0}。
清單 16 展示了經過刪減的 JBossMQ JMXCollector XML 配置:
清單 16. 本地 JBossMQ JMXCollector
<!-- The JBoss RMI MBeanServerConnection Provider -->
<bean id="LocalRMIAdaptor"
class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiTemplate" ref="jbossJmxJndiTemplate" />
<property name="jndiName" value="jmx/invoker/RMIAdaptor" />
</bean>
<!-- The JBossMQ JMXCollection Profile -->
<bean id="StandardJBossJMSProfile"
class="org.runtimemonitoring.spring.collectors.collections.InitableHashSet"
init-method="init" >
<constructor-arg><set>
<bean class="org.runtimemonitoring.spring.collectors.jmx.JMXCollection">
<property name="targetObjectName" value="*:service=Queue,*"/>
<property name="segments" value="Destinations,Queues,{target-property:name}"/>
<property name="metricNames" value="*"/>
<property name="attributeNames"
value="QueueDepth,ScheduledMessageCount,InProcessMessageCount,ReceiversCount"/>
<property name="defaultMetricType" value="SINT"/>
</bean>
<bean class="org.runtimemonitoring.spring.collectors.jmx.JMXCollection">
<property name="targetObjectName" value="jboss.mq:service=DestinationManager"/>
<property name="segments" value="Destniations,{target-property:service}"/>
<property name="metricNames" value="*"/>
<property name="attributeNames" value="ClientCount"/>
<property name="defaultMetricType" value="SINT"/>
</bean>
<!-- MBeans Also Included: Topics, ThreadPool, MessageCache -->
</set>
</constructor>
</bean>
<!-- The JMXCollector for local JBoss MQ Server -->
<bean id="LocalJBossCollector"
class="org.runtimemonitoring.spring.collectors.jmx.JMXCollector"
init-method="springStart">
<property name="server" ref="LocalRMIAdaptor" />
<property name="scheduler" ref="CollectionScheduler" />
<property name="logErrors" value="true" />
<property name="tracingNameSpace" value="JMS,Local" />
<property name="objectName"
value="org.runtime.jms:name=JMSQueueMonitor,type=JMXCollector" />
<property name="frequency" value="10000" />
<property name="initialDelay" value="10" />
<property name="jmxCollections" ref="StandardJBossJMSProfile"/>
</bean>
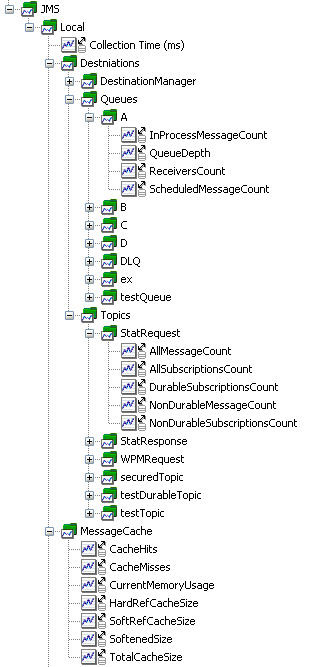
圖 18 顯示了用 JMXCollector 監控的 JBossMQ 服務器的 JMS 隊列的 APM 樹:
圖 18. JBossMQ 隊列的 JMX 監控的 APM 樹
用隊列浏覽器監控 JMS 隊列
如果缺少足夠用於監控 JMS 隊列的管理 API 的話,可以使用 javax.jms.QueueBrowser。隊列浏覽器的行為與 javax.jms.QueueReceiver 的行為類似,不同的是獲取的信息不會從隊列中移除,而且在被浏覽器檢索之後仍然可以發送。隊列深度通常都是一種重要的指標。據觀察在很多消息傳遞系統中,消息生產者要多於消息消費者。這種嚴重的不平衡從代理隊列中消息的數量可以看出來。因此,如果無法用其他的方式訪問隊列深度的話,那麼最後一招就是使用隊列浏覽器了。該技巧有很多的缺點。為了計數隊列中的消息數,隊列浏覽器一定要檢索隊列中的每一條信息(然後刪除它們)。這樣做的效率是很低的,而且要耗費比使用管理 API 多得多的收集時間 — 而且可能在 JMS 服務器的資源上開銷更高。隊列浏覽的另一個問題是,對於繁忙的系統來說,計數在浏覽完成的時候很可能就已經是錯誤的了。雖說如此,要是為了監控的話,近似值還是可以接受的;更何況在高負載的系統中,即便是對隊列深度在給定瞬間的高精確度的度量在下一個瞬間也會是無用的了。
隊列浏覽有一個好處:在浏覽隊列的信息的過程中,可以確定最老的消息的年齡。這是一個很難獲取的指標,即便是使用最好的 JMS 管理 API 也很難獲取,而且在某些情況下,它可能是一個至關重要的監控點。思考一下用於傳輸重要信息的 JMS 隊列。消息生產者和消息消費者有著明顯的區別,而流量的模式是這樣的:對隊列深度執行一次標准的輪詢通常顯示一到兩條信息。通常情況下,導致這個問題的原因是存在一定的延遲,而輪詢的頻率卻是一分鐘,隊列中的消息不同於輪詢到輪詢間的消息。它們相同麼?它們可能不是相同的消息,在這種情況下,上述的情況就是很正常的。但也可能是消息生產者和消息消費者同時遭遇失敗,因此隊列中被觀察的這對消息在每個輪詢中是相同的消息。在這種場景中,在監控隊列深度的同時監控最老的消息的年齡就會使情況變得很清晰了:正常情況下,消息的年齡要少於幾秒,但如果生產者和消費者同時失敗的話,從 APM 出現明顯的數據只會占用兩個輪詢周期間的時間。
這個功能在 Spring 收集器的 org.runtimemonitoring.spring.collectors.jmx.JMSBrowserCollector 中有所展示。它的另外兩個配置屬性有 javax.jms.ConnectionFactory,它與 JMSCollector 類似,還有要浏覽的隊列的集合。清單 17 展示了該收集器的配置:
清單 17. 本地 JBossMQ JMSBrowserCollector
<!-- A collection of Queues to browse -->
<bean id="BrowserMonitorQueues" class="java.util.HashSet">
<constructor-arg>
<set>
<bean id="QueueA"
class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiTemplate" ref="jbossJndiTemplate" />
<property name="jndiName" value="queue/A" />
</bean>
<bean id="QueueB"
class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiTemplate" ref="jbossJndiTemplate" />
<property name="jndiName" value="queue/B" />
</bean>
</set>
</constructor-arg>
</bean>
<!-- the JMS Queue Browser -->
<bean id="LocalQueueBrowserCollector"
class="org.runtimemonitoring.spring.collectors.jms.JMSBrowserCollector"
init-method="springStart">
<property name="scheduler" ref="CollectionScheduler" />
<property name="logErrors" value="true" />
<property name="tracingNameSpace" value="JMS,Local,Queue Browsers" />
<property name="frequency" value="5000" />
<property name="initialDelay" value="3000" />
<property name="queueConnectionFactory" ref="RealJMSConnectionFactory"/>
<property name="queues" ref="BrowserMonitorQueues"/>
</bean>
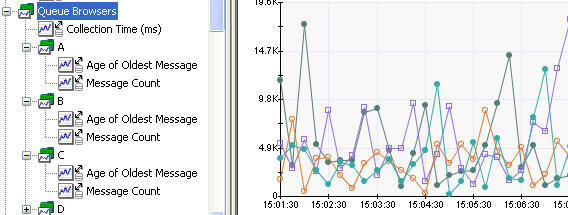
圖 19 展示了該收集器的 APM 樹:
圖 19. JMSBrowserCollector 的 APM 樹
作為一個測試機制,一個載入腳本開始循環,在循環中向每一個隊列發送了幾百條消息。在每一個循環中,被清除的隊列是隨機選取的。因此,每一個隊列中的消息年齡的上限都會隨著時間的推移而隨意變化。
使用私有 API 監控消息傳遞系統
有些消息傳遞系統擁有實現諸如監控這樣的管理功能的私有 API。一些消息傳遞系統使用請求/響應 的模式來用它們自己的消息傳遞系統提交管理請求。ActiveMQ(參見 參考資料)提供了一個 JMS 通信管理 API 以及一個 JMX 管理 API。實現一個私有的管理 API 需要一個自定義的收集器。在這個小節中,我將呈現 WebSphere® MQ(原來稱為 MQ Series)的收集器。該收集器結合使用了兩種 API:
MS0B: WebSphere MQ Java classes for PCF:PCF API 是 WebSphere MQ 的一個管理 API。
The core WebSphere MQ Java classes:原來稱為 MA88 的 API 已經被合並到了核心 WebSphere MQ Java 類庫中(參見 參考資料)。
其實使用兩個 API 是多余的,但是畢竟展示了兩種不同的私有 API 的使用方法。
Spring 收集器實現是一個名為 org.runtimemonitoring.spring.collectors.mq.MQCollector 的類。它監控 WebSphere MQ 服務器上的所有隊列,收集每一個隊列的隊列深度以及當前打開的輸入/輸出處理的數量。清單 18 展示了 org.runtimemonitoring.spring.collectors.mq.MQCollector 的配置:
清單 18. WebSphere MQ 收集器
<bean id="MQPCFAgentCollector"
class="org.runtimemonitoring.spring.collectors.mq.MQCollector"
init-method="springStart">
<property name="scheduler" ref="CollectionScheduler" />
<property name="logErrors" value="true" />
<property name="tracingNameSpace" value="MQ, Queues" />
<property name="frequency" value="5000" />
<property name="initialDelay" value="3000" />
<property name="channel" value="SERVER1.QM2"/>
<property name="host" value="192.168.7.32"/>
<property name="port" value="50002"/>
</bean>
這裡獨特的配置屬性有:
host WebSphere MQ 服務器的主機名稱的 IP 地址
port :WebSphere MQ 進程在該端口監聽連接
channel :要連接到的 WebSphere MQ 通道
注意這個例子不包含任何的驗證方面。
圖 20 展示了為 org.runtimemonitoring.spring.collectors.mq.MQCollector 生成的 APM 樹:
圖 20. MQCollector 的 APM 樹
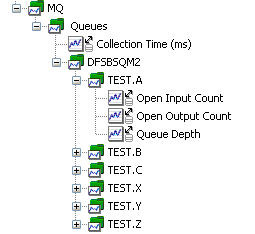
我對消息傳遞服務監控的論述就到此為止。正如我在前面提到的,接下來我將介紹如何用 SNMP 進行監控。
使用 SNMP 進行監控
SNMP 原本是作為應用層協議而創建的,該協議用來在諸如路由器、防火牆和交換機這樣的網絡設備間交換信息。這也許仍然是它最常用的功能,但是它也可以充當監控性能和可用性的靈活的標准化協議。SNMP 的整個主題以及它作為一個監控工具的實現超出了本文的討論范圍。但是,SNMP 在監控領域已經非常普及,因此難免會有所遺漏。
SNMP 中的核心結構之一就是代理,它負責代理針對某一個設備的 SNMP 請求。SNMP 相對簡單且較低級,所以 SNMP 代理可以簡單且快捷地嵌套到多種硬件設備和軟件服務中。因此 SNMP 就是一個在應用程序生態系統中監控大量服務的標准化協議。另外,SNMP 被廣泛用於通過掃描一系列的 IP 地址和端口來執行發現。從監控的角度看,SNMP 的這個應用可以節省一些管理時間,因為它能夠自動填充和更新一個監控目標的集中式清單。SNMP 在很多方面都與 JMX 極其相似。雖然兩者之間還是有一些明顯的差別,但還是可以在兩者間找出一些相同的內容,而且 JMX 和 SNMP 間的互操作性被廣泛地支持與實現。表 1 總結了一些兩者之間的等價內容:
表 1. SNMP 和 JMX 對比
SNMP 結構 等效 JMX 結構 代理 代理或者 MBeanServer 管理程序 客戶機、MBeanServerConnection、協議適配器 MIB MBean、ObjectName、MBeanInfo OID ObjectName 和 ObjectName+ Attribute 名 陷阱 JMX Notification GET、SET getAttribute、setAttribute BULKGET getAttributes
單從監控角度考慮,發布一個 SNMP 查詢時,我需要了解的重要因素有:
主機地址:目標 SNMP 代理所在的 IP 地址或主機名。
端口:目標 SNMP 代理在其上進行監聽的端口。由於一個網絡地址可能在處理很多個 SNMP 代理,每一個代理都需要在不同的端口上進行監聽。
協議版本:SNMP 協議已經經歷過多次的修訂了,而支持級別會根據不同的代理而變化。可選的版本有:1、2c 和 3。
社區:SNMP 社區是一個松散定義的管理域。如果社區不是已知的話,SNMP 客戶機就無法憑代理發出請求,所以發揮著松散形式的驗證作用。
OID:這是一個指標或一組指標的惟一標示符。其格式為一系列用點分隔的整數。例如,Linux 主機的一分鐘載入的 SNMP OID 為 .1.3.6.1.4.1.2021.10.1.3.1,由 1、5 和 15 分鐘載入的指標子集的 OID 為 .1.3.6.1.4.1.2021.10.1.3。
除了社區以外,有些代理還可以定義其他層面的驗證。
在我深入論述 SNMP API 之前,要注意 SNMP 指標可以使用兩個普通的命令行實用程序來檢索,它們是: snmpget,它檢索一個 OID 的值;snmpwalk,它檢索 OID 值的子集。記住了這點,我就能夠經常擴展我的 ShellCollector CommandSet 來跟蹤 SNMP OID 值了。清單 19 示范了一個 snmpwalk 的例子,它帶有在 Linux 主機上檢索 1、5 和 15 分鐘載入的原始的輸出。我使用的是該協議的 2c 版本和公共社區。
清單 19. snmpwalk 示例
$> snmpwalk -v 2c -c public 127.0.0.1 .1.3.6.1.4.1.2021.10.1.3
UCD-SNMP-MIB::laLoad.1 = STRING: 0.22
UCD-SNMP-MIB::laLoad.2 = STRING: 0.27
UCD-SNMP-MIB::laLoad.3 = STRING: 0.26
$> snmpwalk -v 2c -c public 127.0.0.1 .1.3.6.1.4.1.2021.10.1.3 \
| awk '{ split($1, name, "::"); print name[2] " " $4}'
laLoad.1 0.32
laLoad.2 0.23
laLoad.3 0.22
第二條命令可以輕松地在我的 Linux 命令集中表現出來,如清單 20 所示:
清單 20. 處理 snmpwalk 命令的 CommandSet
<CommandSet name="LinuxSNMP">
<Commands><Command>
<shellCommand><![CDATA[snmpwalk -v 2c -c public 127.0.0.1
.1.3.6.1.4.1.2021.10.1.3 | awk '{ split($1, name, "::"); print name[2] "
" $4}']]></shellCommand>
<Extractors><CommandResultExtract>
<paragraph id="0" name="System Load Summary" header="false"/>
<columns entryName="0" values="1" offset="0">
<namemapping from="laLoad.1" to="1 Minute Load"/>
<namemapping from="laLoad.2" to="5 Minute Load"/>
<namemapping from="laLoad.3" to="15 Minute Load"/>
</columns>
<tracers default="SINT"/>
<lineSplit>\n</lineSplit>
</CommandResultExtract></Extractors>
</Command></Commands>
</CommandSet>
商用的、開源 SNMP Java API 有好多個。我實現了一個基本的 Spring 收集器,它的名稱為 org.runtimemonitoring.spring.collectors.snmp.SNMPCollector,該收集器的實現使用到了一個名為 joeSNMP 的開源 API(參見 參考資料)。該收集器擁有如下的重要配置屬性:
hostName :目標主機的主機名或 IP 地址。
port :目標 SNMP 代理正在其上進行監聽的端口的數量(默認為 161)。
targets :一組由 org.runtimemonitoring.spring.collectors.snmp.SNMPCollection 的實例組成的 SNMP OID 目標。該 bean 的配置屬性有:
nameSpace :跟蹤名稱空間的後綴。
oid :跟蹤名稱空間的後綴。
protocol :SNMP 協議, 0 表示 v1,1 表示 v2(默認為 v1)。
community :SNMP 社區(默認為 public)。
retries :嘗試操作的次數(默認為 1)。
timeOut :以 ms 為單位的 SNMP 調用的超時時間(默認為 5000)。
清單 21 展示了 SNMPCollector 設置的示例配置,該配置的目的是監控本地 JBoss 應用服務器:
清單 21. SNMPCollector 的配置
<!-- Defines the SNMP OIDs I want to collect and the mapped name -->
<bean id="JBossSNMPProfile" class="java.util.HashSet">
<constructor-arg><set>
<bean class="org.runtimemonitoring.spring.collectors.snmp.SNMPCollection">
<property name="nameSpace" value="Free Memory"/>
<property name="oid" value=".1.2.3.4.1.2"/>
</bean>
<bean class="org.runtimemonitoring.spring.collectors.snmp.SNMPCollection">
<property name="nameSpace" value="Max Memory"/>
<property name="oid" value=".1.2.3.4.1.3"/>
</bean>
<bean class="org.runtimemonitoring.spring.collectors.snmp.SNMPCollection">
<property name="nameSpace" value="Thread Pool Queue Size"/>
<property name="oid" value=".1.2.3.4.1.4"/>
</bean>
<bean class="org.runtimemonitoring.spring.collectors.snmp.SNMPCollection">
<property name="nameSpace" value="TX Manager, Rollback Count"/>
<property name="oid" value=".1.2.3.4.1.7"/>
</bean>
<bean class="org.runtimemonitoring.spring.collectors.snmp.SNMPCollection">
<property name="nameSpace" value="TX Manager, Current Count"/>
<property name="oid" value=".1.2.3.4.1.8"/>
</bean>
</set></constructor-arg>
</bean>
<!-- Configures an SNMP collector for my local JBoss Server -->
<bean id="LocalJBossSNMP"
class="org.runtimemonitoring.spring.collectors.snmp.SNMPCollector"
init-method="springStart">
<property name="scheduler" ref="CollectionScheduler" />
<property name="logErrors" value="true" />
<property name="tracingNameSpace" value="Local,JBoss,SNMP" />
<property name="frequency" value="5000" />
<property name="initialDelay" value="3000" />
<property name="hostName" value="localhost"/>
<property name="port" value="1161"/>
<property name="targets" ref="JBossSNMPProfile"/>
</bean>
該收集器的確是有些缺點,畢竟配置有些長,而且由於它要為每一個 OID 做出一個調用而非批量收集,導致運行時效率低下。示例代碼中的 snmp-collectors.xml 文件(參見 下載)也包含了一個監控 Linux 服務器的 SNMP 收集器的配置示例。圖 21 顯示了 APM 系統指標樹:
圖 21. SNMPCollector 的 APM 樹
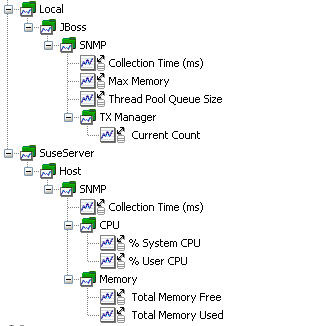
此時,您可能了解到如何創建收集器了。要覆蓋整個環境,可能需要集中不同類型的收集器,如果您對此感興趣的話,您可以參見本文的示例代碼,那裡包含有其他監控目標的收集器示例。它們都位於 org.runtimemonitoring.spring.collectors 包中。表 2 是這些收集器的一個概述:
表 2. 其他收集器示例
收集目標 類 Web 服務:檢查安全 Web 服務的響應時間和可用性 webservice.MutualAuthWSClient Web 服務和 URL 檢查 webservice.NoAuthWSClient Apache Web Server、性能和可用性 apacheweb.ApacheModStatusCollector Ping network.PingCollector NTop:一個收集詳細網絡統計信息的實用程序 network.NTopHostTrafficCollector
數據管理
收集繁忙的可用性和性能數據的系統所面臨的一個最復雜的難題就是:如何有效地將收集到的數據持久化到普通指標數據庫中。對於要使用的數據庫和持久化機制要考慮的問題有:
指標數據庫一定要支持對歷史指標的適當快速的、簡單的查詢,以實現數據可視化、數據報告和數據分析。
指標數據庫一定要保留數據的歷史和粒度,從而支持報告的時窗、准確性和所需精確度。
持久化機制一定要足夠好地、並行地運行,避免影響前端監控的活躍性。
指標數據的檢索和儲存要能夠並行運行,且兩者都不會對方有任何負面的影響。
從數據庫中請求數據的請求要能夠支持一段時間內的聚合。
數據庫中的數據要以適當的方式存儲,允許使用一種時間序列模式檢索數據或使用某種機制保證多個數據點能夠在有效時間段相同的情況下相互關聯。
鑒於這些考慮,您需要:
一個性能良好的、可伸縮的、帶有很多磁盤空間的數據庫。
一個帶有有效搜索算法的數據庫。本質上講,由於指標將會通過復合名稱來儲存,所以解決方案就是將復合名稱儲存為一個字符串並使用某種形式的模式匹配來指定目標查詢指標。很多關系數據庫都支持內置於 SQL 語法的正則表達式,這是一個通過復合名稱查詢的理想方法,但是這個方法比較慢,這是因為它通常排除使用索引。但是很多關系數據庫同樣支持功能索引,該索引能夠在使用模式匹配搜索時用來加快查詢的速度。另外一個選擇是完全標准化 數據並分別取出復合名稱的單個片斷(參見下面的 標准化數據庫結構和扁平數據庫結構 )。
限制寫入數和寫入數據庫的總數據量的策略就是實現一連串的分層聚合和合並。這可以在數據被寫入數據庫前通過保持一個總體緩沖器來完成。在指定的時間段內,將所有標記為儲存的指標寫入一個累計緩沖器,它可以保留指標有效啟動時間和終止時間,以及在該段時間內的平均的、最小的和最大的指標值。這樣,指標值就可以在寫入數據庫前被聚合和合並。例如,如果一個收集器的頻率是 15 秒,而聚合時間是 1 分鐘的話, 4 個單個指標將會被合並成為 1 個。這裡假設可以允許持久化的數據丟失粒度,所以要在低數據量的低粒度和高數據量的高粒度之間做出權衡。同時,指標的實時可視化可以通過從聚合前的常駐內存循環緩沖器呈現圖形來實現,這樣就只有持久化的數據被聚合了。當然,您有權選擇哪些指標需要持久化。
另外一個減少儲存數據量的策略是實現一個采樣頻率,在這個采樣頻率中只有每 y 行中的 x 個指標會被儲存。這也會降低持久化數據的粒度,但會占用比維護聚合緩沖器更少的資源(尤其是內存)。
持久化的指標數據還可以在指標數據庫中累積並清除。同樣,在容忍的粒度丟失范圍內,可以將數據庫中幾個時間段內的數據分小時、天、周、月等累計到匯總表格中;你也可以清除原始數據;仍然保留適當的有用的指標數據。
為了避免數據持久化過程的活動影響到數據收集器本身,有必要實現一個非侵入式的後台線程,它能夠將離散的指標數據的收集刷新到數據儲存進程。
對於多個擁有不同有效時窗的數據集,創建一個類似時間序列的報告有些困難。思考一下圖形中表示時間的 x 軸,和表示特定指標的值和多個序列(直線或曲線)(代表來源於不同資源集的相同指標)的 y 軸。如果讀取每一個序列的有效時間戳有很大差別的話,就一定要傳輸數據以保持圖形表示有效。這個可以通過將數據聚合到所有繪制的序列中最不一致的時窗來實現,同樣粒度也會丟失。更簡單的解決方案是維護一個在所有指標值中都一致的、有效的時間戳。時間序列數據庫有這個功能。常用的是 RRDTool,它跨序列中所有不同的數據值有效地實施一致的、均衡分布的時間戳。為了使有效的時間戳在關系數據庫中保持一致,一個絕佳的策略就是用一個單一的、統一的調度程序對所有指標取樣。例如,一個計時器可能每兩分鐘觸發一次,結果導致在那一刻捕獲了所有指標的一個單一的 “交換”,而且所有的指標都用相同的時間戳標記,然後放入隊列中等待持久化。
顯然,要以一種最佳的方式來解決上述的每一個問題是很難的,所以必須要考慮折衷的辦法。圖 22 展示了一個數據收集器在概念上的數據持久化流程:
圖 22. 數據管理流程
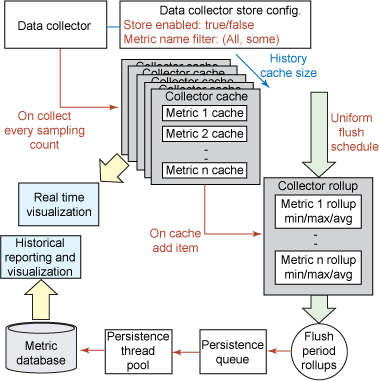
圖 22 表示概念數據收集器(像本文中呈現的 Spring 收集器)的數據流。目的是通過一些層推動單個指標跟蹤度量,直到它們被持久化。具體的過程為:
數據收集器是隨意配置的,為了實現帶有如下屬性的指標持久化:
啟用持久化:True 或 false。
指標名稱過濾器:一個正則表達式。匹配正則表達的指標名會被標記為持久化。
采樣計數:會跳過持久化的指標收集的數量,也就是說 0 意味著全部持久化。
歷史緩存大小:必須保存在緩存中的被跟蹤的指標的數量。為了實現實時可視化,必須為歷史緩存啟用大多數指標,即使這些指標未被標記為持久化,這樣它們可以呈現為實時圖表。
收集器緩存就是很多的離散指標讀數,該讀數與收集器生成的各種指標的數量相等。緩存遵循先入先出(first in, first out,FIFO)原則,所以當歷史緩存變滿時,最老的指標會被清除,為最新的指標騰出空間。緩存支持注冊緩存事件監聽器,它們可以被告知有哪些指標被從緩存中移除,又有哪些被存入。
收集器總計是一系列由收集器生成的指標實例的兩個或更多循環緩存。由於循環緩沖器中的每一個緩存實例變為活動狀態,它就會為歷史緩存注冊新的跟蹤事件並聚合每一個輸入的新值,有效地合並給定時間段內的數據流。該總計包含:
該時間段的啟動和終止時間(終止時間在時間段結束前是未定的)。
該時間段內的最小、最大和平均讀數。
指標類型。
中央計時器會在每個時間段末尾觸發一個刷新事件。當計時器觸發後,收集器總計循環緩沖器索引是遞增的,而歷史緩存事件被傳遞給緩沖器中的下一個緩存。然後 “關閉的” 緩沖器中的每一個聚合的總計都會有一個公用的時間戳應用於該總計,並被寫入待存入數據庫的持久化隊列。
注意當循環緩沖器遞增時,下一個緩沖元素的最小的、最大的和平均值將會是零,除了 sticky 指標類型。
持久化線程池中的一池線程從持久化隊列中讀取總計項並將它們寫入數據庫。
相同收集器總計被合並的總計時間段的長度要取決於中央刷新計時器的頻率。該時間段越長,寫入數據庫的數據就越少,代價是數據粒度將會丟失。
標准化數據庫結構與扁平數據庫結構
一些專用數據庫(比如 RRDTool)可以用於指標存儲,但是通常使用的是關系數據庫。在關系數據庫中執行指標存儲時,需要考慮兩個一般選項:標准化數據或保持一種更加扁平的結構。這主要關系到如何存儲復合指標名稱;根據數據建模最佳實踐,應該對所有其他引用數據進行標准化。
完全標准化的數據庫結構的好處在於,通過將指標復合名稱分解為獨立的片段,實際上任何數據庫都可以利用索引功能來加速查詢。它們存儲的冗余數據更少,從而使數據庫更小,數據密度更高,性能也更好。其缺點在於復雜性和查詢的大小:即使相對簡單的復合指標名稱或指標名稱的模式(例如主機 11 到 93 之間的 % User CPU)都要求 SQL 包含一些連接和大量謂詞。這個缺點可以通過使用數據庫視圖和硬存儲常用指標名解碼來減輕。每個單獨指標的存儲需要分解復合名稱來定位指標引用數據項(或創建一個新的引用數據項),但是這種性能開銷可以通過在持久過程中緩存所有引用數據來減輕。
圖 23 展示一種用於在標准化結構中存儲復合指標的模型:
圖 23. 一種用於指標存儲的標准化模型
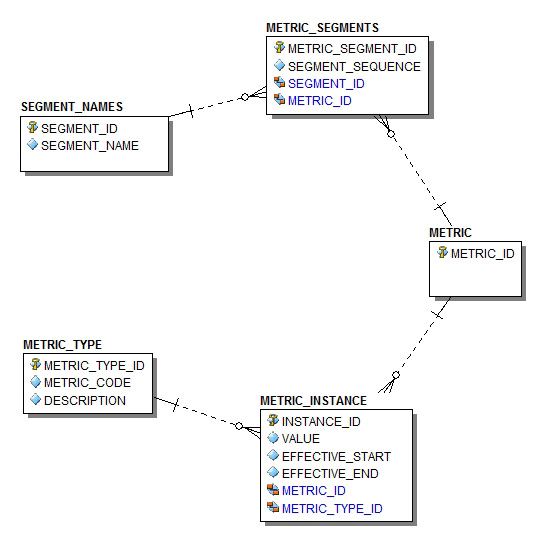
在圖 23 中,為每個惟一的復合指標分配了一個惟一的 METRIC_ID,為每個惟一的片段分配了一個 SEGMENT_ID。然後在一個包含 METRIC_ID、SEGMENT_ID 和片段出現順序的關聯實體中構建復合名稱。指標類型存儲在引用表 METRIC_TYPE 中,而指標值本身存儲在 METRIC_INSTANCE 中(包含值、時間戳的開始和結束屬性,以及對指標類型和惟一 METRIC_ID 的引用)。
另一方面,扁平模型結構非常簡單,如圖 24 所示:
圖 24. 用於指標存儲的扁平模型
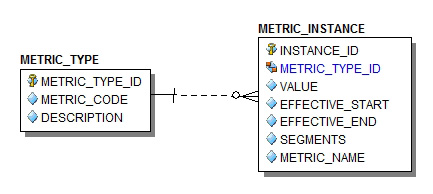
在本例中,我將指標名稱從復合名稱中分離開來,剩余的片段仍然保持其在 segments 列中的原有模式。同樣,如果實現的數據庫引擎能夠使用基於模式的謂詞(比如正則表達式)執行適合較寬的文本列的查詢,那麼這種模型非常易於查詢。這種優點應當重視。使用簡化的查詢結構,能夠顯著地簡化數據分析、可視化和報告工具,而且在緊急的分類會話期間,加快查詢的編寫速度可能是最重要的方面!
如果需要持久化數據存儲,挑選正確的數據庫是非常關鍵的一步。使用關系數據庫是一種可行的方法,因為關系數據庫能夠很好地執行,並且可以從中提取數據並針對您的需要進行格式化。時間序列驅動的數據的生成比較復雜,但是通過正確地分組和聚合 —— 以及使用其他工具,比如 JFreeChart(參見 參考資料)—— 可以生成出色的典型報告和圖表。如果想要實現一種更加專門化的數據庫(比如 RRDTool),那麼請做好心理准備,因為這種數據庫的提取和報告需要很長時間。如果數據庫不支持 ODBC、JDBC 等標准,那麼將不能使用常用的標准化報告工具。
對數據管理的討論到此為止。本文最後一節將提供一些用於實時可視化數據的技術。
可視化和報告
在某些情況下,將實現插裝和性能數據收集器,數據將會流入您的 APM 系統中。那麼下一個邏輯步驟就是實時地查看數據的可視化表示。我在這裡寬泛地使用實時 這個詞,其含義是可視化地表示最近收集的數據。
常用的數據可視化術語是指示板。指示板能夠可視化地呈現您所考慮的數據模式或活動的所有方面,它們惟一的限制就是數據的質量和數量。本質上,指示板告訴您生態系統中正在發生什麼。指示板在 APM 系統中的一個強大之處是,它能夠通過一種統一的顯示形式表示各種各樣的數據(即從不同來源收集的數據)。例如,一種顯示形式可以在指示板上同時顯示數據庫中 CPU 的最近使用情況和當前趨勢、應用服務器之間的網絡活動,以及當前登錄到您的應用程序的用戶數量。在本節中,我將提供一些不同的數據可視化樣式,以及我在本文前面提供的 Spring 收集器的一個可視化層實現示例。
Spring 收集器可視化層的前提條件包括:
將一個緩存類實例部署為一個 Spring bean。可以配置緩存類實例來保存任何數量的 ITracer 歷史跟蹤,但它的大小是固定的並且遵循先進先出的規則。一個緩存可以配置為保存 50 條歷史記錄,這意味著一旦緩存被填滿,它將保存最近的 50 條歷史記錄。
Spring 收集器在 Spring XML 配置文件中使用 cacheConfiguration 進行配置,使用一個緩存進程封裝 ITracer 實例。配置還將收集器與定義的緩存實例相關聯。收集的跟蹤記錄像平常一樣進行處理,但是添加了與收集器相關聯的緩存實例。我們看一下前面的示例,如果緩存的歷史記錄大小為 50,並且收集器每隔 30 秒收集一次,那麼當緩存被填滿時,它將保存收集器在最近 25 分鐘內收集的歷史跟蹤記錄。
Spring 收集器實例部署了大量呈現類。呈現器(Renderer)是一些用於實現 org.runtimemonitoring.spring.rendering.IRenderer 接口的類。它們的工作是從緩存獲取一系列數據並呈現這些數據的某種可視化形式。從呈現器定期檢索可視化媒體將生成最新的表示,或者與緩存數據一樣新的表示。
呈現內容然後可以在一種指示板上下文(比如一個 Web 浏覽器)中傳遞到一個客戶機或某種形式的富客戶機。
圖 25 列出了這一過程:
圖 25. 緩存和呈現
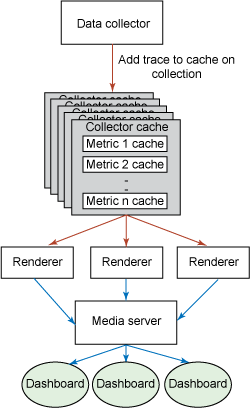
本例中的緩存實現是 org.runtimemonitoring.spring.collectors.cache.TraceCacheStore。可以將其他對象注冊為緩存事件監聽器,這樣,在其他事件中,呈現器可以監聽表示新值被添加到緩存的新緩存項 事件。通過這種方式,呈現器能夠實際地緩存它們生成的內容,並在新數據可用時使緩存無效。來自呈現器的內容通過一個稱為 org.runtimemonitoring.spring.rendering.MediaServlet 的 servlet 傳遞到客戶機指示板。該 servlet 解析它接收到的請求,定位呈現器,並請求內容(所有內容都以一個字節數組的形式呈現和傳遞)和內容的 MIME 類型。字節數組和 MIME 類型然後流動到客戶機,以供客戶機解釋。處理來自基於 URL 的服務的圖形內容是最理想的,因為它們可以被 Web 浏覽器、富客戶機及它們之間的所有內容使用。當呈現器從媒體服務器接收到一個內容請求時,內容將從緩存傳遞,除非該緩存被一個緩存事件標記為 dirty。通過這種方式,呈現器不需要對每個請求重新生成它們的內容。
以字節數組格式生成、緩存和傳遞可視化的媒體非常有用,因為這種格式占用的空間最小,並且大多數客戶機都可以在提供了 MIME 類型的情況下重新建立內容。由於這種實現在內存中緩存生成的內容,所以我使用了一種壓縮方案。總體內存消耗隨著緩存內容的增多而顯著增加;同樣,如果內容附帶提供了壓縮算法標記,那麼大多數客戶機都能夠解壓縮。例如,時下流行的大多數浏覽器都支持 gzip 解壓縮。然而,合理的壓縮級別不一定要非常高(對於較大的圖像來說,30-40% 的壓縮率就不錯了),因此,呈現實現可以緩存到磁盤,或者如果磁盤訪問開銷更高,動態地重新生成內容可能會需要更少的資源。
在這裡,使用一個具體示例將有助於理解。我設置了兩個 Apache Web Server 收集器來監控大量繁忙的 worker 線程。每個收集器都分配有一個緩存,而且我設置了少量的呈現器,用以提供圖表來顯示每個服務器上繁忙的 worker 線程。在本例中,呈現器生成一個 PNG 文件來顯示兩個服務器的時間序列線圖及其序列。一個服務器的收集器和緩存設置如清單 22 所示:
清單 22. 一個 Apache Web Server 收集器和緩存
<!-- The Apache Collector -->
<bean id="Apache2-AP02"
class="org.runtimemonitoring.spring.collectors.apacheweb.ApacheModStatusCollector"
init-method="springStart">
<property name="scheduler" ref="CollectionScheduler" />
<property name="logErrors" value="true" />
<property name="tracingNameSpace" value="WebServers,Apache" />
<property name="frequency" value="15000" />
<property name="initialDelay" value="3000" />
<property name="modStatusURL" value="http://WebAP02/server-status?auto" />
<property name="name" value="Apache2-AP02" />
<property name="cacheConfiguration">
<bean
class="org.runtimemonitoring.spring.collectors.cache.CacheConfiguration">
<property name="cacheStores" ref="Apache2-AP02-Cache"/>
</bean>
</property>
</bean>
<!-- The Apache Collector Cache -->
<bean id="Apache2-AP02-Cache"
class="org.runtimemonitoring.spring.collectors.cache.TraceCacheStore">
<constructor-arg value="50"/>
</bean>
注意收集器中的 cacheConfiguration 屬性,以及它如何引用稱為 Apache2-AP02-Cache 的緩存對象。
我還設置了一個呈現器,它是 org.runtimemonitoring.spring.rendering.GroovyRenderer 的一個實例。這個呈現器將所有呈現任務委派給文件系統的一個底層 Groovy 腳本。這是最理想的方法,因為我能夠在運行時對其進行調整,從而調整生成的圖的細節。這個呈現器的一般屬性包括:
groovyRenderer :一個對 org.runtimemonitoring.spring.groovy.GroovyScriptManager 的引用,它被配置為從一個目錄載入 Groovy 腳本。這也是我用於將從 Telnet 會話返回的數據傳遞到我的 Cisco CSS 的類。
dataCaches :一組緩存,呈現器從中請求數據並呈現出來。呈現器也注冊為當緩存添加新項時從緩存接收事件。當它這樣做時,它將其內容標記為 dirty,並對下一個請求重新生成內容。
renderingProperties :傳遞給呈現器的默認屬性,指定生成的圖形的具體細節,比如圖像的默認大小。您將會在下面看到,這些屬性可以被客戶機請求覆蓋。
metricLocatorFilters :一個收集器緩存,包含收集器生成的每個指標的緩存跟蹤。這個屬性允許指定一個正則表達式數組來篩選您想要的指標。
緩存設置如清單 23 所示:
清單 23. 用於 Apache Web Server 繁忙 worker 線程監控的圖形呈現器
<bean id="Apache2-All-BusyWorkers-Line"
class="org.runtimemonitoring.spring.rendering.GroovyRenderer"
init-method="init"
lazy-init="false">
<property name="groovyRenderer">
<bean class="org.runtimemonitoring.spring.groovy.GroovyScriptManager">
<property name="sourceUrl" value="file:///groovy/rendering/multiLine.groovy"/>
</bean>
</property>
<property name="dataCaches">
<set>
<ref bean="Apache2-AP01-Cache"/>
<ref bean="Apache2-AP02-Cache"/>
</set>
</property>
<property name="renderingProperties">
<value>
xSize=700
ySize=300
title=Apache Servers Busy Workers
xAxisName=Time
yAxisName=# of Workers Busy
</value>
</property>
<property name="metricLocatorFilters" value=".*/Busy Workers"/>
</bean>
呈現器非常容易實現,但是我發現,我經常需要對它們進行調整,因此這裡列出的 Groovy 方法非常適用於對新的圖表類型或者新的圖形包進行快速原型化。編譯 Groovy 代碼時,性能非常好,實現出色的內容緩存也不是問題。動態熱更新功能和功能強大的 Groovy 語法使動態更新變得非常輕松。隨後,當我確定了呈現器要做的工作以及它應該支持哪些選項時,我將它們移植到 Java 代碼。
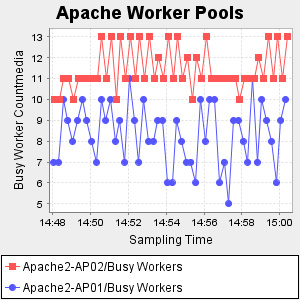
指標名稱由 org.runtimemonitoring.tracing.Trace 類生成。這個類的每個實例表示一個 ITracer 讀操作,所以它封裝了跟蹤的值、時間戳和完整的名稱空間。指標的名稱就是完整的名稱空間。在本例中,我所顯示的指標是 WebServers/Apache/Apache2-AP01/Busy Workers,因此,在清單 23 的呈現器中定義的過濾器使用該指標來呈現。生成的 JPG 如圖 26 所示:
圖 26. 呈現的 Apache 繁忙 worker 線程
不同的客戶機可能需要不同的呈現圖。例如,一個客戶機可能需要一個更小的圖像。能夠動態調整大小的圖像通常比較合適。另一個客戶機可能也需要一個更小的圖像,但不想要標題(在其自己的 UI 中提供標題)。MediaServlet 允許在內容請求期間實現其他選項。這些選項被附加到內容請求的 URL 之後,並以 REST 格式進行處理。基本格式是媒體 servlet 路徑(可以進行配置)後接緩存名稱,或 /media/Apache2-All-BusyWorkers-Line。每個呈現器能夠支持不同的選項。對於我們上面使用的呈現器,以下選項就是一個很好的示例:
默認 URI:/media/Apache2-All-BusyWorkers-Line
縮小到 300 X 300:/media/Apache2-All-BusyWorkers-Line/300/300
縮小到 300 X 300,帶有最小的標題和軸名稱:/media/Apache2-All-BusyWorkers-Line/300/300/BusyWorkers/Time/#Workers
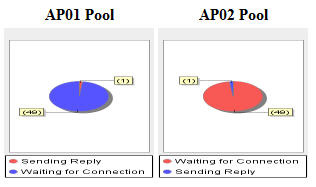
圖 27 展示了兩個沒有標題的縮小的餅圖,使用了 URI Apache2-AP02-WorkerStatus-Pie/150/150/ /:
圖 27. 縮小的 Apache Server worker 線程池圖像
呈現器可以生成請求內容的客戶機能夠顯示的幾乎任何格式的內容。圖像格式可以是 JPG、PNG 或 GIF。也支持其他圖像格式,但是對於定位於 Web 浏覽器客戶機的靜態圖像,PNG 和 GIF 可能最適合。其他格式選擇包括基於文本的標記,比如 HTML。浏覽器和富客戶機都能夠呈現 HTML 片段,HTML 是顯示獨立數據字段和交叉表格的理想選擇。純文本也非常有用。例如,一個 Web 浏覽器客戶機可以從呈現器檢索表示系統生成的事件消息的文本,並將其插入到文本框和列表框中。其他類型的標記也非常實用。許多呈現適用於浏覽器的數據包的富客戶機和客戶端讀入定義圖形的 XML 文檔,然後這些圖形可以在客戶端生成,這樣可以優化性能。
客戶端呈現能夠提供額外的優化。如果客戶機能夠呈現自己的可視化,那麼它就可以將緩存更新直接傳遞到客戶機,繞過呈現器,除非需要使用呈現器來添加標記。通過這種方式,客戶機可以訂閱緩存更新事件,並接受這些事件,更新其自己的可視化。可以通過多種方式將數據傳遞到客戶機。在浏覽器客戶機中,一種簡單的 Ajax 風格的輪詢程序能夠周期性地檢查服務器的更新,並實現一個能夠將任何更新插入到數據結構中的處理程序來處理浏覽器中的呈現。其他選項稍微復雜,涉及到使用 Comet 模式的實際數據流,要求一個到服務器的連接始終保持打開,而且當服務器寫入數據時,這些數據就會被客戶機讀取(參見 參考資料)。對於富客戶機,使用一個消息傳遞系統是最理想的方法,客戶機可以在其中訂閱數據更新提要。ActiveMQ 既能夠與 Jetty Web 服務器結合使用,又具有其 Comet 功能,因此可以創建一個基於浏覽器的 JavaScript JMS 客戶機並訂閱隊列和主題。
客戶端上豐富的呈現選擇還提供了扁平圖像不具有的功能,比如單擊元素以向下鑽取的功能 — APM 指示板的一種常見需求,向下鑽取用於導航或更詳細地查看圖表中的特定項。一個示例就是 Visifire,它是一種開源繪圖工具,與 Silverlight(參見 參考資料)結合使用。清單 24 展示一個 XML 片段,該片段生成一個顯示各個數據庫服務器的 CPU 使用情況的條形圖:
清單 24. 數據庫平均 CPU 使用情況的圖形呈現器
<vc:Chart xmlns:vc="clr-namespace:Visifire.Charts;assembly=Visifire.Charts"
Theme="Theme3">
<vc:Title Text="Average CPU Utilization on Database Servers"/>
<vc:AxisY Prefix="%" Title="Utilization"/>
<vc:DataSeries Name="Utilization" RenderAs="Column">
<vc:DataPoint AxisLabel="DB01" YValue="13"/>
<vc:DataPoint AxisLabel="DB02" YValue="57"/>
<vc:DataPoint AxisLabel="DB03" YValue="41"/>
<vc:DataPoint AxisLabel="DB04" YValue="10"/>
<vc:DataPoint AxisLabel="DB05" YValue="30"/>
</vc:DataSeries>
</vc:Chart>
這段 XML 非常普通,所以很容易為其創建一個呈現器,並且外觀非常不錯。客戶端呈現器也可以為可視化添加動畫效果,這對 APM 系統顯示沒什麼價值,但是在一些情況下可能非常有幫助。圖 28 展示了在啟用了 Silverlight 客戶機的浏覽器中生成的圖形:
圖 28. 一個 VisiFire Silverlight 呈現的圖表
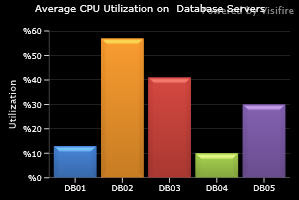
APM 指示板中包含所有標准圖標類型。最常見的是折線圖、多線圖、條形圖和餅圖。一些圖表通常是組合而成的,比如將條形圖和折線圖組合以顯示兩種不同類型數據的重疊情況。在另外一些情形中,一個折線圖具有兩條 y 軸,以便在同一個圖表中表示數量差距較大的數據序列。繪制一個百分比值和一個標量值時通常屬於這種情況,比如路由器上的 % CPU 利用率與傳遞的字節數。
在一些場景下,可以創建專門的小部件來以一種自定義方式表示數據,或者以一種直觀的方式顯示數據。例如,枚舉的符號顯示一個與監控目標狀態一致的特定圖標。因為狀態通常由有限的值表示,使用圖形表示有些大材小用了,所以可以采用一些類似交通燈的顯示方式來表示,比如紅色表示下降、黃色表示警告、綠色表示良好。另一個流行的小部件是刻度盤(通常表示為一種速度計)。我認為使用刻度盤浪費了屏幕空間,因為它們僅顯示一個數據矢量,不包含歷史記錄。折線圖既能顯示相同的數據,還能夠顯示歷史趨勢。一個例外是,多指針的刻度盤能夠顯示高/低/當前狀態等范圍。但是在很大程度上,它們只能提供一種視覺上的吸引力,比如圖 29 中的刻度盤,通過 “high/low/current” 顯示了在過去一小時內每秒獲得的數據庫塊緩沖區情況:
圖 29. 示例刻度盤小部件

依我看來,可視化的好處在於信息密度高。屏幕空間是有限的,但我想要查看盡可能多的數據。可以通過多種方式來提高數據密度,但自定義圖形表示是一種有趣的方式,它將多種維度的數據組合到一個小的圖片之中。圖 30 展示了一種不錯的示例,該示例來自一個已經退役的數據庫監控產品:
圖 30. Savant 緩存命中率顯示
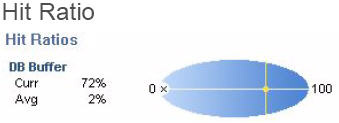
圖 30 顯示了與數據庫緩沖命中率相關的一些數據矢量:
水平軸表示在緩存中找到的數據的百分比。
垂直軸表示當前的命中率。
X 表示命中率趨勢。
灰色的圓圈(在這個圖像中幾乎看不見)表示標准偏差。灰色圓圈的直徑越大,緩存性能的偏差就越大。
黃色的球表示過去一小時內的緩存性能。
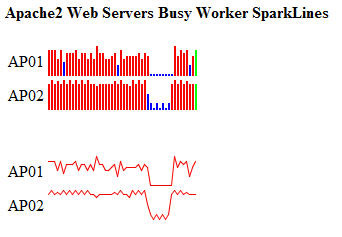
提高數據密度的第二種方法是 Sparkline,這是一種要求更低的方法。這個詞是由數據可視化專家(參見 參考資料)根據 “嵌入到文字、數字和圖像中的小型、高分辨率圖形” 得出的。它通常用於顯示大量的財務統計信息。盡管缺乏上下文,但它們的用途是顯示跨許多指標的相對趨勢。Sparkline 呈現器由 org.runtimemonitoring.spring.rendering.SparkLineRenderer 類實現,它為 Java 庫實現開源的 Sparklines(參見 參考資料)。圖 31 中演示了兩個 Sparklines,展示了基於條和線的顯示效果:
圖 31. 顯示 Apache 2 繁忙 worker 線程的 Sparklines
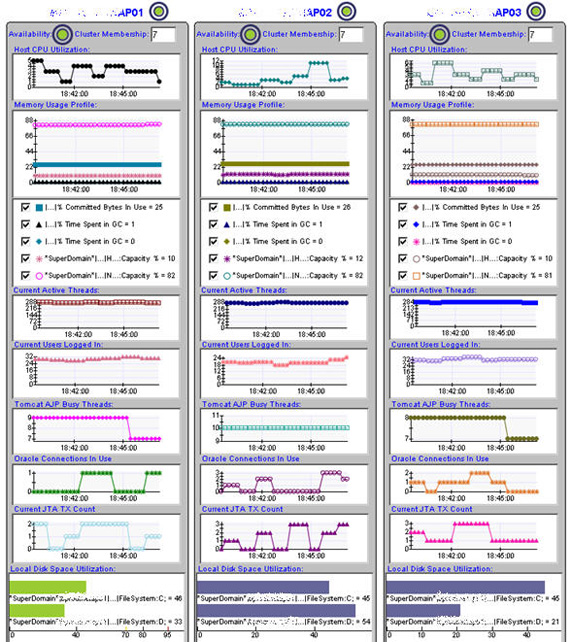
此處和附加的代碼中列出的示例都非常簡單,但一個 APM 系統顯然需要更高級和詳細的指示板。而且,大多數用戶都不希望從頭創建指示板。APM 系統通常擁有某種指示板生成器,允許用戶查看或搜索可用指標的存儲庫,並挑選要嵌入到指示板中的指標以及應該顯示的格式。圖 32 顯示了我使用 APM 系統創建的指示板的一部分:
圖 32. 指示板示例
結束語
現在,本系列 已經全部結束了。我提供了一些指導、一些常見的性能監控技術,以及您能夠實現的特定開發模式,可以使用這些模式增強或構建您自己的監控系統。收集和分析好的數據可以顯著提高應用程序的正常運行時間和性能。我鼓勵開發人員參與到監控生產應用程序的過程中來:要確定您編寫的軟件在負荷狀態下運行時實際發生了什麼,這是最好的信息來源。作為改進的一部分,這種反饋的價值不可估量。希望您的監控過程充滿樂趣!
致謝
非常感謝 Sandeep Malhotra 在 Web 服務收集器方面提供的幫助。