為應用程序添加搜索能力經常是一個常見的需求。本文介紹了一個框架,開發者可以使用它以最小的付出實現搜索引擎功能,理想情況下只需要一個配置文件。該框架基於若干開源的庫和工具,如 Apache Lucene,Spring 框架,cpdetector 等。它支持多種資源。其中兩個典型的例子是數據庫資源和文件系統資源。Indexer 對配置的資源進行索引並傳輸到中央服務器,之後這些索引可以通過 API 進行搜索。Spring 風格的配置文件允許清晰靈活的自定義和調整。核心 API 也提供了可擴展的接口。
引言
為應用程序添加搜索能力經常是一個常見的需求。盡管已經有若干程序庫提供了對搜索基礎設施的支持,然而對於很多人而言,使用它們從頭開始建立一個搜索引擎將是一個付出不小而且可能乏味的過程。另一方面,很多的小型應用對於搜索功能的需求和應用場景具有很大的相似性。本文試圖以對多數小型應用的適用性為出發點,用 Java 語言構建一個靈活的搜索引擎框架。使用這個框架,多數情形下可以以最小的付出建立起一個搜索引擎。最理想的情況下,甚至只需要一個配置文件。特殊的情形下,可以通過靈活地對框架進行擴展滿足需求。當然,如題所述,這都是借助開源工具的力量。
基礎知識
Apache Lucene 是開發搜索類應用程序時最常用的 Java 類庫,我們的框架也將基於它。為了下文更好的描述,我們需要先了解一些有關 Lucene 和搜索的基礎知識。注意,本文不關注索引的文件格式、分詞技術等話題。
什麼是搜索和索引
從用戶的角度來看,搜索的過程是通過關鍵字在某種資源中尋找特定的內容的過程。而從計算機的角度來看,實現這個過程可以有兩種辦法。一是對所有資源逐個與關鍵字匹配,返回所有滿足匹配的內容;二是如同字典一樣事先建立一個對應表,把關鍵字與資源的內容對應起來,搜索時直接查找這個表即可。顯而易見,第二個辦法效率要高得多。建立這個對應表事實上就是建立逆向索引(inverted index)的過程。
Lucene 基本概念
Lucene 是 Doug Cutting 用 Java 開發的用於全文搜索的工具庫。在這裡,我假設讀者對其已有基本的了解,我們只對一些重要的概念簡要介紹。要深入了解可以參考 參考資源 中列出的相關文章和圖書。下面這些是 Lucene 裡比較重要的類。
Document:索引包含多個 Document。而每個 Document 則包含多個 Field 對象。Document 可以是從數據庫表裡取出的一堆數據,可以是一個文件,也可以是一個網頁等。注意,它不等同於文件系統中的文件。
Field:一個 Field 有一個名稱,它對應 Document的一部分數據,表示文檔的內容或者文檔的元數據(與下文中提到的資源元數據不是一個概念)。一個 Field 對象有兩個重要屬性:Store ( 可以有 YES, NO, COMPACT 三種取值 ) 和 Index ( 可以有 TOKENIZED, UN_TOKENIZED, NO, NO_NORMS 四種取值 )
Query:抽象了搜索時使用的語句。
IndexSearcher:提供 Query 對象給它,它利用已有的索引進行搜索並返回搜索結果。
Hits:一個容器,包含了指向一部分搜索結果的指針。
使用 Lucene 來進行編制索引的過程大致為:將輸入的數據源統一為字符串或者文本流的形式,然後從數據源提取數據,創建合適的 Field 添加到對應數據源的 Document 對象之中。
系統概覽
要建立一個通用的框架,必須對不同情況的共性進行抽象。反映到設計需要注意兩點。一是要提供擴展接口;二是要盡量降低模塊之間的耦合程度。我們的框架很簡單地分為兩個模塊:索引模塊和搜索模塊。索引模塊在不同的機器上各自進行對資源的索引,並把索引文件(事實上,下面我們會說到,還有元數據)統一傳輸到同一個地方(可以是在遠程服務器上,也可以是在本地)。搜索模塊則利用這些從多個索引模塊收集到的數據完成用戶的搜索請求。
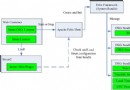
圖 1 展現了整體的框架。可以看到,兩個模塊之間相對是獨立的,它們之間的關聯不是通過代碼,而是通過索引和元數據。在下文中,我們將會詳細介紹如何基於開源工具設計和實現這兩個模塊。
圖 1. 系統架構圖
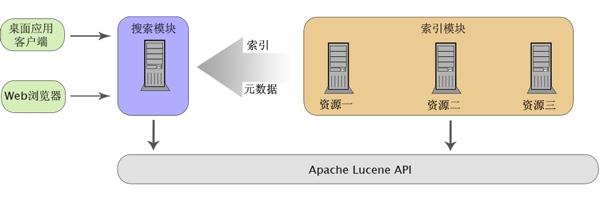
建立索引
可以進行索引的對象有很多,如文件、網頁、RSS Feed 等。在我們的框架中,我們定義可以進行索引的一類對象為資源。從實現細節上來說,從一個資源中可以提取出多個 Document 對象。文件系統資源和數據庫結果集資源都是資源的代表性例子。
前面提到,從資源中收集到的索引被統一傳送到同一個地方,以被搜索模塊所用。顯然除了索引之外,搜索模塊需要對資源有更多的了解,如資源的名稱、搜索該資源後搜索結果的呈現格式等。這些額外的附加信息稱為資源的元數據。元數據和索引數據一同被收集起來,放置到某個特定的位置。
簡要地介紹過資源的概念之後,我們首先為其定義一個 Resource 接口。這個接口的聲明如下。
清單 1. Resource 接口
public interface Resource {
// RequestProcessor 對象被動地從資源中提取 Document,並返回提取的數量
public int extractDocuments(ResourceProcessor processor);
// 添加的 DocumentListener 將在每一個 Document 對象被提取出時被調用
public void addDocumentListener(DocumentListener l);
// 返回資源的元數據
public ResourceMetaData getMetaData();
}
其中元數據包含的字段見下表。在下文中,我們還會對元數據的用途做更多的介紹。
表 1. 資源元數據包含的字段
屬性 類型 含義 resourceName String 資源的唯一名稱 resourceDescription String 資源的介紹性文字 hitTextPattern String 當文檔被搜索到時,這個 pattern 規定了結果顯示的格式 searchableFields String[] 可以被搜索的字段名稱
而 DocumentListener 的代碼如下。
清單 2. DocumentListener 接口
public interface DocumentListener extends EventListener {
public void documentExtracted(Document doc);
}
為了讓索引模塊能夠知道所有需要被索引的資源,我們在這裡使用 Spring 風格的 XML 文件配置索引模塊中的所有組件,尤其是所有資源。您可以在 下載部分 查看一個示例配置文件。
為什麼選擇使用 Spring 風格的配置文件?
這主要有兩個好處:
僅依賴於 Spring Core 和 Spring Beans 便免去了定義配置機制和解析配置文件的負擔;
Spring 的 IoC 機制降低了框架的耦合性,並使擴展框架變得簡單;
基於以上內容,我們可以大致描述出索引模塊工作的過程:
首先在 XML 配置的 bean 中找出所有 Resource 對象;
對每一個調用其 extractDocuments() 方法,這一步除了完成對資源的索引外,還會在每次提取出一個 Document 對象之後,通知注冊在該資源上的所有 DocumentListener;
接著處理資源的元數據(getMetaData() 的返回值);
將緩存裡的數據寫入到本地磁盤或者傳送給遠程服務器;
在這個過程中,有兩個地方值得注意。
第一,對資源可以注冊 DocumentListener 使得我們可以在運行時刻對索引過程有更為動態的控制。舉一個簡單例子,對某個文章發布站點的文章進行索引時,一個很正常的要求便是發布時間更靠近當前時間的文章需要在搜索結果中排在靠前的位置。每篇文章顯然對應一個 Document 對象,在 Lucene 中我們可以通過設置 Document 的 boost 值來對其進行加權。假設其中文章發布時間的 Field 的名稱為 PUB_TIME,那麼我們可以為資源注冊一個 DocumentListener,當它被通知時,則檢測 PUB_TIME 的值,根據距離當前時間的遠近進行加權。
第二點很顯然,在這個過程中,extractDocuments() 方法的實現依不同類型的資源而各異。下面我們主要討論兩種類型的資源:文件系統資源和數據庫結果集資源。這兩個類都實現了上面的 接口。
文件系統資源
對文件系統資源的索引通常從一個基目錄開始,遞歸處理每個需要進行索引的文件。該資源有一個字符串數組類型的 excludedFiles 屬性,表示在處理文件時需要排除的文件絕對路徑的正則表達式。在遞歸遍歷文件系統樹的同時,絕對路徑匹配 excludedFiles 中任意一項的文件將不會被處理。這主要是考慮到一般我們只需要對一部分文件夾(比如排除可能存在的備份目錄)中的一部分文件(如 doc, ppt 文件等)進行索引。
除了所有文件共有的文件名、文件路徑、文件大小和修改時間等 Field,不同類型的文件需要有不同的處理方法。為了保留靈活性,我們使用 Strategy 模式封裝對不同類型文件的處理方式。為此我們抽象出一個 DocumentBuilder 的接口,該接口僅定義了一個方法如下:
清單 3. DocumentBuilder 接口
public interface DocumentBuilder {
Document buildDocument(InputStream is);
}
什麼是 Strategy 模式?
根據 Design patterns: Elements of reusable object orientated software 一書:Strategy 模式“定義一系列的算法,把它們分別封裝起來,並且使它們相互可以替換。這個模式使得算法可以獨立於使用它的客戶而變化。”
不同的 DocumentBuilder(Strategy) 用於從一個輸入流中讀取數據,處理不同類型的文件。對於常見的文件格式來說,都有合適的開源工具幫助進行解析。在下表中我們列舉一些常見文件類型的解析辦法。
文件類型 常用擴展名 可以使用的解析辦法 純文本文檔 txt 無需類庫解析 RTF 文檔 rtf 使用 javax.swing.text.rtf.RTFEditorKit 類 Word 文檔(非 OOXML 格式) doc Apache POI (可配合使用 POI Scratchpad) PowerPoint 演示文稿(非 OOXML 格式) xls Apache POI (可配合使用 POI Scratchpad) PDF 文檔 pdf PDFBox(可能中文支持欠佳) HTML 文檔 htm, html JTidy, Cobra
這裡以 Word 文件為例,給出一個簡單的參考實現。
清單 4. 解析純文本內容的實現
// WordDocument 是 Apache POI Scratchpad 中的一個類
Document buildDocument(InputStream is) {
String bodyText = null;
try {
WordDocument wordDoc = new WordDocument(is);
StringWriter sw = new StringWriter();
wordDoc.writeAllText(sw);
sw.close();
bodyText = sw.toString();
} catch (Exception e) {
throw new DocumentHandlerException("Cannot extract text from a Word document", e);
}
if ((bodyText != null) && (bodyText.trim().length() > 0)) {
Document doc = new Document();
doc.add(new Field("body", bodyText, Field.Store.YES, Field.Index.TOKENIZED));
return doc;
}
return null;
}
那麼如何選擇合適的 Strategy 來處理文件呢?UNIX 系統下的 file(1) 工具提供了從 magicnumber 獲取文件類型的功能,我們可以使用 Runtime.exec() 方法調用這一命令。但這需要在有 file(1) 命令的情況下,而且並不能識別出所有文件類型。在一般的情況下我們可以簡單地根據擴展名來使用合適的類處理文件。擴展名和類的映射關系寫在 properties 文件中。當需要添加對新的文件類型的支持時,我們只需添加一個新的實現 DocumentBuilder 接口的類,並在映射文件中添加一個映射關系即可。
數據庫結果集資源
大多數應用使用數據庫作為永久存儲,對數據庫查詢結果集索引是一個常見需求。
生成一個數據庫結果集資源的實例需要先提供一個查詢語句,然後執行查詢,得到一個結果集。這個結果集中的內容便是我們需要進行索引的對象。extractDocuments 的實現便是為結果集中的每一行創建一個 Document 對象。和文件系統資源不同的是,數據庫資源需要放入 Document 中的 Field 一般都存在在查詢結果集之中。比如一個簡單的文章發布站點,對其後台數據庫執行查詢 SELECT ID, TITLE, CONTENT FROM ARTICLE 返回一個有三列的結果集。對結果集的每一行都會被提取出一個 Document 對象,其中包含三個 Field,分別對應這三列。
然而不同 Field 的類型是不同的。比如 ID 字段一般對應 Store.YES 和 Index.NO 的 Field;而 TITLE 字段則一般對應 Store.YES 和 Index.TOKENIZED 的 Field。為了解決這個問題,我們在數據庫結果集資源的實現中提供一個類型為 Properties 的 fieldTypeMappings 屬性,用於設置數據庫字段所對應的 Field 的類型。對於前面的情況來說,這個屬性可能會被配置成類似這樣的形式:
ID = YES, NO
TITLE = YES, TOKENIZED
CONTENT = NO, TOKENIZED
配合這個映射,我們便可以生成合適類型的 Field,完成對結果集索引的工作。
收集索引
完成對資源的索引之後,還需要讓索引為搜索模塊所用。前面我們已經說過這裡介紹的框架主要用於小型應用,考慮到復雜性,我們采取簡單地將分布在各個機器上的索引匯總到一個地方的策略。
匯總索引的傳輸方式可以有很多方案,比如使用 FTP、HTTP、rsync 等。甚至索引模塊和搜索模塊可以位於同一台機器上,這種情況下只需要將索引進行本地拷貝即可。同前面類似,我們定義一個 Transporter 接口。
清單 5. Transporter 接口
public interface Transporter {
public void transport(File file);
}
以 FTP 方式傳輸為例,我們使用 Commons Net 完成傳輸的操作。
public void transport(File file) throws TransportException {
FTPClient client = new FTPClient();
client.connect(host);
client.login(username, password);
client.changeWorkingDirectory(remotePath);
transportRecursive(client, file);
client.disconnect();
}
public void transportRecursive(FTPClient client, File file) {
if (file.isFile() && file.canRead()) {
client.storeFile(file.getName(), new FileInputStream(file));
} else if (file.isDirectory()) {
client.makeDirectory(file.getName());
client.changeWorkingDirectory(file.getName());
File[] fileList = file.listFiles();
for (File f : fileList) {
transportRecursive(client, f);
}
}
}
對其他傳輸方案也有各自的方案進行處理,具體使用哪個 Transporter 的實現被配置在 Spring 風格的索引模塊配置文件中。傳輸的方式是靈活的。比如當需要強調安全性時,我們可以換用基於 SSL 的 FTP 進行傳輸。所需要做的只是開發一個使用 FTP over SSL 的 Transporter 實現,並在配置文件中更改 Transporter 的實現即可。
進行搜索
在做了這麼多之後,我們開始接觸和用戶關聯最為緊密的搜索模塊。注意,我們的框架不包括一個搜索的 Web 前端界面。但是類似這樣的界面可以在搜索模塊的基礎上方便地開發出來。基於已經收集好的索引進行搜索是個很簡單的過程。Lucene 已經提供了功能強大的 IndexSearcher 及其子類。在這個部分,我們不會再介紹如何使用這些類,而是關注在前文提到過的資源元數據上。元數據從各個資源所在的文件夾中讀取得到,它在搜索模塊中扮演重要的角色。
構建一個查詢
對不同資源進行搜索的查詢方法並不一樣。例如搜索一個論壇裡的所有留言時,我們關注的一般是留言的標題、作者和內容;而當搜索一個 FTP 站點時,我們更多關注的是文件名和文件內容。另一方面,我們有時可能會使用一個查詢去搜索多個資源的結果。這正是之前我們在前面所提到的元數據中 searchableFields 和 resourceName 屬性的作用。前者指出一個資源中哪些字段是參與搜索的;後者則用於在搜索時確定使用哪個或者哪些索引。從技術細節來說,只有有了這些信息,我們才可以構造出可用的 Query 對象。
呈現搜索結果
當從 IndexSearcher 對象得到搜索結果(Hits)之後,當然我們可以直接從中獲取需要的值,再格式化予以輸出。但一來格式化輸出搜索結果(尤其在 Web 應用中)是個很常見的需求,可能會經常變更;二來結果的呈現格式應該是由分散的資源各自定義,而不是交由搜索模塊來定義。基於上面兩個原因,我們的框架將使用在資源收集端配置結果輸出格式的方式。這個格式由資源元數據中的 hitTextPattern 屬性定義。該屬性是一個字符串類型的值,支持兩種語法
形如 ${field_name} 的子字符串都會被動態替換成查詢結果中各個 Document 內 Field 的值。
形如 $function(...) 的被解釋為函數,括號內以逗號隔開的符號都被解釋成參數,函數可以嵌套。
例如搜索“具體”返回的搜索結果中包含一個 Document 對象,其 Field 如下表:
Field 名稱 Field 內容 url http://example.org/article/1.html title 示例標題 content 這裡是具體的內容。
那麼如果 hitTextPatten 被設置為“<a href="${url}">${title}</a><br/>$highlight(${content}, 5, "<b>", "</b>")”,返回的結果經浏覽器解釋後可能的顯示結果如下(這只是個演示鏈接,請不要點擊):
示例標題
這裡是具體...
上面提到的 $highlight() 函數用於在搜索結果中取得最匹配的一段文本,並高亮顯示搜索時使用的短語,其第一個參數是高亮顯示的文本,第二個參數是顯示的文本長度,第三和第四個參數是高亮文本時使用的前綴和後綴。
可以使用正則表達式和文本解析來實現前面所提到的語法。我們也可以使用 JavaCC 定義 hitTextPattern 的文法,進而生成詞法分析器和語法解析器。這是更為系統並且相對而言不易出錯的方法。對 JavaCC 的介紹不是本文的重點,您可以在下面的 閱讀資源 中找到學習資料。
相關產品
下面列出的是一些與我們所提出的框架所相關或者類似的產品,您可以在 學習資料 中更多地了解他們。
IBM®OmniFind™Family
OmniFind 是 IBM 公司推出的企業級搜索解決方案。基於 UIMA (Unstructured Information Management Architecture) 技術,它提供了強大的索引和獲取信息功能,支持巨大數量、多種類型的文檔資源(無論是結構化還是非結構化),並為 Lotus®Domino®和 WebSphere®Portal 專門進行了優化。
Apache Solr
Solr 是 Apache 的一個企業級的全文檢索項目,實現了一個基於 HTTP 的搜索服務器,支持多種資源和 Web 界面管理,它同樣建立在 Lucene 之上,並對 Lucene 做了很多擴展,例如支持動態字段及唯一鍵,對查詢結果進行動態分組和過濾等。
Google SiteSearch
使用 Google 的站點搜索功能可以方便而快捷地建立一個站內搜索引擎。但是 Google 的站點搜索基於 Google 的網絡爬蟲,所以無法訪問受保護的站點內容或者 Intranet 上的資源。另外,Google 所支持的資源類型也是有限的,我們無法對其進行擴展。
SearchBlox™
SearchBlox 是一個商業的搜索引擎構建框架。它本身是一個 J2EE 組件,和我們的框架類似,也支持對網頁和文件系統等資源進行索引,進而進行搜索。
還需考慮的問題
本文介紹的思想試圖利用開源的工具解決中小型應用中的常見問題。當然,作為一個框架,它還有很多不足,下面列舉出一些可以進行改進的地方。
性能考慮
當需要進行索引的資源數目不多時,隔一定的時間進行一次完全索引不會占用很長時間。使用一台 2G 內存,Xeon 2.66G 處理器的服務器進行實際測試,發現對數據庫資源的索引占用的時間很少,一千多條記錄花費的時間在 1 秒到 2 秒之內。而對 1400 多個文件進行索引耗時大約十幾秒。但在大型應用中,資源的容量是巨大的,如果每次都進行完整的索引,耗費的時間會很驚人。我們可以通過跳過已經索引的資源內容,刪除已不存在的資源內容的索引,並進行增量索引來解決這個問題。這可能會涉及文件校驗和索引刪除等。
另一方面,框架可以提供查詢緩存來提高查詢效率。框架可以在內存中建立一級緩存,並使用如 OSCache 或 EHCache 實現磁盤上的二級緩存。當索引的內容變化不頻繁時,使用查詢緩存更會明顯地提高查詢速度、降低資源消耗。
分布式索引
我們的框架可以將索引分布在多台機器上。搜索資源時,查詢被 flood 到各個機器上從而獲得搜索結果。這樣可以免去傳輸索引到某一台中央服務器的過程。當然也可以基於實現了分布式哈希表 (DHT)的結構化 P2P 網絡,配合索引復制 (Replication),使得應用程序更為安全,可靠,有伸縮性。在 閱讀資料 中給出了 一篇關於構建分布式環境下全文搜索的可行性的論文。
安全性
目前我們的框架並沒有涉及到安全性。除了依賴資源本身的訪問控制(如受保護的網頁和文件系統等)之外,我們還可以從兩方面增強框架本身的安全性:
考慮到一個組織的搜索功能對不同用戶的權限設置不一定一樣,可以支持對用戶角色的定義,實行對搜索模塊的訪問控制。
在資源索引模塊中實現一種機制,讓資源可以限制自己暴露的內容,從而縮小索引模塊的索引范圍。這可以類比 robots 文件可以規定搜索引擎爬蟲的行為。
總結
通過上文的介紹,我們認識了一個可擴展的框架,由索引模塊和搜索模塊兩部分組成。它可以靈活地適應不同的應用場景。如果需要更獨特的需求,框架本身預留了可以擴展的接口,我們可以通過實現這些接口完成功能的定制。更重要的是這一切都是建立在開源軟件的基礎之上。希望本文能為您揭示開源的力量,體驗用開源工具組裝您自己的解決方案所帶來的莫大快樂。
本文配套源碼