繼承線程與實現Runnable的差異?為什麼那麼多人都采取第二種方式?
因為第二種方式更符合面向對象的思維方式。創建一個線程,線程要運行代碼,而運行的代碼都封裝到一個獨立的對象中去。一個叫線程,一個叫線程運行的代碼,這是兩個東西。兩個東西一組合,就表現出了面向對象的思維。如果兩個線程實現數據共享,必須用Runnable的方式。
查看Thread類的run()方法的源代碼,可以看到其實這兩種方式都是在調用Thread對象的run方法,如果Thread類的run方法沒有被覆蓋,並且為該Thread對象設置了一個Runnable對象,該run方法會調用Runnable對象的run方法。
問題:如果在Thread子類覆蓋的run方法中編寫了運行代碼,也為Thread子類對象傳遞了一個Runnable對象,那麼,線程運行時的執行代碼是子類的run方法的代碼?還是Runnable對象的run方法的代碼?子類的run方法。
示例代碼
1 new Thread(new Runnable() {
2 public void run() {
3 while (true) {
4 System.out.println("run:runnable");
5 }
6 }
7 }) {
8 public void run() {
9 while (true) {
10 try {
11 Thread.sleep(1000);
12 } catch (Exception e) {
13 }
14 System.out.println("run:thread");
15 }
16 }
17 }.start();
該線程會運行重寫的Thread中的run方法,而不是Runnable中的run方法,因為在傳統的Thread的run方法是:
1 public void run() {
2 if (target != null) {
3 target.run();
4 }
5 }
如果想要運行Runnable中的run方法,必須在Thread中調用,但是此時我重寫了Thread中的run方法,導致if (target != null) { target.run(); }不存在,所以調用不了Runnable中的run方法。
注意:多線程的執行,會提高程序的運行效率嗎?為什麼會有多線程下載?
不會,有時候還會降低程序的運行效率。因為CPU只有一個,在CPU上下文切換的時候,可能還會耽誤時間。
多線程下載:其實你的機器沒有變快,而是你搶了服務器的帶寬。如果你一個人下載,服務器給你提供的是20K的話,那麼10個人的話,服務器提供的就是200K。這個時候你搶走200k,所以感覺變快了。
Timer:一種工具,線程用其安排以後在後台線程中執行的任務。可安排任務執行一次,或者定期重復執行。
scheduleAtFixedRate(TimerTask task, Date firstTime, long period):
安排指定的任務在指定的時間開始進行重復的固定速率執行。
schedule(TimerTask task, long delay, long period): 安排指定的任務從指定的延遲後開始進行重復的固定延遲執行。
作業調度框架 Quartz(專門用來處理時間時間的工具)。你能夠用它來為執行一個作業而創建簡單的或復雜的調度。{ http://www.oschina.net/p/quartz}
問題:每天早晨3點來送報紙。
問題:每個星期周一到周五上班,周六道周日不上班。
示例代碼:(間隔不同時間,執行不同事件)
1 package com.chunjiangchao.thread;
2
3 import java.util.Timer;
4 import java.util.TimerTask;
5 /**
6 * 重復執行某項任務,但是時間間隔性不同是2,4這種狀態
7 * @author chunjiangchao
8 *
9 */
10 public class TimerDemo02 {
11
12 private static long count = 1;
13 public static void main(String[] args) {
14 Timer timer = new Timer();
15 timer.schedule(new Task(), 1000);
16 /*
17 測試打印結果如下:
18 執行任務,當前時間為:1460613231
19 執行任務,當前時間為:1460613235
20 執行任務,當前時間為:1460613237
21 執行任務,當前時間為:1460613241
22 */
23
24 new Thread(new Runnable() {
25 public void run() {
26 while (true) {
27 System.out.println("run:runnable");
28 }
29 }
30 }) {
31 public void run() {
32 while (true) {
33 try {
34 Thread.sleep(1000);
35 } catch (Exception e) {
36 }
37 System.out.println("run:thread");
38 }
39 }
40 }.start();
41
42
43 }
44
45 static class Task extends TimerTask{
46
47 @Override
48 public void run() {
49 System.out.println("執行任務,當前時間為:"+System.currentTimeMillis()/1000);
50 new Timer().schedule(new Task(), 2000*(1+count%2));
51 count++;
52 }
53
54 }
55
56 }
本道例題:關鍵在於說明:要想實現線程間的互斥,線程數量必須達到兩個或者兩個以上,同時,訪問資源的時候要用同一把鎖(這個是必須的)。如果兩個線程都訪問不同的同步代碼塊,而且它們的鎖對象都不相同,那麼這些線程就沒有達到同步的目的。
示例代碼:(訪問同一個資源對象,但是鎖對象不同,同樣沒有達到同步的目的)

在設計的時候,最好將相關的代碼封裝到一個類中,不僅可以方便處理,還可以實現內部的高耦合。
問題示例圖
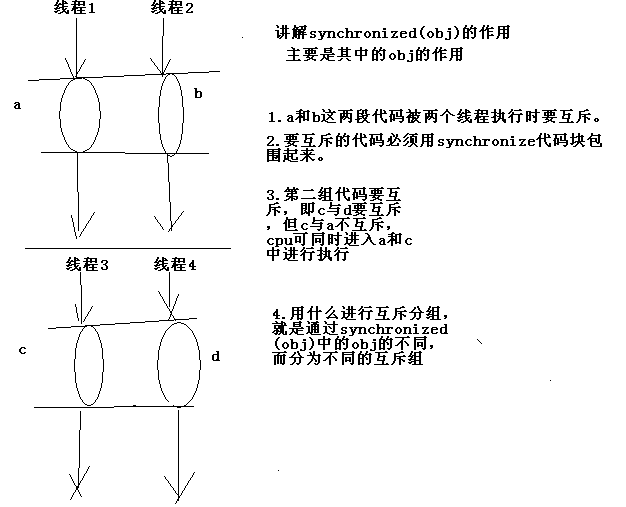
經驗總結:要用到共同數據(包括同步鎖)或共同算法的若干個方法應該歸在同一個類身上,這種設計正好體現了高類聚和程序的健壯性。
同步通信,互斥的問題不是寫在線程上面的,而是直接寫在資源裡面的,線程是直接拿過來使用就可以了。好處就是,以後我的類,交給任何一個線程去訪問,它天然就同步了,不需要考慮線程同步的問題。如果是在線程上面寫,明天又有第三個線程來調用我,還得在第三個線程上面寫互斥寫同步。(全部在資源類的內部寫,而不是在線程的代碼上面去寫)
示例代碼:(子線程循環10次,接著主線程循環100,接著又回到子線程循環10次,接著再回到主線程又循環100, 如此循環50次,請寫出程序。)
1 package com.chunjiangchao.thread;
2
3 public class TraditionalThreadCommunication {
4 /**
5 * 經驗:涉及到線程互斥共享,應該想到將同步方法寫在資源裡面,而不是寫在線程代碼塊中 在資源中判斷標記的時候,最好用while語句
6 */
7 public static void main(String[] args) {
8 final Output output = new Output();
9 new Thread(new Runnable() {
10 public void run() {
11 for (int i = 0; i < 50; i++) {
12 output.sub(10);
13 }
14 }
15 }).start();
16 for (int i = 0; i < 50; i++) {
17 output.main(i);
18 }
19 }
20 }
21
22 class Output {
23 private boolean flag = true;
24
25 public synchronized void sub(int i) {
26 while (!flag) {// 用while比用if更加健壯,原因是即使線程被喚醒了,也判斷一下是不是真的該它執行了
27 // 防止偽喚醒的事件發生。
28 try {
29 this.wait();
30 } catch (InterruptedException e) {
31 }
32 }
33 for (int j = 0; j < 10; j++) {
34 System.out.println(i + "子線程運行" + j);
35 }
36 flag = false;// 記得要改變一下標記的狀態
37 this.notify();// 最後要喚醒其他要使用該鎖的線程
38 }
39
40 public synchronized void main(int i) {
41 while (flag) {
42 try {
43 this.wait();
44 } catch (InterruptedException e) {
45 }
46 }
47 for (int j = 0; j < 100; j++) {
48 System.out.println(i + "主線程運行" + j);
49 }
50 flag = true;
51 this.notify();
52 }
53 }
線程范圍內的數據共享:不管是A模塊,還B模塊,如果他們在同一個線程上運行,那麼他們操作的數據應該是相同。而不應該是不管A模塊和B模塊在哪個線程上面運行他們的數據在每個線程中的數據是一樣的。(應該是各自線程上的數據是獨立的)
線程間的事務處理:
如圖:
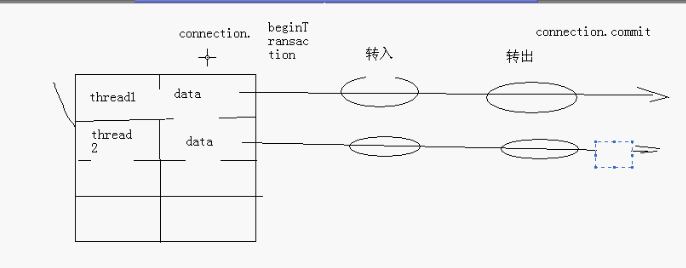
不能出現這樣的情況:thread1轉入的data,還沒有來得及操作。CPU時間片轉入到thread2,該thread2來執行,轉入、轉出,最後直接提交事務。導致thread1的數據出現錯誤。
線程范圍內的變量有什麼用?
我這件事務在線程范圍內搞定,不要去影響別的線程的事務。但是我這個線程內,幾個模塊之間是獨立的,這幾個模塊又要共享同一個對象。它們既要共享又要獨立,在線程內共享,在線程外獨立。【對於相同的程序代碼,多個模塊在同一個線程中運行時要共享一份數據,而在另外線程中運行時又共享另外一份數據。】
示例代碼(不同線程之間共享同一個Map對象,但是Map中的每個元素表示的是不同線程的數據)
1 package com.chunjiangchao.thread;
2
3 import java.util.HashMap;
4 import java.util.Map;
5 import java.util.Random;
6
7 /**
8 * 線程范圍內共享數據
9 * @author chunjiangchao
10 *
11 */
12 public class ThreadScopeShareDataDemo {
13 //所有線程共享的數據是datas,但是datas中的每個元素key是Thread,每個元素針對每個線程來說是獨立的,value代表不同線程處理的數據
14 private static Map<Thread,Integer> datas = new HashMap<Thread,Integer>();
15 public static void main(String[] args) {
16 for(int i=0;i<2;i++){
17 new Thread(new Runnable() {
18
19 @Override
20 public void run() {
21 int nextInt = new Random().nextInt();
22 datas.put(Thread.currentThread(), nextInt);
23 ///A模塊與B模塊是獨立的,但是A與B共享當前當前線程中的數據
24 new ModuleA().getThreadData();
25 new ModuleB().getThreadData();
26 }
27 }).start();
28 }
29 /*
30 打印的結果為
31 Thread-1的ModuleA獲取的變量為:-918049793
32 Thread-0的ModuleA獲取的變量為:-1424853148
33 Thread-0的ModuleB獲取的變量為:-1424853148
34 Thread-1的ModuleB獲取的變量為:-918049793
35
36 */
37 }
38 static class ModuleA{
39 public void getThreadData(){
40 System.out.println(Thread.currentThread().getName()+"的ModuleA獲取的變量為:"+datas.get(Thread.currentThread()));
41 }
42 }
43 static class ModuleB{
44 public void getThreadData(){
45 System.out.println(Thread.currentThread().getName()+"的ModuleB獲取的變量為:"+datas.get(Thread.currentThread()));
46 }
47 }
48
49 }
ThreadLocal就相當於一個Map。
一個ThreadLocal代表一個變量,故其中只能放一個數據,你有兩個變量都要線程范圍內共享,則要定義兩個ThreadLocal對象,如果有一個一百個變量要線程共享?那麼就應該定義一個對象來裝著一百個變量,然後在ThreadLocal中存儲這一個對象。
問題:怎麼在線程結束的時候得到通知?提示:監聽虛擬機結束。
最重要的一點,就是裡面涉及到的設計方法。