隨著多核處理器成為主流,應用開發人員對於如何編寫高伸縮性的應用以利用底層硬 件的優勢這個問題面臨巨大的壓力。此外,遺留系統不得不移植到新的架構上。保證應用 伸縮性的一種有效方式是使用高伸縮性組件構建應用。舉例來說,在各種應用中, java.util.concurrent.ConcurrentHashMap可以替代同步的HashTable,使應用伸縮性更 好。因此,向應用直接提供一套高伸縮性構造塊以引入並行是非常有用的。
我們創建了一套高伸縮性並發Java組件作為Amin庫項目的一部分。在本文中,我們將 介紹一些創建該開源庫的想法。
概述
作為軟件工程師,我們不得不並行我們的應用使它們在多核機器上很好的伸縮。一種 並行方式是把它們分成若干子任務,其中每一個子任務與應用的其他子任務通信和同步。 這通常被稱為基於任務的並發。我們可以基於子任務的通信模式將應用分類。
尴尬式並行——應用的子任務從不或者很少與其他子任務通信。通常情況下,每一個 任務只處理自己的私有數據。一些例子包括:
蒙特卡洛模擬程序
快速排序程序,使用fork/join模式很容易實現並發。當我們處理尴尬式並行應用時容 易得到很好的伸縮性。
粗粒度和細粒度式並行——這些應用的子任務需要互相通信。根據子任務之間的通信 頻率可以把程序分為粗粒度和細粒度並行。一個例子是生產者/消費者問題。生產者產生 驅動消費者的數據。從生產者到消費者的數據發送需要通信。相比尴尬式並行應用,處理 子任務頻繁交互的應用較難得到良好的伸縮性。
經過為伸縮性而優化的組件非常有益於解決這些困難問題。舉例來說,如果存在一個 高伸縮性隊列組件,那麼實現生產者/消費者伸縮性相對容易些。本文中,我們提供了若 干通用技術提高軟件組件的伸縮性。
針對伸縮性的分析
應用分析是開發過程的重要方面。分析是為了了解應用的運行特征。分析數據經常被 用於提高應用的性能和伸縮性。大多數分析器遵從一個簡單的執行模式,其中有一個配置 階段。在該階段,根據信息獲取的類型,會配置不同層次的計算堆棧。硬件計數器可以被 用來監控硬件事件。操作系統可以通過配置各種操作系統事件來監控。如果在計算層次中 還有虛擬機,那麼需要配置以訪問虛擬機的事件。最後,應用需要配置以得到真實應用的 事件。優秀的分析器能夠在不要求應用重新編譯的情況下完成這些配置。大多數分析器通 常都配置虛擬機和應用層。應用在配置之後運行時,會生成跟蹤信息,例如函數運行時間 、資源使用情況、硬件性能參數、鎖使用、系統時間、用戶時間等等。不同的分析器會在 把跟蹤信息輸出到文件系統前做一些計算。最後,分析器會通過顯示界面可視化這些數據 。
用於並發應用的分析器需要提供有關線程、鎖競爭和同步點的詳細信息。我們使用了 下面一些分析器作為Amino性能分析:
Java鎖監控器(Java Lock Monitor)——Java開發人員使用該工具分析應用中鎖的使 用情況。在運行時,監控組件收集各種鎖數據用於發現鎖競爭。該工具能夠通過表格展示 詳細的鎖和競爭信息。IBM Java Lock Analyzer (JLA)是另一個提供鎖信息的工具。它與 JLA類似,只不是通過圖形界面顯示縮合競爭數據。兩個工具都支持x86和Power平台。
THOR ——該工具用於詳細分析Java應用的性能。它能夠深入分析完整的執行棧,從硬 件到應用層。信息來自於棧的四個層面——硬件、操作系統、JVM和應用。用戶可以看到 鎖競爭的信息以及對應的代碼、瓶頸、多核之間的線程遷移和競爭導致的性能下降。該工 具支持x86和Power平台。
AIX性能工具——IBM的AIX操作系統自帶一套底層的性能分析和調試工具。其中包括:
Simple Performance Lock Analysis Tool (SPLAT) ——該工具是AIX系統上的一個鎖 分析工具,可以通過命令行運行,用於分析各種內核級的鎖。同時,它也可以分析和顯示 用戶級鎖(讀/寫和mutex)的競爭。應用必須啟用跟蹤選項,SPLAT需要用到這些跟蹤數 據。
XProfiler——該分析工具基於X—Windows,用於C語言應用的函數級分析,能夠顯示 在用戶代碼中計算敏感的函數。如果要使用XProfiler,代碼需要使用特殊的標志(-pg選 項)編譯。
prof、 tprof和gprofncbr——各種prof命令都可以用於分析用戶應用。prof命令能夠 得到所有應用中的外部符號和函數。gprof是 prof的超集,可以獲得應用的調用關系圖。 最後,tprof用於得到應用的宏觀和微觀的分析信息。tprof能夠得到各個指令、子程序、 線程、進程的計時數據,還有用戶模式函數、庫函數、Java類、Java方法、內核函數、內 核擴展等的處理器使用情況。
減少熱點
傳統的性能調優方法,比如適用於順序應用的方法也適用於並行應用。在完成傳統調 優之後,我們需要檢查共享數據是如何被多線程訪問的。通過使用JLM或者JLA,我們能夠 發現線程在訪問共享資源時是如何競爭的。
舉例來說,如果應用有100個線程,並且所有的線程都需要從一個 java.util.HashTable提取/存儲元素,該應用的性能由於線程競爭會下降。每一個線程需 要在訪問該HashTable之前等待很長時間。
如果我們使用類似JLM的工具就會發現,該Hash表關聯的monitor使用非常頻繁。解決 這一問題的辦法是使用能夠替代HashTable的高擴展性 組件。在本例中,我們可以通過 java.util.concurrent.ConcurrentHashMap替換該hash表。 ConcurrentHashMap把它的內 部數據結構分成若干段。在應用中使用ConcurrentHashMap替換HashMap替換使線程針對多 個子組件競爭而不是單個大組件。使用ConcurrentHashMap的應用產生競爭的幾率比之前 要小得多。
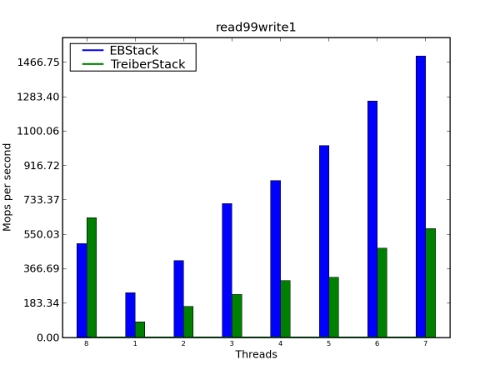
還有一種辦法降低訪問共享組件的競爭幾率。如果一個組件具有相反語義的操作,如 棧的壓入和彈出,這兩種操作可以無需接觸核心數據結構即可完成。這種技術最 早由 Danny Hendler、Nir Shavit和Lena Yerushalmi引入,已經在Amino庫中實現。這種方法 的性能改善見圖1。
圖1.性能比較:EBStack和TreiberStack
使用無鎖/無等待算法
傳統上,大家都采用基於鎖的方法來確保共享數據的一致性和對關鍵區域的互斥訪問 。鎖的概念易懂,但基於鎖的算法引起了很多挑戰。其中一些著名的問題包括死鎖、活鎖 、優先級倒置和鎖競爭等。鎖競爭會減少組件和算法的可擴展性。
無鎖和無等待算法到現在已經存在二十多年了。它們被認為可以能夠解決大部分與鎖 有關的問題。這些算法支持在不使用任何鎖算法的情況下更新共享數據結構,不僅如此, 還有助於創建擴展性良好的算法。最初,這些無鎖和無等待的算法純粹是理論興趣。但是 ,隨著算法社區的發展和新硬件的支持,無鎖技術在現實產品中得到了越來越多的應用, 比如操作系統內核、虛擬機、線程庫等。
從JDK 1.5以後,JDK包含了這些無鎖算法,比如ConcurrentLinkedQueue、 AtomicInteger等。它們的伸縮性通常比對應的基於鎖的組件要好。當我們在Amino庫實現 新組件時,我們會使用目前研究的最新無鎖算法。這使得Amino數據結構擴展性和效率非 常好。但是有時候,特別是在低核硬件上,無鎖數據結構比基於鎖數據結構的吞吐量差, 但是一般來說,它們的吞吐量比較好。
盡可能減少比較—交換(CAS)操作
從JDK 1.5以後,JDK包含了由Doug Lea開發的位於java.util.concurrent包的無鎖的 FIFO(先進先出)隊列。該隊列采用的算法基於單鏈表的並發操作,最初由 Michael和 Scott開發。它的出列操作需要一次比較—交換,而入列操作需要兩次比較—交換。這對 入列和出列操作來說太容易了。但是分析數據(圖 2)顯示比較—交換操作占用了大部分 執行時間,同時入列操作需要兩次交換—比較,這增加了失敗的概率。在現代多處理器上 ,一次成功的比較—交換操作要比一次加載或者存儲的時間長一個數量級,因為它們需要 獨立占用和沖刷處理器寫緩存。
圖2. CAS操作的執行時間
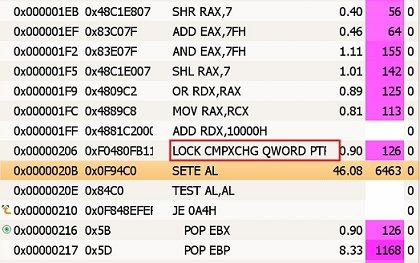
從圖2可以看出,CAS操作執行時間的百分比為46.08%,幾乎占了全部執行時間的一半 。分析數據有一個操作的延遲。真正的時間是在"SETE AL"指令之後發生的。
Mozes和Shavit(MoS-queue)在它們的無鎖隊列算法中,提供了一種新穎的辦法來降 低入列操作時CAS的數量。其關鍵點在於替換單鏈表,因為其中的指針在插入時需要浪費 一次CAS操作,取而代之的是采用一個雙鏈表,其中的指針在更新時只需要一次存儲操作 ,如果事件亂序導致雙鏈表不一致則可以修復。
我們做了一次基准測試來比較ConcurrentLinkedQueue(JSR166y)和Mos-Queue的性能 。結果在圖3中顯示。對於大量線程來說,Mos-Queue的性能優於JDK ConcurrentLinkedQueue。
圖3. 性能比較:ConcurrentLinkedQueue和Mos-Queue
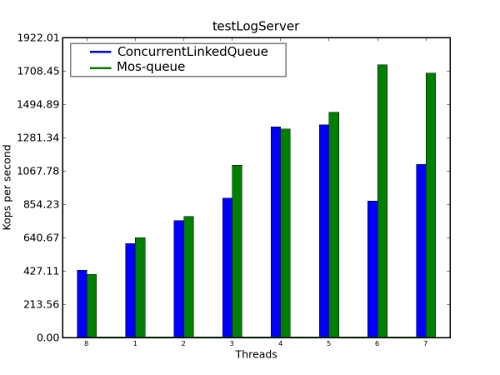
更多有關Mos-Queue的信息參見Mozes和Shavit的論文《An Optimistic Approach to Lock-Free FIFO Queues》。
減少內存分配
Java虛擬機擁有一套強大、有效的內存管理體系。垃圾回收器能夠壓縮現有對象,以 確保在垃圾回收之後Java堆裡沒有空隙。因為空閒空間在垃圾回收之後都是連續的,所以 內存分配不多是增加了一個指針而已。
這對多線程應用同樣有效,如果內存使用不敏感的話。JVM為每一個線程分配了一個線 程范圍的緩存。在內存分配時,線程范圍的緩存首先被使用。只有在線程范圍的緩存被耗 盡之後才會使用全局堆。
在線程范圍內分配內存對應用性能非常有益,但是如果分配過於頻繁,則會不起作用 。根據我們的經驗,線程范圍的緩存在分配頻率高的情況下會很快耗盡。
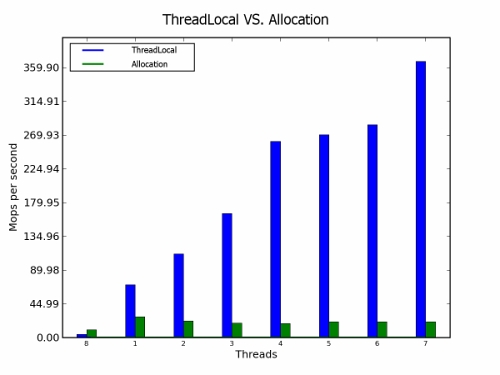
如果在循環中需要暫時性的對象,則線程范圍的類會比較有益。如果我們在線程本地 對象中存儲臨時對象,我們可以在每一次循環迭代中重用它。雖然,線程本地類會增加額 外的負擔,但是大多數時候都比在內存中頻繁分配內存要好。
圖 4.性能比較:線程本地和分配
結論
在本文中,我們介紹了使用Java創建高擴展性組件的幾個重要原則。一般來說,這些 原則通常很有幫助,但是它們無法替代謹慎的測試和性能調優。