因為網上已經太多的關於HashMap的相關文章了,為了避免大量重復,又由於網上關於java8的HashMap的相關文章比較少,至少我沒有找到比較詳細的。所以才有了本文。
本文主要的內容:
1.HashMap的數據結構,以及java 8的新特征
2.HashMap的put方法的實現原理
3.resize()到底做了什麼事情,它是怎麼擴容的
4.HashMap節點紅黑樹存儲
HashMap的數據結構,以及java 8的新特征
下面來看下HashMap的主要兩種存儲方式是示意圖(圖片來自網絡):
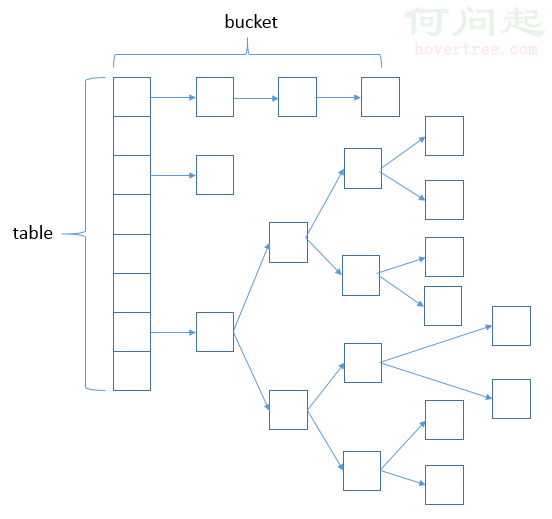
這就是java8的HashMap的數據結構,跟之前版本不一樣的是當table達到一定的閥值時,bucket就會由鏈表轉換為紅黑樹的方式進行存儲,下面會做具體的源碼分析。
HashMap的put方法實現原理
下面我們來看下關於put的方法,hashMap的Capacity的默認值為16,負載因子的默認值為0.75
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//table為空就創建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//確定插入table的位置,算法是(n - 1) & hash
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//在table的i位置發生碰撞,有兩種情況,1、key值是一樣的,替換value值,
//2、key值不一樣的有兩種處理方式:2.1、存儲在i位置的鏈表;2.2、存儲在紅黑樹中
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//2.2
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//2.1
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//超過了鏈表的設置長度8就擴容
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果e為空就替換舊的oldValue值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//threshold=newThr:(int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
//默認0.75*16,大於threshold值就擴容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
因為已經做了注釋了具體請看注釋,所以大部分細節就不多說了,下面說說hash的算法和尋址的算法
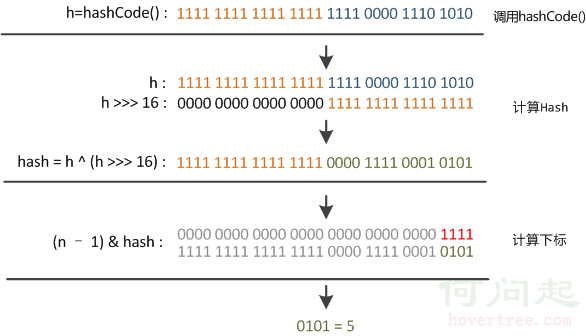
首先計算hash值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
具體的計算過程用如下圖表示,在設計hash函數時,因為目前的table長度2的N次方,而計算下標的時候,使用&位操作,而非%求余:
請看putVal代碼27/28行,當桶bucket大於TREEIFY_THRESHOLD(8)值時就執行treeifyBin,如果是之前java7之前的代碼的話是要進行擴容的,但是java8可能會把這個bucket的鏈表上的數據轉化為紅黑樹
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//當tab.length<MIN_TREEIFY_CAPACITY(64)是還是進行resize
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
//存儲在紅黑樹
hd.treeify(tab);
}
}resize到底做了什麼事情,它是怎麼擴容的
我們先看下resize這個方法吧,這段代碼後面會講到24行的treeify方法,也是本文的重點紅黑樹的存儲,以為這個方法的實現方式還是有別與java7的,桶中存在一個鏈表,需要將鏈表重新整理到新表當中,因為newCap是oldCap的兩倍所以原節點的索引值要麼和原來一樣,要麼就是原(索引+oldCap)和JDK 1.7中實現不同這裡不存在rehash
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//分別記錄頭和尾的節點
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
//把節點移動新的位置j+oldCap,這種情況不適用與鏈表的節點數大於8的情況
//鏈表節點大於8的情況會轉換為紅黑樹存儲
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap節點紅黑樹存儲
好了終於到treeify了,大部分內容都在注解中
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
//遍歷root,把節點x插入到紅黑樹中,執行先插入,然後進行紅黑樹修正
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);//比較k和pk的值,用於判斷是遍歷左子樹還是右子樹
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//修正紅黑樹
root = balanceInsertion(root, x);
//退出循環
break;
}
}
}
}
moveRootToFront(tab, root);
}上面主要做的是紅黑樹的insert,我們知道紅黑樹insert後是需要修復的,為了保持紅黑樹的平衡,我們來看下紅黑樹平衡的幾條性質:
1.節點是紅色或黑色。
2.根是黑色。
3.所有葉子都是黑色(葉子是NIL節點)。
4.每個紅色節點必須有兩個黑色的子節點。(從每個葉子到根的所有路徑上不能有兩個連續的紅色節點。)
5.從任一節點到其每個葉子的所有簡單路徑都包含相同數目的黑色節點。
當insert一個節點之後為了達到平衡,我們可能需要對節點進行旋轉和顏色翻轉(上面的balanceInsertion方法)。具體操作這裡就不細講了,對紅黑樹的修復還不是很清楚的同學可以去參考下數據結構與算法分析這本書,我將在後面寫一篇關於紅黑樹關於java實現的相關文章。
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
//插入的節點必須是紅色的,除非是根節點
x.red = true;
//遍歷到x節點為黑色,整個過程是一個上濾的過程
//xp=x.parent;xpp=xp.parent;xppl=xpp.left;xppr=xpp.right;
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
//如果xp的黑色就直接完成,最簡單的情況
else if (!xp.red || (xpp = xp.parent) == null)
return root;
//如果x的父節點是x父節點的左節點
if (xp == (xppl = xpp.left)) {
//x的父親節點的兄弟是紅色的(需要顏色翻轉)
if ((xppr = xpp.right) != null && xppr.red) {
//x父親節點的兄弟節點置成黑色
xppr.red = false;
//父幾點和其兄弟節點一樣是黑色
xp.red = false;
//祖父節點置成紅色
xpp.red = true;
//然後上濾(就是不斷的重復上面的操作)
x = xpp;
}
else {
//如果x是xp的右節點整個要進行兩次旋轉,先左旋轉再右旋轉
if (x == xp.right) {
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
//以左節點鏡像對稱就不做具體分析了
else {
if (xppl != null && xppl.red) {
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {
if (x == xp.left) {
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
參考
http://yikun.github.io/2015/04/01/Java-HashMap%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E7%8E%B0/
耗子哥的這篇文章詳細記錄了HashMap的死循環原因,這篇文章比較形象的描述了hashmap的rehash的過程
http://coolshell.cn/articles/9606.html#more-9606
http://www.importnew.com/18604.html
http://blog.csdn.net/lyg468088/article/details/49464121