簡介:
Java Persistence API(JPA)是 EJB 3.0 新引入的數據持久化編程模型,它 利用 Java 5 中的注釋(Annotation)和對象/關系映射,為數據持久化提供了更 簡單、易用的編程方式。 本系列 文章將全面介紹其開源實現 — Apache OpenJPA,將為學習 JPA 標准和使用 OpenJPA 進行實際的應用開發提供詳細的指 南。
本文是系列文章的第一部分,概述了關系型數據庫和面向對象之間的阻抗失諧 (impedance mismatch),介紹了 EJB 3.0 JPA 標准的相應解決方案,並對 OpenJPA 進行了初步介紹。
關系型數據庫與面向對象
幾乎所有的企業應用都需要持久化數據,沒有數據持久化需求的企業應用在現 在的市場環境下幾乎是不可能出現的。由於關系型數據的普及,通常我們提到數 據持久化時,一般指的是將數據持久化到關系型數據庫中。關系型數據是一種結 構化的數據管理方式,開發者只能通過 SQL 來操作數據庫。
Java 語言天生就是一門面向對象的編程語言,在 Java 的世界中,被處理的 內容都被組織成一個一個的對象,對象和對象之間存在著繼承、引用關系,這樣 的關系無法通過簡單的方式直接反應到關系型數據庫中。因此在關系型數據庫與 面向對象之間便存在著阻抗失諧(impedance mismatch)。
我們通過一個簡單的例子來說明這種阻抗失諧給企業應用開發者帶來的困難。 假設在企業應用中存在三個 Java 類:Animal、Fish 和 Dog,其中 Fish、Dog 都是 Animal 的子類。在 Java 世界中,Fish、Dog 都可以被作為 Animal 對象 處理。但是如果我們換到關系型數據庫中,這三個對象通常都保存在各自對應的 表中,假設分別對應 Animal 表、Fish 表和 Dog 表,如果要維護 Animal 和 Fish 的繼承關系,我們就需要使用 SQL 的聯合查詢語句查出 Animal 的所有屬 性和 Fish 的所有屬性,並且使用某種外鍵進行關聯:
Select animal.*,fish.* form animal,fish where animal.id = fish.id
從這個簡單的例子中我們就可以看出,一個企業應用開發者需要同時掌握面向 對象和關系型數據庫的兩種思想,而且還必須保證它們之間的映射是正確的,否 則無法保證企業應用的正確性,這對於企業應用開發者是個挑戰,因此 Java 社 區一直在尋求如何將面向對象和關系型數據庫思想簡單的統一起來的途徑,這方 面的努力促進了持久化技術的發展。
發展中的持久化技術
持久化是企業應用開發的核心需求之一,最近幾年以來,它也成為 Java 社區 中最熱門的話題之一,在 Java 社區努力解決持久化數據管理的過程中,曾經湧 現出了非常多的技術方案試圖解決這個問題,從最早的序列化,到 JDBC、JDO、 ORM、對象數據庫、EJB 2.X,然而這些技術都存在著各種各樣的局限,影響他們 成為最好的選擇。下面我們簡單的回顧一下 Java 社區中那些曾經試圖為持久化 數據管理提供完整解決方案的技術。
序列化
序列化是最早出現的、管理持久化數據的實現方案,也是 Java 語言中內置的 數據持久化解決方案。它的工作原理是將對象轉化為字節流,生成的字節流能夠 通過網絡傳輸或者保存在文件中。序列化非常易於使用,但是局限性也非常大, 由於序列化必須一次將所有對象全部取出,這限制了它在處理大量數據情形下的 應用,同時它也無法在更新失敗的情況下撤銷對對象的修改,這使它無法用於對 數據一致性要求嚴格的應用中。多線程或者多個應用不能同時並發地、互不沖突 地讀寫同一個序列化數據,也不能提供查詢功能。
JDBC
很多企業應用的開發者選擇使用 JDBC 管理關系型數據庫中的數據。相對序列 化而言,JDBC 克服了很多缺點:它支持處理大量的數據,能夠保證數據的一致性 ,支持信息的並發訪問,提供 SQL 查詢語言查找數據。不幸的是,JDBC 沒有提 供序列化所具有的易用性。JDBC 所使用的關系模型不是為保存對象而設計的,因 此迫使開發者選擇在處理持久數據時放棄面向對象編程,或者自己去開發將面向 對象特性(比如:類之間的繼承)和關系型數據庫進行映射的專有解決方案。
關系對象映射(Object Relational Mapping,ORM)
ORM 是目前完成對象和關系數據表之間的映射最好的一種技術, 這些 ORM 框 架處理對象和關系數據庫之間的協調工作,將開發者從這部分工作中解脫出來, 集中精力處理對象模型。阻礙 ORM 發展的問題是,現有的每一種 ORM 產品都有 自己特有的 API,開發者只能將自己的代碼綁定到某一個框架提供商的接口上, 這種狀況形成了廠商鎖定,意味著一旦該框架提供商無法解決系統中出現的嚴重 錯誤,或者因為其它的原因轉而采用其它的框架,將會給開發者的企業應用帶來 極大的困難,唯一的解決辦法是重寫所有的持久化代碼。
對象數據庫(Object DataBase)
已經有一些軟件公司選擇了開發為保存對象而特別設計的對象數據庫,而不是 選擇將對象映射到關系型數據庫上。這種解決方案通常比使用對象/關系映射更加 易於使用。和 ORM 相同的問題是,對象數據庫的訪問接口並沒有標准化,因此非 常容易形成廠商鎖定的局面。與此同時,放棄已經成熟的關系數據庫而轉向未知 的對象數據庫讓非常多的企業決策者猶豫不決。而且目前為對象數據庫而設計的 分析工具太少,無法滿足企業的需求。而且現實情況下,每一個企業基本上都有 大量的已有數據保存在關系數據庫中,要從關系數據庫轉向對象數據庫對企業而 言也需要大量工作。
EJB 2.X
EJB 2.X 實體 Bean 是管理持久化數據的組件框架,和 ORM 解決方案一樣, EJB 2.X 實體 Bean 提供持久化數據的面向對象視圖。和 ORM 解決方案不一樣的 是,EJB 2.X 實體 Bean 不僅僅局限於數據庫,它展示的信息可能來自於 EIS (Enterprise Information System)或者其他持久化設備。EJB 2.X 實體 Bean 最大的局限是規定了太過於嚴格的標准,這些標准保證了企業應用能夠在不同的 EJB 容器之間可以移植,但是也讓 EJB2.X 實體 Bean 規范變得非常復雜並難於 使用。而且 EJB 2.X 標准在面向對象特性處理方面的支持非常有限,無法支持繼 承、多態和復雜關系等面向對象的高級特性。EJB 2.X 實體 Bean 只能在重量級 的、價格昂貴的 EJB 容器中運行,這對應用 EJB 2.X 實體 Bean 開發企業應用 提出了更高的要求,加重了企業的經濟壓力。
Java 數據對象(Java Data Object,JDO)
JDO 是 Java EE 標准中另外一個支持管理持久化數據的規范,JDO 規范使用 和 JPA 非常類似的 API,只是通常是通過 JCA 技術集成到應用服務器上。但是 JDO 是針對輕量級容器而設計的,不能夠支持容器級別的聲明式安全、事務特性 ,也無法對遠程方法調用提供支持。
EJB 3.0 規范
2006 年 5 月 2 日,EJB 3.0 規范最終版由 JCP(Java Community Process ) 正式公布,標准號為 JSR(Java Specification Request)220。EJB 3.0 規 范的發布為企業應用開發者提供了一種全新的、簡化的 API。制定這組 API 的目 標是讓開發變得更加容易,相對於以前版本的 EJB 規范,這組 API 也更加簡單 。Java Persistence API 是 EJB 3.0 中負責處理持久化數據管理的部分,目標 是為開發者處理持久化數據庫管理提供標准支持,也成為 Java EE 容器提供商必 須遵守的標准。
EJB 3.0 規范由三部分組成:EJB3.0 Simplified API、EJB 核心規范(EJB Core Contracts and Requirements)和 JPA(Java Persistence API)。
Simplified API
Simplified API 部分主要規定了基於 EJB 3.0 標准開發企業應用時所需要遵 守的 Bean 類和接口要求、這些 API 的使用方式以及容器支持等多方面的內容。 還詳細的規定了 EJB3.0 中除 Java Persistence API 部分之外的 EJB 實現所支 持的注釋(Annotation)。規范中還有專門章節講解 EJB 3.0 和此前的 EJB 規 范如何同時工作,以及如何將此前已經開發好的企業應用移植到 EJB 3.0 容器中 。其中的 Persistence 的內容放在了 JPA 規范中。
EJB 核心規范
EJB 核心規范中首先描述了 EJB 在企業應用中的角色、EJB 規范的體系結構 ,確定了支持 EJB 標准的容器應該遵守的准則和要求。隨後從多個角度詳細的介 紹了 EJB 體系中各部分的功能需求和實現要求,包括 Session Bean、消息驅動 Bean(Message-Driven Bean)、事務、安全管理、部署描述符等。其中的 Persistence 的內容放在了 JPA 規范中。由於 EJB 3.0 規范並不排斥之前的 EJB 規范,因此 EJB 2.X 和 EJB 1.X 中的內容也保留在了 EJB 核心規范中。
Java Persistence API(JPA)
EJB 2.X 和 EJB 1.X 規范中的實體 Bean(EntityBean)部分都難以使用,使 持久化成為 EJB 規范的一個軟肋,影響了 EJB 標准發揮更大的作用,自然而然 的,JPA 成為了 EJB3.0 規范中被關注最多的部分。JPA 規范部分詳細的介紹了 JPA 中實體 Bean 新的定義,並介紹了實體 Bean 支持的注釋、全新的查詢語言 、實體管理接口、容器實現規范等內容。
JPA 標准中引入了新的實體概念,每一個實體都是一個普通的 Java 類,不需 要繼承任何其他的接口或者擴展某個指定類,這個 Java 類必須使用 javax.persistence.Entity 進行注釋。JPA 標准中還提供了包括 javax.persistence.Table、javax.persistence.Id 等在內的多個注釋,用於完 成實體和數據庫之前的映射。JPA 中引入了新的查詢語言 JPQL(Java Persistence Query Language),JPQL 允許開發者采用面向對象的查詢語言來查 找實體,這些實體持久化在關系型的數據庫中,”select a from Animal a where a.name=’a’” 是一個 JPQL 的例子。其中的 Animal 是一個 Java 類, 而不是關系型數據庫中的一個表或者視圖。除了簡單的查詢功能之外,JPQL 中還 能夠支持 Group、Order 等通常只有 SQL 才能提供的高級功能。JPA 標准中還規 定了在 Java EE 環境中和非 Java EE 環境中使用 JPA 時的差異,以及 Java EE 環境中容器的職責等。
JPA 體系架構
JPA 中定義一套類和接口用於實現持久化管理和對象/關系的映射,下面這張 圖中顯示了 JPA 的主要組件以及它們之間的相互關系。
圖1 JPA 主要組件和相互關系
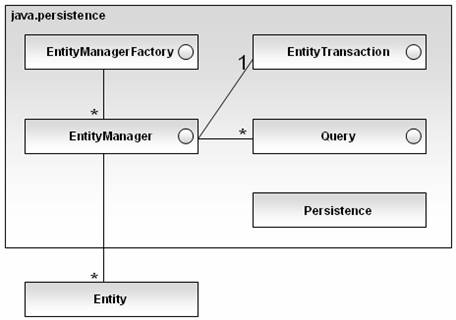
EntityManagerFactory
EntityManagerFactory 是 EntityManager 的工廠類,負責創建 EntityManager 對象。
EntityManager
EntityManager 是 JPA 應用中使用的基本對象,通過它提供的相應方法可以 管理持久化對象,也可以新建或者刪除持久化對象。EntityManager 還負責創建 Query 實例。在容器外使用時,EntityManagerFactory 和 EntityManager 之間 是一對一的關系。
Entity
EntityTransaction 提供 Entity 操作時需要的事務管理,和 EntityManager 是一對一的關系。在查詢操作時不需要使用 EntityTransaction,而在對象持久 化、狀態更新、對象刪除等情況下則必須使用顯式的使用 EntityTransaction 的 相關方法管理事務。
Query
Query 是查詢實體的接口,Query 對象可以從 EntityManager 中獲得。根據 EJB 3.0 規范中的描述,Query 接口需要同時支持 JPQL 和原生態 SQL 兩種語法 。
Persistence
Persistence 是一個工具類,負責根據配置文件提供的參數創建 EntityManagerFactory 對象。
下面的代碼演示了如何通過 JPA 提供的接口和 JPQL 查詢語言完成實體查詢 和更新的例子,例子中的代碼假定運行在非 Java EE 環境中。
清單 1 在非 Java EE 環境使用 JPA 接口的例子
1. /*
2. * Persistence 類獲取 EntityManagerFactory 實例;
3. * 一般 EntityManagerFactory 實例被緩存起來重復使用,
4. * 避免重復創建 EntityManagerFactory 實例引起的性能影響
5. */
6. EntityManagerFactory factory =
7. Persistence.createEntityManagerFactory (“mysql”);
8.
9. // 從 EntityManagerFactory 實例 factory 中獲取 EntityManager
10. EntityManager em = factory.
11. createEntityManager(PersistenceContextType.EXTENDED);
12.
13. // 實體的更新需要在事務中運行
14. EntityTransaction tx = em.getTransaction ();
15. tx.begin ();
16.
17. // 查找所有公司中的女性雇員
18. Query query = em.createQuery ("select e from Employee e "
19. + " where e.sex = 'femail'");
20. List results = query.getResultList ();
21.
22. // 給所有女性雇員增加半天假期
23. for (Object res : results){
24. Employee emp = (Employee) res;
25. emp.setHoliday (emp.getHoliday () +0.5);}
26.
27. // 提交事務(持久化所有更新)
28. tx.commit ();
29. em.close ();
30. factory.close ();
下面的代碼顯示了在 EJB 容器中開發 JPA 應用時的接口使用情況,由於容器 中的 EntityManager 是注入的,事務也是聲明式的,因此在容器中完成上面的業 務邏輯要簡單得多。
清單 2 在容器中運行的 JPA 例子
1. /*
2. * 在容器中運行 JPA 應用時,EntityManager 接口的實例”em”
3. * 是通過 @Resource 注釋注入的。事務也通常是聲明式的。
4. */
5. // 查找所有公司中的女性雇員
6. Query query = em.createQuery ("select e from Employee e "
7. + " where e.sex = 'femail'");
8. List results = query.getResultList ();
9.
10. // 給所有女性雇員增加半天假期
11. for (Object res : results){
12. Employee emp = (Employee) res;
13. emp.setHoliday (emp.getHoliday () +0.5);}
JPA 的優勢
JPA 標准制定過程中充分吸收了目前已經出現的所有持久化技術的所有優點, 摒棄了它們存在的局限,使 JPA 在簡單易用、查詢能力等方面表現突出。
標准化
JPA 是 JCP 組織發布的 Java EE 標准之一,因此任何聲稱符合 JPA 標准的 框架都遵循同樣的架構,提供相同的訪問 API,這保證了基於 JPA 開發的企業應 用能夠經過少量的修改就能夠在不同的 JPA 框架下運行。
對容器級特性的支持
JPA 框架中支持大數據集、事務、並發等容器級事務,這使得 JPA 超越了簡 單持久化框架的局限,在企業應用發揮更大的作用。
簡單易用,集成方便
JPA 的主要目標之一就是提供更加簡單的編程模型:在 JPA 框架下創建實體 和創建 Java 類一樣簡單,沒有任何的約束和限制,只需要使用 javax.persistence.Entity 進行注釋;JPA 的框架和接口也都非常簡單,沒有太 多特別的規則和設計模式的要求,開發者可以很容易的掌握。JPA 基於非侵入式 原則設計,因此可以很容易的和其它框架或者容器集成。
可媲美 JDBC 的查詢能力
JPA 定義了獨特的 JPQL(Java Persistence Query Language),JPQL 是 EJB QL 的一種擴展,它是針對實體的一種查詢語言,操作對象是實體,而不是關 系數據庫的表,而且能夠支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常 只有 SQL 才能夠提供的高級查詢特性,甚至還能夠支持子查詢。
支持面向對象的高級特性
JPA 中能夠支持面向對象的高級特性,比如類之間的繼承、多態和類之間的復 雜關系,這樣的支持能夠讓開發者最大限度的使用面向對象的模型設計企業應用 ,而不需要自行處理這些特性在關系數據庫的持久化。
下面的這個表格中列出了當前常用持久化技術的優缺點。
表 1 持久化技術的優缺點
支持內容: 序列化 JDBC ORM ODB EJB 2.X JDO EJB 3 (JPA) Java 對象 Yes No Yes Yes Yes Yes Yes 高級 OO 原理 Yes No Yes Yes No Yes Yes 事務完整性 No Yes Yes Yes Yes Yes Yes 並發 No Yes Yes Yes Yes Yes Yes 大數據集 No Yes Yes Yes Yes Yes Yes 現有 Schema No Yes Yes No Yes Yes Yes 關系型和非關系型數據存儲 No No No No Yes Yes No 查詢 No Yes Yes Yes Yes Yes Yes 嚴格的標准 / 可移植 Yes No No No Yes Yes Yes 簡單易用 Yes Yes Yes Yes No Yes Yes
OpenJPA 簡介
OpenJPA 是 Apache 組織提供的開源項目,它實現了 EJB 3.0 中的 JPA 標准 ,為開發者提供功能強大、使用簡單的持久化數據管理框架。OpenJPA 封裝了和 關系型數據庫交互的操作,讓開發者把注意力集中在編寫業務邏輯上。OpenJPA 可以作為獨立的持久層框架發揮作用,也可以輕松的與其它 Java EE 應用框架或 者符合 EJB 3.0 標准的容器集成。
除了對 JPA 標准的支持之外,OpenJPA 還提供了非常多的特性和工具支持讓 企業應用開發變得更加簡單,減少開發者的工作量,包括允許數據遠程傳輸/離線 處理、數據庫/對象視圖統一工具、使用緩存(Cache)提升企業應用效率等。
數據遠程傳輸 / 離線處理
JPA 標准規定的運行環境是 "本地" 和 "在線" 的。本地是指 JPA 應用中的 EntityManager 必須直接連接到指定的數據庫,而且必須和使用它的代碼在同一 個 JVM 中。在線是指所有針對實體的操作必須在一個 EntityManager 范圍中運 行。這兩個特征,加上 EntityManager 是非序列化的,無法在網絡上傳輸,導致 JPA 應用無法適用於企業應用中的 C/S 實現模式。OpenJPA 擴展了這部分接口, 支持數據的遠程傳輸和離線處理。
數據庫 / 對象視圖統一工具
使用 OpenJPA 開發企業應用時,保持數據庫和對象視圖的一致性是非常重要 的工作,OpenJPA 支持三種模式處理數據庫和對象視圖的一致性:正向映射 (Forward Mapping)、反向映射(Reverse Mapping)、中間匹配(Meet-in- the-Middle Mapping),並且為它們提供了相應的工具支持。
正向映射 是指使用 OpenJPA 框架中提供的 org.apache.openjpa.jdbc.meta.MappingTool 工具從開發者提供的實體以及在實 體中提供的對象 / 關系映射注釋生成相應的數據庫表。
反向映射 是指 OpenJPA 框架中提供的 org.apache.openjpa.jdbc.meta.ReverseMappingTool 工具從數據庫表生成符合 JPA 標准要求的實體以及相應的對象 / 關系映射注釋內容。
中間匹配 是指開發者負責創建數據庫表、符合 JPA 標准的實體和相應的對象 / 關系映射注釋內容,使用 OpenJPA 框架中提供的 org.apache.openjpa.jdbc.meta.MappingTool 工具校驗二者的一致性。
使用 緩存提升效率
性能是企業應用重點關注的內容之一,緩存是提升企業系統性能的重要手段之 一。OpenJPA 針對數據持久化提供多種層次、多方面的緩存支持,包括數據、查 詢、匯編查詢的緩存等。這些緩存的應用可以大幅度的提高企業應用的運行效率 。
總結
本文中,我們回顧了關系型數據庫和面向對象之間的阻抗失諧問題和 Java 社 區中為解決對象持久化而做出的努力,這些努力促進了 Java 中對象持久化的發 展,但是沒有任何一種技術象 EJB 3.0 標准中的 JPA 標准來的這麼簡單和高效 。
JPA 標准中使用注釋聲明數據庫表和對象之間的映射,開發者通過操作實體就 可以完成對數據庫的操作。OpenJPA 是 Apache 組織提供的開源項目,它實現了 EJB 3.0 中的 JPA 標准,為開發者提供功能強大、使用簡單的持久化數據管理框 架。除此之外 OpenJPA 還為開發者提供了更多額外的特性如數據遠程傳輸/離線 處理、數據庫/對象視圖統一工具、使用緩存提升企業應用效率等。
本系列 的後續文章將分別對 Apache OpenJPA 提供的標准特性和額外的增強 特性進行詳細介紹。在接下來的一篇文章中,請跟隨我們開始 OpenJPA 編程之旅 ,學習如何下載、安裝 OpenJPA 以及配置開發環境,並以此為起點開始第一個 OpenJPA 應用程序的開發。