這個月,我著手撰寫一篇文章,分析一個寫得很糟糕的微評測。畢竟,我們 的程序員一直受性能困擾,我們也都想了解我們編寫、使用或批評的代碼的性能 特征。當我偶然間寫到性能這個主題時,我經常得到這樣的電子郵件:“我寫的 這個程序顯示,動態 frosternation 要比靜態 blestification 快,與您上一 篇的觀點相反!”許多隨這類電子郵件而來的所謂“評測“程序,或者它們運行 的方式,明顯表現出他們對於 JVM 執行字節碼的實際方式缺乏基本認識。所以 ,在我著手撰寫這樣一篇文章(將在未來的專欄中發表)之前,我們先來看看 JVM 幕後的東西。理解動態編譯和優化,是理解如何區分微評測好壞的關鍵(不 幸的是,好的微評測很少)。
動態編譯簡史
Java 應用程序的編譯過程與靜態編譯語言(例如 C 或 C++)不同。靜態編 譯器直接把源代碼轉換成可以直接在目標平台上執行的機器代碼,不同的硬件平 台要求不同的編譯器。Java 編譯器把 Java 源代碼轉換成可移植的 JVM 字節 碼,所謂字節碼指的是 JVM 的“虛擬機器指令”。與靜態編譯器不同,javac 幾乎不做什麼優化 —— 在靜態編譯語言中應當由編譯器進行的優化工作,在 Java 中是在程序執行的時候,由運行時執行。
第一代 JVM 完全是解釋的。JVM 解釋字節碼,而不是把字節碼編譯成機器碼 並直接執行機器碼。當然,這種技術不會提供最好的性能,因為系統在執行解釋 器上花費的時間,比在需要運行的程序上花費的時間還要多。
即時編譯
對於證實概念的實現來說,解釋是合適的,但是早期的 JVM 由於太慢,迅速 獲得了一個壞名聲。下一代 JVM 使用即時 (JIT) 編譯器來提高執行速度。按照 嚴格的定義,基於 JIT 的虛擬機在執行之前,把所有字節碼轉換成機器碼,但 是以惰性方式來做這項工作:JIT 只有在確定某個代碼路徑將要執行的時候,才 編譯這個代碼路徑(因此有了名稱“ 即時 編譯”)。這個技術使程序能啟動得 更快,因為在開始執行之前,不需要冗長的編譯階段。
JIT 技術看起來很有前途,但是它有一些不足。JIT 消除了解釋的負擔(以 額外的啟動成本為代價),但是由於若干原因,代碼的優化等級仍然是一般般。為了避免 Java 應用程序嚴重的啟動延遲,JIT 編譯器必須非常迅速,這意味著 它無法把大量時間花在優化上。所以,早期的 JIT 編譯器在進行內聯假設 (inlining assumption)方面比較保守,因為它們不知道後面可能要裝入哪個類 。
雖然從技術上講,基於 JIT 的虛擬機在執行字節碼之前,要先編譯字節碼, 但是 JIT 這個術語通常被用來表示任何把字節碼轉換成機器碼的動態編譯過程 —— 即使那些能夠解釋字節碼的過程也算。
HotSpot 動態編譯
HotSpot 執行過程組合了編譯、性能分析以及動態編譯。它沒有把所有要執 行的字節碼轉換成機器碼,而是先以解釋器的方式運行,只編譯“熱門”代碼 —— 執行得最頻繁的代碼。當 HotSpot 執行時,會搜集性能分析數據,用來決 定哪個代碼段執行得足夠頻繁,值得編譯。只編譯執行最頻繁的代碼有幾項性能 優勢:沒有把時間浪費在編譯那些不經常執行的代碼上;這樣,編譯器就可以花 更多時間來優化熱門代碼路徑,因為它知道在這上面花的時間物有所值。而且, 通過延遲編譯,編譯器可以訪問性能分析數據,並用這些數據來改進優化決策, 例如是否需要內聯某個方法調用。
為了讓事情變得更復雜,HotSpot 提供了兩個編譯器:客戶機編譯器和服務 器編譯器。默認采用客戶機編譯器;在啟動 JVM 時,您可以指定 -server 開關 ,選擇服務器編譯器。服務器編譯器針對最大峰值操作速度進行了優化,適用於 需要長期運行的服務器應用程序。客戶機編譯器的優化目標,是減少應用程序的 啟動時間和內存消耗,優化的復雜程度遠遠低於服務器編譯器,因此需要的編譯 時間也更少。
HotSpot 服務器編譯器能夠執行各種樣的類。它能夠執行許多靜態編譯器中 常見的標准優化,例如代碼提升( hoisting)、公共的子表達式清除、循環展開 (unrolling)、范圍檢測清除、死代碼清除、數據流分析,還有各種在靜態編譯 語言中不實用的優化技術,例如虛方法調用的聚合內聯。
持續重新編譯
HotSpot 技術另一個有趣的方面是:編譯不是一個全有或者全無(all-or- nothing)的命題。在解釋代碼路徑一定次數之後,會把它重新編譯成機器碼。但 是 JVM 會繼續進行性能分析,而且如果認為代碼路徑特別熱門,或者未來的性 能分析數據認為存在額外的優化可能,那麼還有可能用更高一級的優化重新編譯 代碼。JVM 在一個應用程序的執行過程中,可能會把相同的字節碼重新編譯許多 次。為了深入了解編譯器做了什麼,請用 -XX:+PrintCompilation 標志調用 JVM,這個標志會使編譯器(客戶機或服務器)每次運行的時候打印一條短消息 。
棧上(On-stack)替換
HotSpot 開始的版本編譯的時候每次編譯一個方法。如果某個方法的累計執 行次數超過指定的循環迭代次數(在 HotSpot 的第一版中,是 10,000 次), 那麼這個方法就被當作熱門方法,計算的方式是:為每個方法關聯一個計數器, 每次執行一個後向分支時,就會遞增計數器一次。但是,在方法編譯之後,方法 調用並沒有切換到編譯的版本,需要退出並重新進入方法,後續調用才會使用編 譯的版本。結果就是,在某些情況下,可能永遠不會用到編譯的版本,例如對於 計算密集型程序,在這類程序中所有的計算都是在方法的一次調用中完成的。重 量級方法可能被編譯,但是編譯的代碼永遠用不到。
HotSpot 最近的版本采用了稱為 棧上(on-stack)替換 (OSR) 的技術,支持 在循環過程中間,從解釋執行切換到編譯的代碼(或者從編譯代碼的一個版本切 換到另一個版本)。
那麼,這與評測有什麼關系?
我向您許諾了一篇關於評測和性能測量的文章,但是迄今為止,您得到的只 是歷史的教訓和 Sun 的 HotSpot 白皮書的老調重談。繞這麼大的圈子的原因是 ,如果不理解動態編譯的過程,就不可能正確地編寫或解釋 Java 類的性能測試 。(即使深入理解動態編譯和 JVM 優化,也仍然是非常困難的。)
為 Java 代碼編寫微評測遠比為 C 代碼編寫難得多
判斷方法 A 是否比方法 B 更快的傳統方法,是編寫小的評測程序,通常叫 做 微評測。這個趨勢非常有意義。科學的方法不能缺少獨立的調查。魔鬼總在 細節之中。為動態編譯的語言編寫並解釋評測,遠比為靜態編譯的語言難得多。為了了解某個結構的性能,編寫一個使用該結構的程序一點也沒有錯,但是在許 多情況下,用 Java 編寫的微評測告訴您的,往往與您所認為的不一樣。
使用 C 程序時,您甚至不用運行它,就能了解許多程序可能的性能特征。只 要看看編譯出的機器碼就可以了。編譯器生成的指令就是將要執行的機器碼,一 般情況下,可以很合理地理解它們的時間特征。(有許多有毛病的例子,因為總 是遺漏分支預測或緩存,所以性能差的程度遠遠超過查看機器碼所能夠想像的程 度,但是大多數情況下,您都可以通過查看機器碼了解 C 程序的性能的很多方 面。)
如果編譯器認為某段代碼不恰當,准備把它優化掉(通常的情況是,評測到 它實際上不做任何事情),那麼您在生成的機器碼中可以看到這個優化 —— 代 碼不在那兒了。通常,對於 C 代碼,您不必執行很長時間,就可以對它的性能 做出合理的推斷。
而在另一方面,HotSpot JIT 在程序運行時會持續地把 Java 字節碼重新編 譯成機器碼,而重新編譯觸發的次數無法預期,觸發重新編譯的依據是性能分析 數據積累到一定數量、裝入新類,或者執行到的代碼路徑的類已經裝入,但是還 沒有執行過。持續的重新編譯情況下的時間測量會非常混亂、讓人誤解,而且要 想獲得有用的性能數據,通常必須讓 Java 代碼運行相當長的時間(我曾經看到 過一些怪事,在程序啟動運行之後要加速幾個小時甚至數天),才能獲得有用的 性能數據。
清除死代碼
編寫好評測的一個挑戰就是,優化編譯器要擅長找出死代碼 —— 對於程序 執行的輸出沒有作用的代碼。但是評測程序一般不產生任何輸出,這就意味著有 一些,或者全部代碼都有可能被優化掉,而毫無知覺,這時您實際測量的執行要 少於您設想的數量。具體來說,許多微評測在用 -server 方式運行時,要比用 -client 方式運行時好得多,這不是因為服務器編譯器更快(雖然服務器編譯器 一般更快),而是因為服務器編譯器更擅長優化掉死代碼。不幸的是,能夠讓您 的評測工作非常短(可能會把評測完全優化掉)的死代碼優化,在處理實際做些 工作的代碼時,做得就不會那麼好了。
奇怪的結果
清單 1 的評測包含一個什麼也不做的代碼塊,它是從一個測試並發線程性能 的評測中摘出來的,但是它實際測量的根本不是要評測的東西。
清單 1. 被意料之外的死代碼弄亂的評測
public class StupidThreadTest {
public static void doSomeStuff() {
double uselessSum = 0;
for (int i=0; i<1000; i++) {
for (int j=0;j<1000; j++) {
uselessSum += (double) i + (double) j;
}
}
}
public static void main(String[] args) throws InterruptedException {
doSomeStuff();
int nThreads = Integer.parseInt(args[0]);
Thread[] threads = new Thread[nThreads];
for (int i=0; i<nThreads; i++)
threads[i] = new Thread(new Runnable() {
public void run() { doSomeStuff(); }
});
long start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++)
threads[i].start();
for (int i = 0; i < threads.length; i++)
threads[i].join();
long end = System.currentTimeMillis();
System.out.println("Time: " + (end-start) + "ms");
}
}
表面上看, doSomeStuff() 方法可以給線程分點事做,所以我們能夠從 StupidThreadBenchmark 的運行時間推導出多線程調度開支的一些情況。但是, 因為 uselessSum 從沒被用過,所以編譯器能夠判斷出 doSomeStuff 中的全部 代碼是死的,然後把它們全部優化掉。一旦循環中的代碼消失,循環也就消失了 ,只留下一個空空如也的 doSomeStuff。表 1 顯示了使用客戶機和服務器方式 執行 StupidThreadBenchmark 的性能。兩個 JVM 運行大量線程的時候,都表現 出差不多是線性的運行時間,這個結果很容易被誤解為服務器 JVM 比客戶機 JVM 快 40 倍。而實際上,是服務器編譯器做了更多優化,發現整個 doSomeStuff 是死代碼。雖然確實有許多程序在服務器 JVM 上會提速,但是您 在這裡看到的提速僅僅代表一個寫得糟糕的評測,而不能成為服務器 JVM 性能 的證明。但是如果您沒有細看,就很容易會把兩者混淆。
表 1. 在客戶機和服務器 JVM 中 StupidThreadBenchmark 的性能
線程數量 客戶機 JVM 運行時間 服務器 JVM 運行時間 10 43 2 100 435 10 1000 4142 80 10000 42402 1060對於評測靜態編譯語言來說,處理過於積極的死代碼清除也是一個問題。但 是,在靜態編譯語言中,能夠更容易地發現編譯器清除了大塊評測。您可以查看 生成的機器碼,查看是否漏了某塊程序。而對於動態編譯語言,這些信息不太容 易訪問得到。
預熱
如果您想測量 X 的性能,一般情況下您是想測量它編譯後的性能,而不是它 的解釋性能(您想知道 X 在賽場上能跑多快)。要做到這樣,需要“預熱” JVM —— 即讓目標操作執行足夠的時間,這樣編譯器在為執行計時之前,就有 足夠的運行解釋的代碼,並用編譯的代碼替換解釋代碼。
使用早期 JIT 和沒有棧上替換的動態編譯器,有一個容易的公式可以測量方 法編譯後的性能:運行多次調用,啟動計時器,然後執行若干次方法。如果預熱 調用超過方法被編譯的阈值,那麼實際計時的調用就有可能全部是編譯代碼執行 的時間,所有的編譯開支應當在開始計時之前發生。
而使用今天的動態編譯器,事情更困難。編譯器運行的次數很難預測,JVM 按照自己的想法從解釋代碼切換到編譯代碼,而且在運行期間,相同的代碼路徑 可能編譯、重新編譯不止一次。如果您不處理這些事件的計時問題,那麼它們會 嚴重歪曲您的計時結果。
圖 1 顯示了由於預計不到的動態編譯而造成的可能的計時歪曲。假設您正在 通過循環計時 200,000 次迭代,編譯代碼比解釋代碼快 10 倍。如果編譯只在 200,000 次迭代時才發生,那麼您測量的只是解釋代碼的性能(時間線(a))。如果編譯在 100,000 次迭代時發生,那麼您總共的運行時間是運行 200,000 次 解釋迭代的時間,加上編譯時間(編譯時間非您所願),加上執行 100,000 次 編譯迭代的時間(時間線(b))。如果編譯在 20,000 次迭代時發生,那麼總時 間會是 20,000 次解釋迭代,加上編譯時間,再加上 180,000 次編譯迭代(時 間線(c))。因為您不知道編譯器什麼時候執行,也不知道要執行多長時間,所 以您可以看到,您的測量可能受到嚴重的歪曲。根據編譯時間和編譯代碼比解釋 代碼快的程度,即使對迭代數量只做很小的變化,也可能造成測量的“性能”有 極大差異。
圖 1. 因為動態編譯計時造成的性能測量歪曲
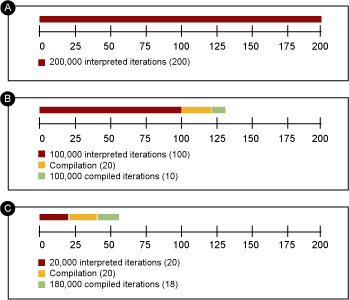
那麼,到底多少預熱才足夠呢?您不知道。您能做到的最好的,就是用 - XX:+PrintCompilation 開關來運行評測,觀察什麼造成編譯器工作,然後改變 評測程序的結構,以確保編譯在您啟動計時之前發生,在計時循環過程中不會再 發生編譯。
不要忘記垃圾收集
那麼,您已經看到,如果您想得到正確的計時結果,就必須要讓被測代碼比 您想像的多運行幾次,以便讓 JVM 預熱。另一方面,如果測試代碼要進行對象 分配工作(差不多所有的代碼都要這樣),那麼垃圾收集器也肯定會運行。這是 會嚴重歪曲計時結果的另一個因素 —— 即使對迭代數量只做很小的變化,也意 味著沒有垃圾收集和有垃圾收集之間的區別,就會偏離“每迭代時間”的測量。
如果用 -verbose:gc 開關運行評測,您可以看到在垃圾收集上耗費了多少時 間,並相應地調整您的計時數據。更好一些的話,您可以長時間運行您的程序, 這可以保證觸發許多垃圾收集,從而更精確地分攤垃圾收集的成本。
動態反優化(deoptimization)
許多標准的優化只能在“基本塊”內執行,所以內聯方法調用對於達到好的 優化通常很重要。通過內聯方法調用,不僅方法調用的開支被清除,而且給優化 器提供了更大的優化塊可以優化,會帶來相當大的死代碼優化機會。
清單 2 顯示了一個通過內聯實現的這類優化的示例。outer() 方法用參數 null 調用 inner(),結果是 inner() 什麼也不做。但是通過把 inner() 的調 用內聯,編譯器可以發現 inner() 的 else 分支是死的,因此能夠把測試和 else 分支優化掉,在某種程度上,它甚至能把整個對 inner() 的調用全優化掉 。如果 inner() 沒有被內聯,那麼這個優化是不可能發生的。
清單 2. 內聯如何帶來更好的死代碼優化
public class Inline {
public final void inner(String s) {
if (s == null)
return;
else {
// do something really complicated
}
}
public void outer() {
String s=null;
inner(s);
}
}
但是不方便的是,虛方法對內聯造成了障礙,而虛函數調用在 Java 中要比 在 C++ 中普遍。假設編譯器正試圖優化以下代碼中對 doSomething() 的調用:
Foo foo = getFoo();
foo.doSomething();
從這個代碼片斷中,編譯器沒有必要分清要執行哪個版本的 doSomething() —— 是在類 Foo 中實現的版本,還是在 Foo 的子類中實現的版本?只在少數 情況下答案才明顯 —— 例如 Foo 是 final 的,或者 doSomething() 在 Foo 中被定義為 final 方法 —— 但是在多數情況下,編譯器不得不猜測。對於每 次只編譯一個類的靜態編譯器,我們很幸運。但是動態編譯器可以使用全局信息 進行更好的決策。假設有一個還沒有裝入的類,它擴展了應用程序中的 Foo。現 在的情景更像是 doSomething() 是 Foo 中的 final 方法 —— 編譯器可以把 虛方法調用轉換成一個直接分配(已經是個改進了),而且,還可以內聯 doSomething()。(把虛方法調用轉換成直接方法調用,叫做 單形 (monomorphic)調用變換。)
請稍等 —— 類可以動態裝入。如果編譯器進行了這樣的優化,然後裝入了 一個擴展了 Foo 的類,會發生什麼?更糟的是,如果這是在工廠方法 getFoo() 內進行的會怎麼樣? getFoo() 會返回新的 Foo 子類的實例?那麼,生成的代 碼不就無效了麼?對,是無效了。但是 JVM 能指出這個錯誤,並根據目前無效 的假設,取消生成的代碼,並恢復解釋(或者重新編譯不正確的代碼路徑)。
結果就是,編譯器要進行主動的內聯決策,才能得到更高的性能,然後當這 些決策依據的假設不再有效時,就會收回這些決策。實際上,這個優化如此有效 ,以致於給那些不被覆蓋的方法添加 final 關鍵字(一種性能技巧,在以前的 文章中建議過)對於提高實際性能沒有太大作用。
奇怪的結果
清單 3 中包含一個代碼模式,其中組合了不恰當的預熱、單形調用變換以及 反優化,因此生成的結果毫無意義,而且容易被誤解:
清單 3. 測試程序的結果被單形調用變換和後續的反優化歪曲
public class StupidMathTest {
public interface Operator {
public double operate(double d);
}
public static class SimpleAdder implements Operator {
public double operate(double d) {
return d + 1.0;
}
}
public static class DoubleAdder implements Operator {
public double operate(double d) {
return d + 0.5 + 0.5;
}
}
public static class RoundaboutAdder implements Operator {
public double operate(double d) {
return d + 2.0 - 1.0;
}
}
public static void runABunch(Operator op) {
long start = System.currentTimeMillis();
double d = 0.0;
for (int i = 0; i < 5000000; i++)
d = op.operate(d);
long end = System.currentTimeMillis();
System.out.println("Time: " + (end-start) + " ignore:" + d);
}
public static void main(String[] args) {
Operator ra = new RoundaboutAdder();
runABunch(ra); // misguided warmup attempt
runABunch(ra);
Operator sa = new SimpleAdder();
Operator da = new DoubleAdder();
runABunch(sa);
runABunch(da);
}
}
StupidMathTest 首先試圖做些預熱(沒有成功),然後測量 SimpleAdder、 DoubleAdder、 RoundaboutAdder 的運行時間,結果如表 2 所示。看起來好像 先加 1,再加 2 ,然後再減 1 最快。加兩次 0.5 比加 1 還快。這有可能麼? (答案是:不可能。)
表 2. StupidMathTest 毫無意義且令人誤解的結果
方法 運行時間 SimpleAdder 88ms DoubleAdder 76ms RoundaboutAdder 14ms這裡發生什麼呢?在預熱循環之後, RoundaboutAdder和runABunch() 確實 已經被編譯了,而且編譯器 Operator和RoundaboutAdder 上進行了單形調用轉 換,第一輪運行得非常快。而在第二輪( SimpleAdder)中,編譯器不得不反優化 ,又退回虛函數分配之中,所以第二輪的執行表現得更慢,因為不能把虛函數調 用優化掉,把時間花在了重新編譯上。在第三輪( DoubleAdder)中,重新編譯比 第二輪少,所以運行得就更快。(在現實中,編譯器會在 RoundaboutAdder和 DoubleAdder 上進行常數替換(constant folding),生成與 SimpleAdder 幾乎 相同的代碼。所以如果在運行時間上有差異,那麼不是因為算術代碼)。哪個代 碼首先執行,哪個代碼就會最快。
那麼,從這個“評測”中,我們能得出什麼結論呢?實際上,除了評測動態 編譯語言要比您可能想到的要微妙得多之外,什麼也沒得到。
結束語
這個示例中的結果錯得如此明顯,所以很清楚,肯定發生了什麼,但是更小 的結果能夠很容易地歪曲您的性能測試程序的結果,卻不會觸發您的“這裡肯定 有什麼東西有問題”的警惕。雖然本文列出的這些內容是微評測歪曲的一般來源 ,但是還有許多其他來源。本文的中心思想是:您正在測量的,通常不是您以為 您正在測量的。實際上,您通常所測量的,不是您以為您正在測量的。對於那些 沒有包含什麼實際的程序負荷,測試時間不夠長的性能測試的結果,一定要非常 當心。