為了後面的tree grammar更簡潔,本篇對上一篇的樹重寫規則和一些語法細節做了些調整。並且,將 生成的lexer和parser的源碼目標換到了CSharp2,以便後面能使用一些.NET的庫。
要使用CSharp2的目標,需要從官網下載相應的運行時庫。當前的最新版是3.1.1,可以從這裡獲取。 CSharp/CSharp2目標的詳細情況,可以查閱官網上的文檔。以上一篇的語法為基礎,要換到CSharp2目標 只要把幾個嵌入動作裡的System.out.println換成Console.WriteLine,把toStringTree換成 ToStringTree,把clear換成Clear就可以了。編譯的時候至少需要引用Antlr3.Runtime.dll。
那麼除去更換生成目標帶來的影響,這次做了些怎樣的修改呢?
首先,語法做了些細微的調整。例如說,program規則從原本允許沒有語句到現在要求至少有一條語句 ;blockStatement為空block寫了條專門的分支;expressionStatement也添加了一個EXPR_STMT的虛構 token為根節點,等等。
變化最大的還是variableDeclaration及相關規則。上一篇裡這條規則的重寫規則並不區分有初始化與 無初始化、簡單類型與數組類型的區別;本篇裡則將這兩個區別都明確的寫在了重寫規則裡,以不同的虛 構token來作為生成的樹的根節點。這樣,到寫後面的tree grammar的時候,需要的lookahead數就可以減 少。
ANTLR所生成的AST,以深度優先的方式遍歷,可以看做一個一維的流:每一層父子關系都可以表示為 :
root -> "down" -> element1 -> element2 -> ... -> elementN -> "up" -> ...
其中"down"和"up"是ANTLR插入的虛構token,用於指定樹的層次。
這樣,後面使用tree grammar來遍歷AST時,實際上遍歷的就是這樣一個一維的流 (CommonTreeNodeStream)。所以我們也可以把tree grammar看做是隱含了"down"和"up"虛構token的普 通parser grammar。那麼,tree grammar中需要的lookahead個數的分析,也就跟parser grammar的一樣 。
看看下面的例子。對於上一篇variableDeclaration的重寫規則中出現的變量聲明的類型,可以用這樣 的tree grammar來匹配:
Java代碼
type : ^( SIMPLE_TYPE INT ) | ^( SIMPLE_TYPE REAL ) | ^( ARRAY_TYPE INT Integer+ ) | ^( ARRAY_TYPE REAL Integer+ ) ;
樹語法的^( ... )就隱含了"down"和"up"這兩個虛構token。實際上這條規則匹配的是:
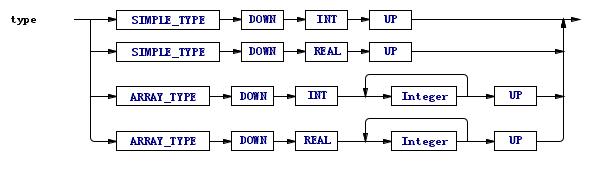
可以很清楚的看到"down"和"up"在規則中的位置。
在進入這條規則之後,需要多少個lookahead才足以判斷應該選擇哪條分支呢?
向前看一位:只能排除掉兩個分支,還有兩個,不夠;
向前看兩位:第二位是什麼呢?四個分支裡第二位都是"down"節點,對判斷分支沒幫助,還是不夠用 ;
向前看三位:SIMPLE和ARRAY、INT和REAL都能分開了,足夠。
那麼對這條規則而言,需要2個lookahead。閱讀ANTLR生成的源碼,可以看到input.LA(3)這樣的調用 ,表示向前看第三位的token。每多一個lookahead,生成的代碼就得多以層嵌套的if-else,很是麻煩。
如果能調整一下parser這邊生成的AST的結構,讓tree grammar那邊能寫成:
Java代碼
simpleType : INT | REAL ; arrayType : ^( INT Integer+ ) | ^( REAL Integer+ ) ;
那麼這兩條規則都只需要1個lookahead就足以判斷分支了,比原本的寫法要簡單,也會稍微快一些。 寫了個Ruby腳本來檢查生成的源碼裡用的lookahead的個數(*):
Ruby代碼
1.def check_lookaheads(file)
2. lookaheads = open file, 'r' do |f|
3. ret = []
4. f.readlines.grep(/^\s+(.+\.la\((\d+)\).+)$/i) do
5. ret << "#{$2}: #{$1}"
6. end
7. ret
8. end
9.end
10.
11.if __FILE__ == $0
12. la = check_lookaheads ARGV[0] || 'JerryParser.cs'
13. puts 'Lookaheads:', la, ''
14. puts "Non-LL(1)'s:", la.select { |l| ?1 != l[0] }
15.end
明白了這個道理,就應該盡量將重寫規則中的各個根節點設計成能直接區分的。
實際上不只是樹的語法,在編程語言的源碼的語法設計上也是一樣:最容易解析的語法是每條規則都 以特殊的token開頭的語法,例如說聲明變量就以var關鍵字開頭,聲明函數就以function關鍵字開頭等。 這樣能保證語法只需要1個lookahead。而類似C的語法對解析器來說實在算不上友善……|||
(*:ANTLR在遇到比較復雜的判斷條件時不會直接在規則對應的方法裡調用input.LA(n),而是會生成 一個DFA類來計算應該走的分支。上面的Ruby腳本不檢查這個狀況。)
其次,所有虛構token都添加了一些信息在後面。例如說原本一元負號的規則是:
Java代碼
MINUS primaryExpression -> ^( UNARY_MINUS primaryExpression )
則UNARY_MINUS這個虛構token將不包含任何文字、位置信息。因為MINUS原本攜帶的位置信息已經丟失 了,所以如果後續處理中需要知道這個表達式的位置就沒辦法得到。
改寫為這樣:
Java代碼
MINUS primaryExpression -> ^( UNARY_MINUS[$MINUS] primaryExpression )
則使得UNARY_MINUS繼承MINUS匹配時的文字、位置等屬性,解決了前面的問題。
除此之外,原本寫在program規則裡的嵌入動作也去掉了。之前寫在那裡主要是為了在parser內輸出 AST的字符串表示,只是演示用。
修改後的完整語法如下:
C#代碼
1.grammar Jerry;
2.
3.options {
4. language = CSharp2;
5. output = AST;
6. ASTLabelType = CommonTree;
7.}
8.
9.tokens {
10. // imaginary tokens
11. SIMPLE_VAR_DECL;
12. SIMPLE_VAR_DECL_INIT;
13. ARRAY_VAR_DECL;
14. ARRAY_VAR_DECL_INIT;
15. ARRAY_LITERAL;
16. SIMPLE_VAR_ACCESS;
17. ARRAY_VAR_ACCESS;
18. UNARY_MINUS;
19. BLOCK;
20. EMPTY_BLOCK;
21. EXPR_STMT;
22.}
23.
24.// parser rules
25.
26.program : statement+ EOF!
27. ;
28.
29.statement
30. : expressionStatement
31. | variableDeclaration
32. | blockStatement
33. | ifStatement
34. | whileStatement
35. | breakStatement
36. | readStatement
37. | writeStatement
38. ;
39.
40.expressionStatement
41. : expression SEMICOLON
42. - > ^( EXPR_STMT[$expression.start, "ExprStmt"] expression )
43. ;
44.
45.variableDeclaration
46. : typeSpecifier
47. ( id1=Identifier
48. ( ( -> ^( SIMPLE_VAR_DECL[$id1, "VarDecl"] ^( typeSpecifier ) $id1 ) )
49. | ( EQ expression
50. -> ^( SIMPLE_VAR_DECL_INIT[$id1, "VarDeclInit"] ^( typeSpecifier ) $id1 expression ) )
51. | ( ( LBRACK Integer RBRACK )+
52. -> ^( ARRAY_VAR_DECL[$id1, "VarDecl"] ^( typeSpecifier Integer+ ) $id1 ) )
53. | ( ( LBRACK Integer RBRACK )+ EQ arrayLiteral
54. -> ^( ARRAY_VAR_DECL_INIT[$id1, "VarDeclInit"] ^( typeSpecifier Integer+ ) $id1 arrayLiteral ) )
55. )
56. )
57. ( COMMA id2=Identifier
58. ( ( -> $variableDeclaration ^( SIMPLE_VAR_DECL[$id2, "VarDecl"] ^( typeSpecifier) $id2 ) )
59. | ( EQ exp=expression
60. -> $variableDeclaration ^( SIMPLE_VAR_DECL_INIT [$id2, "VarDeclInit"] ^( typeSpecifier ) $id2 $exp ) )
61. | ( ( LBRACK dim1+=Integer RBRACK )+
62. -> $variableDeclaration ^( ARRAY_VAR_DECL[$id2, "VarDecl"] ^( typeSpecifier $dim1+ ) $id2 ) )
63. | ( ( LBRACK dim2+=Integer RBRACK )+ EQ al=arrayLiteral
64. - > $variableDeclaration ^( ARRAY_VAR_DECL_INIT[$id2, "VarDeclInit"] ^( typeSpecifier $dim2+ ) $id2 $al ) )
65. )
66. { if (null != $dim1) $dim1.Clear(); if (null != $dim2) $dim2.Clear(); }
67. )*
68. SEMICOLON
69. ;
70.
71.typeSpecifier
72. : INT | REAL
73. ;
74.
75.arrayLiteral
76. : LBRACE
77. arrayLiteralElement ( COMMA arrayLiteralElement )*
78. RBRACE
79. -> ^( ARRAY_LITERAL [$LBRACE, "Array"] arrayLiteralElement+ )
80. ;
81.
82.arrayLiteralElement
83. : expression
84. | arrayLiteral
85. ;
86.
87.blockStatement
88. : LBRACE statement+ RBRACE
89. -> ^( BLOCK[$LBRACE, "Block"] statement+ )
90. | LBRACE RBRACE // empty block
91. -> EMPTY_BLOCK[$LBRACE, "EmptyBlock"]
92. ;
93.
94.ifStatement
95. : IF^ LPAREN! expression RPAREN! statement ( ELSE! statement )?
96. ;
97.
98.whileStatement
99. : WHILE^ LPAREN! expression RPAREN! statement
100. ;
101.
102.breakStatement
103. : BREAK SEMICOLON!
104. ;
105.
106.readStatement
107. : READ^ variableAccess SEMICOLON!
108. ;
109.
110.writeStatement
111. : WRITE^ expression SEMICOLON!
112. ;
113.
114.variableAccess
115. : Identifier
116. ( -> ^( SIMPLE_VAR_ACCESS[$Identifier, "VarAccess"] Identifier )
117. | ( LBRACK Integer RBRACK )+
118. -> ^( ARRAY_VAR_ACCESS[$Identifier, "VarAccess"] Identifier Integer+ )
119. )
120. ;
121.
122.expression
123. : assignmentExpression
124. | logicalOrExpression
125. ;
126.
127.assignmentExpression
128. : variableAccess EQ^ expression
129. ;
130.
131.logicalOrExpression
132. : logicalAndExpression ( OROR^ logicalAndExpression )*
133. ;
134.
135.logicalAndExpression
136. : relationalExpression ( ANDAND^ relationalExpression )*
137. ;
138.
139.relationalExpression
140. : additiveExpression ( relationalOperator^ additiveExpression )?
141. | BANG^ relationalExpression
142. ;
143.
144.additiveExpression
145. : multiplicativeExpression ( additiveOperator^ multiplicativeExpression )*
146. ;
147.
148.multiplicativeExpression
149. : primaryExpression ( multiplicativeOperator^ primaryExpression )*
150. ;
151.
152.primaryExpression
153. : variableAccess
154. | Integer
155. | RealNumber
156. | LPAREN! expression RPAREN!
157. | MINUS primaryExpression
158. -> ^( UNARY_MINUS[$MINUS] primaryExpression )
159. ;
160.
161.relationalOperator
162. : LT | GT | EQEQ | LE | GE | NE
163. ;
164.
165.additiveOperator
166. : PLUS | MINUS
167. ;
168.
169.multiplicativeOperator
170. : MUL | DIV
171. ;
172.
173.// lexer rules
174.
175.LPAREN : '('
176. ;
177.
178.RPAREN : ')'
179. ;
180.
181.LBRACK : '['
182. ;
183.
184.RBRACK : ']'
185. ;
186.
187.LBRACE : '{'
188. ;
189.
190.RBRACE : '}'
191. ;
192.
193.COMMA : ','
194. ;
195.
196.SEMICOLON
197. : ';'
198. ;
199.
200.PLUS : '+'
201. ;
202.
203.MINUS : '-'
204. ;
205.
206.MUL : '*'
207. ;
208.
209.DIV : '/'
210. ;
211.
212.EQEQ : '=='
213. ;
214.
215.NE : '!='
216. ;
217.
218.LT : '<'
219. ;
220.
221.LE : '<='
222. ;
223.
224.GT : '>'
225. ;
226.
227.GE : '>='
228. ;
229.
230.BANG : '!'
231. ;
232.
233.ANDAND : '&&'
234. ;
235.
236.OROR : '||'
237. ;
238.
239.EQ : '='
240. ;
241.
242.IF : 'if'
243. ;
244.
245.ELSE : 'else'
246. ;
247.
248.WHILE : 'while'
249. ;
250.
251.BREAK : 'break'
252. ;
253.
254.READ : 'read'
255. ;
256.
257.WRITE : 'write'
258. ;
259.
260.INT : 'int'
261. ;
262.
263.REAL : 'real'
264. ;
265.
266.Identifier
267. : LetterOrUnderscore ( LetterOrUnderscore | Digit )*
268. ;
269.
270.Integer : Digit+
271. ;
272.
273.RealNumber
274. : Digit+ '.' Digit+
275. ;
276.
277.fragment
278.Digit : '0'..'9'
279. ;
280.
281.fragment
282.LetterOrUnderscore
283. : Letter | '_'
284. ;
285.
286.fragment
287.Letter : ( 'a'..'z' | 'A'..'Z' )
288. ;
289.
290.WS : ( ' ' | '\t' | '\r' | '\n' )+ { $channel = HIDDEN; }
291. ;
292.
293.Comment
294. : '/*' ( options { greedy = false; } : . )* '*/' { $channel = HIDDEN; }
295. ;
296.
297.LineComment
298. : '//' ~ ('\n'|'\r')* '\r'? '\n' { $channel = HIDDEN; }
299. ;
同上一篇一樣,也寫一個啟動lexer和parser的程序。這次是用C#來寫:
C#代碼
using System;
using System.IO;
using Antlr.Runtime; // Antlr3.Runtime.dll
using Antlr.Runtime.Tree;
using Antlr.Utility.Tree; // Antlr3.Utility.dll
sealed class TestJerryAst {
static void PrintUsage( ) {
Console.WriteLine( "Usage: TestJerryAst [-dot] <source file>" );
}
static void Main( string[] args ) {
bool generateDot = false;
string srcFile;
switch ( args.Length ) {
case 0:
PrintUsage( );
return;
case 1:
if ( !File.Exists( args[ 0 ] ) ) goto case 0;
srcFile = args[ 0 ];
break;
default:
if ( "-dot" == args[ 0 ] ) {
generateDot = true;
if ( !File.Exists( args[ 1 ] ) ) goto case 0;
srcFile = args[ 1 ];
} else {
goto case 1;
}
break;
}
var input = new ANTLRReaderStream( File.OpenText( srcFile ) );
var lexer = new JerryLexer( input );
var tokens = new CommonTokenStream( lexer );
var parser = new JerryParser( tokens );
var programReturn = parser.program();
var ast = ( CommonTree ) programReturn.Tree;
// Generate DOT diagram if -dot option is given
if ( generateDot ) {
var dotgen = new DOTTreeGenerator( );
var astDot = dotgen.ToDOT( ast );
Console.WriteLine( astDot );
} else {
Console.WriteLine( ast.ToStringTree( ) );
}
}
}
因為使用了DOTTreeGenerator,編譯時記得在引用Antlr3.Runtime.dll之外,還需要引用 Antlr3.Utility.dll與StringTemplate.dll。
繼續使用前兩篇用過的Jerry代碼為例子:
C代碼
// line comment
// declare variables with/without initializers
int i = 1, j;
int x = i + 2 * 3 - 4 / ( 6 - - 7 );
int array[2][3] = {
{ 0, 1, 2 },
{ 3, 4, 6 }
};
/*
block comment
*/
while (i < 10) i = i + 1;
while (!x > 0 && i < 10) {
x = x - 1;
if (i < 5) break;
else read i;
}
write x - j;
通過上面的程序,可以得到這樣的AST:

上面的程序生成的是.dot文件(輸出到標准輸出流上)。使用Graphviz的dot,將這個文件以
Java代碼
dot JerrySample.dot -Tpng -o JerrySample.png
這樣的命令來轉換,就能得到PNG圖像。
本篇就到這裡。下一篇看看遍歷AST用的基本tree grammar。