簡介
正如您在本系列(共三篇文章)的 第 1 部分 中所了解到的,監控 Java 應用程序的可用性和性能及其生產中的依賴性,這對於確保問題檢測和加速問題診斷和修復至關重要。需要進行監視的類的源代碼級插裝具有 第 1 部分 所論述過的那些優勢,但是這種方法通常都不可取或者不切實際。例如,很多您所感興趣的監控點可能位於第三方組件中,而第三方組件的源代碼您是不得而知的。在第 2 部分中,我著重介紹了無需修改原始源代碼而插裝 Java 類和資源的方法。
可選擇的在源代碼外編排插裝的方法有:
截取
類包裝
字節碼插裝
本文使用了 第 1 部分 中呈現的 ITracer 接口來實現性能數據跟蹤,依次舉例闡明了這些技巧。
通過截取進行 Java 插裝
截取 的基本前提是通過一個截取構造和收集傳入的入站與出站調用信息,對特定的調用模式進行轉換。一個基本的截取程序的實現會:
獲取對入站調用請求的當前時間。
取回出站響應的當前時間。
將運行時間作為兩次度量的增量計算出來。
將調用的運行時間提交給應用程序性能管理(APM)系統。
圖 1 展示了該流程:
圖 1. 性能數據收集截取程序的基本流程
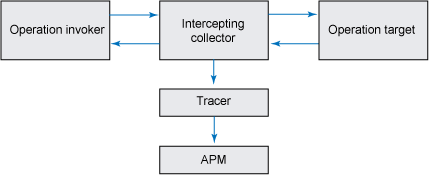
很多諸如 Java Platform 和 Enterprise Edition(Java EE)這樣的 Java 框架都包括對截取棧的核心支持,服務的調用可以在截取棧中通過一系列預處理和後處理組件來進行傳遞。有了這些棧就可以很好地將插裝注入到執行路徑中,這樣做的好處有二:第一,無需修改目標類的源代碼;第二,只要將截取程序類插入到 JVM 的類路徑中並修改組件的部署描述符,這樣就把插裝截取程序插入到了執行流程中。
截取的核心指標
截取程序所收集的一個典型的指標就是運行時間。其他的指標同樣適合截取模式。我將介紹支持這些指標的 ITracer 接口的兩個新的方面,所以在這裡我要轉下話題,先簡要論述一下這些指標。
使用截取程序時需要收集的典型指標有:
運行時間:完成一個執行的平均時鐘時間。
每個時間間隔內的調用:調用目標的次數。
每個時間間隔內的響應:目標響應調用的次數。
每個時間間隔內的異常l:目標調用導致異常的次數。
並發性:並發執行目標的線程數。
還有兩個 ThreadMXBean 指標可以選擇,但它們的作用有限,而且收集成本會高一些:
運行 CPU 時間:這是線程在執行期間消耗的 CPU 時間,以納秒為單位。CPU 的利用情況在起初時似乎有用,但其實也就是作為一種趨勢模式,其他的用處不大。或者,如果收集成本特別高的話,可以計算線程在執行時占用 CPU 資源的百分比的近似值。
阻塞/等待計數和時間:等待表示由具體線程調度導致的同步或者等待。阻塞常見於執行等待資源時,如響應來自遠程數據庫的 Java 數據庫連接(Java Database Connectivity,JDBC)調用(至於這些指標的用處,請參見本文的 JDBC 插裝 部分)。
為了澄清 ThreadMXBean 指標的收集方法,清單 1 快速回顧了基於源代碼的插裝。在這個例子中,我針對 heavilyInstrumentedMethod 方法實現了大量插裝。
清單 1. 實現大量插裝的方法
protected static AtomicInteger concurrency = new AtomicInteger();
.
.
for(int x = 0; x < loops; x++) {
tracer.startThreadInfoCapture(CPU+BLOCK+WAIT);
int c = concurrency.incrementAndGet();
tracer.trace(c, "Source Instrumentation", "heavilyInstrumentedMethod",
"Concurrent Invocations");
try {
// ===================================
// Here is the method
// ===================================
heavilyInstrumentedMethod(factor);
// ===================================
tracer.traceIncident("Source Instrumentation",
"heavilyInstrumentedMethod", "Responses");
} catch (Exception e) {
tracer.traceIncident("Source Instrumentation",
"heavilyInstrumentedMethod", "Exceptions");
} finally {
tracer.endThreadInfoCapture("Source Instrumentation",
"heavilyInstrumentedMethod");
c = concurrency.decrementAndGet();
tracer.trace(c, "Source Instrumentation",
"heavilyInstrumentedMethod", "Concurrent Invocations");
tracer.traceIncident("Source Instrumentation",
"heavilyInstrumentedMethod", "Invocations");
}
try { Thread.sleep(200); } catch (InterruptedException e) { }
}
清單 1 引入了兩個新的構造:
ThreadInfoCapture 方法:ThreadInfoCapture 方法對於獲取運行時間和目標調用前後的 ThreadMXBean 指標增量都很有幫助。startThreadInfoCapture 為當前線程捕獲基准,而 endThreadInfoCapture 計算出增量和趨勢。由於這些指標永遠都是遞增的,所以必須事先確定一個基准,再根據它計算出之後的差量。但這個場景不適用於跟蹤程序的增量功能,這是因為每一個線程的絕對值都是不同的,而且運行中的 JVM 中的線程也不是保持不變的。另外還要注意跟蹤程序使用了一個棧來保存基准,所以您可以(小心地)嵌套調用。要收集這個數據可是要費一番力氣。圖 2 展示了收集各種 ThreadMXBean 指標所需要的相對運行時間:
圖 2. 收集 ThreadMXBean 指標所需的相對成本

雖然如果小心使用調用的話,收集這些指標的總開銷不會很大,但是仍然需要遵循在記錄日志時需要考慮的一些事項,例如不要在緊湊循環(tight loop)內進行。
並發性:要跟蹤在特定時間內通過這個代碼的線程數,需要創建一個計數器,該計數器既要是線程安全的又要對目標類的所有實例可用 — 在本例為 AtomicInteger 類。此種情況比較麻煩,因為有時可能多個類加載器都載入了該類,致使計數器無法精確計數,從而導致度量錯誤。解決這個問題的辦法為:將並發計數器保存在 JVM 的一個特定的受保護位置中,諸如平台代理中的 MBean。
並發性只有在插裝目標是多線程的或者共用的情況下可用,但是它是非常重要的指標,這一點我將在稍後介紹 Enterprise JavaBean(EJB)截取程序時進一步闡述。EJB 截取程序是我接下來要論述的幾個基於截取的插裝示例的第一個,借鑒了 清單 1 中查看的跟蹤方法。
EJB 3 截取程序
發布了 EJB 3 後,截取程序就成了 Java EE 架構中的標准功能(有些 Java 應用服務器支持了 EJB 截取程序一段時間)。大多數 Java EE 應用服務器的確提供了性能指標,報告有關諸如 EJB 這樣的主要組件,但是仍然需要實現自己的性能指標,因為:
您需要基於上下文的或者基於范圍/阈值的跟蹤。
應用服務器指標固然不錯,但是您希望指標位於 APM 系統中,而不是應用服務器中。
應用服務器指標無法滿足您的要求。
雖然如此,根據您的 APM 系統和應用服務器實現的不同,有些工作可能不用您再親歷親為了。例如,WebSphere® PMI 通過 Java 管理擴展(Java Management Extensions,JMX)公開了服務器指標(參見 參考資料)。即使您的 APM 供應商沒有提供自動讀取這個數據的功能,讀完本篇文章之後您也會知道如何自行讀取。
在下一個例子中,我將向一個稱為 org.aa4h.ejb.HibernateService 的無狀態會話的上下文 bean 中注入一個截取程序。EJB 3 截取程序的要求和依賴性都是相當小的:
接口:javax.interceptor.InvocationContext
注釋:javax.interceptor.AroundInvoke
目標方法:任何一個名稱裡面有 public Object anyName(InvocationContext ic) 的方法
清單 2 展示了樣例 EJB 的截取方法:
清單 2. EJB 3 截取程序方法
@AroundInvoke
public Object trace(InvocationContext ctx) throws Exception {
Object returnValue = null;
int concur = concurrency.incrementAndGet();
tracer.trace(concur, "EJB Interceptors", ctx.getTarget().getClass()
.getName(), ctx.getMethod().getName(),
"Concurrent Invocations");
try {
tracer.startThreadInfoCapture(CPU + BLOCK + WAIT);
// ===================================
// This is the target.
// ===================================
returnValue = ctx.proceed();
// ===================================
tracer.traceIncident("EJB Interceptors", ctx.getTarget().getClass()
.getName(), ctx.getMethod().getName(), "Responses");
concur = concurrency.decrementAndGet();
tracer.trace(concur, "EJB Interceptors", ctx.getTarget().getClass()
.getName(), ctx.getMethod().getName(),
"Concurrent Invocations");
return returnValue;
} catch (Exception e) {
tracer.traceIncident("EJB Interceptors", ctx.getTarget().getClass()
.getName(), ctx.getMethod().getName(), "Exceptions");
throw e;
} finally {
tracer.endThreadInfoCapture("EJB Interceptors", ctx.getTarget()
.getClass().getName(), ctx.getMethod().getName());
tracer.traceIncident("EJB Interceptors", ctx.getTarget().getClass()
.getName(), ctx.getMethod().getName(), "Invocations");
}
}
如 清單 1 一樣,清單 2 包含一個大的插裝集,一般不推薦使用,此處僅作為一個例子使用。清單 2 中有以下幾點需要注意:
@AroundInvoke 注釋通過封裝 EJB 調用而將方法標記為一個截取程序。
方法調用一直沿著棧傳遞調用,可能傳遞到最終目標,或到下一個截取程序。因此,要在調用該方法前確定度量基准,在調用後跟蹤它。
傳入跟蹤方法的 InvocationContext 為截取程序提供全部有關調用的元數據,包括:
目標對象
目標方法名
所傳遞的參數
注意到這點是很重要的,因為該截取程序可以應用於很多不同的 EJB,因此要截取什麼類型的調用是無法預知的。擁有一個可以從截取程序內部訪問的元數據源是至關重要的:沒有這個源的話,只能得到很少的關於被截取調用的信息;您的指標可以展示出很多有趣的趨勢,但卻無法明確它們所指的是哪個操作。
從插裝的角度看,這些截取程序最有用之處在於您可以通過修改部署描述符而將它們應用於 EJB。清單 3 展示了樣例 EJB 的 ejb-jar.xml 部署描述符:
清單 3. EJB 3 截取程序部署描述符
<ejb-jar xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/ejb-jar_3_0.xsd" version="3.0">
<interceptors>
<interceptor>
<interceptor-class>
org.runtimemonitoring.interceptors.ejb.EJBTracingInterceptor
</interceptor-class>
<around-invoke>
<method-name>trace</method-name>
</around-invoke>
</interceptor>
</interceptors>
<assembly-descriptor>
<interceptor-binding>
<ejb-name>AA4H-HibernateService</ejb-name>
<interceptor-class>
org.runtimemonitoring.interceptors.ejb.EJBTracingInterceptor
</interceptor-class>
</interceptor-binding>
</assembly-descriptor>
</ejb-jar>
正如我在前面所提到過的,插裝截取程序對於基於上下文或者基於范圍/阈值的跟蹤是有用的。而 InvocationContext 中的 EJB 調用參數值是可用的,這加強了插裝截取程序的作用。這些值可以用於跟蹤范圍或其他上下文的復合名稱。考慮一下包含有 issueRemoteOperation(String region、Command command) 方法的 org.myco.regional.RemoteManagement 類中的 EJB 調用。EJB 接受一個命令,然後遠程調用根據域識別的服務器。在這個場景中,區域服務器遍布於一個廣泛的地理區域,每一個區域服務都有自己的 WAN 特性。這裡呈現的模式與 第 1 部分 中的 payroll-processing 例子類似,這是因為如果沒有明確命令到底被分配到哪一個區域的話,確定一個 EJB 調用的運行時間是很困難的。您可能已經預料到,從距離一個洲遠的區域調用的運行時間要比從隔壁調用的運行時間要長的多。但是您是可以從 InvocationContext 參數確定區域的,因此您只需將區域代碼添加到跟蹤復合名稱並按區域劃分性能數據,如清單 4 所示:
清單 4. EJB 3 截取程序實現上下文跟蹤
String[] prefix = null;
if(ctx.getTarget().getClass().getName()
.equals("org.myco.regional.RemoteManagement") &&
ctx.getMethod().getName().equals("issueRemoteOperation")) {
prefix = new String[]{"RemoteManagement",
ctx.getParameters()[0].toString(),
"issueRemoteOperation"};
}
// Now add prefix to the tracing compound name
Servlet 過濾器截取程序
Java Servlet API 提供了一個叫做過濾器(filter)的構造,它與 EJB 3 截取程序非常類似,含有無需源代碼的注入和元數據可用性。清單 5 展示了一個過濾器的 doFilter 方法,帶有縮略了的插裝。指標的復合名由過濾器類名和請求的統一資源標識符(Uniform Resource Identifier,URI)構建:
清單 5. servlet 過濾器截取程序方法
public void doFilter(ServletRequest req, ServletResponse resp,
FilterChain filterChain) throws IOException, ServletException {
String uri = null;
try {
uri = ((HttpServletRequest)req).getRequestURI();
tracer.startThreadInfoCapture(CPU + BLOCK + WAIT);
// ===================================
// This is the target.
// ===================================
filterChain.doFilter(req, resp);
// ===================================
} catch (Exception e) {
} finally {
tracer.endThreadInfoCapture("Servlets", getClass().getName(), uri);
}
}
清單 6 展示了清單 5 的過濾器的 web.xml 部署描述符的相關片斷:
清單 6. servlet 過濾器部署描述符
<web-app >
<filter>
<filter-name>ITraceFilter</filter-name>
<display-name>ITraceFilter</display-name>
<filter-class>org.myco.http.ITraceFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>ITraceFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>
EJB 客戶端截取程序與上下文傳遞
前面的例子側重於服務器端組件,但一些諸如客戶端截取這樣的插裝實現方法也是存在的。Ajax 客戶機可以注冊度量 XMLHttpRequest 運行時間的性能監聽器,並可以在下一個請求的參數列表末尾承載請求的 URI(對於復合名稱)和運行時間。有些 Java EE 服務器,如 JBoss,允許使用客戶端的截取程序,本質上這些截取程序與 EJB 3 截取程序所作的工作相同,並且它們也能夠承載下一個請求中的度量提交。
監控中的客戶端通常都會被忽視。所以下次聽到用戶抱怨您的應用程序太慢時,不要因為服務器端的監控確保服務器端是良好的就無視這些抱怨。客戶端的插裝可以確保您所度量的正是用戶所體驗的,它們可能不會總是與服務器端的指標一致。
一些 Java EE 實現支持的客戶端截取程序被實例化並綁定在 EJB 的客戶端。這意味著如果一個遠程客戶機通過遠程方法調用(Remote Method Invocation,RMI)協議調用服務器上的 EJB,則也可以從遠程客戶機無縫收集到性能數據。在遠程調用的任一端實現截取程序類都會實現在兩者間傳遞上下文的能力,從而獲取額外的性能數據。
下面的例子展示了一對截取程序,它們共享數據並獲得傳輸時間(傳送請求和響應的運行時間)以及客戶機方面對服務器的遠程請求的響應時間。該例子使用了 JBoss 應用服務器的客戶端和服務器端的 EJB 3 截取程序專有的實現。
這對截取程序通過在相同負載內承載上下文數據,將上下文數據作為 EJB 調用傳遞到同一個調用。上下文數據包括:
客戶端發出請求的時間:EJB 客戶機截取程序發出請求時的請求的時間戳
服務器端接收請求的時間:EJB 服務器端截取程序接收請求時的請求的時間戳
服務器端發送響應的時間:EJB 服務器端截取程序將響應回送給客戶機時的響應的時間戳
調用參數被當作一個棧結構,上下文數據通過這個結構進出參數。上下文數據由客戶端截取程序放入該調用中,再由服務器端截取程序取出,然後傳入到 EJB 服務器 stub。數據返回時則按此過程的逆向過程傳遞。圖 3 展示了這個流程:
圖3. 客戶機和服務器 EJB 截取程序的數據流
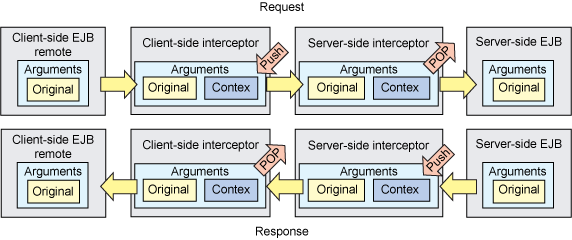
為這個例子構建截取程序需要為客戶機和服務器實現 org.jboss.aop.advice.Interceptor 接口。該接口有一個重要的方法:
public abstract java.lang.Object invoke(
org.jboss.aop.joinpoint.Invocation invocation) throws java.lang.Throwable
這個方法引入了調用封裝 的理念,根據這個理念,一個方法的執行被封裝成為一個獨立對象,它表示以下內容:
目標類
要調用的方法名
由作為實參傳入目標方法的參數組成的負載
接著這個對象可以被繼續傳遞,直至傳遞到調用方,調用方解組調用對象並針對端點目標對象實現動態執行。
客戶端截取程序將當前請求時間添加到調用上下文,而服務器端截取程序則負責添加接收請求的時間戳和發送響應的時間戳。或者,服務器可以獲得客戶機請求,由客戶機計算出請求和來回傳輸的總運行時間。每種情況的計算方法為:
客戶端,向上傳輸時間等於 ServerSideReceivedTime 減去 ClientSideRequestTime
客戶端,向下傳輸時間等於 ClientSideReceivedTime 減去 ServerSideRespondTime
服務器端,向上傳輸時間等於 ServerSideReceivedTime 減去 ClientSideRequestTime
清單 7 展示了客戶端截取程序的 invoke 方法:
清單 7. 客戶端截取程序的 invoke 方法
/**
* The interception invocation point.
* @param invocation The encapsulated invocation.
* @return The return value of the invocation.
* @throws Throwable
* @see org.jboss.aop.advice.Interceptor#invoke(org.jboss.aop.joinpoint.Invocation)
*/
public Object invoke(Invocation invocation) throws Throwable {
if(invocation instanceof MethodInvocation) {
getInvocationContext().put(CLIENT_REQUEST_TIME, System.currentTimeMillis());
Object returnValue = clientInvoke((MethodInvocation)invocation);
long clientResponseTime = System.currentTimeMillis();
Map<String, Serializable> context = getInvocationContext();
long clientRequestTime = (Long)context.get(CLIENT_REQUEST_TIME);
long serverReceiveTime = (Long)context.get(SERVER_RECEIVED_TIME);
long serverResponseTime = (Long)context.get(SERVER_RESPOND_TIME);
long transportUp = serverReceiveTime-clientRequestTime;
long transportDown = serverResponseTime-clientResponseTime;
long totalElapsed = clientResponseTime-clientRequestTime;
String methodName = ((MethodInvocation)invocation).getActualMethod().getName();
String className = ((MethodInvocation)invocation).getActualMethod()
.getDeclaringClass().getSimpleName();
ITracer tracer = TracerFactory.getInstance();
tracer.trace(transportUp, "EJB Client", className, methodName,
"Transport Up", transportUp);
tracer.trace(transportDown, "EJB Client", className, methodName,
"Transport Down", transportDown);
tracer.trace(totalElapsed, "EJB Client", className, methodName,
"Total Elapsed", totalElapsed);
return returnValue;
} else {
return invocation.invokeNext();
}
}
服務器端截取程序在概念上是類似的,不同的是為了避免使例子過於復雜,它使用了本地線程來檢查 reentrancy — 相同的請求處理線程在同一遠程調用中不只一次調用相同的 EJB(和截取程序)。該截取程序忽略了除第一個請求之外的所有請求的跟蹤和上下文處理。清單 8 展示了服務器端截取程序的 invoke 方法:
清單 8. 服務器端截取程序的 invoke 方法
/**
* The interception invocation point.
* @param invocation The encapsulated invocation.
* @return The return value of the invocation.
* @throws Throwable
* @see org.jboss.aop.advice.Interceptor#invoke(org.jboss.aop.joinpoint.Invocation)
*/
public Object invoke(Invocation invocation) throws Throwable {
Boolean reentrant = reentrancy.get();
if((reentrant==null || reentrant==false)
&& invocation instanceof MethodInvocation) {
try {
long currentTime = System.currentTimeMillis();
MethodInvocation mi = (MethodInvocation)invocation;
reentrancy.set(true);
Map<String, Serializable> context = getInvocationContext(mi);
context.put(SERVER_RECEIVED_TIME, currentTime);
Object returnValue = serverInvoke((MethodInvocation)mi);
context.put(SERVER_RESPOND_TIME, System.currentTimeMillis());
return addContextReturnValue(returnValue);
} finally {
reentrancy.set(false);
}
} else {
return invocation.invokeNext();
}
}
JBoss 通過面向方面的編程(aspect-oriented programming,AOP)(參見 參考資料)技術來應用截取程序,該技術讀取名為 ejb3-interceptors-aop.xml 的指令文件並根據其中定義的指令應用截取程序。JBoss 使用這種 AOP 技術在運行時將 Java EE 核心規則應用於 EJB 3 類。因此,除了性能監控截取程序之外,該文件還包含了關於事務管理、安全性和持久性這樣的指令。客戶端指令則相當簡單明了。它們被簡單地定義為包含一系列截取程序類名的 stack name XML 元素。每一個在此定義的類名同時都有資格作為 PER_VM 或 PER_INSTANCE 截取程序,這表明每一個 EJB 實例都應該共享一個截取程序實例或者具有各自的非共享實例。針對性能監控截取程序的目標,則應該確定此項配置,無論截取程序代碼是否是線程安全的。如果截取程序代碼能夠安全地並行處理多個線程,那麼使用 PER_VM 策略更有效,而對於線程安全但是效率較低的策略,則可以使用 PER_INSTANCE。
服務器端的截取程序的配置要相對復雜一些。截取程序要依照一組語法模式和用 XML 定義的過濾器來應用。如果所關注的特定的 EJB 方法與定義的模式相符的話,那麼為該模式定義的截取程序就會被應用。服務器端截取程序能夠通過進一步細化定義來將部署的 EJB 的特定子集定為目標。對於客戶端截取程序,您可以通過創建一個新的特定於目標 bean 的 stack name 來實現自定義棧。而在服務器端,自定義棧可以在一個新的 domain 中進行定義。個別 EJB 的關聯客戶機 stack name 和服務器棧 domain 可以在 EJB 的注釋中指定。或者,如果您不能或是不想修改源代碼的話,這些信息可以在 EJB 的部署描述符中指定或者跳過。清單 9 展示了一個刪減的用於此例的 ejb3-interceptors-aop.xml 文件:
清單 9. 經過刪減的 EJB 3 AOP 配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE aop PUBLIC
"-//JBoss//DTD JBOSS AOP 1.0//EN"
"http://labs.jboss.com/portal/jbossaop/dtd/jboss-aop_1_0.dtd">
<aop>
.
.
<interceptor
class="org.runtimemonitoring.ejb.interceptors.ClientContextualInterceptor"
scope="PER_VM"/>
.
.
<stack name="StatelessSessionClientInterceptors">
<interceptor-ref
name="org.runtimemonitoring.ejb.interceptors.ClientContextualInterceptor"/>
.
.
</stack>
.
.
<interceptor
class="org.runtimemonitoring.ejb.interceptors.ServerContextualInterceptor"
scope="PER_VM"/>
.
.
<domain name="Stateless Bean">
<bind pointcut="execution(public * *->*(..))">
<interceptor-ref name="org.aa4h.ejb.interceptors.ServerContextualInterceptor"/>
.
.
</bind>
</domain>
</aop>
這種性能數據收集方法可以一箭雙標。首先,它可以告訴您從客戶機的角度看,一個 EJB 目前的性能是多少。再者,如果性能滯後的話,傳輸時間可以很好地指明是否是由客戶機和服務器間的網絡連接速度緩慢而導致的。圖 4 展示了總運行時間和上/下傳輸指標,該指標是從客戶機度量的,度量方法是在客戶機和服務器之間使用一個人為減緩的網絡連接來突出顯示傳輸時間:
圖 4. 上下文客戶機截取程序性能指標
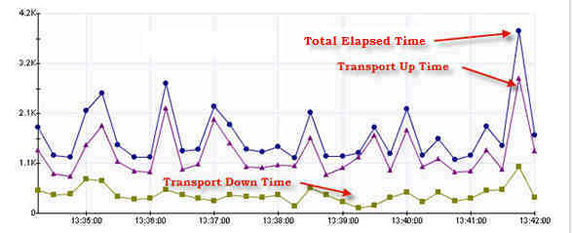
使用客戶端截取程序時,客戶機截取程序類本身必須處於客戶機應用程序的類路徑中。或者一定要啟用從服務器載入的遠程類,這樣才能夠在啟動時將客戶端截取程序及其依賴項下載到客戶機上。如果您的客戶機系統時鐘不是完全 與服務器系統時鐘同步的話,您就會得到與兩個時鐘的時間差大小成正比的特殊結果。
Spring 中的截取程序
盡管 Java EE 提供豐富的正交無縫截取方法,但很多流行的非 Java EE 容器同樣支持隱式的和顯式的截取。我之所以使用容器 這個詞是想暗指某種使用或鼓勵使用松散耦合的框架。只要不使用緊密耦合,就能夠實現截取。這種類型的框架通常稱為依賴注入 或者 Inversion of Control(IoC) 架構。它們讓您能夠在外部定義個別組件如何 “粘合” 在一起,而不是硬編碼組件,從而實現組件間的之間通信。我將使用流行的 IoC 框架 Spring Framework(參見 參考資料)中的跟蹤截取程序來查看性能數據的收集,以此結束對截取的討論。
Spring Framework 讓您能夠使用普通初始 Java 對象(Plain Old Java Object,POJO)來構建應用程序。POJO 僅包含業務邏輯,而 Spring 框架添加了構建企業應用程序所需的內容。如果在最初編寫 Java 應用程序時沒有考慮插裝的話,Spring 的分層架構是很有用處的。雖然將應用程序架構備份到 Spring 並非一無是處,但除一系列的 Java EE 和 AOP 集成外,還有 Spring 的 POJO 管理特性足以將普通硬連接的 Java 類委托給 Spring 的容器管理功能。您可以通過截取添加性能插裝,無需修改目標類的源代碼。
Spring 通常被描述為 IoC 容器,這是因為它顛倒了 Java 應用程序的傳統拓撲結構。在傳統的拓撲中,會有一個中心的程序或控制線程按照程序載入全部需要的組件和依賴項。容器用 IoC 載入幾個組件,並依照外部配置管理組件間的依賴項。此處的依賴項管理稱為依賴項注入,因為依賴項(如 JDBC DataSource)是通過容器注入組件的;組件無需尋找到它們自己的依賴項。為了進行插裝,容器的配置可以輕易修改,從而將截取程序插入到這些組件間的 “結締組織” 中。圖 5 解釋了該概念:
圖 5. Spring 和截取概觀
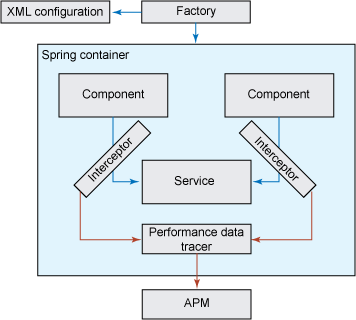
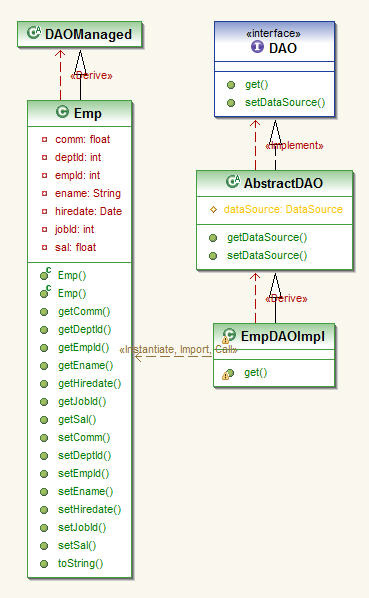
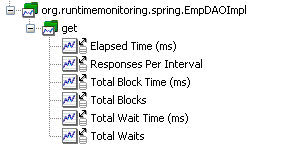
現在我將要展示一個簡單的用 Spring 截取的例子。它涉及一個 EmpDAOImpl 類,該類是一個基本的數據訪問對象(data access object,DAO)模式類,它實現了一個定義了名為 public Map<Integer, ? extends DAOManaged> get(Integer...pks) 的方法的 DAO 接口。該接口要求我傳入一組主鍵作為完整的對象,DAO 實現將返回對象的 Map。這個代碼中的依賴項的列表太長了,無法在此詳細說明。可以肯定地說,它沒有提供插裝的供應,並且不使用任何種類的對象關系映射(object-relational mapping,ORM)框架。圖 6 描述出了該類結構的輪廓。參見 下載,獲取此處提及的工件的完整源代碼和文本文件。
圖 6. EmpDAO 類
EmpDAOImpl 在由 spring.xml 文件配置時被部署到 Spring 容器,清單 10 中展示了該文件的一小部分:
清單 10. Spring 例子的基本容器配置
<beans>
<bean id="tracingInterceptor"
class="org.runtimemonitoring.spring.interceptors.SpringTracingInterceptor">
<property name="interceptorName" value="Intercepted DAO"/>
</bean>
<bean id="tracingOptimizedInterceptor"
class="org.runtimemonitoring.spring.interceptors.SpringTracingInterceptor">
<property name="interceptorName" value="Optimized Intercepted DAO"/>
</bean>
<bean id="DataSource"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close"
p:url="jdbc:postgresql://DBSERVER:5432/runtime"
p:driverClassName="org.postgresql.Driver"
p:username="scott"
p:password="tiger"
p:initial-size="2"
p:max-active="5"
p:pool-prepared-statements="true"
p:validation-query="SELECT CURRENT_TIMESTAMP"
p:test-on-borrow="false"
p:test-while-idle="false"/>
<bean id="EmployeeDAO" class="org.runtimemonitoring.spring.EmpDAOImpl"
p:dataSource-ref="DataSource"/>
<bean id="empDao" class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="proxyInterfaces" value="org.runtimemonitoring.spring.DAO"/>
<property name="target" ref="EmployeeDAO"/>
<property name="interceptorNames">
<list>
<idref local="tracingInterceptor"/>
</list>
</property>
</bean>
<bean id="empDaoOptimized"
class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="target" ref="EmployeeDAO"/>
<property name="optimize">
<value>true</value>
</property>
<property name="proxyTargetClass">
<value>true</value>
</property>
<property name="interceptorNames">
<list>
<idref local="tracingOptimizedInterceptor"/>
</list>
</property>
</bean>
</beans>
被部署的還有其他幾個對象。這些組件通過引用它們的 Spring bean id 來描述,這些 bean id 在清單 10 中的每一個 bean 元素中都可以看得見:
tracingInterceptor 和 tracingOptimizedInterceptor:兩個 SpringTracingInterceptor 類型的截取程序。這個類包含了將收集到的數據跟蹤到 APM 系統的 ITracer 調用。
DataSource:一個將 JDBC 連接匯合到名為 runtime 的樣例數據庫的 JDBC DataSource,該樣例數據庫將會被注入到 EmpDAOImpl。
EmployeeDAO:我將調用的 EmpDAOImpl 將作為例子的一部分調用。
empDao 和 empDaoOptimized:spring.xml 文件中定義的最後兩個 bean 為 Spring ProxyFactoryBean。它們本質上是 EmpDAOImpl 的代理,且每一個都各自引用一個截取程序。雖然 EmpDAOImpl 可以直接訪問,但是使用代理會調用截取程序並生成性能指標。清單 10 中的兩個代理和截取程序說明了一些差別和配置考慮。參見 優化的截取程序 側邊欄。
Spring 容器是從 SpringRunner 類中引導出來的。它還會啟動一個測試循環,針對四個目標調用 DAO.get:
EmployeeDAO Spring bean,它代表一個未用 Spring 插裝的托管 DAO。
empDao Spring bean,它代表一個用 Spring 插裝的托管的帶有標准截取程序的 DAO。
empDaoOptimized Spring bean,它代表一個用 Spring 插裝的托管的帶有優化截取程序的 DAO。
一個非 Spring 管理的 EmpDAOImpl,與 Spring 管理的 bean 相對。
Spring 通過一個名為 org.aopalliance.intercept.MethodInterceptor 的接口實現這些類型的截取程序。要實現的方法只有一個:public Object invoke(MethodInvocation invocation)throws Throwable。MethodInvocation 對象提供了兩個關鍵項:帶有某種上下文(即正在被截取的方法名)的跟蹤程序和 proceed 方法,該方法將調用向前引領到指定目標。
清單 11 展示了 SpringTracingInterceptor 類的 invoke 方法。在這種情況下是不需要 interceptorName 屬性的,但是我還是添加了這個屬性,目的是為這個例子提供輔助的上下文。對於一個多用途的截取程序實現,跟蹤程序通常都會將類名添加到跟蹤上下文,這樣所有被截取的類中的所有方法都會被跟蹤到單獨的 APM 名稱空間中。
清單 11. SpringTracingInterceptor 類的 invoke 方法
public Object invoke(MethodInvocation invocation) throws Throwable {
String methodName = invocation.getMethod().getName();
tracer.startThreadInfoCapture(WAIT+BLOCK);
Object returnValue = invocation.proceed();
tracer.endThreadInfoCapture("Spring", "DAO",
interceptorName, methodName);
tracer.traceIncident("Spring", "DAO", interceptorName,
methodName, "Responses Per Interval");
return returnValue;
}
SpringRunner 類是這個例子的主入口點。它初始化 Spring bean 工廠,然後開始一個長的循環,從而將負載置於每一個 bean 中。清單 12 展示了該循環的代碼。注意由於 daoNoInterceptor 和 daoDirect 不是通過 Spring 的截取程序插裝的,所以我在 SpringRunner 循環中手動添加了插裝。
清單 12. 縮略的 SpringRunner 循環
Map<Integer, ? extends DAOManaged> emps = null;
DAO daoIntercepted = (DAO) bf.getBean("empDao");
DAO daoOptimizedIntercepted = (DAO) bf.getBean("empDaoOptimized");
DAO daoNoInterceptor = (DAO) bf.getBean("EmployeeDAO");
DataSource dataSource = (DataSource) bf.getBean("DataSource");
DAO daoDirect = new EmpDAOImpl();
// Not Spring Managed, so dependency is set manually
daoDirect.setDataSource(dataSource);
for(int i = 0; i < 100000; i++) {
emps = daoIntercepted.get(empIds);
log("(Interceptor) Acquired ", emps.size(), " Employees");
emps = daoOptimizedIntercepted.get(empIds);
log("(Optimized Interceptor) Acquired ", emps.size(), "
Employees");
tracer.startThreadInfoCapture(WAIT+BLOCK);
emps = daoNoInterceptor.get(empIds);
log("(Non Intercepted) Acquired ", emps.size(), " Employees");
tracer.endThreadInfoCapture("Spring", "DAO",
"No Interceptor DAO", "get");
tracer.traceIncident("Spring", "DAO",
"No Interceptor DAO", "get", "Responses Per Interval");
tracer.startThreadInfoCapture(WAIT+BLOCK);
emps = daoDirect.get(empIds);
log("(Direct) Acquired ", emps.size(), " Employees");
tracer.endThreadInfoCapture("Spring", "DAO",
"Direct", "get");
tracer.traceIncident("Spring", "DAO", "Direct",
"get", "Responses Per Interval");
}
由 APM 系統報告的結果展示出了幾個類似的項。表 1 表明了來自每一個 Spring bean 的調用在測試運行中的平均運行時間:
表 1. Spring 截取程序測試運行結果
Spring bean 平均運行時間(ms) 最小運行時間(ms) 最大運行時間(ms) 計數 直接 145 124 906 5110 優化的截取程序 145 125 906 5110 無截取程序 145 124 891 5110 截取程序 155 125 952 5110
圖 7 顯示了在 APM 中為測試用例創建的指標樹。
圖 7. Spring 截取程序在測試運行中的 APM 指標樹

圖 8 以圖表的形式顯示了該數據:
圖 8. Spring 截取程序測試運行結果
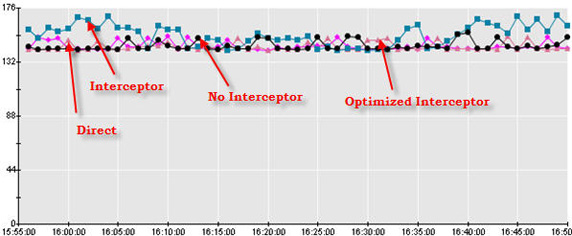
很明顯,這些結果相當緊密地聚集在了一起,但有一些模式顯現了出來。優化的截取程序的確稍微勝過了未優化的截取程序。然而,在這個測試運行中只運行了一個線程,所以比較分析的用處並不大。在下一節中,我將詳述這個測驗用例並實現多個線程。
通過類包裝實現的 JDBC 插裝
我發現造成大多數典型企業 Java 應用程序的慢性性能問題的根本原因在於數據庫接口。通過 JDBC 的數據庫調用或許是最普通的從 JVM 到外部服務的調用,目的是獲取 JVM 中在本地不可用的數據集或資源。所以問題的起因在於數據庫接口也不足為奇。邏輯上,在這種場景中可能出現問題的是數據庫客戶機、數據庫本身或者兩者兼有。然而,很多數據庫的面向客戶機的應用程序被許多性能反模式所困擾,包括:
邏輯上正確但執行很差的 SQL。
請求不夠具體,致使檢索到的數據要比所需的數據多得多。
頻繁地檢索相同的冗余數據。
請求基數小,導致大量數據庫請求為一個邏輯結構檢索數據,而不是少數的請求有效地檢索同一數據集(本人的數據庫訪問原則是寧可一個請求返回很多行和列,也不要多個請求檢索較短、較窄的數據集)。這個模式經常用於嵌套類結構,試圖應用正統的封裝概念(規定每一個對象管理它自己的數據檢索,而不可以委托給一個公用的統一的數據請求者)的開發人員也會使用到。
我當然不會違背每一個實例中的應用程序代碼和設計,在本系列的第 3 部分中,我將展示監控數據庫以進行性能統計的方法。但是基本上最有效的解決方案往往在客戶機一邊。因此,要監控 Java 應用程序中的數據庫接口性能,最好的監控目標就是 JDBC。
我將展示如何使用類包裝 的概念插裝 JDBC 客戶機。類包裝背後的理念是:目標類可以包裝在一層插裝代碼中,後者具有與被包裝的類相同的外部行為。這些場景的難題就在於怎樣可以在不改變依賴結構的情況下,無縫地引入被包裝的類。
在這個例子中,我利用了 JDBC 首先是一個完全由接口定義的 API 這一事實:規范包括的具體類很少,而且 JDBC 的架構排除了直接緊密耦合到特定於數據庫供應商提供的類的必要性。JDBC 的具體實現是被隱式加載的,而且源代碼很少直接引用這些具體類。正因為如此,您可以定義一個全新的無實現的 JDBC 驅動程序,無需將所有針對它的調用全部委托給下面的 “真正的” 驅動程序,並在過程中收集性能數據。
我構建了一個名為 WrappingJDBCDriver 的實現,它足可以展示性能數據收集和支持前面的 Spring 例子 中的 EmployeeDAO 測試用例。圖 9 展示了 WrappingJDBCDriver 的總體工作方式:
圖 9. WrappingJDBCDriver 概覽
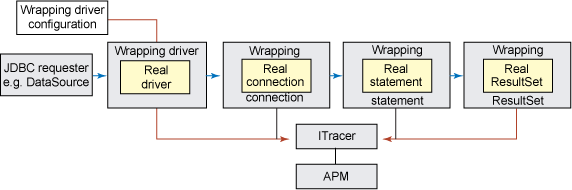
載入 JDBC 驅動程序的標准過程需要兩項:驅動程序的類名和連接的目標數據庫的 JDBC URL。驅動程序的加載程序載入驅動程序類(可能是通過調用 Class.forName(jdbcDriverClassName))。大多數 JDBC 驅動程序會在類加載時用 JDBC java.sql.DriverManager 注冊自己。然後驅動程序加載程序將 JDBC URL 傳入 JDBC 驅動程序的一個實例中,以測試驅動程序是否接受該 URL。假定 URL 被接受,加載程序就能夠對驅動程序調用 connect 並返回一個 java.sql.Connection。
包裝的驅動程序的類名為 org.runtimemonitoring.jdbc.WrappingJDBCDriver。當被實例化時,它會從類路徑中載入一個名為 wrapped-driver.xml 的配置文件。該文件包含插裝配置項,配置項使用與目標驅動程序相關的形象化(figurative)名稱索引:
<Figurative Name>.driver.prefix:JDBC 驅動程序的真正的 JDBC URL 前綴 — 例如,jdbc.postgresql。
<Figurative Name>.driver.class:JDBC 驅動程序的類名 — 例如,org.postgresql.Driver。
<Figurative Name>.driver.class.path:一連串由逗號隔開的通往 JDBC 驅動程序位置的類路徑入口。該項為可選項;如果不包括此項,WrappingJDBCDriver 會使用自己的類加載程序來定位驅動程序類。
<Figurative Name>.tracer.pattern.<Zero Based Index>:一連串的正則表達模式,用於為特定目標數據庫提取跟蹤類別。索引必須以 0 開始,由序列來定義跟蹤類別的層次結構。
WrappingJDBCDriver 的基本前提是配置 JDBC 客戶機應用程序,讓它使用 “被轉換的(munged)” JDBC URL,其他任何的 JDBC 驅動程序(包括以插裝為目標的)都無法識別這個 JDBC URL,因此除了 WrappingJDBCDriver 以外,不接受其他的 JDBC 驅動程序。WrappingJDBCDriver 將會識別被轉換的 URL、內部載入目標驅動程序並將其與被轉換的 URL 關聯。此時,被轉換的 URL 被 “解除轉換”,並會被委托給內部驅動程序以獲取與目標數據庫的真正的連接。然後這個真正的連接被包裝在 WrappingJDBCConnection 中,返回給請求應用程序。munge 算法是很基本的算法,只要它能夠使目標 “真正的” JDBC 驅動程序完全無法識別 JDBC URL。否則的話,真正的驅動程序可能會繞過 WrappingJDBCDriver。在這個例子中,我將 jdbc:postgresql://DBSERVER:5432/runtime 真正的 JDBC URL 轉換為 jdbc:!itracer!wrapped:postgresql://DBSERVER:5432/runtime。
“真正的” 驅動程序的類名和可選類路徑配置項的作用是允許 WrappingJDBCDriver 查找和載入驅動程序類,這樣它就能夠被包裝和委托了。跟蹤程序模式配置項是一組正則表達式,它們指導 WrappingJDBCDriver 如何為目標數據庫確定跟蹤名稱空間。這些表達式被應用於 “真正的” JDBC URL,並被利用,這樣跟蹤程序就能夠給按目標數據庫劃分的 APM 系統提供性能指標。由於 WrappingJDBCDriver 用於多個(可能是不同的)數據庫,因此按目標系統庫進行劃分是很重要的,這樣收集的指標就可以按目標數據庫進行分組了。例如,一個 jdbc:postgresql://DBSERVER:5432/runtime 的 JDBC URL 可能會生成一個 postgresql, runtime 的名稱空間。
清單 13 展示了一個樣例 wrapped-driver.xml 文件,它使用了映射到 PostgreSQL 8.3 JDBC Driver 的 postgres 的形象化的名稱:
清單 13. 樣例 wrapped-driver.xml 文件
<properties>
<entry key="postgres.driver.prefix">jdbc:postgresql:</entry>
<entry key="postgres.driver.class">org.postgresql.Driver</entry>
<entry key="postgres.driver.class.path">
C:\Postgres\psqlJDBC\postgresql-8.3-603.jdbc3.jar
</entry>
<entry key="postgres.tracer.pattern.0">:([a-zA-Z0-9]+):</entry>
<entry key="postgres.tracer.pattern.1">.*\/\/.*\/([\S]+)</entry>
</properties>
該部分實現受到了一個名為 P6Spy 的開源產品的啟發(參見 參考資料)。
為了展示 WrappingJDBCDriver 的使用方法,我創建了一個新的 EmpDAO Spring 測試用例的加強版。新的 Spring 配置文件是 spring-jdbc-tracing.xml,新的入口點類是 SpringRunnerJDBC。該測試用例包含幾個其他的對比測試點,所以為了更明確一些,一些命名約定被更新了。我還加強了測試用例使其成為多線程的,這樣就會在收集的指標中創建各種有趣的行為。而且,為了使之富於變化,DAO 的參數可以隨機化。
我為這個新測試用例添加了如下的跟蹤加強:
定義了兩個數據源。一個使用直接的 JDBC 驅動程序,另一個使用插裝的 JDBC 驅動程序。
這兩個數據源可以通過 Spring 代理隨意訪問,插裝這個代理的目的是監控獲取連接的運行時間。
DAO 截取程序被加強了,它能夠監控經過截取程序的並發線程的數量。
另外還衍生了另一個後台線程,用以輪詢數據源中統計信息的使用情況。
所有的 WrappingJDBC 類都通過基類 WrappingJDBCCore 調用了它們的大部分 跟蹤程序調用。該基類除了向它的 ITracer 發出一個直接傳遞(passthrough)外,還在數據庫實例級發出了 rollup 級別的跟蹤。這展示了 APM 系統中的一個常見的特性,憑此特性可以多次將低級的和特定指標跟蹤到更高級的名稱空間,提供匯總的指標。例如,任何對象類型中的全部 JDBC 調用都上升到數據庫級別,從而為所有的數據庫調用匯總平均運行時間和請求量。
清單 14 顯示了 spring-jdbc-tracing.xml 文件中的新 bean 定義的實例。注意在 InstrumentedJDBC.DataSource bean 中定義的 JDBC URL 使用了 munged 約定。
清單 14. spring-jdbc-tracing.xml 片段
<!-- A DataSource Interceptor -->
<bean id="InstrumentedJDBCDataSourceInterceptor"
class="org.runtimemonitoring.spring.interceptors.SpringDataSourceInterceptor">
<property name="interceptorName" value="InstrumentedJDBC.DataSource"/>
</bean>
<!-- A DataSource for Instrumented JDBC -->
<bean id="InstrumentedJDBC.DataSource"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close"
p:url="jdbc:!itracer!wrapped:postgresql://DBSERVER:5432/runtime"
p:driverClassName="org.runtimemonitoring.jdbc.WrappingJDBCDriver"
p:username="scott"
p:password="tiger"
p:initial-size="2"
p:max-active="10"
p:pool-prepared-statements="true"
p:validation-query="SELECT CURRENT_TIMESTAMP"
p:test-on-borrow="false"
p:test-while-idle="false"/>
<!-- The Spring proxy for the DataSource -->
<bean id="InstrumentedJDBC.DataSource.Proxy"
class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="target" ref="InstrumentedJDBC.DataSource"/>
<property name="optimize"><value>true</value></property>
<property name="proxyTargetClass"><value>true</value></property>
<property name="interceptorNames">
<list>
<idref local="InstrumentedJDBCDataSourceInterceptor"/>
</list>
</property>
</bean>
<!--
The Spring proxy for the DataSource which is injected into
the DAO bean instead of the DataSource bean itself.
-->
<bean id="InstrumentedJDBC.DataSource.Proxy"
class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="target" ref="InstrumentedJDBC.DataSource"/>
<property name="optimize"><value>true</value></property>
<property name="proxyTargetClass"><value>true</value></property>
<property name="interceptorNames">
<list>
<idref local="InstrumentedJDBCDataSourceInterceptor"/>
</list>
</property>
</bean>
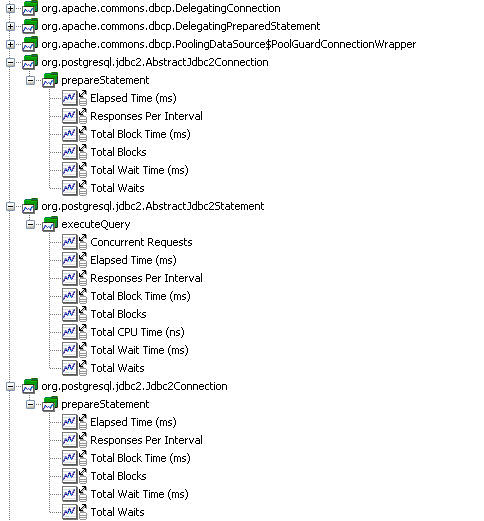
圖 10 顯示了這個測試用例的 APM 指標樹:
圖 10. 插裝的 JDBC 指標樹
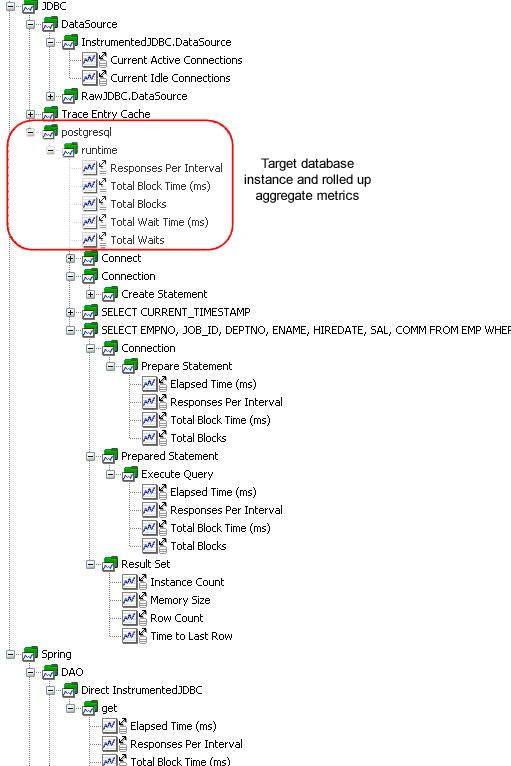
有了這個例子中的大量數據,就可以使用一些具體例子展示線程 BLOCK 和 WAIT 的起因。SpringRunnerJDBC 在每一個循環末尾的一個簡單的語句 Thread.currentThread().join(100) 周圍添加了一個 ThreadInfoCapture(WAIT+BLOCK) 跟蹤。依照 APM 系統,這顯示為一個平均為 103 ms 的線程等待。所以把一個線程置於等待某事發生的等待狀態時,它會導致一段等待時間。相反,當線程試圖從 DataSource 獲取連接時,它在訪問一個緊密同步的資源,而隨著競爭連接的線程數的增加,DAO.get 方法會明確顯示出增加了的線程阻塞數。
這個測試用例顯示了由於添加了插裝的和非插裝的數據源而導致的另外幾個 DAO.get bean 實例。表 2 展示了更新了的對比場景和數值結果的列表:
表 2. 插裝的 JDBC 測試運行結果
測試用例 平均運行時間(ms) 最小運行時間(ms) 最大運行時間(ms) 計數 直接訪問,原始 JDBC 5 0 78 12187 直接訪問,插裝的 JDBC 27 0 281 8509 無截取程序 Spring bean,原始 JDBC 15 0 125 12187 無截取程序 Spring bean,插裝的 JDBC 35 0 157 8511 插裝的 Spring bean,原始 JDBC 16 0 125 12189 插裝的 Spring bean,插裝的 JDBC 36 0 250 8511 優化的插裝 Spring bean,原始 JDBC 15 0 203 12188 優化的插裝 Spring bean,插裝的 JDBC 35 0 187 8511
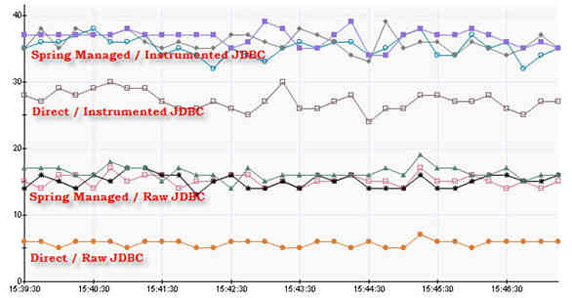
這些結果顯示出了一些有趣的模式,但有一點很明了:插裝的 JDBC 顯然要比原始 JDBC 慢。這一點告誡我們一定要竭盡所能改進和調試插裝。在這個基本的 JDBC 插裝示例中,造成性能差異的原因是使用了插入式跟蹤、較長的代碼路徑以及創建了大量額外的對象(用來執行一系列查詢)。如果我想在高性能環境中使用這個方法,則需要對這個代碼庫執行更多的工作!使用插裝的 DAO.get bean 會有另外一個明顯但不是很嚴重的影響。這還是要歸因於反射調用中的額外開銷、較長的代碼路徑和跟蹤活動。跟蹤適配器看起來好像也能使用一些調優,但事實是所有的插裝都會導致某種程度的開銷。圖 11 顯示了此測試的運行時間結果:
圖 11. 插裝的 JDBC 結果
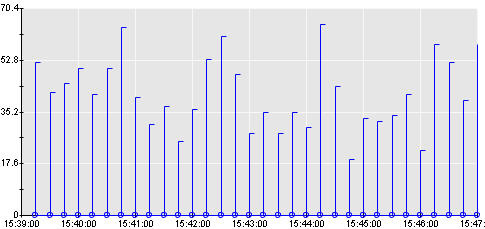
本節最後將介紹上升到數據庫級的線程阻塞時間。這些數據庫級的統計數字代表所有收集到的每個時間間隔內數據庫調用指標的總計值。運行時間為平均值,但是計數(每個時間間隔內的響應、阻塞和等待)為每個時間間隔內的總數。在這個測試用例中,總計的每個時間間隔內的平均阻塞時間為零,但是在圖 12 中,您可以觀察到一些 APM 可視化工具的一個特性。雖然平均值是零,但是每一個時間間隔都有一個最大(和最小)讀數。在這個圖中,我的 APM 顯示了一個空白的零行,它既表明了平均值也表明了最大值:
圖 12. JDBC 總計阻塞時間
在本文的最後一節中,我將介紹最後一個不改變源代碼插裝 Java 類的技巧:字節碼插裝。
字節碼插裝
到此為止,我向您展示的不基於源代碼的插裝都涉及到添加對象並經常延長代碼執行路徑,使它比跟蹤代碼本身的執行還要長。在字節碼插裝(BCI)技巧中,字節碼被直接插入到一個 Java 類中,從而獲得類最初不支持的功能。對於希望修改類而不觸及源代碼,或者希望在運行時動態修改類定義的開發人員,這個過程可以實現多種用途。我將向您展示如何使用 BCI 來將性能監控插裝注入到類中。
不同的 BCI 框架可以以不同的方式達到這個目的。有一個簡單的可以在方法級實現插裝的技巧:重新命名目標方法,並使用包含跟蹤指令並調用初始(重命名的)方法的原始簽名插入一個新方法。一個名為 JRat 的開源 BCI 工具演示了一個技巧,該技巧專門為方法執行收集運行時間,因此要比通用的 BCI AOP 工具(參見 參考資料)簡短。我將一個 JRat 項目的例子壓縮成了清單 15 所示的內容:
清單 15. 使用 BCI 的插裝方法示例
//////////////////////////////////////////////////////////////
// The Original Method
//////////////////////////////////////////////////////////////
public class MyClass {
public Object doSomething() {
// do something
}
}
//////////////////////////////////////////////////////////////
// The New and Old Method
//////////////////////////////////////////////////////////////
public class MyClass {
private static final MethodHandler handler = HandlerFactory.getHandler(...);
// The instrumented method
public Object doSomething() {
handler.onMethodStart(this);
long startTime = Clock.getTime();
try {
Object result = real_renamed_doSomething(); // call your method
handler.onMethodFinish(this, Clock.getTime() - startTime, null);
} catch(Throwable e) {
handler.onMethodFinish(this, Clock.getTime() - startTime, e);
throw e;
}
}
// The renamed original method
public Object real_renamed_doSomething() {
// do something
}
}
實現 BCI 的兩個常用策略為:
靜態:Java 類或者類庫被插裝,插裝的類被保存在原始類或類庫的副本中。然後這些副本被部署到一個應用程序,這個應用程序對插裝的類和其他的類一視同仁。
動態:在類載入過程中,Java 類在運行時被插裝。插裝的類僅暫存於內存中;JVM 結束後,它們就會消失。
動態 BCI 的優勢之一就在於提供了靈活性。動態 BCI 通常都是依照一組被配置的指令(通常位於一個文件中)執行。雖然它支持熱交換,但修改插裝只需要升級該文件和 JVM 周期就可以了。盡管動態 BCI 很簡單,但我還是要先分析靜態插裝過程。
靜態 BCI
在這個例子中,我將使用靜態 BCI 來插裝 EmpDAOImpl 類。我將使用 JBoss AOP,一個開源 BCI 框架(參見 參考資料)。
第一步:定義我要用來收集方法調用性能數據的截取程序,因為這個類將會被靜態編入 EmpDAOImpl 類的字節碼中。在這種情況下,JBoss 接口與我為 Spring 定義的截取程序是相同的,不同的是導入的類名。這個例子使用的截取程序是 org.runtimemonitoring.aop.ITracerInterceptor。第二步:使用與定義 EJB 3 截取程序的 jboss-aop.xml 相同的語法定義 jboss-aop.xml 文件。清單 16 顯示了該文件:
清單 16. 靜態 BCI jboss-aop.xml 文件
<aop>
<interceptor class="org.runtimemonitoring.aop.ITracerInterceptor" scope="PER_VM"/>
<bind
pointcut="execution(public * $instanceof{org.runtimemonitoring.spring.DAO}->get(..))">
<interceptor-ref name="org.runtimemonitoring.aop.ITracerInterceptor"/>
</bind>
</aop>
第三步:使用 JBoss 提供的名為 Aop Compiler(aopc)的工具來執行靜態插裝過程。用 Ant 腳本來完成這個過程是最簡單的。清單 17 展示了 Ant 任務和編譯器輸出的代碼片斷,該片斷表明我定義的切入點與目標類相匹配:
清單 17. aopc Ant 任務和輸出
<target name="staticBCI" depends="compileSource">
<taskdef name="aopc" classname="org.jboss.aop.ant.AopC"
classpathref="aop.lib.classpath"/>
<path id="instrument.target.path">
<path location="${classes.dir}"/>
</path>
<aopc compilerclasspathref="aop.class.path" verbose="true">
<classpath path="instrument.target.path"/>
<src path="${classes.dir}"/>
<aoppath path="${conf.dir}/jboss-aop/jboss-aop.xml"/>
</aopc>
</target>
Output:
[aopc] [trying to transform] org.runtimemonitoring.spring.EmpDAOImpl
[aopc] [debug] javassist.CtMethod@955a8255[public transient get
([Ljava/lang/Integer;)Ljava/util/Map;] matches pointcut:
execution(public * $instanceof{org.runtimemonitoring.spring.DAO}->get(..))
定義於 jboss-aop.xml 文件的切入點和 清單 16 中定義的切入點一樣實現了一個專用於 AOP 的語法,實現該語法的目的是為了提供一個表達力強的通配符語言來籠統地或是明確地定義切入點目標。實質上一個方法的任一標識屬性都可以從類和包名映射到注釋並返回類型。在 清單 17 中,我指定 org.runtimemonitoring.spring.DAO 的任何實例中的任何名為 get 的公共方法都應被作為目標。因此,由於 org.runtimemonitoring.spring.EmpDAOImpl 是惟一符合這個標准的具體類,所以只有這個類被插裝了。
到此為止,插裝就結束了。要運行啟用了這個插裝的 SpringRunner 測試用例,就必須在啟動 JVM 時用諸如 -Djboss.aop.path=[directory]/jboss-aop.xml 這樣的 JVM 參數把 jboss-aop.xml 文件的位置定義在系統屬性中。這樣做的前提是您可以獲得一些靈活性,因為 jboss-aop.xml 首先在構建時的靜態插裝中使用,然後再在運行時使用,這是由於您一開始可以插裝任意一個類,但在運行時卻僅能激活特定類。為 SpringRunner 測試用例生成的 APM 系統指標樹現在包含了 EmpDAOImpl 的指標。圖 13 展示了這個樹:
圖 13. 靜態 BCI 指標樹
雖然靜態插裝的確可以提供某種靈活性,但是若非靜態處理這些類(這很費力),就無法為插裝激活它們,這一點終究是有限制性的。而且,一旦類被靜態插裝,它們就只能為插裝時定義的截取程序激活。在下面的例子中,我將用動態 BCI 重復這個測試用例。
動態 BCI
完成動態 BCI 的方法很多,但是使用 Java 1.5 javaagent 接口有著一個很明顯的優勢。在此我將在更高的層面簡要描述這個接口;想要深入了解關於這個主題的知識,請參見 Andrew Wilcox 所著的文章 “構建自己的分析工具”(參見 參考資料)。
javaagent 通過兩個結構啟用運行時動態 BCI。首先,當用 -javaagent:a JAR file (這裡的命名的 JAR 文件包含一個 javaagent 實現)啟動 JVM 時,JVM 調用了在一個特殊清單條目中定義的類的一個 public static void premain(String args, Instrumentation inst) 方法。正如名稱 premain 所暗示的,這個方法是在主 Java 應用程序入口點前被調用的,該入口點允許調用的類優先訪問它,從而開始修改載入的類。關於這點它是通過注冊 ClassTransformer(第二個結構)實例來實現的。ClassTransformer 接口負責從類加載程序有效截取調用並動態重寫載入類的字節碼。ClassTransformer 的單個方法 — transform — 被傳入要重定義的類和包含類的字節碼的字節數組。然後 transform 方法實現各種修改,並返回一個包含修改的(或插裝的)類的字節碼的新字節數組。這種模型允許快速有效地傳輸類,並且與前面的一些方法不同,它不需要本地組件參與工作。
實現 SpringRunner 測試用例中的動態 BCI 有兩步:首先,必須重新編譯 org.runtimemonitoring.spring.EmpDAOImpl 類,將上面的測試用例中的靜態 BCI 移除。其次,JVM 啟動選項需要保留 -Djboss.aop.path=[directory]/jboss-aop.xml 選項,並且要按如下的方式添加 javaagent 選項:
-javaagent:[directory name]/jboss-aop-jdk50.jar
清單 18 展示了一個稍微修改過的 jboss-aop.xml 文件,它說明了動態 BCI 的優勢:
清單 18. 縮減的動態 BCI jboss-aop.xml 文件
<interceptor class="org.runtimemonitoring.aop.ITracerInterceptor"
scope="PER_VM"/>
<interceptor class="org.runtimemonitoring.aop.PreparedStatementInterceptor"
scope="PER_VM"/>
<bind
pointcut="execution(public * $instanceof{org.runtimemonitoring.spring.DAO}->get(..))">
<interceptor-ref name="org.runtimemonitoring.aop.ITracerInterceptor"/>
</bind>
<bind
pointcut="execution(public * $instanceof{java.sql.Connection}->prepareStatement(..))">
<interceptor-ref name="org.runtimemonitoring.aop.ITracerInterceptor"/>
</bind>
pointcut="execution(public * $instanceof{java.sql.PreparedStatement}->executeQuery(..))">
<interceptor-ref name="org.runtimemonitoring.aop.ITracerInterceptor"/>
</bind>
動態 BCI 的好處之一就是可以插裝任何類,包括第三方庫,所以清單 18 展示了 java.sql.Connection 所有實例的插裝。然而它更強大的能力是可以把任何(但可用的)截取程序應用到定義的切入點。例如,org.runtimemonitoring.aop.PreparedStatementInterceptor 是一個普通的但卻與 ITracerInterceptor 有些不同的截取程序。截取程序的整個庫(在 AOP 用語中常指方面(aspects))都可以被開發,並可以通過開源提供商獲得。這些方面庫可以提供廣泛的透視圖,根據您想要應用的插裝類型、要插裝的 API 的不同,或者兩者均不同,這些透視圖的用途也不一樣。
圖 14 展示了其他指標的指標樹。注意通過使用 Spring 中的 Jakarta Commons DataSource 提供者,有幾個類實現了 java.sql 接口。
圖 14. 動態 BCI 指標樹
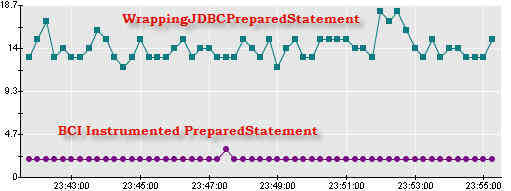
對比一下 WrappingJDBC 插裝技術和使用 BCI 插裝的驅動程序的性能差異,BCI 方法最大的優點就很明了了。這點在清單 15 中有所展示,清單 15 展示了 PreparedStatement.executeQuery 的對比運行時間:
圖 15. BCI 對比包裝性能
第 2 部分結束語
在這篇文章中我介紹了很多種插裝 Java 應用程序的方式,目的是為了跟蹤 APM 系統的性能監控數據。我所展現的這些技巧都不需要修改原始源代碼。到底哪一個方法更合適要視情況而定,但是可以確定的是 BCI 已經成為了主流。APM 系統是內部開發的、開源的、商用的系統,可以用它來為 Java 性能管理實現 BCI,要想實現性能良好且高度可用的系統,APM 系統必不可少。
本系列的第三部分也是最後一部分將介紹監控 JVM 外部資源的方式,包括主機和它們的操作系統以及諸如數據庫和通信系統這樣的遠程服務。它還總結了應用程序性能管理的其他問題,諸如數據管理、數據可視化、報告和警報。