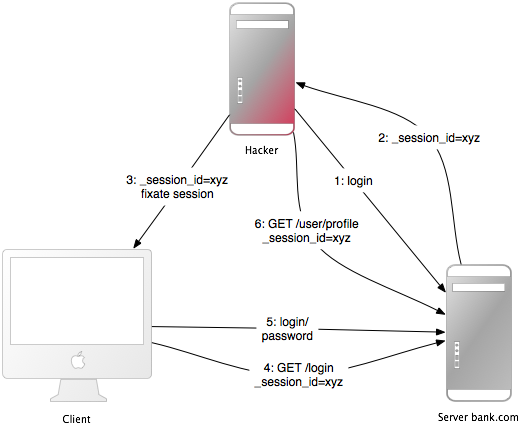
聊聊Java和CPU的關系。本站提示廣大學習愛好者:(聊聊Java和CPU的關系)文章只能為提供參考,不一定能成為您想要的結果。以下是聊聊Java和CPU的關系正文
其實寫Java的人貌似和CPU沒啥關系,最多最多和我們在後面說起到的若何將CPU跑滿、若何設置線程數有點關系,然則誰人算法只是一個參考,許多場景分歧須要采用現實的手腕來處理才可以;並且將CPU跑滿後我們還會斟酌若何讓CPU不是那末滿,呵呵,人類,就是這麼XX,呵呵,好了,本文要說的是其他的一些器械,或許你在java的寫代碼時簡直不消存眷CPU,由於知足營業才是第一主要的工作,假如你要做到框架級別,為框架供給許多同享數據緩存之類的器械,中央必定存在許多數據的征用成績,固然java供給了許多concurrent包的類,你可以用它,然則它外部若何做的,你要明確細節能力用得比擬好,不然還不如不消,本文能夠不是論述這些內容作為重點,由於如題目黨:我們要說CPU,呵呵。
照樣那句話,貌似java和CPU沒有若干關系,我們如今來聊聊有啥關系;
1、當碰到同享元素,我們平日第一設法主意是經由過程volatile來包管分歧性讀的操作,也就是相對的可見性,所謂可見性,就是每主要應用該數據的時刻,CPU不會應用任何cache的內容都邑從內存中去抓取一次數據,而且這個進程對多CPU依然有用,也就是相當CPU和內存之間此時是同步的,CPU會像總線收回一個Lock addl 0相似的的匯編指令,+0但絕對於甚麼都不會做;不外一旦該指令完成,後續操作將不再影響這個元素其他線程的拜訪,也就是他能完成的相對可見性,然則不克不及完成分歧性操作,也就是說,volatile不克不及完成的是i++這類操作的分歧性(在多線程下並發),由於i++操作是被分化為:
int tmp = i; tmp = tmp + 1; i = tmp;
這三個步調來完成,從這點你也能看出i++為何能完成先做其他的工作再自我加1,由於它講值付與給了另外一個變量。
2、我們要用到多線程並發分歧性,就須要用到鎖的機制,今朝相似Atomic*的器械根本可以知足這些請求,外部供給了許多unsafe類的辦法,經由過程赓續比較相對可見性的數據來包管獲得的數據是最新的;接上去我們持續來講一些CPU其他的工作。
3、之前我們為了將CPU跑滿,然則不管若何跑不滿,由於我們開端說了疏忽失落內存與CPU的延遲,明天既然說起到這兒,我們就簡略說下延遲,普通來說如今的CPU有三級cache,年月分歧延遲分歧,所以詳細數字只能說個年夜概罷了,如今的CPU普通一級cache的延遲在1-2ns,二級cache普通是幾個ns到十來ns閣下,三級cache普通是30ns到50ns不等,內存拜訪廣泛會上到70ns乃至更多(盤算機成長速度很快,這個值也僅僅在某些CPU上的數據,做一個規模參考罷了);別看這個延遲很小,都是納秒級別,你會發明你的法式被拆分為指令運算的時刻,會有許多CPU交互,每次交互的延遲假如有這麼年夜的誤差,此時體系機能是會有變更的;
4、回到適才說的volatile,它每次從內存中獲得數據,就是廢棄cache,天然假如在某些單線程的操作中,會變得加倍慢,有些時刻我們也不能不如許做,乃至於讀寫操作都請求分歧性,乃至於全部數據塊都被同步,我們只能在必定水平上下降鎖的粒度,然則不克不及完整沒有鎖,即便是CPU自己級別也會有指令級其余限制。
5、在CPU自己級其余原子操作普通叫樊籬,有讀樊籬、寫樊籬等,普通是基於一個點的觸發,當法式多條指令發送到CPU的時刻,有些指令未必是依照法式的次序來履行,有些必需依照法式的次序來履行,只需能終究包管分歧便可;在排序上,JIT在運轉時會做轉變,CPU指令級別也會做轉變,緣由重要是為了優化運轉時指令讓法式跑得更快。
6、CPU級別會對內存做cache line的操作,所謂cache line會持續讀一塊內存,普通和CPU型號和架構有關系,如今許多CPU每次讀取持續內存普通是64byte,晚期的有32byte的,所以在某些數組遍歷的時刻會比擬快(基於列遍歷很慢),但這個其實不完整對,上面會對比一些相反的情形來講。
7、CPU對數據假如產生了修正,此時就不能不說CPU對數據修正的狀況,數據假如都被讀取,在多CPU下可以被多線程並行讀取並,當對數據塊產生寫操作的時刻,就紛歧樣了,數據塊會有獨有、修正、掉效等狀況,數據修正後天然就會掉效,當在多CPU下,多個線程都在對統一個數據塊停止修正時,就會產生CPU之間的總線數據拷貝(QPI),固然假如修正到統一個數據上的時刻我們是沒有方法的,然則回到第6點的cache line外面,成績就比擬費事了,假如數據是在統一個數組上,而數組中的元素會被同時cache line到一個CPU上的時刻,多線程的QPI就會異常頻仍,有些時刻即便是數組上組裝的是對象也會湧現這個成績,如:
class InputInteger {
private int value;
public InputInteger(int i) {
this.value = i;
}
}
InputInteger[] integers = new InputInteger[SIZE];
for(int i=0 ; i < SIZE ; i++) {
integers[i] = new InputInteger(i);
}
此時你看出來integers外面放的全體是對象,數組上只要對象的援用,然則對象的排布實際上說各自對象是自力的,不會持續寄存,不外java在分派對象內存的時刻,許多時刻,在Eden區域是持續分派的,當在for輪回的時刻,假如沒有其他線程的接入,這些對象就會被寄存在一路,即便被GC到OLD區域也很有能夠會放在一路,所以靠簡略對象來處理cache line後還對全部數組修正的方法貌似不靠譜,由於int 是4字節,假如在64形式下,這個年夜小是24字節(有4byte補齊),指針緊縮開啟是16byte;也就是每次cpu可以看齊3-4個對象,若何讓CPUcache了,然則又不影響體系的QPI,別想經由過程分隔對象來完成,由於GC進程內存拷貝進程極可能會拷貝到一路,最好的方法是補齊,固然有點糟蹋內存,然則這是最靠譜的辦法,就是將對象補齊到64字節,上述若未開啟指針緊縮有24byte,此時還有40個字節,只須要在對象外部增長5個long便可。
class InputInteger {
public int value;
private long a1,a2,a3,a4,a5;
}
呵呵,這個方法很土,不外很管用,有些時刻,Jvm編譯的時刻發明這幾個參數啥都沒做,就直接給你干失落了,優化有效,土方法加土方法就是在一個辦法體外面簡略對這5個參數做一個操作(都用上),然則這個辦法永久不挪用它便可。
8、在CPU這個級別有些時刻就未必能先做盡可能先做的事理為王者了,相似獲得鎖這類操作,在AtomicIntegerFieldUpdater的操作,假如挪用getAndSet(true)在單線程下你會發明跑得還蠻快,在多核CPU下就開端變慢,為何下面說得很清晰了,由於getAndSet外面是修正後比較,先改了再說,QPI會很高,所以這個時刻,先做get操作,再修正才是比擬好的做法;還有就是獲得一次,假如獲得不到,就妥協一下,讓其他的線程去做其他的工作;
9、CPU有些時刻為懂得決某些CPU忙和不忙碌的成績,會有許多算法來處理,如NUMA是個中一種計劃,不外豈論哪一種架構都在必定場景下比擬有效,對有一切場景未必有用;有隊列鎖機制來完成對CPU狀況治理,不外這又存在了cache line的成績,由於狀況都是常常轉變的,各類運用法式的內核為了合營CPU也會出一些算法來做,使得CPU可以加倍有用的應用起來,如CLH隊列等。
有關這方面的細節會許多如用通俗變量輪回疊加和用volatile類型的做和Atomic*系列的來做,完整是紛歧樣的;多維度數組輪回,依照分歧緯度向後順序來輪回也是紛歧樣的,細節上點許多,明確為何就在現實優化進程中有靈感了;鎖的細節說太細很暈,在體系底層的級別,一直有一些輕量級的原子操作,豈論誰說他的代碼是不須要加鎖的,最細的可以細到CPU在每一個剎時只能履行一條指令那末簡略,多焦點CPU在總線級別也會有同享區來掌握一些內容,有讀級別、寫級別、內存級別等,在分歧的場景下使得鎖的粒度盡可能下降,那末體系的機能不問可知,很正常的成果。