java集合類。本站提示廣大學習愛好者:(java集合類)文章只能為提供參考,不一定能成為您想要的結果。以下是java集合類正文
java集合類包含在java.util包下
集合類存放的是對象的引用,而非對象本身。
集合類型主要分為Set(集),List(列表),Map(映射)。
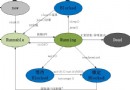
1.1 java集合類圖

HashSet是Set接口的一個子類
主要的特點是:
裡面不能存放重復元素,元素的插入順序與輸出順序不一致
采用散列的存儲方法,所以沒有順序。
package cn.swum;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
public class HashSetTest {
public static void main(String[] args) {
Set set = new HashSet();
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add("f");
//插入重復元素,測試set是否可以存放重復元素
set.add("a");
set.add(null);
//插入重復null,看結果是否可以存放兩個null
set.add(null);
Iterator iter = set.iterator();
System.out.println("輸出的排列順序為:");
while (iter.hasNext()){
System.out.println( iter.next());
}
}
}
輸出結果:
 小結:
小結:
HashSet存放的值無序切不能重復,可以存放null,但只能存放一個null值
HashSet 繼承AbstractSet,有兩個重要的方法,其中HashCode()和equals()方法,當對象被存儲到HashSet當中時,會調用HashCode()方法,獲取對象的存儲位置。
HashSet集合判斷兩個元素相等的標准是兩個對象通過equals方法比較相等,並且兩個對象的hashCode()方法返回值相等。
2.2 LinkedHashSetLinkedHashSet是HashSet的一個子類
只是HashSet底層用的HashMap,
而LinkedHashSet底層用的LinkedHashMap
package cn.swum;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
public class LinkedHashSetTest {
public static void main(String[] args) {
Set set = new LinkedHashSet();
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add("e");
System.out.println("LinkedHashSet存儲值得排序為:");
for (Iterator iter = set.iterator();iter.hasNext();){
System.out.println(iter.next());
}
}
}
輸出結果:

小結:
此時,LinkedHashSet中的元素是有序的
2.3 SortedSet(接口)SortedSet是一個接口,裡面(只有TreeSet這一個實現可用)的元素一定是有序的。
保證迭代器按照元素遞增順序遍歷的集合,
可以按照元素的自然順序(參見 Comparable)進行排序, 或者按照創建有序集合時提供的 Comparator進行排序
public interface SortedSet<E> extends Set<E> {
//返回與此有序集合關聯的比較器,如果使用元素的自然順序,則返回 null。
Comparator<? super E> comparator();
//返回此有序集合的部分元素,元素范圍從 fromElement(包括)到 toElement(不包括)。
SortedSet<E> subSet(E fromElement, E toElement);
//用一個SortedSet, 返回此有序集合中小於end的所有元素。
SortedSet<E> headSet(E toElement);
//返回此有序集合的部分元素,其元素大於或等於 fromElement。
SortedSet<E> tailSet(E fromElement);
//返回此有序集合中當前第一個(最小的)元素。
E first();
//返回此有序集合中最後一個(最大的)元素
E last();
}
2.4 TreeSet
TreeSet類實現Set 接口,該接口由TreeMap 實例支持,此類保證排序後的 set 按照升序排列元素,
根據使用的構造方法不同,可能會按照元素的自然順序 進行排序(參見 Comparable或按照在創建 set 時所提供的比較器進行排序。
Set 接口根據 equals 操作進行定義,但 TreeSet 實例將使用其 compareTo(或 compare)方法執行所有的鍵比較
package cn.swum;
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetTest {
static class Person{
int id;
String name;
int age;
public Person(int id, String name, int age){
this.id = id;
this.name = name;
this.age = age;
}
public String toString(){
return "id:"+ this.id + " " + "name:" + this.name +" " + "age:" + this.age;
}
}
static class MyComparator implements Comparator<Person> {
@Override
public int compare(Person p1, Person p2) {
if(p1 == p2) {
return 0;
}
if(p1 != null && p2 == null) {
return 1;
}else if(p1 == null && p2 != null){
return -1;
}
if(p1.id > p2.id){
return 1;
}else if(p1.id < p2.id){
return -1;
}
return 0;
}
}
public static void main(String[] args) {
MyComparator myComparator = new MyComparator();
TreeSet<Person> treeSet = new TreeSet<>(myComparator);
treeSet.add(new Person(3,"張三",20));
treeSet.add(new Person(2,"王二",22));
treeSet.add(new Person(1,"趙一",18));
treeSet.add(new Person(4,"李四",29));
//增加null空對象
treeSet.add(null);
System.out.println("TreeSet的排序是:");
for (Person p : treeSet){
if(p == null){
System.out.println(p);
}else {
System.out.println(p.toString());
}
}
}
}
實例用TreeSet保存對象引用,並且實現Comparator中compare方法進行比較和排序
輸出結果:
表明TreeSet是可以按照自定義方法中的比較進行排序的,且可以有空值。
Vector 類也是基於數組實現的隊列,代碼與ArrayList非常相似。
線程安全,執行效率低。
動態數組的增長系數
由於效率低,並且線程安全也是相對的,因此不推薦使用vector
Stack 是繼承了Vector,是一個先進後出的隊列
Stack裡面主要實現的有一下幾個方法:
package cn.swum;
import java.util.Stack;
public class StackTest {
static class Person{
int id;
String name;
int age;
public Person(int id, String name, int age){
this.id = id;
this.name = name;
this.age = age;
}
public String toString(){
return "id:"+ this.id + " " + "name:" + this.name +" " + "age:" + this.age;
}
}
public static void main(String[] args) {
Stack stack = new Stack();
stack.push(new Person(1,"趙一",18));
stack.push(new Person(2,"王二",19));
stack.push(new Person(3,"張三",20));
stack.push(new Person(4,"李四",21));
System.out.println("棧頂元素是:(" + stack.peek() + ")");
System.out.println("目標元素離棧頂多少距離:" + stack.search(stack.get(0)));
System.out.println("棧元素從棧頂到棧底的排序是:");
//此處先用size保存是因為pop時,size會減1,
// 如果直接stack.size放在循環中比較,只能打印一半對象
int size = stack.size();
for (int i = 0; i < size ; i++) {
Person p = (Person) stack.pop();
System.out.println(p.toString());
}
}
}
輸出結果:

Stack 是一個有序的棧,遵循先進後出原則。
ArrayList是List的子類,它和HashSet相反,允許存放重復元素,因此有序。
集合中元素被訪問的順序取決於集合的類型。
如果對ArrayList進行訪問,迭代器將從索引0開始,每迭代一次,索引值加1。
然而,如果訪問HashSet中的元素,每個元素將會按照某種隨機的次序出現。
雖然可以確定在迭代過程中能夠遍歷到集合中的所有元素,但卻無法預知元素被訪問的次序。
代碼實例:ArrayListTestpackage cn.swum;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class ArrayListTest {
public static void main(String[] args) {
List<String> arrayList = new ArrayList<String>();
arrayList.add("a");
arrayList.add("b");
arrayList.add("c");
//添加重復值
arrayList.add("a");
arrayList.add("d");
arrayList.add("e");
//添加null
arrayList.add(null);
System.out.println("arrayList的輸出順序為:");
for (int i = 0; i < arrayList.size(); i++) {
System.out.println((i+1) + ":" +arrayList.get(i));
}
}
}
輸出結果:

ArrayList是一個有序且允許重復和空值的列表
LinkedList是一種可以在任何位置進行高效地插入和刪除操作的有序序列。
代碼實例:LinkedListTestpackage cn.swum;
import java.util.LinkedList;
/**
* @author long
* @date 2017/2/28
*/
public class LinkedListTest {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<String>();
linkedList.add("a");
linkedList.add("b");
linkedList.add("c");
linkedList.add("d");
linkedList.add("e");
linkedList.add(2,"2");
System.out.println("linkedList的輸出順序是:" + linkedList.toString());
linkedList.push("f");
System.out.println("push後,linkedList的元素順序:" + linkedList.toString());
linkedList.pop();
System.out.println("pop後,linkedList的所剩元素:" + linkedList.toString());
}
}
輸出結果:
LinkedList是有序的雙向鏈表,可以在任意時刻進行元素的插入與刪除,讀取效率低於ArrayList,插入效率高
pop和push操作都是在隊頭開始
HashMap的數據結構:
數組的特點是:尋址容易,插入和刪除困難;
而鏈表的特點是:尋址困難,插入和刪除容易。
哈希表結合了兩者的優點。
哈希表有多種不同的實現方法,可以理解將此理解為“鏈表的數組”

從上圖我們可以發現哈希表是由數組+鏈表組成的,一個長度為16的數組中,每個元素存儲的是一個鏈表的頭結點。那麼這些元素是按照什麼樣的規則存儲到數組中呢。一般情況是通過hash(key)%len獲得,也就是元素的key的哈希值對數組長度取模得到。比如上述哈希表中:
12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存儲在數組下標為12的位置。然後每個線性的數組下存儲一個鏈表,鏈接起來。
首先HashMap裡面實現一個靜態內部類Entry,其重要的屬性有 key , value, next,從屬性key,value我們就能很明顯的看出來Entry就是HashMap鍵值對實現的一個基礎bean.我們上面說到HashMap的基礎就是一個線性數組,這個數組就是Entry[],Map裡面的內容都保存在Entry[]裡面。
HashMap的存取實現:
//存儲時: int hash = key.hashCode();// 這個hashCode方法這裡不詳述,只要理解每個key的hash是一個固定的int值 int index = hash % Entry[].length; Entry[index] = value;
//取值時: int hash = key.hashCode(); int index = hash % Entry[].length; return Entry[index];
疑問:如果兩個key通過hash%Entry[].length得到的index相同,會不會有覆蓋的危險?
這裡HashMap裡面用到鏈式數據結構的一個概念。上面我們提到過Entry類裡面有一個next屬性,作用是指向下一個Entry。打個比方,第一個鍵值對A進來,通過計算其key的hash得到的index=0,記做:Entry[0] = A。一會後又進來一個鍵值對B,通過計算其index也等於0,現在怎麼辦?
HashMap會這樣做:B.next = A,Entry[0] = B,如果又進來C,index也等於0,那麼C.next = B,Entry[0] = C;這樣我們發現index=0的地方其實存取了A,B,C三個鍵值對,他們通過next這個屬性鏈接在一起。所以疑問不用擔心。也就是說數組中存儲的是最後插入的元素。
HashMapTest代碼實例,自我實現HashMap:Entry.java
package cn.swum.cn.swun.hash;
/**
* @author long
* @date 2017/2/28
*/
public class Entry <K,V>{
final K key;
V value;
Entry<K,V> next;//下一個結點
//構造函數
public Entry(K k, V v, Entry<K,V> n) {
key = k;
value = v;
next = n;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Entry))
return false;
Entry e = (Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^ (value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}
MyHashMap.java
package cn.swum.cn.swun.hash;
/**
* @author long
* @date 2017/2/28
*/
public class MyHashMap<K,V>{
private Entry[] table;//Entry數組表
static final int DEFAULT_INITIAL_CAPACITY = 16;//默認數組長度
private int size;
// 構造函數
public MyHashMap() {
table = new Entry[DEFAULT_INITIAL_CAPACITY];
size = DEFAULT_INITIAL_CAPACITY;
}
//獲取數組長度
public int getSize() {
return size;
}
// 求index
static int indexFor(int h, int length) {
return h % (length - 1);
}
//獲取元素
public V get(Object key) {
if (key == null)
return null;
int hash = key.hashCode();// key的哈希值
int index = indexFor(hash, table.length);// 求key在數組中的下標
for (Entry<K, V> e = table[index]; e != null; e = e.next) {
Object k = e.key;
if (e.key.hashCode() == hash && (k == key || key.equals(k)))
return e.value;
}
return null;
}
// 添加元素
public V put(K key, V value) {
if (key == null)
return null;
int hash = key.hashCode();
int index = indexFor(hash, table.length);
// 如果添加的key已經存在,那麼只需要修改value值即可
for (Entry<K, V> e = table[index]; e != null; e = e.next) {
Object k = e.key;
if (e.key.hashCode() == hash && (k == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;// 原來的value值
}
}
// 如果key值不存在,那麼需要添加
Entry<K, V> e = table[index];// 獲取當前數組中的e
table[index] = new Entry<K, V>(key, value, e);// 新建一個Entry,並將其指向原先的e
return null;
}
}
MyHashMapTest.java
package cn.swum.cn.swun.hash;
/**
* @author long
* @date 2017/2/28
*/
public class MyHashMapTest {
public static void main(String[] args) {
MyHashMap<Integer, Integer> map = new MyHashMap<Integer, Integer>();
map.put(1, 90);
map.put(2, 95);
map.put(17, 85);
System.out.println(map.get(1));
System.out.println(map.get(2));
System.out.println(map.get(17));
System.out.println(map.get(null));
}
}
輸出結果:

package cn.swum.cn.swun.hash;
import java.util.WeakHashMap;
/**
* @author long
* @date 2017/2/28
*/
public class WeekHashMapTest {
public static void main(String[] args) {
int size = 10;
if (args.length > 0) {
size = Integer.parseInt(args[0]);
}
Key[] keys = new Key[size];
WeakHashMap<Key, Value> whm = new WeakHashMap<Key, Value>();
for (int i = 0; i < size; i++) {
Key k = new Key(Integer.toString(i));
Value v = new Value(Integer.toString(i));
if (i % 3 == 0) {
keys[i] = k;//強引用
}
whm.put(k, v);//所有鍵值放入WeakHashMap中
}
System.out.println(whm);
System.out.println(whm.size());
System.gc();
try {
// 把處理器的時間讓給垃圾回收器進行垃圾回收
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(whm);
System.out.println(whm.size());
}
}
class Key {
String id;
public Key(String id) {
this.id = id;
}
public String toString() {
return id;
}
public int hashCode() {
return id.hashCode();
}
public boolean equals(Object r) {
return (r instanceof Key) && id.equals(((Key) r).id);
}
public void finalize() {
System.out.println("Finalizing Key " + id);
}
}
class Value {
String id;
public Value(String id) {
this.id = id;
}
public String toString() {
return id;
}
public void finalize() {
System.out.println("Finalizing Value " + id);
}
}
輸出結果:

HashTable和HashMap存在很多的相同點,但是他們還是有幾個比較重要的不同點。
我們從他們的定義就可以看出他們的不同,HashTable基於Dictionary類,而HashMap是基於AbstractMap。Dictionary是什麼?它是任何可將鍵映射到相應值的類的抽象父類,而AbstractMap是基於Map接口的骨干實現,它以最大限度地減少實現此接口所需的工作。
HashMap可以允許存在一個為null的key和任意個為null的value,但是HashTable中的key和value都不允許為null。如下:當HashMap遇到為null的key時,它會調用putForNullKey方法來進行處理。對於value沒有進行任何處理,只要是對象都可以。
Hashtable的方法是同步的,而HashMap的方法不是。所以有人一般都建議如果是涉及到多線程同步時采用HashTable,沒有涉及就采用HashMap,但是在Collections類中存在一個靜態方法:synchronizedMap(),該方法創建了一個線程安全的Map對象,並把它作為一個封裝的對象來返回,所以通過Collections類的synchronizedMap方法是可以我們你同步訪問潛在的HashMap。
遍歷不同:HashMap僅支持Iterator的遍歷方式,Hashtable支持Iterator和Enumeration兩種遍歷方式。