使用了O/R Mapping工具的典型J2EE應用都會面臨這樣一個問題:如何通過最精簡的SQL查詢獲取所需的數據。很多時候這可不是輕而易舉的事情。默認情況下,O/R Mapping工具會按需加載數據,除非你改變了其默認設置。延遲加載行為保證了依賴的數據只有在真正請求時才會被加載進來,這樣就可以避免創建無謂的對象。有時我們的業務並不會使用到依賴的那些組件,這時延遲加載就派上用場了,同時也無需加載那些用不上的組件了。
典型情況下,我們的業務很清楚需要哪些數據。但由於使用了延遲加載,在執行大量Select查詢時數據庫的性能會降低,因為業務所需的數據並不是一下子獲得的。這樣,對於那些需要支持大量請求的應用來說可能會產生瓶頸(可伸縮性問題)。
來看個例子吧,假設某個業務流程想要得到一個Person及其Address信息。我們將Address組件配置成延遲加載,這樣要想得到所需的數據就需要更多的SQL查詢,也就是說首先查詢Person,然後再查詢Address。這增加了數據庫與應用之間的通信成本。解決辦法就是在一個單獨的查詢中將 Person和Address都得到,因為我們知道這兩個組件都是業務流程所需的。
如果在DAO/Repository及底層Service開發特定於業務的Fetching-API,對於那些擁有不同數據集的相同領域對象來說,我們就得編寫不同的API進行抓取並組裝了。這麼做會使Repository及底層Service過於膨脹,最終變成維護的夢魇。
延遲抓取的另一個問題就是在獲取到請求的數據前要一直打開數據庫連接,否則應用就會拋出一個延遲加載異常。
說明:如果在查詢中使用預先抓取來獲取二級緩存中的數據時,我們將無法解決上面提出的問題。對於Hibernate來說,如果我們使用預先抓取來獲取二級緩存中的數據,那麼它將從數據庫而不是緩存中去獲取數據,哪怕是二級緩存中已經存在該數據。這就說明Hibernate也沒有解決這個問題,從而表明我們不應該在查詢中通過預先抓取來獲得二級緩存中的對象。
對於那些可以讓我們調節查詢以獲取緩存對象的O/R Mapping工具來說,如果緩存中有對象就會從緩存中獲取,否則采取預先抓取的方式。這就解決了上面提到的事務/DB連接問題,因為在查詢的執行過程中會同時獲取緩存中的數據而不是按需讀取(也就是延遲加載)。
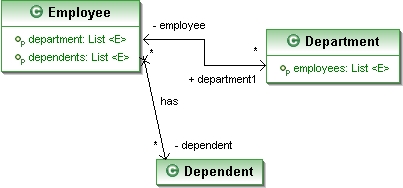
通過下面的示例代碼來了解一下延遲加載所面對的問題及解決辦法。考慮如下場景:某領域中有3個實體,分別是Employee、Department及Dependent。
這三個實體之間的關系如下:
Employee有0或多個dependents。
Department有0或多個employees。
Employee屬於0或1個department。
我們要執行三個操作:
獲取employee的詳細信息。
獲取employee及其dependent的詳細信息。
獲取employee及其department的詳細信息。
以上三個操作需要獲取並呈現不同的數據。使用延遲加載有如下弊端:
如果對實體employee所關聯的dependent和department這兩個實體使用延遲加載,那麼在操作2和3中就會生成更多的SQL查詢語句。
在多個查詢語句的執行過程中需要保持數據庫連接,否則會拋出一個延遲加載異常,這將導致數據出現問題。
但另一方面,使用預先抓取也存在如下弊端:
對employee所對應的dependents和department采取預先抓取會產生不必要的數據。
無法在特定的場景下對查詢進行調優。
在Repository/DAO或底層服務中使用特定於操作的API可以解決上述問題,但卻會導致如下問題:
代碼膨脹——不管是Service還是Repository/DAO類都無法幸免。
維護的夢魇——不管是Service還是Repository/DAO層,只要有新的操作都需要增加新的API。
代碼重復——有時底層服務需要在獲取的實體上增加某些業務邏輯,與之類似,還要在數據返回前檢查DAO/Repository層的查詢響應以驗證數據可用性。
為了解決上面這些問題,Repository/DAO層需要根據不同的業務情況執行不同的查詢來獲取實體。就像Aspect類所定義的那樣,我們可以根據特定的操作使用不同的抓取機制來覆蓋Repository/DAO類所定義的默認抓取模式。所有的抓取模式類都實現了相同的接口。
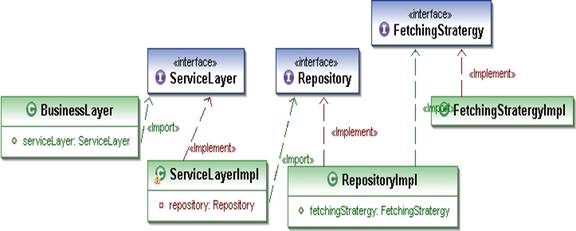
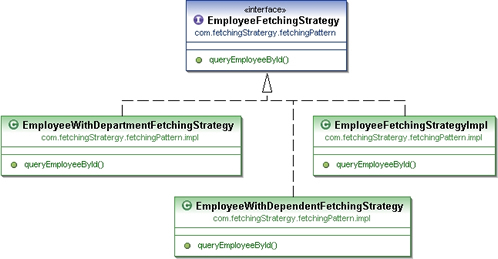
Repository類使用了上述的抓取模式來執行查詢,如下代碼所示:
public Employee findEmployeeById(int employeeId) {
List employee = hibernateTemplate.find(fetchingStrategy.queryEmployeeById(),
new Integer(employeeId));
if(employee.size() == 0)
return null;
return (Employee)employee.get(0);
}
Repository類中的employee的抓取策略需要根據實際情況進行調整。我們決定將Repository層的抓取策略調整到 Repository和Service層外,放在一個Aspect類中,這樣當需要增加新的業務邏輯時只需修改Aspect類並增加一個針對於 Repository的抓取策略實現即可。這裡我們使用了面向方面的編程(Aspect Oriented Programming)以根據業務的不同使用不同的抓取策略。
什麼是面向方面的編程?
面向方面的編程(AOP)可以通過模塊化的形式實現實際應用中的橫切關注點,如日志、追蹤、動態分析、錯誤處理、服務水平協議、策略增強、池化、緩存、並發控制、安全、事務管理以及業務規則等等。對這些關注點的傳統實現方式需要我們將這些實現融合到模塊的核心關注點中。憑借AOP,我們可以在一個叫做方面(aspect)的獨立模塊中實現這些關注點。模塊化的結果就是設計簡化、易於理解、質量提升、開發時間降低以及對系統需求變更的快速響應。
接下來讀者朋友們可以參考 Ramnivas Laddad所著的《AspectJ in Action》一書以詳細了解AspectJ的概念以及編程方式,還可以了解一下AspectJ的開發工具。
Aspect在抓取策略實現上扮演著重要角色。抓取策略是個業務層的橫切關注點,它會隨著業務的變化而變化。Aspect對於特定的業務邏輯下使用何種抓取策略起到了至關重要的作用。這裡我們將對抓取策略的管理放在了底層服務和Respository層之外。任何新的業務都可能需要不同的抓取策略,這樣我們就無需修改底層服務或是Respository層的API就能應用新的抓取策略了。
FetchingStrategyAspect.aj
/**
Identify the getEmployeeWithDepartmentDetails flow where you need to change the fetching
strategy at repository level
*/
pointcut empWithDepartmentDetail(): call(* EmployeeRepository.findEmployeeById(int))
&& cflow(execution(* EmployeeDetailsService.getEmployeeWithDepartmentDetails(int)));
/**
When you are at the specified poincut before continuing further update the fetchingStrategy in
EmployeeRepositoryImpl to EmployeeWithDepartmentFetchingStrategy
*/
before(EmployeeRepositoryImpl r): empWithDepartmentDetail() && target(r) {
r.fetchingStrategy = new EmployeeWithDepartmentFetchingStrategy();
}
/**
Identify the getEmployeeWithDependentDetails flow where you need to change the fetching
staratergy at repository level
*/
pointcut empWithDependentDetail(): call(* EmployeeRepository.findEmployeeById(int))
&& cflow(execution(* EmployeeDetailsService.getEmployeeWithDependentDetails(int)));
/**
When you are at the specified poincut before continuing further update the fetchingStrategy in
EmployeeRepositoryImpl to EmployeeWithDependentFetchingStrategy
*/
before(EmployeeRepositoryImpl r): empWithDependentDetail() && target(r) {
r.fetchingStrategy = new EmployeeWithDependentFetchingStrategy();
}
這樣,Repository到底要執行何種查詢就不是由Service和Repository層所決定了,而是由外面的Aspect決定,縱使增加了新的業務也無需修改底層服務和Repository層。決定執行何種查詢的邏輯就成為一個橫切關注點了,它被放在Aspect中。Aspect會根據業務規則的不同在Service層調用Repository層的API之前將抓取策略注入到Repository中。這樣我們就可以使用相同的Service和 Repository層API來滿足各種不同的業務規則了。
來看個具體示例吧,該示例會同時抓取一個employee的Department和Dependent的詳細信息。我們需要對業務層進行一些變更,增加一個方法:getEmployeeWithDepartmentAndDependentsDetails(int employeeId)。實現新的抓取策略類EmployeeWithDepartmentAndDependentFetchingStaratergy,後者又實現了EmployeeFetchingStrategy並重寫了queryEmployeeById方法,該方法會返回優化後的查詢,可以在一個SQL語句中獲取所需數據。
由Aspect將上述的抓取策略注入到相關的業務中,如下所示:
pointcut empWithDependentAndDepartmentDetail(): call(* EmployeeRepository.findEmployeeById(int))
&& cflow(execution(* EmployeeDetailsService.getEmployeeWithDepartmentAndDependentsDetails(int)));
before(EmployeeRepositoryImpl r): empWithDependentAndDepartmentDetail() && target(r) {
r.fetchingStrategy = new EmployeeWithDepartmentAndDependentFetchingStaratergy();
}
如你所見,我們並沒有修改底層業務與Repository層而是使用Aspect和一個新的FetchingStrategy實現就完成了上述新增的業務。
現在我們來談談關於二級緩存的查詢優化問題。在上面的示例代碼中,我們對department實體進行一些修改並配置在二級緩存中。如果對 department實體采取預先抓取,那麼對於同樣的department實例,縱使它位於二級緩存中,每次也都需要查詢數據庫。如果不在查詢中獲取 department實體,那麼業務層就需要參與到事務當中,因為我們並沒有將department實體緩存起來而是通過延遲加載的方式得到它。
這樣,事務聲明就從底層移到了業務層,雖然我們知道該業務需要哪些數據,但O/R Mapping工具卻沒有提供相應的機制來解決上面遇到的問題,即預先抓取緩存中的數據。
對於那些沒有緩存的數據來說這種方式沒什麼問題,但對於緩存數據來說,這就依賴於O/R Mapping工具了,因為只有它才能解決緩存數據問題。
該示例附帶的源代碼詳細解釋了抓取策略。該zip文件含有一個工程示例,闡述了上面談到的所有場景。你可以使用任何IDE或是使用aspectj編譯器從命令行執行代碼。在執行前請確保jdbc.properties文件與你機器上的信息一致並創建示例應用所需的表。
你可以使用Eclipse IDE以及AJDT插件運行代碼,請按照下面的步驟進行:
解壓縮下載好的代碼並將工程導入到Eclipse中。
配置Resources/dbscript目錄下的jdbc.properties文件中的數據庫信息。
完成上面的步驟後請執行resources\dbscript\tables.sql腳本,這將創建該示例應用所需的表。
以AspectJ/Java應用的方式運行Main.java文件來創建默認數據並測試上面的抓取策略實現。
結論
本文介紹了如何通過不同的抓取策略從後端系統中獲取數據,這是以模塊化的方式根據業務需求實現的,同時又不會導致底層服務或Repository層過度膨脹。
關於作者:Manjunath R Naganna目前供職於阿爾卡特朗訊公司,擔任高級軟件工程師一職,尤其專注基於Java/J2EE的企業應用設計與實現。他感興趣的領域包括 Spring Framework、領域驅動設計、事件驅動架構以及面向方面的編程。對於Hemraj Rao Surlu對本文所做的編輯與排版工作,Manjunath表達了自己的謝意,同時他也很感謝自己的領導Ramana與Saurabh Sharma在百忙之中抽出時間對本文進行審閱並提出很多重要的反饋信息。