轉:深入理解Java G1垃圾收集器。本站提示廣大學習愛好者:(轉:深入理解Java G1垃圾收集器)文章只能為提供參考,不一定能成為您想要的結果。以下是轉:深入理解Java G1垃圾收集器正文
本文首先簡單介紹了垃圾收集的常見方式,然後再分析了G1收集器的收集原理,相比其他垃圾收集器的優勢,最後給出了一些調優實踐。
一,什麼是垃圾回收首先,在了解G1之前,我們需要清楚的知道,垃圾回收是什麼?簡單的說垃圾回收就是回收內存中不再使用的對象。
垃圾回收的基本步驟
回收的步驟有2步:
1,查找內存中不再使用的對象
那麼問題來了,如何判斷哪些對象不再被使用呢?我們也有2個方法:
引用計數法就是如果一個對象沒有被任何引用指向,則可視之為垃圾。這種方法的缺點就是不能檢測到環的存在。
2.根搜索算法
根搜索算法的基本思路就是通過一系列名為”GC Roots”的對象作為起始點,從這些節點開始向下搜索,搜索所走過的路徑稱為引用鏈(Reference Chain),當一個對象到GC Roots沒有任何引用鏈相連時,則證明此對象是不可用的。
現在我們已經知道如何找出垃圾對象了,如何把這些對象清理掉呢?
2. 釋放這些對象占用的內存
常見的方式有復制或者直接清理,但是直接清理會存在內存碎片,於是就會產生了清理再壓縮的方式。
總得來說就產生了三種類型的回收算法。
1.標記-復制
它將可用內存容量劃分為大小相等的兩塊,每次只使用其中的一塊。當這一塊用完之後,就將還存活的對象復制到另外一塊上面,然後在把已使用過的內存空間一次理掉。它的優點是實現簡單,效率高,不會存在內存碎片。缺點就是需要2倍的內存來管理。
2.標記-清理
標記清除算法分為“標記”和“清除”兩個階段:首先標記出需要回收的對象,標記完成之後統一清除對象。它的優點是效率高,缺點是容易產生內存碎片。
3.標記-整理
標記操作和“標記-清理”算法一致,後續操作不只是直接清理對象,而是在清理無用對象完成後讓所有 存活的對象都向一端移動,並更新引用其對象的指針。因為要移動對象,所以它的效率要比“標記-清理”效率低,但是不會產生內存碎片。
基於分代的假設
由於對象的存活時間有長有短,所以對於存活時間長的對象,減少被gc的次數可以避免不必要的開銷。這樣我們就把內存分成新生代和老年代,新生代存放剛創建的和存活時間比較短的對象,老年代存放存活時間比較長的對象。這樣每次僅僅清理年輕代,老年代僅在必要時時再做清理可以極大的提高GC效率,節省GC時間。
java垃圾收集器的歷史
第一階段,Serial(串行)收集器
在jdk1.3.1之前,java虛擬機僅僅能使用Serial收集器。 Serial收集器是一個單線程的收集器,但它的“單線程”的意義並不僅僅是說明它只會使用一個CPU或一條收集線程去完成垃圾收集工作,更重要的是在它進行垃圾收集時,必須暫停其他所有的工作線程,直到它收集結束。
PS:開啟Serial收集器的方式
-XX:+UseSerialGC
第二階段,Parallel(並行)收集器
Parallel收集器也稱吞吐量收集器,相比Serial收集器,Parallel最主要的優勢在於使用多線程去完成垃圾清理工作,這樣可以充分利用多核的特性,大幅降低gc時間。
PS:開啟Parallel收集器的方式
-XX:+UseParallelGC -XX:+UseParallelOldGC
第三階段,CMS(並發)收集器
CMS收集器在Minor GC時會暫停所有的應用線程,並以多線程的方式進行垃圾回收。在Full GC時不再暫停應用線程,而是使用若干個後台線程定期的對老年代空間進行掃描,及時回收其中不再使用的對象。
PS:開啟CMS收集器的方式
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
第四階段,G1(並發)收集器
G1收集器(或者垃圾優先收集器)的設計初衷是為了盡量縮短處理超大堆(大於4GB)時產生的停頓。相對於CMS的優勢而言是內存碎片的產生率大大降低。
PS:開啟G1收集器的方式
-XX:+UseG1GC
二,了解G1G1的第一篇paper(附錄1)發表於2004年,在2012年才在jdk1.7u4中可用。oracle官方計劃在jdk9中將G1變成默認的垃圾收集器,以替代CMS。為何oracle要極力推薦G1呢,G1有哪些優點?
首先,G1的設計原則就是簡單可行的性能調優
開發人員僅僅需要聲明以下參數即可:
-XX:+UseG1GC -Xmx32g -XX:MaxGCPauseMillis=200
其中-XX:+UseG1GC為開啟G1垃圾收集器,-Xmx32g 設計堆內存的最大內存為32G,-XX:MaxGCPauseMillis=200設置GC的最大暫停時間為200ms。如果我們需要調優,在內存大小一定的情況下,我們只需要修改最大暫停時間即可。
其次,G1將新生代,老年代的物理空間劃分取消了。
這樣我們再也不用單獨的空間對每個代進行設置了,不用擔心每個代內存是否足夠。

取而代之的是,G1算法將堆劃分為若干個區域(Region),它仍然屬於分代收集器。不過,這些區域的一部分包含新生代,新生代的垃圾收集依然采用暫停所有應用線程的方式,將存活對象拷貝到老年代或者Survivor空間。老年代也分成很多區域,G1收集器通過將對象從一個區域復制到另外一個區域,完成了清理工作。這就意味著,在正常的處理過程中,G1完成了堆的壓縮(至少是部分堆的壓縮),這樣也就不會有cms內存碎片問題的存在了。
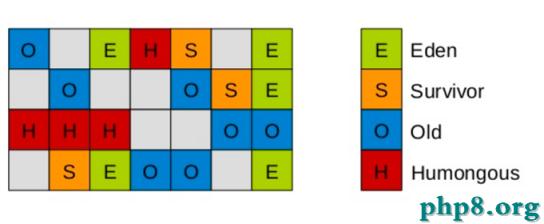
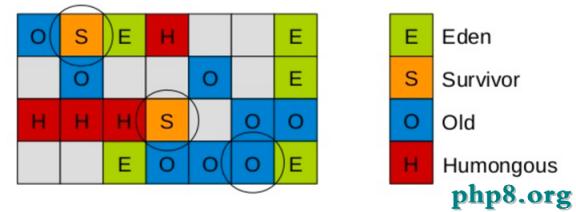
在G1中,還有一種特殊的區域,叫Humongous區域。 如果一個對象占用的空間超過了分區容量50%以上,G1收集器就認為這是一個巨型對象。這些巨型對象,默認直接會被分配在年老代,但是如果它是一個短期存在的巨型對象,就會對垃圾收集器造成負面影響。為了解決這個問題,G1劃分了一個Humongous區,它用來專門存放巨型對象。如果一個H區裝不下一個巨型對象,那麼G1會尋找連續的H分區來存儲。為了能找到連續的H區,有時候不得不啟動Full GC。
PS:在java 8中,持久代也移動到了普通的堆內存空間中,改為元空間。
對象分配策略
說起大對象的分配,我們不得不談談對象的分配策略。它分為3個階段:
TLAB為線程本地分配緩沖區,它的目的為了使對象盡可能快的分配出來。如果對象在一個共享的空間中分配,我們需要采用一些同步機制來管理這些空間內的空閒空間指針。在Eden空間中,每一個線程都有一個固定的分區用於分配對象,即一個TLAB。分配對象時,線程之間不再需要進行任何的同步。
對TLAB空間中無法分配的對象,JVM會嘗試在Eden空間中進行分配。如果Eden空間無法容納該對象,就只能在老年代中進行分配空間。
最後,G1提供了兩種GC模式,Young GC和Mixed GC,兩種都是Stop The World(STW)的。下面我們將分別介紹一下這2種模式。
三,G1 Young GCYoung GC主要是對Eden區進行GC,它在Eden空間耗盡時會被觸發。在這種情況下,Eden空間的數據移動到Survivor空間中,如果Survivor空間不夠,Eden空間的部分數據會直接晉升到年老代空間。Survivor區的數據移動到新的Survivor區中,也有部分數據晉升到老年代空間中。最終Eden空間的數據為空,GC停止工作,應用線程繼續執行。
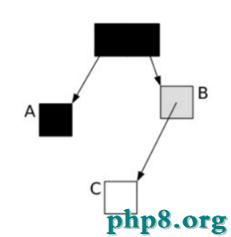
這時,我們需要考慮一個問題,如果僅僅GC 新生代對象,我們如何找到所有的根對象呢? 老年代的所有對象都是根麼?那這樣掃描下來會耗費大量的時間。於是,G1引進了RSet的概念。它的全稱是Remembered Set,作用是跟蹤指向某個heap區內的對象引用。
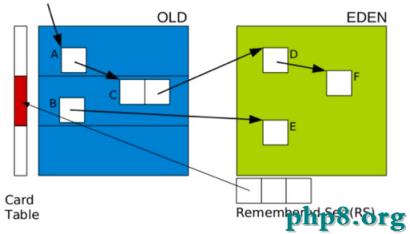
在CMS中,也有RSet的概念,在老年代中有一塊區域用來記錄指向新生代的引用。這是一種point-out,在進行Young GC時,掃描根時,僅僅需要掃描這一塊區域,而不需要掃描整個老年代。
但在G1中,並沒有使用point-out,這是由於一個分區太小,分區數量太多,如果是用point-out的話,會造成大量的掃描浪費,有些根本不需要GC的分區引用也掃描了。於是G1中使用point-in來解決。point-in的意思是哪些分區引用了當前分區中的對象。這樣,僅僅將這些對象當做根來掃描就避免了無效的掃描。由於新生代有多個,那麼我們需要在新生代之間記錄引用嗎?這是不必要的,原因在於每次GC時,所有新生代都會被掃描,所以只需要記錄老年代到新生代之間的引用即可。
需要注意的是,如果引用的對象很多,賦值器需要對每個引用做處理,賦值器開銷會很大,為了解決賦值器開銷這個問題,在G1 中又引入了另外一個概念,卡表(Card Table)。一個Card Table將一個分區在邏輯上劃分為固定大小的連續區域,每個區域稱之為卡。卡通常較小,介於128到512字節之間。Card Table通常為字節數組,由Card的索引(即數組下標)來標識每個分區的空間地址。默認情況下,每個卡都未被引用。當一個地址空間被引用時,這個地址空間對應的數組索引的值被標記為”0″,即標記為髒被引用,此外RSet也將這個數組下標記錄下來。一般情況下,這個RSet其實是一個Hash Table,Key是別的Region的起始地址,Value是一個集合,裡面的元素是Card Table的Index。
Young GC 階段:
Mix GC不僅進行正常的新生代垃圾收集,同時也回收部分後台掃描線程標記的老年代分區。
它的GC步驟分2步:
在進行Mix GC之前,會先進行global concurrent marking(全局並發標記)。 global concurrent marking的執行過程是怎樣的呢?
在G1 GC中,它主要是為Mixed GC提供標記服務的,並不是一次GC過程的一個必須環節。global concurrent marking的執行過程分為五個步驟:
三色標記算法
提到並發標記,我們不得不了解並發標記的三色標記算法。它是描述追蹤式回收器的一種有用的方法,利用它可以推演回收器的正確性。 首先,我們將對象分成三種類型的。
當GC開始掃描對象時,按照如下圖步驟進行對象的掃描:
根對象被置為黑色,子對象被置為灰色。
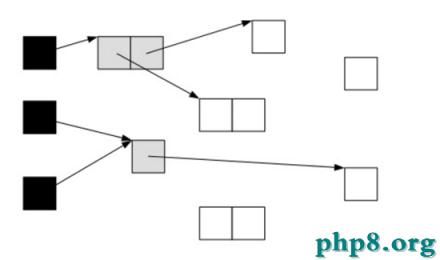
繼續由灰色遍歷,將已掃描了子對象的對象置為黑色。
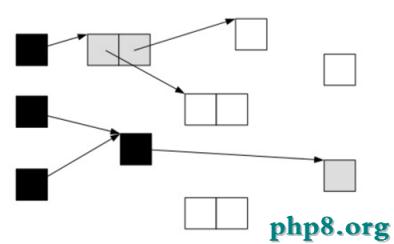
遍歷了所有可達的對象後,所有可達的對象都變成了黑色。不可達的對象即為白色,需要被清理。
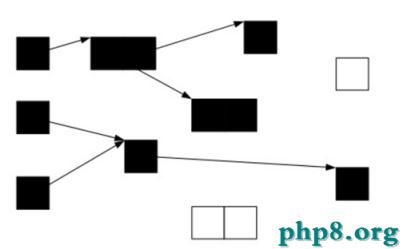
這看起來很美好,但是如果在標記過程中,應用程序也在運行,那麼對象的指針就有可能改變。這樣的話,我們就會遇到一個問題:對象丟失問題
我們看下面一種情況,當垃圾收集器掃描到下面情況時:
這時候應用程序執行了以下操作:
A.c=C
B.c=null
這樣,對象的狀態圖變成如下情形:
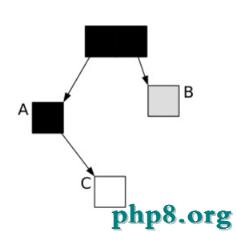
這時候垃圾收集器再標記掃描的時候就會下圖成這樣:
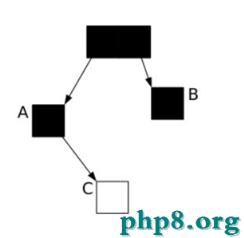
很顯然,此時C是白色,被認為是垃圾需要清理掉,顯然這是不合理的。那麼我們如何保證應用程序在運行的時候,GC標記的對象不丟失呢?有如下2中可行的方式:
剛好這對應CMS和G1的2種不同實現方式:
在CMS采用的是增量更新(Incremental update),只要在寫屏障(write barrier)裡發現要有一個白對象的引用被賦值到一個黑對象 的字段裡,那就把這個白對象變成灰色的。即插入的時候記錄下來。
在G1中,使用的是STAB(snapshot-at-the-beginning)的方式,刪除的時候記錄所有的對象,它有3個步驟:
1,在開始標記的時候生成一個快照圖標記存活對象
2,在並發標記的時候所有被改變的對象入隊(在write barrier裡把所有舊的引用所指向的對象都變成非白的)
3,可能存在游離的垃圾,將在下次被收集
這樣,G1到現在可以知道哪些老的分區可回收垃圾最多。 當全局並發標記完成後,在某個時刻,就開始了Mix GC。這些垃圾回收被稱作“混合式”是因為他們不僅僅進行正常的新生代垃圾收集,同時也回收部分後台掃描線程標記的分區。混合式垃圾收集如下圖:
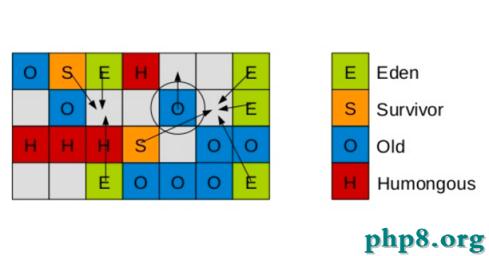
混合式GC也是采用的復制的清理策略,當GC完成後,會重新釋放空間。
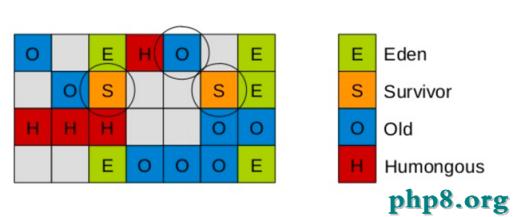
至此,混合式GC告一段落了。下一小節我們講進入調優實踐。
五,調優實踐MaxGCPauseMillis調優
前面介紹過使用GC的最基本的參數:
-XX:+UseG1GC -Xmx32g -XX:MaxGCPauseMillis=200
前面2個參數都好理解,後面這個MaxGCPauseMillis參數該怎麼配置呢?這個參數從字面的意思上看,就是允許的GC最大的暫停時間。G1盡量確保每次GC暫停的時間都在設置的MaxGCPauseMillis范圍內。 那G1是如何做到最大暫停時間的呢?這涉及到另一個概念,CSet(collection set)。它的意思是在一次垃圾收集器中被收集的區域集合。
在理解了這些後,我們再設置最大暫停時間就好辦了。 首先,我們能容忍的最大暫停時間是有一個限度的,我們需要在這個限度范圍內設置。但是應該設置的值是多少呢?我們需要在吞吐量跟MaxGCPauseMillis之間做一個平衡。如果MaxGCPauseMillis設置的過小,那麼GC就會頻繁,吞吐量就會下降。如果MaxGCPauseMillis設置的過大,應用程序暫停時間就會變長。G1的默認暫停時間是200毫秒,我們可以從這裡入手,調整合適的時間。
其他調優參數
-XX:G1HeapRegionSize=n
設置的 G1 區域的大小。值是 2 的冪,范圍是 1 MB 到 32 MB 之間。目標是根據最小的 Java 堆大小劃分出約 2048 個區域。
-XX:ParallelGCThreads=n
設置 STW 工作線程數的值。將 n 的值設置為邏輯處理器的數量。n 的值與邏輯處理器的數量相同,最多為 8。
如果邏輯處理器不止八個,則將 n 的值設置為邏輯處理器數的 5/8 左右。這適用於大多數情況,除非是較大的 SPARC 系統,其中 n 的值可以是邏輯處理器數的 5/16 左右。
-XX:ConcGCThreads=n
設置並行標記的線程數。將 n 設置為並行垃圾回收線程數 (ParallelGCThreads) 的 1/4 左右。
-XX:InitiatingHeapOccupancyPercent=45
設置觸發標記周期的 Java 堆占用率阈值。默認占用率是整個 Java 堆的 45%。
避免使用以下參數:
避免使用 -Xmn 選項或 -XX:NewRatio 等其他相關選項顯式設置年輕代大小。固定年輕代的大小會覆蓋暫停時間目標。
觸發Full GC
在某些情況下,G1觸發了Full GC,這時G1會退化使用Serial收集器來完成垃圾的清理工作,它僅僅使用單線程來完成GC工作,GC暫停時間將達到秒級別的。整個應用處於假死狀態,不能處理任何請求,我們的程序當然不希望看到這些。那麼發生Full GC的情況有哪些呢?
G1啟動標記周期,但在Mix GC之前,老年代就被填滿,這時候G1會放棄標記周期。這種情形下,需要增加堆大小,或者調整周期(例如增加線程數-XX:ConcGCThreads等)。
G1在進行GC的時候沒有足夠的內存供存活對象或晉升對象使用,由此觸發了Full GC。可以在日志中看到(to-space exhausted)或者(to-space overflow)。解決這種問題的方式是:
a,增加 -XX:G1ReservePercent 選項的值(並相應增加總的堆大小),為“目標空間”增加預留內存量。
b,通過減少 -XX:InitiatingHeapOccupancyPercent 提前啟動標記周期。
c,也可以通過增加 -XX:ConcGCThreads 選項的值來增加並行標記線程的數目。
當巨型對象找不到合適的空間進行分配時,就會啟動Full GC,來釋放空間。這種情況下,應該避免分配大量的巨型對象,增加內存或者增大-XX:G1HeapRegionSize,使巨型對象不再是巨型對象。
由於篇幅有限,G1還有很多調優實踐,在此就不一一列出了,大家在平常的實踐中可以慢慢探索。最後,期待java 9能正式發布,默認使用G1為垃圾收集器的java性能會不會又提高呢?
來自:http://blog.jobbole.com/109170/