我們都知道,HashMap在並發環境下使用可能出現問題,但是具體表現,以及為什麼出現並發問題,
可能並不是所有人都了解,這篇文章記錄一下HashMap在多線程環境下可能出現的問題以及如何避免。
在分析HashMap的並發問題前,先簡單了解HashMap的put和get基本操作是如何實現的。
大家知道HashMap內部實現是通過拉鏈法解決哈希沖突的,也就是通過鏈表的結構保存散列到同一數組位置的兩個值,
put操作主要是判空,對key的hashcode執行一次HashMap自己的哈希函數,得到bucketindex位置,還有對重復key的覆蓋操作。
對照源碼分析一下具體的put操作是如何完成的:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
//得到key的hashcode,同時再做一次hash操作
int hash = hash(key.hashCode());
//對數組長度取余,決定下標位置
int i = indexFor(hash, table.length);
/**
* 首先找到數組下標處的鏈表結點,
* 判斷key對一個的hash值是否已經存在,如果存在將其替換為新的value
*/
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
涉及到的幾個方法:
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
數據put完成以後,就是如何get,我們看一下get函數中的操作:
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
/**
* 先定位到數組元素,再遍歷該元素處的鏈表
* 判斷的條件是key的hash值相同,並且鏈表的存儲的key值和傳入的key值相同
*/
for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
看一下鏈表的結點數據結構,保存了四個字段,包括key,value,key對應的hash值以及鏈表的下一個節點:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;//Key-value結構的key
V value;//存儲值
Entry<K,V> next;//指向下一個鏈表節點
final int hash;//哈希值
}
哈希表結構是結合了數組和鏈表的優點,在最好情況下,查找和插入都維持了一個較小的時間復雜度O(1),
不過結合HashMap的實現,考慮下面的情況,如果內部Entry[] tablet的容量很小,或者直接極端化為table長度為1的場景,那麼全部的數據元素都會產生碰撞,
這時候的哈希表成為一條單鏈表,查找和添加的時間復雜度變為O(N),失去了哈希表的意義。
所以哈希表的操作中,內部數組的大小非常重要,必須保持一個平衡的數字,使得哈希碰撞不會太頻繁,同時占用空間不會過大。
這就需要在哈希表使用的過程中不斷的對table容量進行調整,看一下put操作中的addEntry()方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
這裡面resize的過程,就是再散列調整table大小的過程,默認是當前table容量的兩倍。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
//初始化一個大小為oldTable容量兩倍的新數組newTable
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
關鍵的一步操作是transfer(newTable),這個操作會把當前Entry[] table數組的全部元素轉移到新的table中,
這個transfer的過程在並發環境下會發生錯誤,導致數組鏈表中的鏈表形成循環鏈表,在後面的get操作時e = e.next操作無限循環,Infinite Loop出現。
下面具體分析HashMap的並發問題是如何出現的。
HashMap在並發環境下多線程put後可能導致get死循環,具體表現為CPU使用率100%,
看一下transfer的過程:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
//假設第一個線程執行到這裡因為某種原因掛起
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
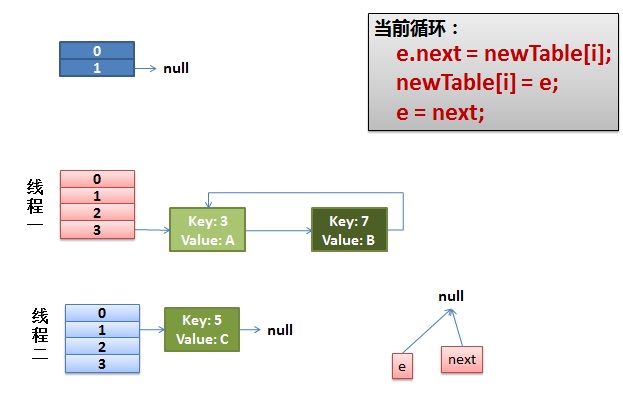
這裡對並發情況的描述起來比較繞,先偷個懶,直接引用酷殼陳皓的博文:
並發下的Rehash
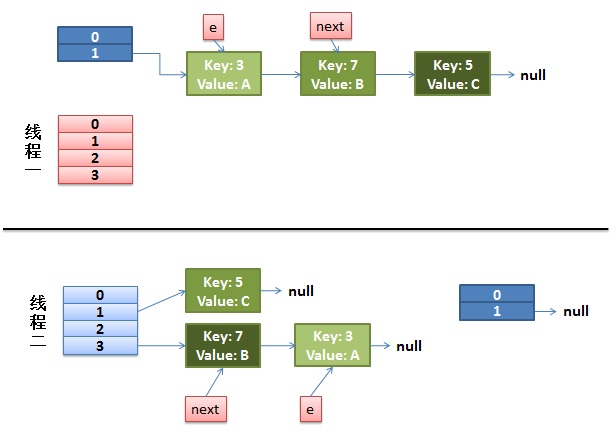
1)假設我們有兩個線程。我用紅色和淺藍色標注了一下。
我們再回頭看一下我們的 transfer代碼中的這個細節:
do{Entry<K,V> next = e.next;// <--假設線程一執行到這裡就被調度掛起了inti = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}while(e !=null);而我們的線程二執行完成了。於是我們有下面的這個樣子。
注意,因為Thread1的 e 指向了key(3),而next指向了key(7),其在線程二rehash後,指向了線程二重組後的鏈表。我們可以看到鏈表的順序被反轉後。
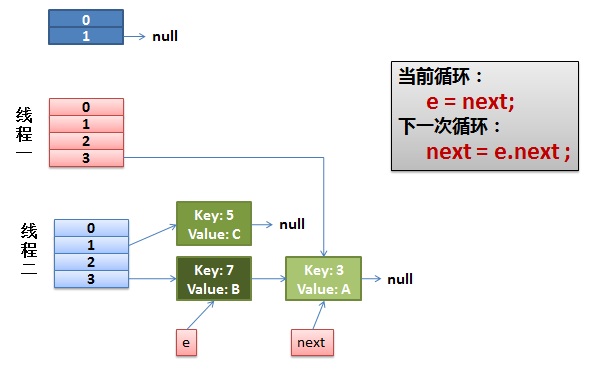
2)線程一被調度回來執行。
- 先是執行 newTalbe[i] = e;
- 然後是e = next,導致了e指向了key(7),
- 而下一次循環的next = e.next導致了next指向了key(3)
3)一切安好。
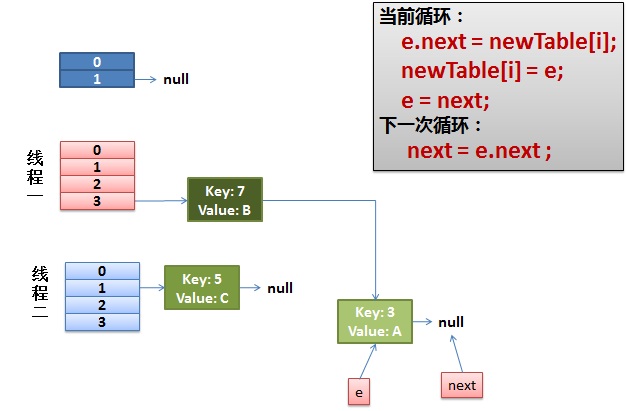
線程一接著工作。把key(7)摘下來,放到newTable[i]的第一個,然後把e和next往下移。
4)環形鏈接出現。
e.next = newTable[i] 導致 key(3).next 指向了 key(7)
注意:此時的key(7).next 已經指向了key(3), 環形鏈表就這樣出現了。
於是,當我們的線程一調用到,HashTable.get(11)時,悲劇就出現了——Infinite Loop。
針對上面的分析模擬這個例子:
public class MapThread extends Thread{
/**
* 類的靜態變量是各個實例共享的,因此並發的執行此線程一直在操作這兩個變量
* 選擇AtomicInteger避免可能的int++並發問題
*/
private static AtomicInteger ai = new AtomicInteger(0);
//初始化一個table長度為1的哈希表
private static HashMap<Integer, Integer> map = new HashMap<Integer, Integer>(1);
//如果使用ConcurrentHashMap,不會出現類似的問題
// private static ConcurrentHashMap<Integer, Integer> map = new ConcurrentHashMap<Integer, Integer>(1);
public void run()
{
while (ai.get() < 100000)
{ //不斷自增
map.put(ai.get(), ai.get());
ai.incrementAndGet();
}
System.out.println(Thread.currentThread().getName()+"線程即將結束");
}
}
測試一下:
public static void main(String[] args){
MapThread t0 = new MapThread();
MapThread t1 = new MapThread();
MapThread t2 = new MapThread();
MapThread t3 = new MapThread();
MapThread t4 = new MapThread();
MapThread t5 = new MapThread();
MapThread t6 = new MapThread();
MapThread t7 = new MapThread();
MapThread t8 = new MapThread();
MapThread t9 = new MapThread();
t0.start();
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
t7.start();
t8.start();
t9.start();
}
注意並發問題並不是一定會產生,可以多執行幾次,
我試驗了上面的代碼很容易產生無限循環,控制台不能終止,有線程始終在執行中,
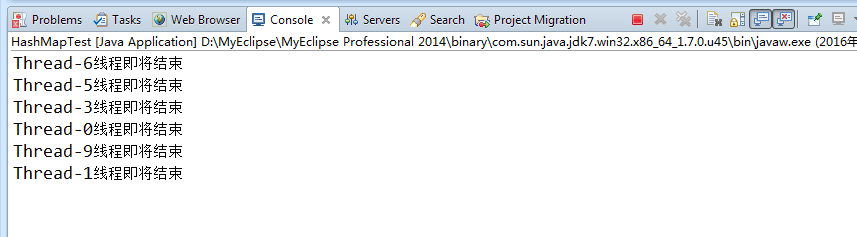
這是一個死循環的控制台截圖,可以看到六個線程順利完成了put工作後銷毀,還有四個線程沒有輸出,卡在了put階段,感興趣的可以斷點進去看一下:
如果換用ConcurrentHashMap就不會出現類似的問題。
HashMap另外一個並發可能出現的問題是,可能產生元素丟失的現象。
考慮在多線程下put操作時,執行addEntry(hash, key, value, i),如果有產生哈希碰撞,
導致兩個線程得到同樣的bucketIndex去存儲,就可能會出現覆蓋丟失的情況:
void addEntry(int hash, K key, V value, int bucketIndex) {
//多個線程操作數組的同一個位置
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
參考 疫苗:Java HashMap的死循環