1.引言
Hibernate是最流行的對象關系映射(ORM)引擎之一,它提供了數據持久化和查詢服務。
在你的項目中引入Hibernate並讓它跑起來是很容易的。但是,要讓它跑得好卻是需要很多時間和經驗的。
通過我們的使用Hibernate 3.3.1和Oracle 9i的能源項目中的一些例子,本文涵蓋了很多Hibernate調優技術。其中還提供了一些掌握Hibernate調優技術所必需的數據庫知識。
我們假設讀者對Hibernate有一個基本的了解。如果一個調優方法在Hibernate 參考文檔(下文簡稱HRD)或其他調優文章中有詳細描述,我們僅提供一個對該文檔的引用並從不同角度對其做簡單說明。我們關注於那些行之有效,但又缺乏文檔的調優方法。
2.Hibernate性能調優
調優是一個迭代的、持續進行的過程,涉及軟件開發生命周期(SDLC)的所有階段。在一個典型的使用Hibernate進行持久化的Java EE應用程序中,調優會涉及以下幾個方面:
業務規則調優
設計調優
Hibernate調優
Java GC調優
應用程序容器調優
底層系統調優,包括數據庫和OS。
沒有一套精心設計的方案就去進行以上調優是非常耗時的,而且很可能收效甚微。好的調優方法的重要部分是為調優內容劃分優先級。可以用Pareto定律(又稱“80/20法則”)來解釋這一點,即通常80%的應用程序性能改善源自頭20%的性能問題[5]。
相比基於磁盤和網絡的訪問,基於內存和CPU的訪問能提供更低的延遲和更高的吞吐量。這種基於IO的Hibernate調優與底層系統IO部分的調優應該優先於基於CPU和內存的底層系統GC、CPU和內存部分的調優。
范例1
我們調優了一個選擇電流的HQL查詢,把它從30秒降到了1秒以內。如果我們在垃圾回收方面下功夫,可能收效甚微——也許只有幾毫秒或者最多幾秒,相比HQL的改進,GC方面的改善可以忽略不計。
好的調優方法的另一個重要部分是決定何時優化[4]。
積極優化的提倡者主張開始時就進行調優,例如在業務規則和設計階段,在整個SDLC都持續進行優化,因為他們認為後期改變業務規則和重新設計代價太大。
另一派人提倡在SDLC末期進行調優,因為他們抱怨前期調優經常會讓設計和編碼變得復雜。他們經常引用Donald Knuth的名言“過早優化是萬惡之源” [6]。
為了平衡調優和編碼需要一些權衡。根據筆者的經驗,適當的前期調優能帶來更明智的設計和細致的編碼。很多項目就失敗在應用程序調優上,因為上面提到的“過早優化”階段在被引用時脫離了上下文,而且相應的調優不是被推遲得太晚就是投入資源過少。
但是,要做很多前期調優也不太可能,因為沒有經過剖析,你並不能確定應用程序的瓶頸究竟在何處,應用程序一般都是這樣演化的。
對我們的多線程企業級應用程序的剖析也表現出大多數應用程序平均只有20-50%的CPU使用率。剩余的CPU開銷只是在等待數據庫和網絡相關的IO。
基於上述分析,我們得出這樣一個結論,結合業務規則和設計的Hibernate調優在Pareto定律中20%的那個部分,相應的它們的優先級更高。
一種比較實際的做法是:
識別出主要瓶頸,可以預見其中多數是Hibernate、業務規則和設計方面的(其數量視你的調優目標而定;但三到五個是不錯的開端)。
修改應用程序以便消除這些瓶頸。
測試應用程序,然後重復步驟1,直到達到你的調優目標為止。
你能在Jack Shirazi的《Java Performance Tuning》[7]一書中找到更多關於性能調優階段的常見建議。
下面的章節中,我們會按照調優的大致順序(列在前面的通常影響最大)去解釋一些特定的調優技術。
3. 監控和剖析
沒有對Hibernate應用程序的有效監控和剖析,你無法得知性能瓶頸以及何處需要調優。
3.1.1 監控SQL生成
盡管使用Hibernate的主要目的是將你從直接使用SQL的痛苦中解救出來,為了對應用程序進行調優,你必須知道Hibernate生成了哪些 SQL。JoeSplosky在他的《The Law of Leaky Abstractions》一文中詳細描述了這個問題。
你可以在log4j中將org.hibernate.SQL包的日志級別設為DEBUG,這樣便能看到生成的所有SQL。你還可以將其他包的日志級別設為DEBUG,甚至TRACE來定位一些性能問題。
3.1.2 查看Hibernate統計
如果開啟hibernate.generate.statistics,Hibernate會導出實體、集合、會話、二級緩存、查詢和會話工廠的統計信息,這對通過SessionFactory.getStatistics()進行的調優很有幫助。為了簡單起見,Hibernate還可以使用MBean“org.hibernate.jmx.StatisticsService”通過JMX來導出統計信息。你可以在這個網站找到配置范例 。
3.1.3 剖析
一個好的剖析工具不僅有利於Hibernate調優,還能為應用程序的其他部分帶來好處。然而,大多數商業工具(例如JProbe [10])都很昂貴。幸運的是Sun/Oracle的JDK1.6自帶了一個名為“Java VisualVM” [11]的調試接口。雖然比起那些商業競爭對手,它還相當基礎,但它提供了很多調試和調優信息。
4. 調優技術
4.1 業務規則與設計調優
盡管業務規則和設計調優並不屬於Hibernate調優的范疇,但此處的決定對後面Hibernate的調優有很大影響。因此我們特意指出一些與Hibernate調優有關的點。
在業務需求收集與調優過程中,你需要知道:
數據獲取特性包括引用數據(reference data)、只讀數據、讀分組(read group)、讀取大小、搜索條件以及數據分組和聚合。
數據修改特性包括數據變更、變更組、變更大小、無效修改補償、數據庫(所有變更都在一個數據庫中或在多個數據庫中)、變更頻率和並發性,以及變更響應和吞吐量要求。
數據關系,例如關聯(association)、泛化(generalization)、實現(realization)和依賴(dependency)。
基於業務需求,你會得到一個最優設計,其中決定了應用程序類型(是OLTP還是數據倉庫,亦或者與其中某一種比較接近)和分層結構(將持久層和服務層分離還是合並),創建領域對象(通常是POJO),決定數據聚合的地方(在數據庫中進行聚合能利用強大的數據庫功能,節省網絡帶寬;但是除了像 COUNT、SUM、AVG、MIN和MAX這樣的標准聚合,其他的聚合通常不具有移植性。在應用服務器上進行聚合允許你應用更復雜的業務邏輯;但你需要先在應用程序中載入詳細的數據)。
范例2
分析員需要查看一個取自大數據表的電流ISO(Independent System Operator)聚合列表。最開始他們想要顯示大多數字段,盡管數據庫能在1分鐘內做出響應,應用程序也要花30分鐘將1百萬行數據加載到前端UI。經過重新分析,分析員保留了14個字段。因為去掉了很多可選的高聚合度字段,從剩下的字段中進行聚合分組返回的數據要少很多,而且大多數情況下的數據加載時間也縮小到了可接受的范圍內。
范例3
過24個“非標准”(shaped,表示每小時都可以有自己的電量和價格;如果所有24小時的電量和價格相同,我們稱之為“標准”)小時會修改小時電流交易,其中包括2個屬性:每小時電量和價格。起初我們使用Hibernate的select-before-update特性,就是更新24行數據需要24次選擇。因為我們只需要2個屬性,而且如果不修改電量或價格的話也沒有業務規則禁止無效修改,我們就關閉了select-before-update特性,避免了24次選擇。
4.2繼承映射調優
盡管繼承映射是領域對象的一部分,出於它的重要性我們將它單獨出來。HRD [1]中的第9章“繼承映射”已經說得很清楚了,所以我們將關注SQL生成和針對每個策略的調優建議。
以下是HRD中范例的類圖:
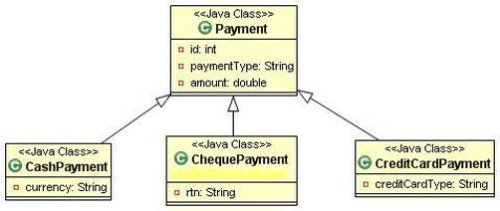
4.2.1 每個類層次一張表
只需要一張表,一條多態查詢生成的SQL大概是這樣的:
select id, payment_type, amount, currency, rtn, credit_card_type from payment
針對具體子類(例如CashPayment)的查詢生成的SQL是這樣的:
select id, amount, currency from payment where payment_type=’CASH’
這樣做的優點包括只有一張表、查詢簡單以及容易與其他表進行關聯。第二個查詢中不需要包含其他子類中的屬性。所有這些特性讓該策略的性能調優要比其他策略容易得多。這種方法通常比較適合數據倉庫系統,因為所有數據都在一張表裡,不需要做表連接。
主要的缺點整個類層次中的所有屬性都擠在一張大表裡,如果有很多子類特有的屬性,數據庫中就會有太多字段的取值為null,這為當前基於行的數據庫(使用基於列的DBMS的數據倉庫處理這個會更好些)的SQL調優增加了難度。除非進行分區,否則唯一的數據表會成為熱點,OLTP系統通常在這方面都不太好。
4.2.2每個子類一張表
需要4張表,多態查詢生成的SQL如下:
select id, payment_type, amount, currency, rtn, credit_card type,
case when c.payment_id is not null then 1
when ck.payment_id is not null then 2
when cc.payment_id is not null then 3
when p.id is not null then 0 end as clazz
from payment p left join cash_payment c on p.id=c.payment_id left join
cheque_payment ck on p.id=ck.payment_id left join
credit_payment cc on p.id=cc.payment_id;
針對具體子類(例如CashPayment)的查詢生成的SQL是這樣的:
select id, payment_type, amount, currency
from payment p left join cash_payment c on p.id=c.payment_id;
優點包括數據表比較緊湊(沒有不需要的可空字段),數據跨三個子類的表進行分區,容易使用超類的表與其他表進行關聯。緊湊的數據表可以針對基於行的數據庫做存儲塊優化,讓SQL執行得更好。數據分區增加了數據修改的並發性(除了超類,沒有熱點),OLTP系統通常會更好些。
同樣的,第二個查詢不需要包含其他子類的屬性。
缺點是在所有策略中它使用的表和表連接最多,SQL語句稍顯復雜(看看Hibernate動態鑒別器的長CASE子句)。相比單張表,數據庫要花更多時間調優數據表連接,數據倉庫在使用該策略時通常不太理想。
因為不能跨超類和子類的字段來建立復合索引,如果需要按這些列進行查詢,性能會受影響。任何子類數據的修改都涉及兩張表:超類的表和子類的表。
4.2.3每個具體類一張表
涉及三張或更多的表,多態查詢生成的SQL是這樣的:
select p.id, p.amount, p.currency, p.rtn, p. credit_card_type, p.clazz
from (select id, amount, currency, null as rtn,null as credit_card type,
1 as clazz from cash_payment union all
select id, amount, null as currency, rtn,null as credit_card type,
2 as clazz from cheque_payment union all
select id, amount, null as currency, null as rtn,credit_card type,
3 as clazz from credit_payment) p;
針對具體子類(例如CashPayment)的查詢生成的SQL是這樣的:
select id, payment_type, amount, currency from cash_payment;
優點和上面的“每個子類一張表”策略相似。因為超類通常是抽象的,所以具體的三張表是必須的[開頭處說的3張或更多的表是必須的],任何子類的數據修改只涉及一張表,運行起來更快。
缺點是SQL(from子句和union all子查詢)太復雜。但是大多數數據庫對此類SQL的調優都很好。
如果一個類想和Payment超類關聯,數據庫無法使用引用完整性(referential integrity)來實現它;必須使用觸發器來實現它。這對數據庫性能有些影響。
4.2.4使用隱式多態實現每個具體類一張表
只需要三張表。對於Payment的多態查詢生成三條獨立的SQL語句,每個對應一個子類。Hibernate引擎通過Java反射找出Payment的所有三個子類。
具體子類的查詢只生成該子類的SQL。這些SQL語句都很簡單,這裡就不再闡述了。
它的優點和上節類似:緊湊數據表、跨三個具體子類的數據分區以及對子類任意數據的修改都只涉及一張表。
缺點是用三條獨立的SQL語句代替了一條聯合SQL,這會帶來更多網絡IO。Java反射也需要時間。假設如果你有一大堆領域對象,你從最上層的Object類進行隱式選擇查詢,那該需要多長時間啊!
根據你的映射策略制定合理的選擇查詢並非易事;這需要你仔細調優業務需求,基於特定的數據場景制定合理的設計決策。
以下是一些建議:
設計細粒度的類層次和粗粒度的數據表。細粒度的數據表意味著更多數據表連接,相應的查詢也會更復雜。
如非必要,不要使用多態查詢。正如上文所示,對具體類的查詢只選擇需要的數據,沒有不必要的表連接和聯合。
“每個類層次一張表”對有高並發、簡單查詢並且沒有共享列的OLTP系統來說是個不錯的選擇。如果你想用數據庫的引用完整性來做關聯,那它也是個合適的選擇。
“每個具體類一張表”對有高並發、復雜查詢並且沒有共享列的OLTP系統來說是個不錯的選擇。當然你不得不犧牲超類與其他類之間的關聯。
采用混合策略,例如“每個類層次一張表”中嵌入“每個子類一張表”,這樣可以利用不同策略的優勢。隨著你項目的進化,如果你要反復重新映射,那你可能也會采用該策略。
“使用隱式多態實現每個具體類一張表”這種做法並不推薦,因為其配置過於繁缛、使用“any”元素的復雜關聯語法和隱式查詢的潛在危險性。
范例4
下面是一個交易描述應用程序的部分領域類圖:
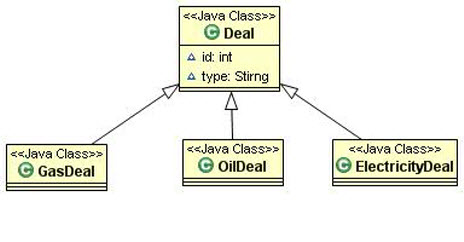
開始時,項目只有GasDeal和少數用戶,它使用“每個類層次一張表”。
OilDeal和ElectricityDeal是後期產生更多業務需求後加入的。沒有改變映射策略。但是ElectricityDeal有太多自己的屬性,因此有很多電相關的可空字段加入了Deal表。因為用戶量也在增長,數據修改變得越來越慢。
重新設計時我們使用了兩張單獨的表,分別針對氣/油和電相關的屬性。新的映射混合了“每個類層次一張表”和“每個子類一張表”。我們還重新設計了查詢,以便允許針對具體交易子類進行選擇,消除不必要的列和表連接。
4.3 領域對象調優
基於4.1節中對業務規則和設計的調優,你得到了一個用POJO來表示的領域對象的類圖。我們建議:
4.3.1 POJO調優
從讀寫數據中將類似引用這樣的只讀數據和以讀為主的數據分離出來。
只讀數據的二級緩存是最有效的,其次是以讀為主的數據的非嚴格讀寫。將只讀POJO標識為不可更改的(immutable)也是一個調優點。如果一個服務層方法只處理只讀數據,可以將它的事務標為只讀,這是優化Hibernate和底層JDBC驅動的一個方法。
細粒度的POJO和粗粒度的數據表。
基於數據的修改並發量和頻率等內容來分解大的POJO。盡管你可以定義一個粒度非常細的對象模型,但粒度過細的表會導致大量表連接,這對數據倉庫來說是不能接受的。
優先使用非final的類。
Hibernate只會針對非final的類使用CGLIB代理來實現延時關聯獲取。如果被關聯的類是final的,Hibernate會一次加載所有內容,這對性能會有影響。
使用業務鍵為分離(detached)實例實現equals()和hashCode()方法。
在多層系統中,經常可以在分離對象上使用樂觀鎖來提升系統並發性,達到更高的性能。
定義一個版本或時間戳屬性。
樂觀鎖需要這個字段來實現長對話(應用程序事務)[譯注:session譯為會話,conversion譯為對話,以示區別]。
優先使用組合POJO。
你的前端UI經常需要來自多個不同POJO的數據。你應該向UI傳遞一個組合POJO而不是獨立的POJO以獲得更好的網絡性能。
有兩種方式在服務層構建組合POJO。一種是在開始時加3.2載所有需要的獨立POJO,隨後抽取需要的屬性放入組合POJO;另一種是使用HQL投影,直接從數據庫中選擇需要的屬性。
如果其他地方也要查找這些獨立POJO,可以把它們放進二級緩存以便共享,這時第一種方式更好;其他情況下第二種方式更好。
4.3.2 POJO之間關聯的調優
如果可以用one-to-one、one-to-many或many-to-one的關聯,就不要使用many-to-many。
many-to-many關聯需要額外的映射表。
盡管你的Java代碼只需要處理兩端的POJO,但查詢時,數據庫需要額外地關聯映射表,修改時需要額外的刪除和插入。
單向關聯優先於雙向關聯。
由於many-to-many的特性,在雙向關聯的一端加載對象會觸發另一端的加載,這會進一步觸發原始端加載更多的數據,等等。
one-to-many和many-to-one的雙向關聯也是類似的,當你從多端(子實體)定位到一端(父實體)。
這樣的來回加載很耗時,而且可能也不是你所期望的。
不要為了關聯而定義關聯;只在你需要一起加載它們時才這麼做,這應該由你的業務規則和設計來決定(見范例5)。
另外,你要麼不定義任何關聯,要麼在子POJO中定義一個值類型的屬性來表示父POJO的ID(另一個方向也是類似的)。
集合調優
如果集合排序邏輯能由底層數據庫實現,就使用“order-by”屬性來代替“sort”,因為通常數據庫在這方面做得比你好。
集合可以是值類型的(元素或組合元素),也可以是實體引用類型的(one-to-many或many-to-many關聯)。對引用類型集合的調優主要是調優獲取策略。對於值類型集合的調優,HRD [1]中的20.5節“理解集合性能”已經做了很好的闡述。
獲取策略調優。請見4.7節的范例5。
范例5
我們有一個名為ElectricityDeals的核心POJO用於描述電的交易。從業務角度來看,它有很多many-to-one關聯,例如和 Portfolio、Strategy和Trader等的關聯。因為引用數據十分穩定,它們被緩存在前端,能基於其ID屬性快速定位到它們。
為了有好的加載性能,ElectricityDeal只映射元數據,即那些引用POJO的值類型ID屬性,因為在需要時,可以在前端通過portfolioKey從緩存中快速查找Portfolio:
<property name="portfolioKey" column="PORTFOLIO_ID" type="integer"/>
這種隱式關聯避免了數據庫表連接和額外的字段選擇,降低了數據傳輸的大小。
4.4 連接池調優
由於創建物理數據庫連接非常耗時,你應該始終使用連接池,而且應該始終使用生產級連接池而非Hibernate內置的基本連接池算法。
通常會為Hibernate提供一個有連接池功能的數據源。Apache DBCP的BasicDataSource[13]是一個流行的開源生產級數據源。大多數數據庫廠商也實現了自己的兼容JDBC 3.0的連接池。舉例來說,你也可以使用Oracle ReaApplication Cluster [15]提供的JDBC連接池[14]以獲得連接的負載均衡和失敗轉移。
不用多說,你在網上能找到很多關於連接池調優的技術,因此我們只討論那些大多數連接池所共有的通用調優參數:
最小池大小:連接池中可保持的最小連接數。
最大池大小:連接池中可以分配的最大連接數。
如果應用程序有高並發,而最大池大小又太小,連接池就會經常等待。相反,如果最小池大小太大,又會分配不需要的連接。
最大空閒時間:連接池中的連接被物理關閉前能保持空閒的最大時間。
最大等待時間:連接池等待連接返回的最大時間。該參數可以預防失控事務(runaway transaction)。
驗證查詢:在將連接返回給調用方前用於驗證連接的SQL查詢。這是因為一些數據庫被配置為會殺掉長時間空閒的連接,網絡或數據庫相關的異常也可能會殺死連接。為了減少此類開銷,連接池在空閒時會運行該驗證。
4.5事務和並發的調優
短數據庫事務對任何高性能、高可擴展性的應用程序來說都是必不可少的。你使用表示對話請求的會話來處理單個工作單元,以此來處理事務。
考慮到工作單元的范圍和事務邊界的劃分,有3中模式:
每次操作一個會話。每次數據庫調用需要一個新會話和事務。因為真實的業務事務通常包含多個此類操作和大量小事務,這一般會引起更多數據庫活動(主要是數據庫每次提交需要將變更刷新到磁盤上),影響應用程序性能。這是一種反模式,不該使用它。
使用分離對象,每次請求一個會話。每次客戶端請求有一個新會話和一個事務,使用Hibernate的“當前會話”特性將兩者關聯起來。
在一個多層系統中,用戶通常會發起長對話(或應用程序事務)。大多數時間我們使用Hibernate的自動版本和分離對象來實現樂觀並發控制和高性能。
帶擴展(或長)會話的每次對話一會話。在一個也許會跨多個事務的長對話中保持會話開啟。盡管這能把你從重新關聯中解脫出來,但會話可能會內存溢出,在高並發系統中可能會有舊數據。
你還應該注意以下幾點。
如果不需要JTA就用本地事務,因為JTA需要更多資源,比本地事務更慢。就算你有多個數據源,除非有跨多個數據庫的事務,否則也不需要 JTA。在最後的一個場景下,可以考慮在每個數據源中使用本地事務,使用一種類似“Last Resource Commit Optimization”[16]的技術(見下面的范例6)。
如果不涉及數據變更,將事務標記為只讀的,就像4.3.1節提到的那樣。
總是設置默認事務超時。保證在沒有響應返回給用戶時,沒有行為不當的事務會完全占有資源。這對本地事務也同樣有效。
如果Hibernate不是獨占數據庫用戶,樂觀鎖會失效,除非創建數據庫觸發器為其他應用程序對相同數據的變更增加版本字段值。
范例6
我們的應用程序有多個在大多數情況下只和數據庫“A”打交道的服務層方法;它們偶爾也會從數據庫“B”中獲取只讀數據。因為數據庫“B”只提供只讀數據,我們對這些方法在這兩個數據庫上仍然使用本地事務。
服務層上有一個方法設計在兩個數據庫上執行數據變更。以下是偽代碼:
//Make sure a local transaction on database A exists
@Transactional (readOnly=false, propagation=Propagation.REQUIRED)
public void saveIsoBids() {
//it participates in the above annotated local transaction
insertBidsInDatabaseA();
//it runs in its own local transaction on database B
insertBidRequestsInDatabaseB(); //must be the last operation
因為insertBidRequestsInDatabaseB()是saveIsoBids ()中的最後一個方法,所以只有下面的場景會造成數據不一致:
在saveIsoBids()執行返回時,數據庫“A”的本地事務提交失敗。
但是,就算saveIsoBids()使用JTA,在兩階段提交(2PC)的第二個提交階段失敗的時候,你還是會碰到數據不一致。因此如果你能處理好上述的數據不一致性,而且不想為了一個或少數幾個方法引入JTA的復雜性,你應該使用本地事務。
(未完待續)
關於作者
Yongjun Jiao是SunGard Consulting Services的技術主管。過去10年中他一直是專業軟件開發者,他的專長包括Java SE、Java EE、Oracle和應用程序調優。他最近的關注點是高性能計算,包括內存數據網格、並行計算和網格計算。
Stewart Clark是SunGard Consulting Services的負責人。過去15年中他一直是專業軟件開發者和項目經理,他的專長包括Java核心編程、Oracle和能源交易。
查看英文原文:http://www.infoq.com/articles/hibernate_tuning