在 “測試驅動設計,第 1 部分” 和 “測試驅動設計,第 2 部分” 中,我 介紹了測試如何為新的項目實現更好的設計。在 “組合方法和 SLAP” 中,我討 論了兩種關鍵模式 — 組合方法(composed method)和單一抽象層原理 — 為您 的代碼結構提供了整體目標。需要牢記這些模式。一旦擁有了一個現有軟件項目 ,那麼發現和利用設計元素的主要方法就是進行重構。在 Martin Fowler 的經典 著作 Refactoring 中,他將重構定義為 “一種嚴格的技術,可以重新構造現有 代碼體,修改代碼的內部結構,但是不會影響代碼的外部行為”。重構是一種具 有某種目的的結構轉換。對任何項目來說,值得稱贊的一點就是擁有可以輕松進 行重構的代碼庫。在本文中,我將討論如何使用重構技術來查找隱藏在代碼庫中 的未得到充分設計的代碼。
關於本系列
本 系列 旨在從全新的視角來介紹經常討論但是又難以理解的軟件架構和設計 概念。通過具體示例,Neal Ford 將幫助您在演化架構 和緊急設計 的靈活實踐 中打下堅實的基礎。通過將重要的架構和設計決定推遲到最後關鍵時刻,您可以 防止不必要的復雜度降低軟件項目的質量。
單元測試可以提供最重要的安全屏障,允許您按照自己的意願重構代碼庫。如 果您的項目的代碼覆蓋率達到了 100%,那麼可以安全地重構代碼。如果尚未達到 這個程度的測試,那麼草率地進行重構就會變得比較危險。本地化修改可以很容 易地應用並且可以立即看到修改效果,但是副作用產生的破壞也會使您非常苦惱 。軟件會產生無法預料的耦合點,對代碼的某一部分進行微小的修改會影響到整 個代碼庫,造成數百行代碼發生錯誤。要安全地修改代碼並找出大量錯誤,需要 進行廣泛的單元測試。對於一個為期 2 年的 ThoughtWorks 項目,技術主管在運 行該項目的前一天對代碼進行了 53 處不同的重構。他在進行重構時信心滿滿, 因為項目擁有廣泛的代碼覆蓋率。
如何實現可以進行重大重構的代碼庫?一個辦法就是不要編寫任何代碼,直到 您將測試添加到整個項目中。當您提出這個建議後,您將被解雇,然後您可以去 另一家重視單元測試的公司工作。這種方法可能不是很好。另一個好方法是讓團 隊的其他成員認識到測試的價值並開始緩慢地圍繞代碼的最關鍵部分添加測試。 做好規劃並在近期內宣布一個日期:“從下周四啟動,我們的代碼覆蓋率將不斷 增長”。每次編寫新代碼時,添加一個測試,每次修復一個 bug 時,編寫一個測 試。通過圍繞最敏感的代碼部分(新特性和容易出現 bug 的部分)逐步添加測試 ,那麼測試就可以發揮最大的作用。
單元測試檢驗原子性行為。但是,如果您的代碼庫沒有堅持組合方法的思想, 該怎麼辦?換句話說,如果您的所有方法都具有幾十或幾百行代碼,並且每個方 法執行大量的任務,那麼應該怎麼做?您可以使用單元測試框架來圍繞這些方法 編寫粗粒度功能測試,主要關注方法的輸入和輸出狀態的轉換。這種方法不如單 元測試,因為不能對行為進行徹底的檢驗,但是總比不采取任何措施要好。對於 代碼中真正關鍵的部分,可能需要在進行重構之前添加一些功能測試作為一種安 全保障。
重構機制非常簡單,並且所有主要 IDE 目前都提供了出色的重構支持。比較 困難的地方在於確定對哪些內容 進行重構。這就是本文其余部分要解決的問題。
與基礎設施耦合
Java 世界的所有開發人員都使用框架來啟動開發並提供最好的關鍵基礎設施 (不需要您編寫的基礎設施)。但是框架(包括商業的和開源的)所隱含的一個 危險就是:它們總是試圖讓您與其進行緊密耦合,這使得發現代碼中隱藏的設計 變得更加困難。
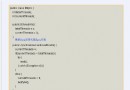
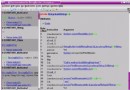
框架和應用服務器都提供了 helper 類,誘使您實施一種更加簡單的開發:如 果您僅僅是導入和使用它們的某些類,那麼完成特定的任務將變得非常容易。一 個典型的例子就是 Struts,這是一種非常流行的開源 Web 框架。Struts 包括了 一組 helper 類來幫助您處理常見問題。例如,如果允許您的域類擴展 Struts ActionForm 類,那麼 Struts 將自動從請求中填充表單字段,處理驗證和生命周 期事件,並執行其他比較簡單的行為。換而言之,Struts 提供了某種權衡:使用 我們的類將使您的開發工作變得非常輕松。它鼓勵您創建一種類似於圖 1 所示的 結構:
圖 1. 使用 Struts ActionForm 類
黃色的方框包含了您的域類,但是 Struts 框架鼓勵您擴展 ActionForm 獲得 有用的行為。然而,您現在必須將代碼與 Struts 框架耦合。除了 Struts 應用 程序外,您不能在其他任何位置使用域類。這還不利於域類的設計,因為這個實 用類現在必須位於對象層次結構的頂層,不允許您使用繼承來整合常見行為。
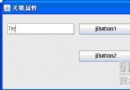
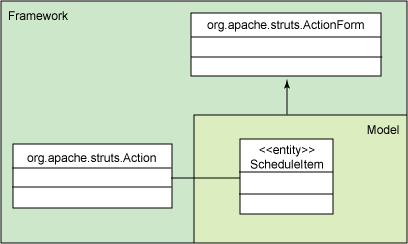
圖 2 展示了一種更好的方法:
圖 2. 改進後的設計,使用復合解除與 Struts 的耦合
采用這種方法,您的域類對 Struts ActionForm 不存在任何依賴關系。相反 ,一個接口為您的域類和 ScheduleItemForm 類定義了語義,後者充當域類與框 架之間的一個橋梁。ScheduleItemImpl 和 ScheduleItemForm 都實現了這個接口 ,而 ScheduleItemForm 類通過復合(而不是繼承)獲得了對域類的引用。允許 Struts helper 維護對您的類的依賴關系,但是反過來並不成立:您不應該讓類 對框架存在依賴關系。現在,您可以在其他類型的應用程序中隨意使用 ScheduleItem(比如 Swing 應用程序和服務層等)。
與基礎設施建立耦合非常簡單,並且對於許多應用程序來說也很普遍。當您導 入了框架的優點時,框架可以極大地簡化對服務的利用。您應當抵制這種誘惑。 如果框架掩蓋住了所有內容,那麼就更加難以發現代碼中的慣用模式(早期文章 中定義為應用程序中出現的 little 模式)。
違反 DRY 原則
在 The Pragmatic Programmer 一書中,Andy Hunt 和 Dave Thomas 定義了 DRY 原則:不要自我復制。代碼中有兩處違背了 DRY 原則 — 復制和粘帖代碼以 及結構化復制,這將對設計產生影響。
復制和粘帖代碼
代碼復制使設計變得更加模糊,因為您無法找到慣用模式。在不同位置復制和 粘帖代碼會產生一些微小的差異,使您無法確定一個方法或多個方法的實際使用 。當然,人們都知道復制和粘帖代碼最終會害了自己,因為您不可避免地要修改 行為,但是很難跟蹤所有復制和粘帖了代碼的位置。
如何找出代碼庫中隱藏的復制?有的 IDE 包括了復制檢測器(比如 IntelliJ ),或者提供了插件(比如 Eclipse)。還存在獨立的工具,即包括開源的(比 如 CPD,即 Copy/Paste Detector),也包括商業的(比如 Simian)。
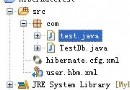
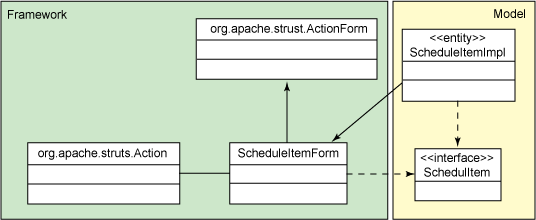
CPD 項目是 PMD 源代碼分析工具的一部分。它是一個基於 Swing 的應用程序 ,可以分析單獨文件內或跨多個文件的標記的可配置數量。我需要一個典型的問 題代碼庫來作為示例,因此選擇了前面提到的 Struts 項目。在 Struts 2 代碼 上運行 CPD 將生成如圖 3 所示的結果:
圖 3. 在 Struts 2 上運行 CPD 生成的結果
CPD 在 Struts 代碼庫中找到了大量復制。其中許多復制主要關於向 Struts 添加 portlet 支持。事實上,大多數跨文件復制存在於 PortletXXX 和 XXX ( 例如 PortletApplicationMap 和 ApplicationMap)之間。這表明 portlet 支持 沒有進行過良好設計。任何時候使用這些復制代碼為現有框架添加額外的行為時 ,這都是主要的代碼特征(code smell)。繼承或復合都提供了一種更加干淨的 方法來擴展框架,如果這兩種方法都不可行的話,那麼問題就更加嚴重了。
這段代碼中另一個常見的復制問題在 ApplicationMap.java 和 Sorter.java 文件中。ApplicationMap.java 包含一個共 27 行的復制代碼塊,如清單 1 所示 :
清單 1. ApplicationMap.java 中的復制代碼
entries.add(new Map.Entry() {
public boolean equals(Object obj) {
Map.Entry entry = (Map.Entry) obj;
return ((key == null) ?
(entry.getKey() == null) :
key.equals(entry.getKey())) && ((value == null) ?
(entry.getValue() == null) :
value.equals(entry.getValue()));
}
public int hashCode() {
return ((key == null) ?
0 :
key.hashCode()) ^ ((value == null) ?
0 :
value.hashCode());
}
public Object getKey() {
return key;
}
public Object getValue() {
return value;
}
public Object setValue(Object obj) {
context.setAttribute(key.toString(), obj);
return value;
}
});
除了多次使用嵌套的三元運算符外(是判斷任務安全性編碼的良好指標,因為 任何人都不能讀取這些代碼),這段復制代碼的有趣之處並不在於代碼本身。而 是在於在出現復制的兩個方法之前顯示的先兆。第一處如清單 2 所示:
清單 2. 第一次出現復制代碼時的先兆
while (enumeration.hasMoreElements()) {
final String key = enumeration.nextElement().toString();
final Object value = context.getAttribute(key);
entries.add(new Map.Entry() {
// remaining code elided, shown in Listing 1
清單 3 展示了出現第二次復制時的先兆:
清單 3. 出現第二次復制代碼時的先兆
while (enumeration.hasMoreElements()) {
final String key = enumeration.nextElement().toString();
final Object value = context.getInitParameter(key);
entries.add(new Map.Entry() {
// remaining code elided, shown in Listing 1
在整個 while 循環中的惟一不同之處在於 清單 2 中對 context.getAttribute(key) 的調用和 清單 3 中對 context.getInitParameter(key) 的調用之間的差別。顯然,這些可以實現參數 化,允許復制代碼銷毀自己的方法。來自 Struts 的示例解釋了免費的復制和粘 帖代碼,這些代碼不僅毫無必要,並且容易修復。
實際上,這解釋了利用並將條目添加到屬性集中的方法在 Struts 代碼庫中是 一種慣用模式。允許將幾乎相同的代碼放到多個位置將隱藏一個事實,即 Struts 需要一直執行這個操作,這將阻止將這些代碼放到一個含義更明顯的位置。要清 理 Struts 代碼庫中多個類的設計,一種方法就是意識到這種慣用模式的存在並 鞏固這一行為。
結構化復制
另一種復制形式更加難以檢測,因此危害也更大:結構化復制。使用有限的幾 種語言的開發人員(特別是那些只具備少量元編程支持的語言,比如 Java 和 C# )尤其容易出現這個問題。我的同事 Pat Farley 使用了一個短語就很好地總結 了結構化復制:相同的空白,不同的值。就是說,您復制了幾乎一模一樣的代碼 (即空白位置也是相同的),但是變量使用不同的值。這種復制並不會出現在 CPD 之類的工具中,因為重復的基礎設施的每個實例的值必須是惟一的。盡管如 此,它仍然會損害您的代碼。
下面舉一個例子。我使用一個包含若干字段的簡單 employee 類,如清單 4 所示:
清單 4. 一個簡單 employee 類
public class Employee {
private String name;
private int salary;
private int hireYear;
public Employee(String name, int salary, int hireYear) {
this.name = name;
this.salary = salary;
this.hireYear = hireYear;
}
public String getName() { return name; }
public int getSalary() { return salary;}
public int getHireYear() { return hireYear; }
}
對於這個簡單類,我希望能夠對類的任意字段進行排序。Java 語言中的一種 機制可以通過創建實現 Comparator 接口的 comparator 類,改變排序次序。清 單 5 展示了 name 和 salary 的 Comparator:
清單 5. name 和 salary 的 Comparator
public class EmployeeNameComparator implements Comparator<Employee> {
public int compare(Employee emp1, Employee emp2) {
return emp1.getName().compareTo(emp2.getName());
}
}
public class EmployeeSalaryComparator implements Comparator<Employee> {
public int compare(Employee emp1, Employee emp2) {
return emp1.getSalary() - emp2.getSalary();
}
}
對於 Java 開發人員來說,這看上去非常自然。然而,考慮圖 4 所示的代碼 視圖,我在其中將兩個 Comparator 重疊:
圖 4. 重疊後的 comparator

可以看到,相同的空白,不同的值 可以很好地形容這個情況。大部分代碼是 經過復制的;惟一不同的部分是返回的值。由於我以一種 “自然” 的方式使用 了比較基礎設施(即按語言設計者的意圖使用),因此很難發現這種復制,但是 它確實存在於代碼中。也許對於區區三個屬性來說不算太嚴重,但是如果增長到 大量屬性呢?您決定什麼時候開始處理這種復制,您打算怎麼對付它?
我准備使用反射(reflection)來創建一種通用的排序基礎設施,其中不會涉 及大量復制的樣板代碼。為此,我創建了一個類來為每個字段自動處理 comparator 的排序和創建。清單 6 展示了 EmployeeSorter 類:
清單 6. EmployeeSorter 類
public class EmployeeSorter {
public void sort(List<DryEmployee> employees, String criteria) {
Collections.sort(employees, getComparatorFor (criteria));
}
private Method getSelectionCriteriaMethod(String methodName) {
Method m;
methodName = "get" + methodName.substring(0, 1).toUpperCase() +
methodName.substring(1);
try {
m = DryEmployee.class.getMethod(methodName);
} catch (NoSuchMethodException e) {
throw new RuntimeException(e.getMessage());
}
return m;
}
public Comparator<DryEmployee> getComparatorFor(final String field) {
return new Comparator<DryEmployee>() {
public int compare(DryEmployee o1, DryEmployee o2) {
Object field1, field2;
Method method = getSelectionCriteriaMethod (field);
try {
field1 = method.invoke(o1);
field2 = method.invoke(o2);
} catch (Exception e) {
throw new RuntimeException(e);
}
return ((Comparable) field1).compareTo (field2);
}
};
}
}
sort() 方法使用 Collecions.sort() 方法,傳遞雇員列表和一個生成的 comparator,調用此類的第三個方法。getComparatorFor() 方法充當一個工廠, 根據傳入的條件動態生成匿名 comparator 類。它通過 getSelectionCriteriaMethod() 使用反射從 employee 類檢索相應的 get 方法 ,對進行比較的每個實例調用該方法,並返回結果。清單 7 中的單元測試展示了 這個類對兩個字段的實際應用:
清單 7. 測試泛型 comparator
public class TestEmployeeSorter {
private EmployeeSorter _sorter;
private ArrayList<DryEmployee> _list;
@Before public void setup() {
_sorter = new EmployeeSorter();
_list = new ArrayList<DryEmployee>();
_list.add(new DryEmployee("Homer", 20000, 1975));
_list.add(new DryEmployee("Smithers", 150000, 1980));
_list.add(new DryEmployee("Lenny", 100000, 1982));
}
@Test public void name_comparisons() {
_sorter.sort(_list, "name");
assertThat(_list.get(0).getName(), is("Homer"));
assertThat(_list.get(1).getName(), is("Lenny"));
assertThat(_list.get(2).getName(), is("Smithers"));
}
@Test public void salary_comparisons() {
_sorter.sort(_list, "salary");
assertThat(_list.get(0).getSalary(), is(20000));
assertThat(_list.get(1).getSalary(), is(100000));
assertThat(_list.get(2).getSalary(), is(150000));
}
}
像上面這樣使用反射代表了一種權衡:復雜性和簡潔性。基於反射的版本最初 比較難以理解,但是它提供了一些優點。首先,它自動為 Employee 類處理所有 屬性。准備好這些代碼後,您可以安全地向 Employee 添加新屬性,而不需要考 慮創建 comparator 來對它們進行排序。其次,這種方法可以更加高效地處理大 量屬性。如果結構化復制不嚴重的話,那麼也可以忍受。但是您必須要問問自己 :當屬性數量達到多少時,您必須使用反射來解決此問題?10 個、20 個還是 50 個?這個數字對於不同的開發人員和團隊來說可能會發生變化。然而,如果試圖 尋找一種比較客觀的衡量,為什麼不衡量一下反射相對於單個 comparator 的復 雜度呢?
在 “測試驅動設計,第 2 部分” 中,我引入了圈復雜度 指標,可以度量單 一方法的相對復雜度。一種可以度量 Java 語言圈復雜度的非常不錯的開源工具 就是 JavaNCSS 工具。如果我對單個 comparator 類運行 JavaNCSS,它將返回 1 ,這並不奇怪:類中的單個方法只有一行代碼而沒有代碼塊。當我對整個 EmployeeSorter 類運行 JavaNCSS 時,所有方法的圈復雜度的總值為 8。這表示 當屬性數達到 9 時需要改用反射;這時結構復雜度超過了基於反射的方法的復雜 度。
總之,每種解決方法都有利弊,這取決於您如何權衡。我已經習慣在 Java 語 言和其他語言中使用反射,因此我將更加積極地推行這種方法,因為我不喜歡在 軟件中使用各種形式的重復。
結束語
在本期文章中,我首先討論了使用重構作為手段來幫助理解和識別緊急設計。 我介紹了與基礎設施的耦合及其對設計的不利影響。文章主要介紹了幾種不同形 式的復制。重構與設計的交互是一個非常豐富的主題;下期文章將繼續這個主題 ,討論如何使用指標查找代碼中最需要進行重構的部分,因此這些部分也最有可 能包含等待發現的慣用模式。