Java完成爬蟲給App供給數據(Jsoup 收集爬蟲)。本站提示廣大學習愛好者:(Java完成爬蟲給App供給數據(Jsoup 收集爬蟲))文章只能為提供參考,不一定能成為您想要的結果。以下是Java完成爬蟲給App供給數據(Jsoup 收集爬蟲)正文
1、需求
比來基於 Material Design 重構了本身的消息 App,數據起源是個成績。
有後人剖析了知乎日報、鳳凰消息等 API,依據響應的 URL 可以獲得消息的 JSON 數據。為了錘煉寫代碼才能,筆者盤算爬蟲消息頁面,本身獲得數據構建 API。
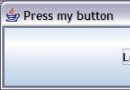
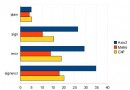
2、後果圖
下圖是原網站的頁面
爬蟲獲得了數據,展現到 APP 手機端
3、爬蟲思緒
關於App 的完成進程可以參看這幾篇文章,本文重要講授一下若何爬蟲數據。
Android下錄制App操作生成Gif靜態圖的全進程 :http://www.jb51.net/article/78236.htm
進修Android Material Design(RecyclerView取代ListView):http://www.jb51.net/article/78232.htm
Android項目實戰之仿網易消息的頁面(RecyclerView ):http://www.jb51.net/article/78230.htm
Jsoup 簡介
Jsoup 是一個 Java 的開源HTML解析器,可直接解析某個URL地址、HTML文本內容。
Jsoup重要有以下功效:
4、爬蟲進程
Get 要求獲得網頁 HTML
消息網頁Html的DOM樹以下所示:
上面這段代碼依據指定的 url,用代碼獲得get 要求前往的 html 源代碼。
public static String doGet(String urlStr) throws CommonException {
URL url;
String html = "";
try {
url = new URL(urlStr);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(5000);
connection.setDoInput(true);
connection.setDoOutput(true);
if (connection.getResponseCode() == 200) {
InputStream in = connection.getInputStream();
html = StreamTool.inToStringByByte(in);
} else {
throw new CommonException("消息辦事器前往值不為200");
}
} catch (Exception e) {
e.printStackTrace();
throw new CommonException("get要求掉敗");
}
return html;
}
InputStream in = connection.getInputStream();將獲得輸出流轉化為字符串是個廣泛需求,我們將其籠統出來,寫一個對象辦法。
public class StreamTool {
public static String inToStringByByte(InputStream in) throws Exception {
ByteArrayOutputStream outStr = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = 0;
StringBuilder content = new StringBuilder();
while ((len = in.read(buffer)) != -1) {
content.append(new String(buffer, 0, len, "UTF-8"));
}
outStr.close();
return content.toString();
}
}
5、解析 HTML 獲得題目
應用 谷歌 閱讀器的審查元素,找出消息題目關於的html 代碼:
<div id="article_title"> <h1> <a href="http://see.xidian.edu.cn/html/news/7428.html"> 關於舉行《經典音樂作品觀賞與人文審美》講座的告訴 </a> </h1> </div>
我們須要從下面的 HTML 中找出id="article_title"的部門,應用 getElementById(String id) 辦法
String htmlStr = HttpTool.doGet(urlStr);
// 將獲得的網頁 HTML 源代碼轉化為 Document
Document doc = Jsoup.parse(htmlStr);
Element articleEle = doc.getElementById("article");
// 題目
Element titleEle = articleEle.getElementById("article_title");
String titleStr = titleEle.text();
6、獲得宣布日期、信息起源
異樣找出關於的 HTML 代碼
<html> <head></head> <body> <div id="article_detail"> <span> 2015-05-28 </span> <span> 起源: </span> <span> 閱讀次數: <script language="JavaScript" src="http://see.xidian.edu.cn/index.php/news/click/id/7428"> </script> 477 </span> </div> </body> </html>
思緒也和下面相似,應用 getElementById(String id) 辦法找出id="article_detail"為Element,再應用getElementsByTag獲得span 部門。由於一共有3個<span> ... </span>,所以前往的是Elements而不是Element。
// article_detail包含了 2016-01-15 起源: 閱讀次數:177
Element detailEle = articleEle.getElementById("article_detail");
Elements details = detailEle.getElementsByTag("span");
// 宣布時光
String dateStr = details.get(0).text();
// 消息起源
String sourceStr = details.get(1).text();
7、解析閱讀次數
假如打印出下面的details.get(2).text(),只會獲得
閱讀次數:
沒有閱讀次數?為何呢?
由於閱讀次數是JavaScript 襯著出來的, Jsoup爬蟲能夠僅僅提取HTML內容,得不到靜態襯著出的數據。
處理辦法有兩種
假如你拜訪下面的 urlhttp://see.xidian.edu.cn/index.php/news/click/id/7428,會獲得上面的成果
document.write(478)
這個478就是我們須要的閱讀次數,我們對下面的url做get 要求,獲得前往的字符串,應用正則找出個中的數字。
// 拜訪這個消息頁面,閱讀次數會+1,次數是 JS 襯著的
String jsStr = HttpTool.doGet(COUNT_BASE_URL + currentPage);
int readTimes = Integer.parseInt(jsStr.replaceAll("\\D+", ""));
// 或許應用上面這個正則辦法
// String readTimesStr = jsStr.replaceAll("[^0-9]", "");
8、解析消息內容
原來是獲得消息內容純文字的情勢,但後來發明 Android 端也能夠顯示 CSS 格局,所今後來內容保存了 HTML 格局。
Element contentEle = articleEle.getElementById("article_content");
// 消息主體內容
String contentStr = contentEle.toString();
// 假如用 text()辦法,消息主體內容的 html 標簽會喪失
// 為了在 Android 上用 WebView 顯示 html,用toString()
// String contentStr = contentEle.text();
9、解析圖片 Url
留意一個網頁上年夜年夜小小的圖片許多,為了只獲得消息注釋中的內容,我們最好起首定位到消息內容的Element,然後再應用getElementsByTag(“img”)挑選出圖片。
Element contentEle = articleEle.getElementById("article_content");
// 消息主體內容
String contentStr = contentEle.toString();
// 假如用 text()辦法,消息主體內容的 html 標簽會喪失
// 為了在 Android 上用 WebView 顯示 html,用toString()
// String contentStr = contentEle.text();
Elements images = contentEle.getElementsByTag("img");
String[] imageUrls = new String[images.size()];
for (int i = 0; i < imageUrls.length; i++) {
imageUrls[i] = images.get(i).attr("src");
}
10、消息實體類 JavaBean
下面獲得了消息的題目、宣布日期、浏覽次數、消息內容等等,我們天然須要結構一個 javabean,把獲得的內容封裝進實體類中。
public class ArticleItem {
private int index;
private String[] imageUrls;
private String title;
private String publishDate;
private String source;
private int readTimes;
private String body;
public ArticleItem(int index, String[] imageUrls, String title, String publishDate, String source, int readTimes,
String body) {
this.index = index;
this.imageUrls = imageUrls;
this.title = title;
this.publishDate = publishDate;
this.source = source;
this.readTimes = readTimes;
this.body = body;
}
@Override
public String toString() {
return "ArticleItem [index=" + index + ",\n imageUrls=" + Arrays.toString(imageUrls) + ",\n title=" + title
+ ",\n publishDate=" + publishDate + ",\n source=" + source + ",\n readTimes=" + readTimes + ",\n body=" + body
+ "]";
}
}
測試
public static ArticleItem getNewsItem(int currentPage) throws CommonException {
// 依據後綴的數字,拼接消息 url
String urlStr = ARTICLE_BASE_URL + currentPage + ".html";
String htmlStr = HttpTool.doGet(urlStr);
Document doc = Jsoup.parse(htmlStr);
Element articleEle = doc.getElementById("article");
// 題目
Element titleEle = articleEle.getElementById("article_title");
String titleStr = titleEle.text();
// article_detail包含了 2016-01-15 起源: 閱讀次數:177
Element detailEle = articleEle.getElementById("article_detail");
Elements details = detailEle.getElementsByTag("span");
// 宣布時光
String dateStr = details.get(0).text();
// 消息起源
String sourceStr = details.get(1).text();
// 拜訪這個消息頁面,閱讀次數會+1,次數是 JS 襯著的
String jsStr = HttpTool.doGet(COUNT_BASE_URL + currentPage);
int readTimes = Integer.parseInt(jsStr.replaceAll("\\D+", ""));
// 或許應用上面這個正則辦法
// String readTimesStr = jsStr.replaceAll("[^0-9]", "");
Element contentEle = articleEle.getElementById("article_content");
// 消息主體內容
String contentStr = contentEle.toString();
// 假如用 text()辦法,消息主體內容的 html 標簽會喪失
// 為了在 Android 上用 WebView 顯示 html,用toString()
// String contentStr = contentEle.text();
Elements images = contentEle.getElementsByTag("img");
String[] imageUrls = new String[images.size()];
for (int i = 0; i < imageUrls.length; i++) {
imageUrls[i] = images.get(i).attr("src");
}
return new ArticleItem(currentPage, imageUrls, titleStr, dateStr, sourceStr, readTimes, contentStr);
}
public static void main(String[] args) throws CommonException {
System.out.println(getNewsItem(7928));
}
輸入信息
ArticleItem [index=7928, imageUrls=[/uploads/image/20160114/20160114225911_34428.png], title=電院2014級展開“讓誠信之花開遍冬季校園”教導運動, publishDate=2016-01-14, source=起源: 片子消息網, readTimes=200, body=<div id="article_content"> <p align="justify"> <strong><span >西電消息網訊</span></strong><span > (通信員</span><strong><span > 丁彤 王朱丹</span></strong><span >...)
本文講授了若何完成Jsoup 收集爬蟲,假如文章對您有贊助,那就給個贊吧。