簡介
當今的許多 Java 應用程序都依賴於一組復雜的分布式依賴關系和移動部件。很多外部因素都可能對應用程序的性能和可用性造成影響。這些影響基本上都無法完全消除或解決,且難以在預生成環境中准確模擬。Stuff happens。但是,您可以創建並維護一個全面的系統來監控應用程序的整個生態系統,從而顯著降低這些事件的嚴重性和持續時間。
本系列文章給出了實現此類系統的一些模式和技巧。模式,以及我將使用的一些術語,都表示泛指。通過結合示例代碼和插圖,它們將幫助您理解應用程序性能監控的概念。這種理解強調解決方案的必要性,並能幫助您選擇商業或開源的解決方案。您可以擴展和定制一個解決方案,或者根據需要將其作為設計解決方案的藍圖。
第 1 部分:
探究應用程序性能管理(APM)系統的屬性
描述系統監控的常見反面模式
列舉監控 JVM 性能的方法
提供有效插裝應用程序源代碼的方法
第 2 部分將重點介紹插裝 Java 類及資源而無需修改原始源代碼的方法。第 3 部分將論述監控 JVM 外部資源的方法,包括主機及其操作系統以及數據庫和消息傳遞系統等遠程服務。它還將總結並歸納其他的 APM 問題,如數據管理、數據虛擬化、報告和報警。
APM 系統:模式和反面模式
為讓大家正確入門,應當強調,雖然此處介紹的多數與 Java 相關的內容看上去與應用程序和代碼性能分析的流程類似,但其實並非 如此。性能分析是一個極具價值的生產前流程,它可以確認您的 Java 代碼是否可擴展、高效、快速和足夠出色。但是,根據 stuff happens 公理,當您在生產中遇到無法說明的問題時,優秀的開發階段代碼性能分析可能無用武之地。
我的意思是,在生產中實現性能分析的一些方面,並從運行中的應用程序收集一些相同的實時數據及其所有外部依賴關系。該數據由一系列遍及目標的定量測量指標組成,它們為整個系統的健康狀況提供細粒度和詳細的表示。此外,通過保留這些指標的歷史庫,您可以捕獲准確的基線,以幫助您確認環境仍然健康,或查明特定缺陷的根源和規模。
監控反面模式
完全沒有監控資源的應用程序微乎其微,但仍然需要考慮這些反面模式,它們經常出現在運行環境中:
盲點:某些系統依賴關系未受監控,或者監控數據不可訪問。運行中的數據庫可以覆蓋所有監控范圍,但如果受支持的網絡無法全面覆蓋,則診斷小組在分析數據庫性能和應用服務器症狀時將無法看到網絡中的故障。
黑盒:核心應用程序或者它的某個依賴關系對於其內部可能不具有監控透明性。JVM 是一個不折不扣的黑盒。舉例來說,診斷小組正在調查 JVM 中的莫名延時問題,並且只擁有支持操作系統的統計數據(如 CPU 利用率和進程需要的內存大小),則他們可能無法診斷垃圾收集或線程同步問題。
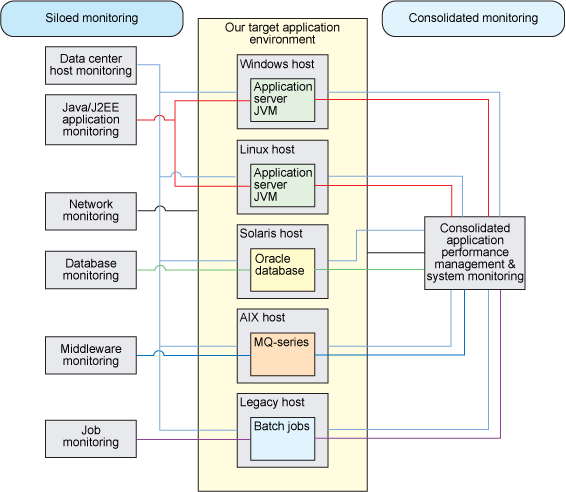
脫節和斷開的監控系統:應用程序可以由大型共享數據中心托管,其中,依賴關系由一系列共享資源組成,比如說數據庫、存儲區網絡(SAN)庫、消息傳遞及中間件服務。組織有時高度孤立,各小組只負責管理自己的監控和 APM 系統(請參閱 孤立監控的缺陷 側欄)。沒有各依賴關系的整合視圖,各組件所有者只能管中窺豹,只見一斑。
圖 1 對比了孤立和整合的 APM 系統:
圖 1. 孤立和整合 APM 系統的對比
事後報告和相關性:為嘗試解決孤立監控的問題,運營支持小組可以運行定期進程獲取各來源的數據,將這些數據整合到一個地方,然後再生成匯總報表。這種方法有時效率低下且不切實際,因為它需要按照指定頻率嚴格執行,而缺乏實時數據也會對診斷小組當場發現問題的能力產生負面影響。此外,事後聚合有時缺乏足夠的粒度,從而導致重要模式隱藏在數據中不被發覺。舉例來說,某個報告可能顯示某特定服務調用昨天平均耗時 200 毫秒,但卻隱藏了它在下午 1:00 到 1:45 間平均耗時 3500 毫秒。
定期或隨需應變的監控:由於某些工具強制占用較高的資源開銷,因此不能(或不應)經常使用它們。結果,它們很少收集數據,或者只在檢測到問題後才收集數據。因此,APM 系統只能執行最低基線,而無法在問題惡化前提前報警,並且可能會自己加劇勢態的嚴重性。
非持久化監控:許多工具都提供了有用的性能和可用性指標實時顯示功能,但它們並不支持持久化指標供長期或短期比較和分析的功能。常見的一種情況是,如果缺少歷史上下文,則性能指標將毫無價值,因為沒有判斷指標優劣的基准。舉例來說,當前的 CPU 利用率是 45%。如果不知道歷史利用率的情況,則不好判斷當前 CPU 利用率負荷的輕重程度。但是,如果知道歷史的典型值為百分之 x,可接受的用戶性能上限是百分之 y,則情況就大有改觀了。
對生產前模型的依賴:假設所有潛在問題都可在生產部署之前從環境中清除,則完全依賴生產前監控和系統模型的實踐經常會導致運行時監控不夠全面。這些假設無法解決不可預測事件和依賴性故障,因此,診斷小組在遇到此類事件時將沒有工具和數據可用。
整合 APM 的實現並不排除監控和診斷工具,如 DBA 管理工具集、低級網絡分析應用程序和數據中心管理解決方案。這些工具仍然是無價的資源,但如果它們依賴於整合視圖的專有性,則難以克服孤立效果的影響。
理想 APM 系統的屬性
與剛才討論的反面模式相反,本系列文章介紹的理想 APM 系統擁有以下屬性:
滲透力:它監控所有應用程序組件和依賴關系。
粒度化:它可以監控層次極低的函數。
整合性:收集的所有指標將被發送到支持整合視圖的同一邏輯 APM 中。
恆定:一周 7 天,一天 24 小時不間斷監控。
高效:性能數據收集不會對監控目標造成不利影響。
實時:可以實時顯示、報告和警告監控的資源指標。
歷史:監控的資源指標將持久化存儲在一個數據庫中,因此可以查看、比較和報告歷史數據。
在深入研究此系統的實現細節之前,了解 APM 系統的一些基本概念是有幫助的。
APM 系統概念
所有 APM 系統都能訪問性能數據源 並提供數據收集 和跟蹤 實用工具。注意,這些是我自己選擇的用於描述一般類別的通用術語。它們並非特定於任何 APM 系統,不同 APM 系統可以使用其他術語表示相同的概念。在本文的其余部分中,我所使用的術語定義如下。
性能數據源
性能數據源(PDS)是性能或可用性數據的來源,這些數據對於反映組件的相對健康狀況非常有用。例如,Java Management Extensions (JMX) 服務通常可以提供關於 JVM 健康狀況的豐富數據。大多數關系數據庫通過 SQL 接口發布性能數據。這兩種 PDS 都是直接 源的例子,即可以直接提供性能數據。相反,推斷 源測定有意和偶然操作,並且產生性能數據。例如,測試消息可以定期發送,並隨後從 Java Message Service (JMS) 服務器中取回,這個往返時間將作為該服務性能的推斷測量。
推斷源(它的實例被稱作綜合事務)有時極為有用,因為它們可以通過遍歷與實際活動相同的路徑來有效測定多個組件或分層調用。綜合事務還在監控連續性方面發揮著重要作用,當直接源不能勝任時,它們可以確認系統在相對空閒期的健康狀況。
收集和收集器
收集是從 PDS 獲取性能或可用性數據的流程。對於直接 PDS,收集器 通常實現一些 API 來訪問該數據。要從網絡路由器讀取統計數據,收集器可以使用簡單網絡管理協議(Simple Network Management Protocol,SNMP)或 Telnet。對於推斷 PDS,收集器用於執行和測定底層操作。
跟蹤和跟蹤程序
跟蹤是收集器向核心 APM 系統交付測量數據的流程。許多商業和開源 APM 系統都提供了一些用於此目的的 API。對於本文中的示例,我實現了一個通用的 Java 跟蹤程序接口,將在下節詳細討論。
通常,大多數 APM 系統將跟蹤程序提交的數據組織到某種分類的層次結構中。圖 2 展示了該數據捕獲的一般流程:
圖 2. 收集、跟蹤和 APM 系統
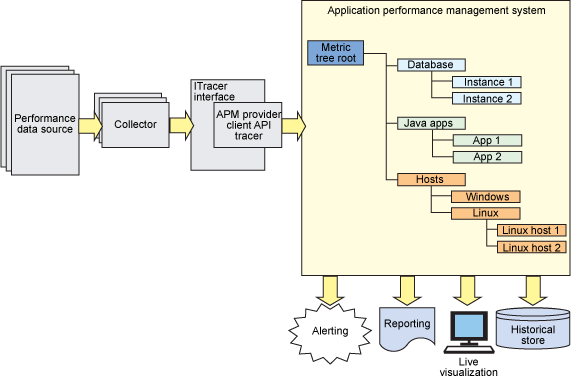
圖 2 還展示了 APM 系統提供的常用服務:
實時顯示:近乎實時顯示選定指標的圖表。
報告:生成的指標活動報告。這通常包括一系列固定報告和自定義報告,並能導出數據供用戶在別處使用。
歷史庫:包含原始或匯總指標的歷史數據庫,從而能夠查看特定時間范圍內的圖表和報告。
報警:將收集指標確定的具體條件通知相關個體或組的功能。典型的報警方法是電子郵件和某種類型的自定義鉤子接口,可以允許運營小組將事件傳播給事件處理系統。
公共跟蹤 API 在 APM 的目標環境中的實現和應用提供了一些一致性。此外,自定義收集器的目的是讓開發人員能夠專心獲取性能數據,而不必擔心跟蹤的問題。下一節將介紹解決此問題的 APM 跟蹤接口。
ITracer:跟蹤程序接口
Java 語言可以很好地充當收集器的實現語言,因為:
廣泛的平台支持。Java 收集器類可以在大多數目標平台上運行,而無需修改。這使監控架構可以在本地靈活地使用 PDS 合並收集器進程,而不需要使用遠程收集。
出色的性能(但是會隨可用資源而變化)。
健壯的並發和同步執行支持。
支持一組豐富的通信協議。
受第三方 API 的廣泛支持,比如 JDBC 實現、SNMP 和專用 Java 接口,因而能支持多種收集器庫。
受活躍開源社區的支持,它提供了額外的工具和接口,使語言能訪問或獲取大量來源的數據。
但是,有一點需要注意,您的 Java 收集器必須能夠與目標 APM 系統提供的跟蹤 API 相結合。如果您的 APM 跟蹤機制未提供 Java 接口,則它的一些模式將仍然適用。但是,如果目標 PDS 只基於 Java(如 JMX),而應用程序平台並不基於 Java,則需要一個橋接接口(如 IKVM)和一個 Java-to-.NET 編譯器(請參閱 參考資料)。
當缺少官方標准時,不同 APM 產品提供的跟蹤 API 也全然不同。因此,我通過實現一個通用的跟蹤 Java 接口(名稱為 org.runtimemonitoring.tracing.ITracer)抽象了此問題。ITracer 接口是針對專用跟蹤 API 的一個通用包裝器。此技巧將確保源代碼庫不會因版本或 API 提供程序而有所不同,並且還支持實現包裝 API 中不可用的額外功能。本文中的大多數其余示例都實現了 ITracer 接口和它所支持的一般底層概念。
圖 3 是 org.runtimemonitoring.tracing.ITracer 接口的 UML 類圖:
圖 3. ITracer 接口和工廠類

跟蹤類別和名稱
ITracer 的基本前提是向中央 APM 系統提交一個度量和相關的名稱。此活動由 trace 方法實現,該方法因提交的度量而有所不同。各 trace 方法都接受一個 String[] name 參數,其中包含復合名稱的上下文組件,其結構特定於 APM 系統。復合名稱向 APM 系統指示提交的名稱空間和實際的指標名稱;因此,復合名稱中通常至少包括根類別和度量說明。底層 ITracer 實現應該知道如何通過傳遞的 String[] 構建復合名稱。表 1 演示了復合命名約定的兩個示例:
表 1. 示例復合名稱
名稱結構 復合名稱 簡單斜槓分隔 Hosts/SalesDatabaseServer/CPU Utilization/CPU3 JMX MBean ObjectName com.myco.datacenter.apm:type=Hosts,service=SalesDatabaseServer,group=CPU Utilization,instance=CPU3
清單 1 是使用此 API 跟蹤調用的簡短示例:
清單 1. 跟蹤 API 調用示例
ITracer simpleTracer = TracerFactory.getInstance(sprops);
ITracer jmxTracer = TracerFactory.getInstance(jprops);
.
.
simpleTracer.trace(37, "Hosts", "SalesDatabaseServer",
"CPU Utilization", "CPU3", "Current Utilization %");
jmxTracer.trace(37,
"com.myco.datacenter.apm",
"type=Hosts",
"service=SalesDatabaseServer",
"group=CPU Utilization",
"instance=CPU3", "Current Utilization %");
);
跟蹤程序度量數據類型
在此接口中,度量數據可以是以下類型:
int
long
java.util.Date
String
APM 系統提供商可能支持其他數據類型的收集度量數據。
跟蹤程序類型
選定了具體的度量數據類型(如 long)之後,可以根據 APM 系統支持的類型來選擇解釋特定值的方式。還需記住,各 APM 實現可以使用不同的術語來表示本質相同的類型,並且 ITracer 使用了一些通用的命名規則。
ITracer 中表示的跟蹤程序類型:
平均時間間隔:trace(long value, String[] name) 和 trace(int value, String[] name) 方法將發出時間間隔平均值的跟蹤(請參閱 時間間隔 側欄)。這表示每個提交將被轉化為當前時間間隔的聚合值。當新時間間隔開始時,聚合值計數器將重置為零。
粘附: traceSticky(value long, String[] name) 和 traceSticky(value int, String[] name) 方法發出粘附值跟蹤。這表示,與時間間隔平均指標相反,聚合將它們的值保留在時間間隔中。如果現在跟蹤值 5,而此後不再執行跟蹤直到第二天某個時刻,則該指標將保持為 5,直到提供了新值。
增量:增量跟蹤將傳遞一個數值,但提供給 APM 系統(或由 APM 系統解釋)的實際值是此度量與前一度量之間的增量。它們有時被稱作 rate 類型,用於反映自己的性能優勢。請考慮事務管理程序的提交總數度量值。該數字始終在增加,並且其絕對值幾乎沒有用處。該數字有用的地方是它增加的速率,因此定期收集它的絕對值並跟蹤每次讀取數據之間的增量可以反映事務提交的速率。增量跟蹤比平均時間間隔和粘附方式的跟蹤更為常用,但仍有些用例采用了平均時間間隔。增量跟蹤必須能夠區分只能增加的度量和同時能增減的度量。小於前值的提交度量應被忽略或造成底層增量重置。
事件:這種類型是一種簡單的非聚合指標,它表示特定事件在時間間隔內發生的次數的增量計算。由於收集器和跟蹤程序都不期望知道特定時刻的運行總數,因此基本的 traceIncident(String[] name) 調用沒有指定任何值,並且隱式只增加一次事件增量。當需要計算多次增量時,除了在循環中多次調用該方法之外,另一種較好的方法是通過 traceIncident(int value, String[] name) 方法根據 value 來計算合值。
智能:智能跟蹤程序是一個參數化的類型,它與跟蹤程序中的某種其他類型相映射。度量值和跟蹤類型將作為 String 傳遞,並且可將可用類型作為常量定義在接口中。當收集器不知道正在收集的數據的類型或跟蹤程序類型時,這是一個非常方便的方法,但是也可以直接將收集值和配置的類型名稱傳遞給跟蹤程序。
TracerFactory 是一個普通的工廠類,用於根據傳遞的配置屬性創建新 ITracer 實例,或者從緩存中引用已創建的 ITracer。
收集器模式
收集通常有三種可選模式,這影響到應該使用的跟蹤程序類型:
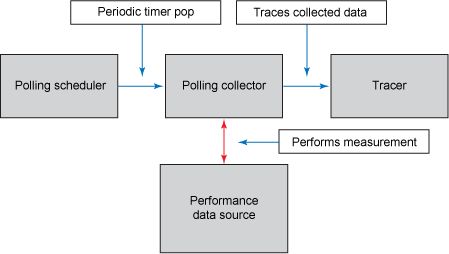
輪詢:按固定頻繁調用收集器,它將檢索和跟蹤 PDS 中的指標或指標集的當前值。例如,可以每分鐘調用一次收集器來讀取主機的 CPU 利用率,或通過 JXM 接口從事務管理器讀取提交事務的總數。輪詢模式的前提是對目標指標的定期采樣。因此,對於輪詢事件,指標的值將提供給 APM 系統,但是,假定中間時期的值不變。因而,輪詢收集器通常使用粘附跟蹤程序類型:APM 系統在生成報告時將假定所有輪詢事件之間的值不變。圖 4 演示了此模式:
圖 4. 輪詢收集模式
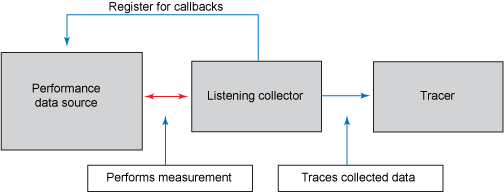
監聽:這種通用數據模式是 Observer 模式的一種形式。收集器將其自身注冊為目標 PDS 的事件監聽程序,它將在相關的事件發生時接受回調。作為回調結果發出的跟蹤值取決於回調有效負荷本身的內容,但收集器至少可以跟蹤每個回調的事件。圖 5 演示了此模式:
圖 5:監聽收集模式
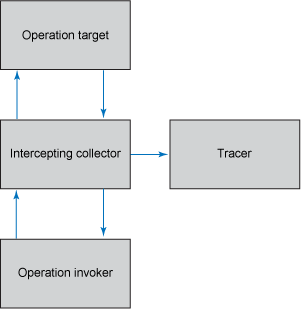
截取:在此模式中,收集器將自己作為截取程序插入到目標和它的調用程序之間。對於通過該截取程序的各個活動實例,截取程序將生成一個度量並跟蹤它。當截取模式是 request/response 時,收集器可以測定請求數量、響應時間、請求或響應的有效負荷。例如,HTTP 代碼服務器可以充當收集器,它可以:
計算請求數,可以選擇根據 HTTP 類型(GET 和 POST 等)或統一資源標識符(URI)來分類。
請求的響應時間。
測定請求和響應的大小。
由於您可以假定截取收集器能 “看到” 每一個事件,因此實現的跟蹤程序通常為平均時間間隔類型。因此,如果時間間隔到期且沒有活動發生,則該時間間隔的聚合值將為零,而與之前時間間隔中的活動無關。圖 6 演示了此模式:
圖 6. 截取收集模式
現在,我已經介紹了性能數據跟蹤 API、它的底層數據類型和數據收集的模式。接下來,我將通過一些用例和示例來演示 API 的應用。
監控 JVM
從 JVM 開始實現性能監控是個明智的選擇。首先,我將介紹所有 JVM 共同的性能指標,然後再介紹企業給應用程序中經常使用的一些 JVM 駐留組件。通常,Java 應用程序實例是受底層操作系統支持的進程,因此,JVM 監控的某些方面最好是從主機 OS 的視角來理解,這些內容將在第 3 部分中介紹。
在 Java Platform, Standard Edition 5 (Java SE) 發行之前,能夠在運行時有效和可靠收集的內部及標准化 JVM 診斷信息非常有限。現在,java.lang.management 接口提供了一些有用的監控點,該接口是所有兼容 Java SE 5(和更新版本)的 JVM 版本的標准。這些 JVM 的某些實現提供了額外的屬性指標,但是它們的訪問模式卻基本相同。我將重點介紹可以通過 JVM 的 MXBeans 訪問的標准模式 — 部署在 VM 內部的 JMX MBeans 公開了一個管理和監控接口(請參閱 參考資料):
ClassLoadingMXBean:監控類加載系統。
CompilationMXBean:監控編譯系統。
GarbageCollectionMXBean:監控 JVM 的垃圾收集器。
MemoryMXBean:監控 JVM 的堆和非堆內存空間。
MemoryPoolMXBean:監控 JVM 分配的內存池。
RuntimeMXBean:監控運行時系統。該 MXBean 提供的有用監控指標很少,但它確實提供了 JVM 的輸入參數和啟動時間及運行時間,這兩者在其他派生指標中都是很有用的。
ThreadMXBean:監控線程系統。
JMX 收集器的前提是它將獲取一個 MBeanServerConnection 對象,該對象可以讀取部署在 JVM 中的 MBeans 的屬性,讀取目標屬性的值,並使用 ITracer API 跟蹤它們。對於這種類型的收集,決定部署收集器的位置非常關鍵。可行的選擇包括本地部署 和遠程部署。
在本地部署中,收集器和它的調用調度程序部署在目標 JVM 中。隨後,JMX 收集器組件將使用 PlatformMBeanServer(可以通過 JVM 內部的 MBeanServerConnection 來連接它)訪問 MXBeans。在遠程部署中,收集器運行在一個單獨的進程中,並使用某種形式的 JMX Remoting 來連接目標 JVM。這可能沒有本地部署那麼高效,但它不需要在目標系統中部署任何額外的組件。JMX Remoting 不在本文的討論范圍之內,但它的實現方法非常簡單:部署一個 RMIConnectorServer 或在 JVM 中啟用外部連接(請參閱 參考資料)。
示例 JMX 收集器
本文的示例 JMX 收集器(請閱讀 下載 一節,獲取本文的完整源代碼)包含三個單獨的方法,可用於獲取 MBeanServerConnection。該收集器可以:
通過調用靜態 java.lang.management.ManagementFactory.getPlatformMBeanServer() 方法,為本地 JVM 的平台 MBeanServer 獲取一個 MBeanServerConnection。
通過調用靜態 javax.management.MBeanServerFactory.findMBeanServer(String agentId) 方法,為部署在本地 JVM 平台中的備用 MBeanServer 獲取一個 MBeanServerConnection。注意,一個 JVM 中可以存在多個 MBeanServer,並且,Java Platform, Enterprise Edition (Java EE) 服務器等較為復雜的系統幾乎始終擁有特定於應用服務器的 MBeanServer,它是獨立的且有別於平台 MBeanServer(請參閱 交叉注冊 MBeans 側邊欄)。
使用 javax.management.remote.JMXServiceURL 通過標准 RMI Remoting 獲取一個遠程 MBeanServerConnection。
清單 2 是摘錄自 JMXCollector collect() 方法的代碼段,它顯示了 ThreadMXBean 中的收集和線程跟蹤活動。點擊 此處 查看完整清單:
清單 2. 示例 JMX 收集器的 collect() 方法的部分代碼,它使用 ThreadMXBean
.
.
objectNameCache.put(THREAD_MXBEAN_NAME, new ObjectName(THREAD_MXBEAN_NAME));
.
.
public void collect() {
CompositeData compositeData = null;
String type = null;
try {
log("Starting JMX Collection");
long start = System.currentTimeMillis();
ObjectName on = null;
.
.
// Thread Monitoring
on = objectNameCache.get(THREAD_MXBEAN_NAME);
tracer.traceDeltaSticky((Long)jmxServer.getAttribute(on,"TotalStartedThreadCount"),
hostName, "JMX", on.getKeyProperty("type"), "StartedThreadRate");
tracer.traceSticky((Integer)jmxServer.getAttribute(on, "ThreadCount"), hostName,
"JMX", on.getKeyProperty("type"), "CurrentThreadCount");
.
.
// Done
long elapsed = System.currentTimeMillis()-start;
tracer.trace(elapsed, hostName, "JMX", "JMX Collector",
"Collection", "Last Elapsed Time");
tracer.trace(new Date(), hostName, "JMX", "JMX Collector",
"Collection", "Last Collection");
log("Completed JMX Collection in ", elapsed, " ms.");
} catch (Exception e) {
log("Failed:" + e);
tracer.traceIncident(hostName, "JMX", "JMX Collector",
"Collection", "Collection Errors");
}
}
清單 2 中的代碼將跟蹤 TotalThreadsStarted 和 CurrentThreadCount 的值。由於它是輪詢收集器,因此兩個跟蹤都使用粘附選項。但是,由於 TotalThreadsStarted 是一個不斷增加的數值,因此最吸引人的地方不是絕對值,而是已創建線程的速率。這樣,該跟蹤程序將使用 DeltaSticky 選項。
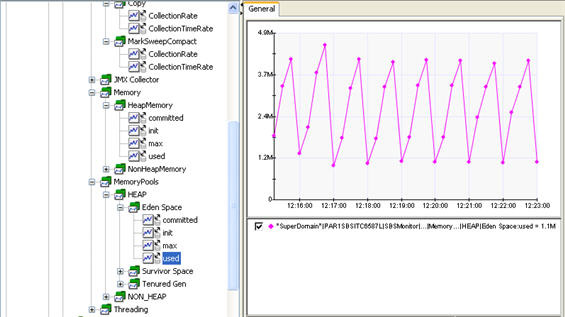
圖 7 顯示了此收集器創建的 APM 指標樹:
圖 7. JMX 收集器 APM 指標樹
JMX 收集器的一些方面並未顯示在清單 2 中(但是可以在 完整源代碼 中看到),比如說調度注冊,它將每隔 10 分鐘為 collect() 方法創建一個定期回調。
在清單 2 中,不同跟蹤程序類型和數據類型的實現方法將由數據源決定。例如:
TotalLoadedClasses 和 UnloadedClassCount 將作為粘附增量被跟蹤,因為它們的值始終遞增,而且增量在測定類加載活動方面比絕對值更加有用。
ThreadCount 變量可增加或減少,因此它將作為粘附類型被跟蹤。
收集錯誤 將作為內部事件被跟蹤,它將在收集遇到異常時遞增。
為了追求效率,由於目標 MXBeans 的 JMX ObjectName 在目標 JVM 的生存期不會更改,因此收集器使用 ManagementFactory 常量名來緩存名稱。
對於 MXBeans 的兩種類型 — GarbageCollector 和 MemoryPool — 准確的 ObjectName 無法預先知曉,但是您可以提供一個通用的模式。在這些情況下,在初次執行收集時,您將對 MBeanServerConnection 發起一個查詢,並請求與提供模式相匹配的所有 MBeans 的列表。為避免未來在目標 JVM 的生存期執行查詢,返回的匹配 MBean ObjectName 將緩存在內存中。
在某些情況下,收集的目標 MBean 屬性可能不是純數值類型。MemoryMXBean 和 MemoryPoolMXBean 就是這種情況。對於這些情況,屬性類型是可查詢鍵和值的 CompositeData 對象。對於 java.lang.management JVM 管理接口,MXBean 標准采用了 JMX Open Types 模型,在該模型中,所有屬性都是語言無關的類型,如 java.lang.Boolean 和 java.lang.Integer。或者,對於 javax.management.openmbean.CompositeType 等復雜類型,這些類型可以被分解為相同簡單類型的鍵/值對。簡單類型的完整列表枚舉在靜態 javax.management.openmbean.OpenType.ALLOWED_CLASSNAMES 字段中。該模型支持一個類型獨立層,使 JMX 客戶機不用依賴於非標准的類,並且還可以支持非 Java 客戶機,因為底層類型相對比較簡單。有關 JMX Open Types 的更多信息,請參閱 參考資料。
對於目標 MBean 屬性是非標准復雜類型的情況,您需要確保定義該類型的類在收集器的類路徑中。並且,您必須實現一些自定義代碼來呈現檢索到的復雜對象中的有用數據。
如果獲取了單個連接並為所有收集保留了該連接,則需要通過錯誤檢測和修復來創建一個新連接,以防止該連接出現故障。某些收集 API 提供斷開監控程序,可以提示收集器關閉、消除和創建新連接。如果收集器嘗試連接到由於維護而停機或由於其他原因而無法訪問的 PDS,則收集器應該以合適的頻率輪詢並重新連接。跟蹤連接的運行時間還可用於在檢測到關機時減少收集的頻率。這可以減少已超負荷運行了一段時間的目標 JVM 的開銷。
這些示例中未實現的兩個額外技巧可以改進 JMX 收集器的效率,並減少它在目標 JVM 中運行所需的開銷。第一個技巧適用於從一個 MBean 中查詢多個屬性的情況。借助 getAttributes(ObjectName name, String[] attributes),您可以在一個調用中請求多個屬性,而不必使用 getAttribute(ObjectName name, String attribute) 一次請求一個屬性。這種差異在本地收集中可以忽略,但是在遠程收集中卻可以顯著減少資源的使用,因為它可以減少網絡調用的數量。第二個技巧是使用監控收集模式代替輪詢模式,從而進一步減少 JMX 公開內存池的輪詢開銷。MemoryPoolMXBean 支持建立一個使用率閥值,超過該閥值時將觸發向監控程序發送一個通知,而監控程序將跟蹤該值。當內存使用率增加時,使用率閥值可以相應地增加。這種方法是缺陷是,如果使用率閥值沒有微小的增量,則一些粒度級的數據可能會丟失,並且閥值下方的內存使用率模式將變為不可見。
最後一個未實現的技巧是測定運行時間和垃圾收集總運行時間的范圍,並實現一些簡單的算法來計算垃圾收集器處於活動狀態的時間在已運行時間中的百分比。這是一個有用的指標,因為一些垃圾收集器(當前)是大多數應用程序必須要面對的問題。由於某些收集(分別執行了一段時間)是期望執行的,因此運行垃圾收集占用的時間可以更加清楚地反映 JVM 的內存健康狀況。根據經驗(因應用程序而大不相同),占用任何 15 分鐘時間段內的 10% 以上則表示存在潛在問題。
收集器的外部配置
為便於演示收集流程,本文介紹的 JMX 收集器經過了適當簡化,但它僅限於硬編碼的收集方式。理想情況下,收集器將實現數據訪問方式,而外部提供的配置將提供內容。這種設計使收集器更具實用性,且易於重用。對於最高級別的重用,外部配置的收集器應該支持這些配置點:
PDS 連接工廠指令,為收集器提供用於連接到 PDS 的接口,以及在連接時使用的配置。
執行收集的頻率。
嘗試重新連接的頻率。
收集的目標 MBean,或通配符形式的對象名稱。
對於各目標,跟蹤復合名稱或者應該跟蹤的度量片段,以及應該跟蹤的數據類型。
清單 3 演示了 JMX 收集器的外部配置:
清單 3. JMX 收集器的外部配置示例
<?xml version="1.0" encoding="UTF-8"?>
<JMXCollector>
<attribute name="ConnectionFactoryClassName">
collectors.jmx.RemoteRMIMBeanServerConnectionFactory
</attribute>
<attribute name="ConnectionFactoryProperties">
jmx.rmi.url=service:jmx:rmi://127.0.0.1/jndi/rmi://127.0.0.1:1090/jmxconnector
</attribute>
<attribute name="NamePrefix">AppServer3.myco.org,JMX</attribute>
<attribute name="PollFrequency">10000</attribute>
<attribute name="TargetAttributes">
<TargetAttributes>
<TargetAttribute objectName="java.lang:type=Threading"
attributeName="ThreadCount" Category="Threading"
metricName="ThreadCount" type="SINT"/>
<TargetAttribute objectName="java.lang:type=Compilation"
attributeName="TotalCompilationTime" Category="Compilation"
metricName="TotalCompilationTime" type="SDINT"/>
</TargetAttributes>
</attribute>
</JMXCollector>
注意,TargetAttribute 元素包含一個名為 type 的屬性,它表示智能類型跟蹤程序的參數化變量。SINT 類型表示粘附 int,SDINT 類型表示增量粘附 int。
通過 JMX 監控應用程序資源
目前為止,我已經討論了通過 JMX 監控惟一標准的 JVM 資源。但是,許多應用程序架構,如 Java EE,可以通過 JMX 公開重要的特定於應用程序的指標(這取決於供應商)。一個典型的例子是 DataSource 利用率。DataSource 是一個用於將連接池化到外部資源(通常為數據庫)的服務,這限制了並發連接的數量,以保護資源不受惡意應用程序的占用。監控數據源是整個監控計劃中的關鍵環節。由於 JMX 抽象層,該流程與之前介紹的類似。
下面是來自 JBoss 4.2 應用服務器實例的典型數據源指標:
可用連接數:當前池中可用連接的數量。
連接數:連接池與數據庫建立的實際物理連接的數量。
最大使用連接數:池中正在使用的連接的上限標記。
正在使用的連接數:當前正在使用的連接數量。
已創建的連接數:為該池創建的連接總數。
已部署的連接數:為該池部署的連接總數。
現在,收集器將使用批屬性檢索,並在一個調用中獲取所有屬性。惟一需要注意的是,您需要查詢返回的數據,以接通不同的數據和跟蹤程序類型。DataSource 指標在沒有活動時也是不會變化的,因此,要使數值變化,您需要生成一些負載。清單 4 顯示 DataSource 收集器的 collect() 方法:
清單 4. DataSource 收集器
public void collect() {
try {
log("Starting DataSource Collection");
long start = System.currentTimeMillis();
ObjectName on = objectNameCache.get("DS_OBJ_NAME");
AttributeList attributes = jmxServer.getAttributes(on, new String[]{
"AvailableConnectionCount",
"MaxConnectionsInUseCount",
"InUseConnectionCount",
"ConnectionCount",
"ConnectionCreatedCount",
"ConnectionDestroyedCount"
});
for(Attribute attribute: (List<Attribute>)attributes) {
if(attribute.getName().equals("ConnectionCreatedCount")
|| attribute.getName().equals("ConnectionDestroyedCount")) {
tracer.traceDeltaSticky((Integer)attribute.getValue(), hostName,
"DataSource", on.getKeyProperty("name"), attribute.getName());
} else {
if(attribute.getValue() instanceof Long) {
tracer.traceSticky((Long)attribute.getValue(), hostName, "DataSource",
on.getKeyProperty("name"), attribute.getName());
} else {
tracer.traceSticky((Integer)attribute.getValue(), hostName,
"DataSource",on.getKeyProperty("name"), attribute.getName());
}
}
}
// Done
long elapsed = System.currentTimeMillis()-start;
tracer.trace(elapsed, hostName, "DataSource", "DataSource Collector",
"Collection", "Last Elapsed Time");
tracer.trace(new Date(), hostName, "DataSource", "DataSource Collector",
"Collection", "Last Collection");
log("Completed DataSource Collection in ", elapsed, " ms.");
} catch (Exception e) {
log("Failed:" + e);
tracer.traceIncident(hostName, "DataSource", "DataSource Collector",
"Collection", "Collection Errors");
}
}
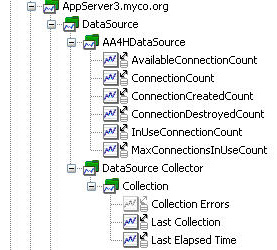
圖 8 顯示了 DataSource 收集器的相應指標樹:
圖 8. DataSource 收集器指標樹
監控 JVM 中的組件
本節介紹的技巧可用於監控應用程序組件、服務、類和方法。相關的主要區域如下:
調用速率:調用服務或方法的速率。
調用響應速率:服務或方法響應的速率。
調用錯誤率:服務或方法生成錯誤的比率。
調用運行時間:調用在每個間隔時間內的平均、最短和最長運行時間。
調用並發性:並發調用服務或方法時執行的線程數。
使用 Java SE 5(和更新版本)ThreadMXBean 的一些實現提供的指標,還可以收集以下指標:
系統和用戶 CPU 時間:調用某方法占用的 CPU 時間。
等待數量和總等待時間:調用某方法或服務時,等待線程的實例數量和總占用時間。當線程進入 WAITING 或 TIMED_WAITING 等待狀態並暫停另一個線程的活動時將發生等待事件。
阻塞數量和總阻塞時間:在調用某個方法或服務時,處於 BLOCKED 狀態的線程的實例數量和總占用時間。當線程等待監控鎖進入或重新進入同步阻塞時會發生阻塞事件。
還可以使用備選工具集和本機接口來確定這些指標和其他指標,但這通常涉及某種級別的開銷,從而造成不必要的生產運行時監控。已經說過,指標本身,甚至在收集時,是低級的。它們的作用也許僅限於分析趨勢,並且很難與無法通過其他手段確定的因果效應相關聯。
所有上述指標都可以通過插裝類和方法的流程來收集,以便於收集和跟蹤目標 APM 系統的性能數據。可以采用各種技巧來直接插裝 Java 類,或者通過它們來間接計算性能指標:
源代碼插裝:最基本的技巧是在源代碼階段添加插裝,這樣編譯和部署後的類就已經在運行時包含了插裝。在某些情況下,這種方法具有意義,並且一些特定的實踐使它成為可行的流程和投資。
截取:通過截取程序(執行測定和跟蹤)轉移調用,可以實現有效和准確的跟蹤,而無需接觸目標類、它們的源代碼和運行時字節碼。這種實踐簡單可取,因為存在許多 Java EE 框架和其他流行的 Java 框架:
通過配置支持抽象。
支持類注入和通過接口引用。
有某些情況下直接支持截取棧概念。執行流程經過定義了配置的對象棧,其作用是接收調用並執行一些處理,然後繼續傳遞。
字節碼插裝:該流程將字節碼注入到應用程序類中。注入的字節碼將添加性能數據收集插裝,該插裝被作為新類的一部分調用。這個流程有時極為有效,因為插裝是完全經過編譯的字節碼,並且代碼的執行路徑以最細化的方式擴展,同時仍然能夠收集數據。它的另一個優點是無需修改初始源代碼,並且其對環境的配置更改也可能最少。此外,通用模式和字節碼注入技巧允許對源代碼不可用的類和庫進行插裝,許多第三方類屬於這種情況。
類包裝:該流程使用另一個類來包裝或替換目標類,前者實現了相同功能,同時也包含了插裝。
在本文的第 1 部分中,我只討論基於源代碼的插裝;您將在第 2 部分中了解更多關於截取、字節碼插裝和類包裝的信息。(從拓撲學的角度來說,截取、字節碼插裝和類包裝的本質完全相同,但它們實現結果的操作有稍微不同的含義)。
異步插裝
異步插裝是類插裝中的基本問題。上一節討論了輪詢性能數據的概念。如果輪詢完成得足夠好,則它應該不會對核心應用程序性能或開銷造成影響。相反,插裝應用程序代碼本身會直接修改和影響核心代碼的執行。任何插裝的目標都必須是無論如何,不產生危害。開銷損失必須盡可能接近忽略不計。事實上,消除測量本身中的極細微的損失是不可能的,但是,在獲取性能數據之後,保持其余跟蹤進程異步是非常重要的。可以采用若干種模式來實現異步跟蹤。圖 9 演示了異步跟蹤的實現方法概覽:
圖 9. 異步跟蹤
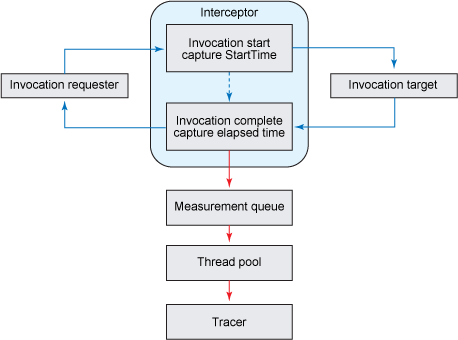
圖 9 演示了一個簡單的插裝截取程序,它通過捕獲調用的起始時間來測量它的運行時間,然後將測量數據(運行時間和指標復合名稱)分發給處理隊列。然後,線程池讀取該隊列,獲取測量數據並完成跟蹤流程。
源代碼中的 Java 類插裝
本節將討論如何實現源代碼級插裝,並將提供一些最佳實踐和示例代碼。文章還介紹了一些新的跟蹤結構,我將在源代碼插裝的上下文中闡明它們的操作和它們的插裝模式。
雖然其他選擇已經流行,但源代碼插裝在某些實例中是無法避免的;在某些情況下,它是惟一的解決方案。借助一些明智的預防措施,它可以實現良好的效果。需要考慮的事項包括:
如果插裝代碼的方案可用,並且無法實現配置更改來垂直影響插裝,則使用可配置和靈活的跟蹤 API 非常重要。
抽象的跟蹤 API 類似於事件記錄 API(如 log4j),它們的共用屬性包括:
運行時冗長控制:log4j 記錄程序和附加程序的冗長等級可以在系統啟動時配置,並隨後在運行時修改。同樣,跟蹤 API 應該能夠根據分級名稱模式來控制哪些指標名稱受跟蹤支持。
輸出端點配置:log4j 通過記錄程序發起記錄聲明,並將它分發給附加程序。經過配置,附加程序可以將記錄流發送給各種輸出,如文件、套接字和電子郵件。跟蹤 API 不需要多樣的輸出方式,但抽象專有或特定於 APM 系統的庫的能力將保護源代碼不受外部配置的更改。
在某些情況下,通過其他方法來跟蹤具體的項目不太可行。通常,我將這種情況稱作上下文跟蹤。我使用該術語描述的性能數據並不是很重要,但它為主要數據添加上下文。
上下文跟蹤
上下文跟蹤受具體的應用程序影響極大,但是可以考慮一個經過簡化的例子:含有 processPayroll(long clientId) 方法的 payroll-processing 類。當被調用時,該方法計算並存儲各客戶員工的薪水。您可以通過各種方法插裝該方法,但是,執行中的底層模式清楚表明,調用時間的增加與員工的數量不成比例。因此,研究 processPayroll 的運行時間趨勢沒有上下文可供參考,除非您知道程序每次處理的員工數量。簡單來講,對於特定的時間段,processPayroll 平均耗時 x 毫秒。無法確定這個值反映的性能是好還是壞,因為您不知道它處理的員工數量是 1 還是 150,而兩種情況反映的性能差別巨大。清單 5 在代碼中顯示了這個簡化的概念:
清單 5. 上下文跟蹤的例子
public void processPayroll(long clientId) {
Collection<Employee> employees = null;
// Acquire the collection of employees
//...
//...
// Process each employee
for(Employee emp: employees) {
processEmployee(emp.getEmployeeId(), clientId);
}
}
此處的主要挑戰是,根據大多數插裝技巧,processPayroll() 方法中的任何東西都是不可觸及的。因此,雖然能夠插裝 processPayroll 甚至 processEmployee,但是卻無法跟蹤員工的數量,從而不能為方法的性能數據提供上下文。清單 6 顯示了一個拙劣的硬編碼示例(且有點效率不高),它將捕獲上面提到的上下文數據:
清單 6. 上下文跟蹤示例
public void processPayrollContextual(long clientId) {
Collection<Employee> employees = null;
// Acquire the collection of employees
employees = popEmployees();
// Process each employee
int empCount = 0;
String rangeName = null;
long start = System.currentTimeMillis();
for(Employee emp: employees) {
processEmployee(emp.getEmployeeId(), clientId);
empCount++;
}
rangeName = tracer.lookupRange("Payroll Processing", empCount);
long elapsed = System.currentTimeMillis()-start;
tracer.trace(elapsed, "Payroll Processing", rangeName, "Elapsed Time (ms)");
tracer.traceIncident("Payroll Processing", rangeName, "Payrolls Processed");
log("Processed Client with " + empCount + " employees.");
}
清單 6 中的關鍵部分是 tracer.lookupRange 調用。Ranges 是指定的收集,它由數值范圍限制鍵控,並且擁有一個表示數值范圍名稱的 String 值。不再跟蹤薪水處理的簡單無格式運行時間,清單 6 將員工計數劃分為范圍,有效分隔運行時間並根據基本類似的員工計數將它們分組。圖 10 顯示了 APM 系統生成的指標樹:
圖 10:根據范圍分組的薪水處理時間
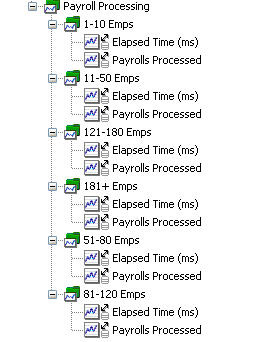
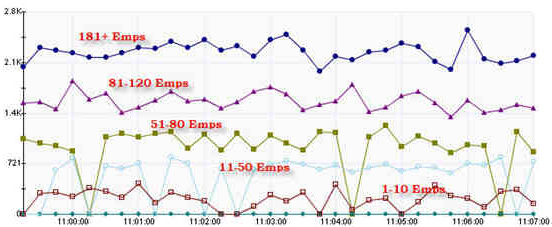
圖 11 演示了根據員工計數劃分的薪水處理運行的時間,它揭示了員工數量和運行時間之間的相互關系:
圖 11. 各范圍的薪水處理運行時間
跟蹤程序配置屬性允許在屬性文件中包括 URL,並能在其中定義范圍和閥值(我將簡單介紹一下閥值)。屬性將在跟蹤程序的構造時間被讀取,並為 tracer.lookupRange 實現提供後台數據。清單 7 顯示了 Payroll Processing 范圍的示例配置。我選擇使用 java.util.Properties 的 XML 表示,因為它更能兼容奇怪的字符。
清單 7. 范圍配置示例
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>Payroll Process Range</comment>
<entry key="L:Payroll Processing">181+ Emps,10:1-10 Emps,50:11-50 Emps,
80:51-80 Emps,120:81-120 Emps,180:121-180 Emps</entry>
</properties>
注入外部定義的范圍可以使您的應用程序不必頻繁更新源代碼,這受益於預期的調整和服務水平協議(SLA)在業務方面的變更。當范圍和閥值更改生效之後,您只需更新外部文件,而不是應用程序本身。
跟蹤閥值和 SLA
外部可配置上下文跟蹤的靈活性支持以更加准確和粒度化的方式來定義和測量性能閥值。范圍 定義一系列數值區間,可以在其中對測量數據進行分類,而閥值 是對范圍的進一步分類,它根據測量數據的確定范圍對獲取的測量數據進行分類。在分析收集的性能數據時,一個常見的需求是確定和報告執行是 “成功” 還是 “失敗”(因為它們未在指定時間發生)。這些數據的總和可以作為關於系統運行健康狀況和性能的通用成績單,或者作為某種形式的 SLA 遵從性評價。
使用薪水處理系統示例,考慮一個內部服務級目標,它將薪水的執行時間(在定義的員工數范圍之內)定義為 Ok、Warn 和 Critical 3 個區間。生成閥值計數的流程從概念上來說非常簡單。您只需為跟蹤程序提供您認為是各類別各區間的上限運行時間的值,並引導跟蹤程序為分類的運行時間發起一個 tracer.traceIncident,然後 — 為簡化報告 — 提供一個總數。表 2 顯示了一些經過設計的 SLA 運行時間:
表 2. 薪水處理閥值
員工數 Ok (ms) Warn (ms) Critical (ms) 1-10 280 400 >400 11-50 850 1200 >1200 51-80 900 1100 >1100 81-120 1100 1500 >1500 121-180 1400 2000 >2000 181+ 2000 3000 >3000
ITracer API 使用與范圍中相同的 XML(屬性)文件中定義的值實現了閥值報告。范圍和閥值定義在兩個方面稍有不同。首先,閥值定義的關鍵值是一個正則表達式。當 ITracer 在跟蹤一個數值時,它會檢查閥值正則表達式是否匹配被跟蹤指標的復合名稱。如果匹配,則閥值會將測量數據分類為 Ok、Warn 或 Critical,並為跟蹤附加一個額外的 tracer.traceIncident。其次,由於閥值只定義了兩個值(根據定義,Critical 值大於 warn 值),因此配置只由兩個數值組成。清單 8 顯示了之前介紹的薪水處理 SLA 的閥值配置:
清單 8. 薪水處理的閥值配置
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <!-- Payroll Processing Thresholds --> <entry key="Payroll Processing.*81-120 Emps.*Elapsed Time \(ms\)">1100,1500</entry> <entry key="Payroll Processing.*1-10 Emps.*Elapsed Time \(ms\)">280,400</entry> <entry key="Payroll Processing.*11-50 Emps.*Elapsed Time \(ms\)">850,1200</entry> <entry key="Payroll Processing.*51-80 Emps.*Elapsed Time \(ms\)">900,1100</entry> <entry key="Payroll Processing.*121-180 Emps.*Elapsed Time \(ms\)">1400,2000</entry> <entry key="Payroll Processing.*181\+ Emps.*Elapsed Time \(ms\)">2000,3000</entry> </properties>
圖 12 顯示添加了閥值指標的薪水處理的指標樹:
圖 12. 添加了閥值的薪水處理指標
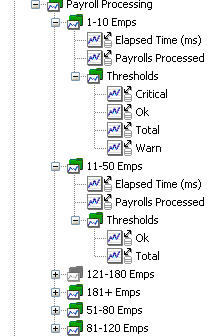
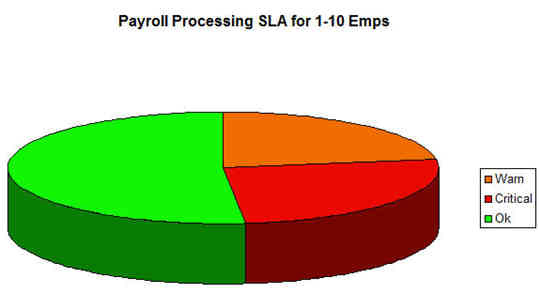
圖 13 演示了哪些收集的數據可以表示在餅形圖中:
圖 13. 薪水處理的 SLA 匯總(1 到 10 名員工)
確保查找上下文和閥值分類的效率和速度非常重要,因為它們在完成實際工作的線程中執行。在 ITracer 實現中,所有指標名稱在第一次被跟蹤程序發現時,將存儲在(線程安全)為具備和不具備閥值的指標指定的映射中。當特定指標的跟蹤事件發生後,閥值確定過程占用的時間是一個 Map 查找時間,它的速度通常足夠快。如果閥值條目或指標名稱的數量非常大,則一種合理的解決方案是推遲閥值確定,並在異步跟蹤線程池中處理它們。
第 1 部分結束語
本系列文章的第 1 部分介紹了一些監控反面模式和一些 APM 系統需要的屬性。我總結了一些通用性能數據收集模式,並介紹了 ITracer 接口,我將在本系列文章的其余部分繼續使用它。我已經演示了監控 JVM 健康狀況的技巧,以及如何通過 JMX 獲取通用性能數據。最後,我總結了各種實現高效和防代碼更改的源代碼級插裝方法(用於監控原始性能統計數據和上下文派生統計數據),以及如何使用這些統計數據生成關於應用程序 SLA 的報告。第 2 部分將探究插裝 Java 系統而無需修改應用程序源代碼的技巧,具體方法是使用截取、類包裝和動態字節碼插裝。
本文配套源碼