談談為JAXB和response設置編碼,處理wechat4j中文亂碼的問題。本站提示廣大學習愛好者:(談談為JAXB和response設置編碼,處理wechat4j中文亂碼的問題)文章只能為提供參考,不一定能成為您想要的結果。以下是談談為JAXB和response設置編碼,處理wechat4j中文亂碼的問題正文
假如有哪一個做順序員的小同伴說自己沒有遇到中文亂碼問題,我是不情願置信的。明天在做微信訂閱號的智能回復時,又一時迷亂的跳進了中文亂碼這個火坑。剛處理問題時,都喝彩雀躍了,完全遺忘了她已經帶給我的苦楚。
一、問題描繪
看到沒,白色框框內的亂碼光禿禿的對我停止尋釁,而我卻迫不得已,真是蹩腳透頂。
二、尋求處理之道
面對問題,只要拿著刀逼自己去處理啊,能怎樣樣呢?
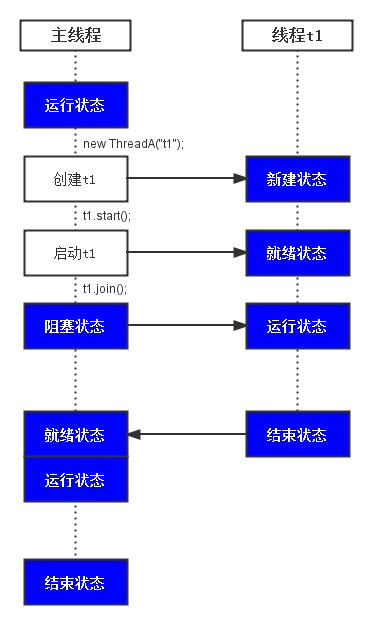
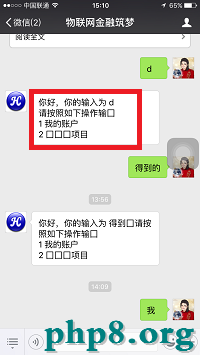
首先,必需搞清楚微信智能回復的機制,畫圖如下:
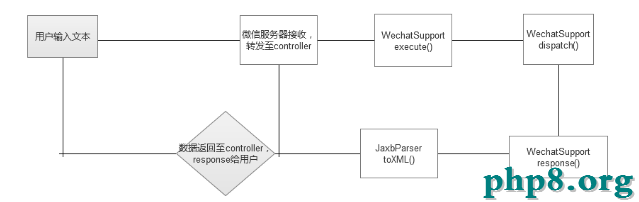
ps,工具用得不好,請見諒。
接上去,我們抓重點,看亂碼重要發作在什麼地位。
1.controller前往給用戶
response.setHeader("content-type", "text/html;charset=UTF-8");// 閱讀器編碼
response.getOutputStream().write(result.getBytes());
就這段代碼了,指定response的編碼方式為UTF-8,按理說亂碼問題應該呈現惡化,但是後果仍然是沒有。
2.JAXB的toXML
public String toXML(Object obj) {
String result = null;
try {
JAXBContext context = JAXBContext.newInstance(obj.getClass());
Marshaller m = context.createMarshaller();
m.setProperty(Marshaller.JAXB_ENCODING, "UTF-8");
m.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, true);
m.setProperty(Marshaller.JAXB_FRAGMENT, true);// 去掉報文頭
ByteArrayOutputStream os = new ByteArrayOutputStream();
XMLSerializer serializer = getXMLSerializer(os);
m.marshal(obj, serializer.asContentHandler());
result = os.toString("UTF-8");
} catch (Exception e) {
e.printStackTrace();
}
logger.info("response text:" + result);
return result;
}
private XMLSerializer getXMLSerializer(OutputStream os) {
OutputFormat of = new OutputFormat();
formatCDataTag();
of.setCDataElements(cdataNode);
of.setPreserveSpace(true);
of.setIndenting(true);
of.setOmitXMLDeclaration(true);
of.setEncoding("UTF-8");
XMLSerializer serializer = new XMLSerializer(of);
serializer.setOutputByteStream(os);
return serializer;
}
這裡有三個關鍵的點:
1. m.setProperty(Marshaller.JAXB_ENCODING, "UTF-8");
2. getXMLSerializer(os)
3. os.toString("UTF-8");
可以看到以上三個中央均會觸及到轉碼,第1處,設置Marshaller的編碼;第二處,設置整個XMLSerializer的編碼;第三處,設置前往的ByteArrayOutputStream的string編碼。三處缺一不可。
這次這麼透徹,應該處理了問題了吧,但是處理仍然中文亂碼,那該如何是好呢?
3.tomcat的輸入環境作祟
針對這一點,網上有人提供這樣的處理思緒。
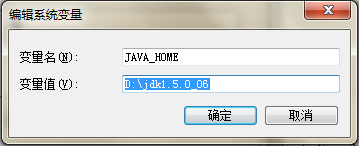
set JAVA_OPTS=%JAVA_OPTS% %LOGGING_MANAGER% -Dfile.encoding=UTF-8
設置後重啟tomcat,問題是可以處理,但反作用是整個tomcat在服務器上運轉輸入(tomcat的cmd窗口)不斷是亂碼,我以為這種方案不可取。
在運轉的war中參加以下代碼
System.getProperty("file.encoding");
你會驚奇的發現,tomcat的運轉環境(window server 2008)居然是GBK,不知道你能否不驚奇,我是嚇到了,為什麼不是UTF-8呢?假如是GBK的話,下面兩個步驟中我參加再多的UTF-8頁扯淡啊,不解。
三、處理問題
有了以上的經歷,我們修正以下wechat4j的代碼,次要是第二點。
public String toXML(Object obj) {
String result = null;
try {
JAXBContext context = JAXBContext.newInstance(obj.getClass());
Marshaller m = context.createMarshaller();
String encoding = Config.instance().getJaxb_encoding();
logger.debug("toXML encoding " + encoding + "System file.encoding " + System.getProperty("file.encoding"));
m.setProperty(Marshaller.JAXB_ENCODING, encoding);
m.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, true);
m.setProperty(Marshaller.JAXB_FRAGMENT, true);// 去掉報文頭
ByteArrayOutputStream os = new ByteArrayOutputStream();
XMLSerializer serializer = getXMLSerializer(os);
m.marshal(obj, serializer.asContentHandler());
result = os.toString(encoding);
} catch (Exception e) {
e.printStackTrace();
}
logger.info("response text:" + result);
return result;
}
private XMLSerializer getXMLSerializer(OutputStream os) {
OutputFormat of = new OutputFormat();
formatCDataTag();
of.setCDataElements(cdataNode);
of.setPreserveSpace(true);
of.setIndenting(true);
of.setOmitXMLDeclaration(true);
String encoding = Config.instance().getJaxb_encoding();
of.setEncoding(encoding);
XMLSerializer serializer = new XMLSerializer(of);
serializer.setOutputByteStream(os);
return serializer;
}
這兩個辦法中,對encoding我們加上可配置的編碼方式,可手動設置GBK(我的服務器上配置了GBK)、GB2312、UTF-8。
如此,會發現wechat4j的後台輸入就不再是中文亂碼了,但前往給用戶的信息更亂了。
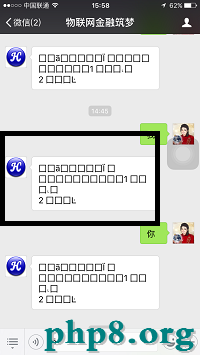
怎樣能這樣呢,耍我這枚順序員啊,真想吐兩句髒話。但別怕啊,既然wechat4j的logger日志不再中文亂碼,那麼只能說是第1個環節又呈現問題了。
調整嘛
response.setHeader("content-type", "text/html;charset=UTF-8");// 閱讀器編碼
response.getOutputStream().write(result.getBytes("UTF-8"));
留意,這裡不能是GBK,只能是UTF-8,我表示不清楚為什麼,微信的產品經理給出來解釋下。
重點,JAXB和response合伙處理wechat4j中文亂碼的 辦法再次聲明如下:
WeChatController.Java,就是你配給微信大眾開發平台的URL處,response調整如下
response.setHeader("content-type", "text/html;charset=UTF-8");// 閱讀器編碼
response.getOutputStream().write(result.getBytes("UTF-8"));
wechat4j的JaxbParser.java,辨別調整toXML(Object obj)和getXMLSerializer(OutputStream os)辦法:
public String toXML(Object obj) {
String result = null;
try {
JAXBContext context = JAXBContext.newInstance(obj.getClass());
Marshaller m = context.createMarshaller();
String encoding = Config.instance().getJaxb_encoding();// GBK
logger.debug("toXML encoding " + encoding + "System file.encoding " + System.getProperty("file.encoding"));
m.setProperty(Marshaller.JAXB_ENCODING, encoding);
m.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, true);
m.setProperty(Marshaller.JAXB_FRAGMENT, true);// 去掉報文頭
ByteArrayOutputStream os = new ByteArrayOutputStream();
XMLSerializer serializer = getXMLSerializer(os);
m.marshal(obj, serializer.asContentHandler());
result = os.toString(encoding);
} catch (Exception e) {
e.printStackTrace();
}
logger.info("response text:" + result);
return result;
}
private XMLSerializer getXMLSerializer(OutputStream os) {
OutputFormat of = new OutputFormat();
formatCDataTag();
of.setCDataElements(cdataNode);
of.setPreserveSpace(true);
of.setIndenting(true);
of.setOmitXMLDeclaration(true);
String encoding = Config.instance().getJaxb_encoding();//GBK
of.setEncoding(encoding);
XMLSerializer serializer = new XMLSerializer(of);
serializer.setOutputByteStream(os);
return serializer;
}
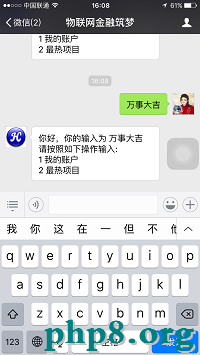
好了,萬事大吉了。
以上就是本文的全部內容,希望對大家的學習有所協助,也希望大家多多支持。