本系列文章第一部分分析了 Spring 解析 XML 配置文件中 <bean /> 元素的源碼,這是 Spring 最原始的一種配置方式,同時也使 XML 中的節點具有命名空間特性。參考 Spring 相關文檔,如果有如下的配置方式: <context:component-scan base-package="com.colorcc.spring.sample" /> 則可知:其一,該元素采用了"http://www.springframework.org/schema/context" 命名空間的配置方式。其二,針對 "com.colorcc.spring.sample" 包裡的每個對象,Spring 可能采用基於 Annotation 方式配置和解析對應的對象。說可能是因為還需要在相關 Java 代碼中使用如 @Component 及其子 Annotation 注解後才可以。
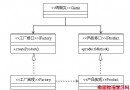
如上文的圖 2 所示,其右下角最後一個 Loop 順序圖即為 Annotation 配置解析 Bean 的入口,因此其詳細步驟可參考上文的圖 2 的分析。 XML Context 命名空間 bean 元素解析由上文的清單 6 可知,如果采用"http://www.springframework.org/schema/context" 命名空間,則執行"delegate.parseCustomElement(ele)" 方法進行 Bean 元素解析,其順序圖如圖 1 和圖 2 所示。
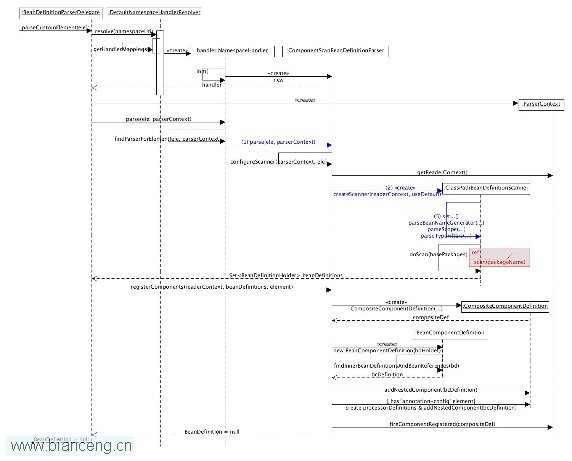
如果開發人員在 XML 文件中配置類似 <context:component-scan ... /> 元素時,其中 context 標識了對應的命名空間,而 component-scan 則具有占位符的功能,通過該占位符,Spring 框架可以定義對應的解析對象(如 component-scan 對應於 ComponentScanBeanDefinitionParser)進行具體的業務邏輯處理。
從 圖 1分析可知,Spring 框架遇到非默認命名空間定義的節點時,會根據該節點解析對應的命名空間對應的 URI。如果是第一次解析該命名空間,則會根據圖 1 描述找到對應的 schema 進行語法檢查。同時也會找到處理該命名空間對應的 Handler。如 context 對應的 handler 為 org.springframework.context.config.ContextNamespaceHandler,這是一個字符串,然後通過反射機制創建該字符串對應的 Java 對象。並緩存該對象供以後繼續使用。
步驟 2 得到的 handler 對象即為每個命名空間處理的 handler,也就是完成對 <context ... /> 的解析。當 handler 創建後,Spring 框架會調用其 init() 方法對其後面跟隨的占位符(如 component-scan 等)創建對應的工具類對象,通常以 Parser 結尾。同時 Spring 框架也會緩存該工具類供以後繼續使用。一個例子如 清單 1 所示。
public class ContextNamespaceHandler extends NamespaceHandlerSupport {
public void init() {
registerBeanDefinitionParser("property-placeholder",
new PropertyPlaceholderBeanDefinitionParser());
registerBeanDefinitionParser("property-override",
new PropertyOverrideBeanDefinitionParser());
registerBeanDefinitionParser("annotation-config",
new AnnotationConfigBeanDefinitionParser());
// component-scan 占位符對應 ComponentScanBeanDefinitionParser 對象
registerBeanDefinitionParser("component-scan",
new ComponentScanBeanDefinitionParser());
registerBeanDefinitionParser("load-time-weaver",
new LoadTimeWeaverBeanDefinitionParser());
registerBeanDefinitionParser("spring-configured",
new SpringConfiguredBeanDefinitionParser());
registerBeanDefinitionParser("mbean-export",
new MBeanExportBeanDefinitionParser());
registerBeanDefinitionParser("mbean-server",
new MBeanServerBeanDefinitionParser());
}
}
通過前述步驟,Spring 得到命名空間對應的 handler 對象集合。這樣就可以通過要解析的節點命名空間對應的占位符尋找其 parser 對象,如未找到,則報錯返回。根據清單 1 可知,對於 component-scan 占位符,其對應的 parser 對象為 ComponentScanBeanDefinitionParser 實例化後的對象(簡稱 csbdParser)。同時,delegate 會根據讀入的 XML 相關信息,實例化一個 ParserContext 對象用於存儲 xml, delegate 等上下文信息。這樣,NamespaceHandler 會根據傳入的節點元素和 ParserContext 信息,找到解析 XML 配置節點的解析對象 csbdParser,調用其 parse(element, parserContect) 方法進行解析 , 如圖 1 的 (1) 處所示。
parse 方法的處理可以簡單歸結為三個步驟:一、創建 Scanner 工具。 二、使用工具掃描 Java 對象,解析符合規則的 Bean 到對應 Bean Definition。三、對得到的 Bean Definitons進行處理。
csbdParser 根據 ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element); 創建一個 Scanner 工具,具體步驟如下: 6.1 根據圖 1 的(2)處所示,csbdParser 會 new 出一個 ClassPathBeanDefinitionScanner 對象 scanner,其傳入參數為 BeanDefinitionRegistry 對象和 boolean 類型參數 useDefaultFilters,前者即為 BeanFactory 對象,前文已經分析過,用於保存 Spring 解析出來的 Bean Definition對象的容器。後者提供給開發人員一個鉤子功能,由開發人員決定是否使用 Spring 框架提供的默認參數尋找滿足條件的 bean 並解析,默認情況為 true。 清單 2 列出了 Spring 框架定義的默認條件的 filters。從中可知通過 @Component、@javax.annotation.ManagedBean 和 @javax.inject.Named 以及標記了這些 Annotation 的新 Annotation 注解過的 Java 對象即為 Spring 框架通過 Annotation 配置的默認規則。 清單 2. Annotation 解析 Bean 定義的默認規則
// 定義默認情況下 filter 規則,凡是被 @Component、@ManagedBean、@Named 及被這些 Annotation
// 注解過的 Annotaion 注解的 Java 文件會被 Spring 框架使用 Annotation 方式處理其 Bean 定義
@SuppressWarnings("unchecked")
protected void registerDefaultFilters() {
// 將 @Component 加入到 filter 中
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl =
ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
// 將 @javax.annotation.ManagedBean 加入到 filter 中
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>)
cl.loadClass("javax.annotation.ManagedBean")), false));
logger.info("JSR-250 'javax.annotation.ManagedBean' found
and supported for component scanning");
}
catch (ClassNotFoundException ex) {
//JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
// 將 @javax.inject.Named 加入到 filter 中
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>)
cl.loadClass("javax.inject.Named")), false));
logger.info("JSR-330 'javax.inject.Named' annotation found and
supported for component scanning");
}
catch (ClassNotFoundException ex) {
//JSR-330 API not available - simply skip.
}
}
6.2 由類圖可知,scanner 繼承了 ClassPathScanningCandidateComponentProvider 對象。該對象提供了一些公共屬性的設置,如默認的掃描文件 Pattern 為"**/*.class",Pattern Resolver 為 PathMatchingResourcePatternResolverd 等。這裡需要特別注意的兩個重要的過濾器 includeFilters 和 excludeFilters,Spring 框架在掃描給定 pattern 的對象時,會根據 excludeFilters 過濾掉滿足條件的對象,然後才根據 includeFilters 過濾需要解析的對象。因此定義 Scanner 時可以根據這兩個過濾器實現開發人員自定義 Scanner 的過濾條件。 Scanner 自己也定義了一些工具類,如 BeanDefinitionDefaults 用於設置由 Annotation 方式解析 Bean 對象得到的 Bean Definition的默認屬性值;BeanNameGenerator 用於設置默認 beanName 屬性等。
6.3 創建了 Scanner 後,Spring 框架會根據一些業務邏輯設置一些屬性供以後使用,如圖 1 的 (3) 處。
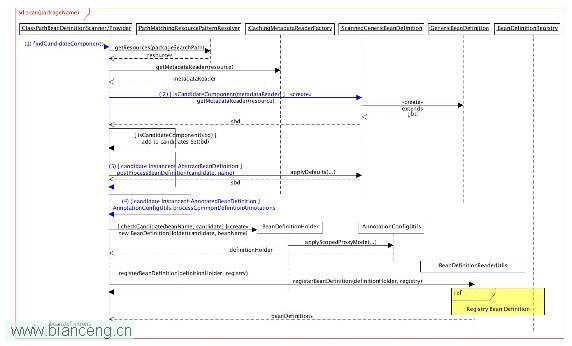
步驟 6 創建了一個工具類 scanner, 同時 Spring 框架也會得到開發人員配置的 base-package 屬性值。這樣 csbdParser 會執行 Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages); 來掃描 basePackages 裡滿足條件的 bean 定義,並生成對應的 Bean Definition,如圖 2 所示。具體分析如下:
7.1 Scanner 首先會定義一個 Set<BeanDefinitionHolder> 容器,用於存放解析每個 bean 對應的 BeanDefinitionHolder 對象。
7.2 傳入的 basePackages 如果以",;"形式分隔,則分割 basePackages 字符串為 String 數組,並循環每個元素,執行後面操作。
查看本欄目
7.3 如圖 2 的 (1) 所示,該循環首先通過 findCandidateComponents 方法根據一定的規則構造 Spring 框架需要加載的 class 文件 pattern,如 basePackage 為 com.colorcc.spring.sample 構造的需要加載的 class 文件 pattern 為 :classpath*:com/colorcc/spring/sample/**/*.class。這樣 Spring 框架會將滿足條件的 class 文件加載並轉換為 Resource 類型對象,返回給 scanner。
7.4 針對得到的每個 Resource 對象,通過 ASM 工具分析其 Annotation 元素,構造 MetadataReader 對象,並將 annotation 信息封裝到 AnnotationMetadata 類型的 annotationMetadata 屬性中。
7.5 針對上步得到的 MetadataReader 對象,根據 annotationMetadata 屬性,如上文 6.2 的描述,如滿足 excludeFilters 過濾器條件,則直接返回,不再解析。反之,如滿足 includeFilters 過濾器條件(默認情況即為被 6.1 描述的 annotation 標記過),則繼續後續步驟。
7.6 使用經過上步過濾後得到的 MetadataReader 對象作為構造函數的參數,創建 ScannedGenericBeanDefinition 對象 sbd。根據類圖(如上文圖 5 所示),其直接繼承 GenericBeanDefinition 對象,因此其具有上一章分析的所有 GenericBeanDefinition 對象的屬性值。同時 sdb 義了一個 AnnotationMetadata 屬性,保存了 MetadataReader 對象中關於 Annotation 元數據的一些信息。並且 sbd 的 beanClass 屬性也是通過 Annotation 元數據得到並設置的。
7.7 得到的 sbd 返回給 scanner,通過 scanner 設置其一些屬性如 resource 和 source 等。同時判斷該 sbd 的屬性若為非接口,非抽象類且子類方法可重寫,則加入到一個 Set 集合 candidates 中。反之循環下一個 resource 繼續進行 7.4-7.7 的業務處理。
7.8 針對所有的開發人員定義的 package,進行 7.3-7.7 的處理,得到所有滿足 Annotation 解析的 bean 元素的結合 candidates。
7.9 循環 7.8 得到的每個 candidate,如果其是 AbstractBeanDefinition 類型,則根據 6.2 定義的 BeanDefinitionDefaults 對象設置 candidate 的一些默認屬性,如圖 2 的 (3) 處所示。
如果 candidate 是 AnnotatedBeanDefinition 類型,則得到其 Annotation 元數據,並根據該元數據中的 annotation 設置 candidate 的一些屬性,如被 @Primary 標識,則設置 candidate 的 primary 屬性為 true,其他 annotation 還包括 @Lazy、@DependsOn 和 @Role 等。
7.10 查詢 registory 的 beanDefinitionMap 屬性容器,如果其不包含 candidate 的 beanName 元素,則通過 candidate 及其 beanName 構造一個 BeanDefinitionHolder 對象,將該對象加入到 7.1 創建都容器中。
7.11 最後一步就是將得到的 beanDefinitionHolder 解析並注冊到 registry 中。該步驟與上文圖 4 黃色背景的的順序圖片段(sd Registry Bean Definition)完全一致。具體分析可參考前文。
csbdParser 最後一步需要完成的操作是將得到的每個 BeanDefinitionHolder 通過 registerComponents(parserContext.getReaderContext(), beanDefinitions, element); 做一些收尾的處理,如圖 1 的右下角部分所示。具體分析如下:
8.1 框架根據 BeanDefinitionHolder 的 BeanDefinition 屬性構造一個 BeanComponentDefinition 對象,該對象繼承 BeanDefinitionHolder,定義了兩個私有屬性 innerBeanDefinitions 和 beanReferences ,用於存放每個 bean 元素解析時所引用的嵌套 bean 和引用 bean 對象。
8.2 根據 XML 配置的 element 信息,定義一個容器 CompositeComponentDefinition 用於存放每個 BeanComponentDefinition 對象。
8.3 默認情況下,將 ConfigurationClassPostProcessor、AutowiredAnnotationBeanPostProcessor、RequiredAnnotationBeanPostProcessor、CommonAnnotationBeanPostProcessor 等通用 processor 也解析成對應的 BeanDefinitionHolder 並加入到 8.2 創建的 CompositeComponentDefinition 容器中。
8.4 類似前文,Spring 框架發送一個 ReaderEventListener 事件。默認情況下,該事件為 EmptyReaderEventListener 對象的 componentRegistered 事件,這是一個空事件,沒有具體的業務邏輯。
前文分析了基於 XML 和 Annotation 配置 Beam Definition的源碼實現。從 Spring3.0 開始,增加了一種新的途經來配置 Bean Definition,這就是通過 Java Code 配置 Bean Definition。與前兩種配置方式不同點在於:
前兩種配置方式為預定義方式,即開發人員通過 XML 文件或者 Annotation 預定義配置 bean 的各種屬性後,啟動 Spring 容器,Spring 容器會首先解析這些配置屬性,生成對應都 Bean Definition,裝入到 DefaultListableBeanFactory 對象的屬性容器中去。與此同時,Spring 框架也會定義一些內部使用的 Bean 定義,如 bean 名為”org.springframework.context.annotation.internalConfigurationAnnotationProcessor”的 ConfigurationClassPostProcessor 定義。
而後者此刻不會做任何 Bean Definition 的定義解析動作,Spring 框架會根據前兩種配置,過濾出 BeanDefinitionRegistryPostProcessor 類型的 Bean 定義,並通過 Spring 框架生成其對應的 Bean 對象(如 ConfigurationClassPostProcessor 實例)。結合 Spring 上下文源碼可知這個對象是一個 processor 類型工具類,Spring 容器會在實例化開發人員所定義的 Bean 前先調用該 processor 的 postProcessBeanDefinitionRegistry(...) 方法。此處實現基於 Java Code 配置 Bean Definition的處理。
由上文圖 5 可知,Spring 框架定義了一系列 Bean Definition對象,通過 XML 配置方式定義的 Bean 屬性,經 Spring 框架解析後會封裝成 GenericBeanDefinition 對象,然後注冊到 DefaultListableBeanFactory 對象的屬性容器中去。通過 Annotation 配置方式定義的 Bean 屬性經 Spring 框架解析後會封裝成 ScannedGenericBeanDefinition 對象(即 GenericBeanDefinition 對象增加了 AnnotationMetadata 屬性),然後注冊到 DefaultListableBeanFactory 對象的屬性容器中去。RootBeanDefinition 類類似 GenericBeanDefinition,都是 AbstractBeanDefinition 的實現類,其額外定義了一些屬性如 externallyManagedConfigMembers,externallyManagedInitMethods 以及 constructorArgumentLock 等,供 Spring 框架將 Bean Definition實例化為 Java 對象時使用。通過 Java Code 配置的 Bean Definition經 Spring 框架解析後會封裝成 ConfigurationClassBeanDefinition 對象(RootBeanDefinition 對象增加了 AnnotationMetadata 屬性), 然後注冊到 DefaultListableBeanFactory 對象的屬性容器中去。
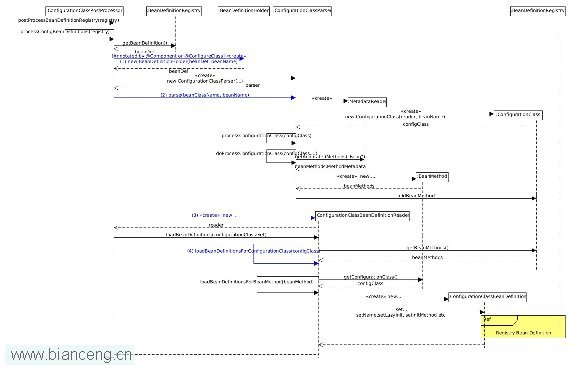
圖 3 展示了基於 Java Code 解析 Bean 的順序圖。簡單分析如下:
根據前文分析,該順序圖的入口為 ConfigurationClassPostProcessor 的 postProcessBeanDefinitionRegistry(BeanDefinitionRegistry reigistry) 方法。
步驟 1 首先注冊一個工具類 ImportAwareBeanPostProcessor 的 Bean 定義到 reigsitry 中去。然後處理 resistry 已有的 Bean Definition。
至圖 3 的步驟 (1) 處,Spring 框架順序掃描每個 Bean Definition,如果被掃描的 Bean Definition 被 @Commponent 及其子注解或者 @ConfigureClass 注解過,則加入到類型為 Set<BeanDefinitionHolder> 的 configCandidates 容器中。如果容器為空,則表示不存在通過 Java Code 配置的 Bean 定義,直接返回。否則,執行步驟 4。
Spring 框架根據 registry 及自定義的一系列屬性如 environment、resourceLoader 等,創建 Bean 解析的工具類 ConfigurationClassParser 對象 parser,然後使用該工具類解析 configCandidates 容器中每個 Bean Definition,如圖 3 的 (2) 處所示。該處掃描 Bean Definition,將所有被 @Bean 注解過的 method 方法及所屬 class 信息封裝成 BeanMethod 對象,並裝入 class 的屬性容器中。最終將處理過的 class 對象裝入 parser 容器中。
Spring 框架根據 registry 及子定義的一系列屬性創建工具類 ConfigurationClassBeanDefinitionReader 對象 reader, 該工具類負責解析 parser 容器中每個 class 的 bean 信息,如圖 3 的 (3) 處所示。
步驟 4 的 parser 和步驟 5 的 reader 區別在於:parser 負責解析被特定 annotation 注解過的 class 對象的被注解 @Bean 注解過的 method 封裝為 BeanMethod 對象。而 reader 負責將每個 BeanMethod 對象解析為 Bean Definition。
有了前述知識,圖 3 的 (3) 處解析將非常簡單。首先通過 parser 找到步驟 4 解析的每個 class 對象,然後以該對象為參數,調用 reader 的 loadBeanDefinitions(class) 方法,如圖 3 的 (4) 處。
步驟 6 的方法會循環其每個被 @Bean 注解過的方法對象 BeanMethod,針對每個 BeanMethod,首先會以 class 為參數,創建一個 ConfigurationClassBeanDefinition 對象 ccbd(這是一個帶有 AnnotationMeta 元數據的 RootBeanDefinition)code type="inline">,設置一些自身屬性。然後將方法名設置為 ccbd 的一個 factory name,再根據 BeanMethod 的 annotation 信息如 autowired、initMethod 以及 destroyMethod 等設置 ccbd 的相關屬性值。
類似前述步驟,將得到的 ccbd 注冊到 rigistry 的屬性容器中去。該步驟與上文圖 4 黃色背景的的順序圖片段(sd Registry Bean Definition)完全一致。具體分析可參考前文。
小結
本文詳細分析了 Spring 框架解析開發人員定義的 Bean 到 Spring 容器的 Bean Definition對象的處理過程。
基於 XML 配置方式是最原始也是使用最普遍的一種方法,其優點在於將配置集中在一起(XML 配置文件中),且與 Java 代碼分離,方便管理。對於配置文件的改變,不需要重新編譯源代碼,極大的提高了開發效率。其缺點在於對大型基於 Spring 配置的項目,冗余的 XML 配置較多,增加了開發的工作量和維護成本。
基於 Annotation 配置方式是隨著 JDK 對 Annotation 支持新引入的一種配置方法,其優點在於可以減少開發人員的工作量,保證代碼的整潔性。而其缺點在於與 Java 代碼結合,同時配置信息散入到每個 Java 文件中,對新加入項目的開發人員,需要一定的學習成本,另外,基於 Annotation 不能實現所有基於 XML 配置的元數據信息。
基於 Java Code 的配置方式,其執行原理不同於前兩種。它是在 Spring 框架已經解析了基於 XML 和 Annotation 配置後,通過加入 BeanDefinitionRegistryPostProcessor 類型的 processor 來處理配置信息,讓開發人員通過 Java 編程方式定義一個 Java 對象。其優點在於可以將配置信息集中在一定數量的 Java 對象中,同時通過 Java 編程方式,比基於 Annotation 方式具有更高的靈活性。並且該配置方式給開發人員提供了一種非常好的范例來增加用戶自定義的解析工具類。其主要缺點在於與 Java 代碼結合緊密,配置信息的改變需要重新編譯 Java 代碼,另外這是一種新引入的解析方式,需要一定的學習成本。