1.1 Oracle的安裝
1.1.1 在WindowsXP、Win7下安裝
第一:解壓win32_11gR2_database_1of2、win32_11gR2_database_2of2,生成detabase目錄
第二:安裝oracle
A、點擊setup圖標即可,注意:安裝目錄不要含有中文
B、在彈出的第一個界面中取消更新選擇項,點擊下一步
C、在彈出的警告框中選擇是
D、選擇創建和配置數據庫選項,下一步
E、選擇桌面類安裝,點擊下一步
F、彈出的窗口中輸入全局數據庫名:orcl
輸入管理口令:bluedot
默認的管理員是:sys和system
G、點完成,開始安裝數據庫,出現進度條
H、口令管理
I、設置口令
J、完成安裝
1.2 Oracle的卸載:
1、 開始->設置->控制面板->管理工具->服務 停止所有Oracle服務。
2、 開始->程序->Oracle - OraHome81->Oracle Installation Products-> Universal Installer,單擊“卸載產品”-“全部展開”,選中除“OraDb11g_home1”外的全部目錄,刪除。
3、 運行regedit,選擇HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE,按del鍵刪除這個入口。
4、 運行regedit,選擇HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services,滾動這個列表,刪除所有Oracle入口(以oracle或OraWeb開頭的鍵)。
5、 運行refedit,HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Eventlog\Application,刪除所有Oracle入口。e
6、 刪除HKEY_CLASSES_ROOT目錄下所有以Ora、Oracle、Orcl或EnumOra為前綴的鍵。
7、 刪除HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Explorer\MenuOrder\Start Menu\Programs中所有以oracle開頭的鍵。
8、刪除HKEY_LOCAL_MACHINE\SOFTWARE\ODBC\ODBCINST.INI中除Microsoft ODBC for Oracle注冊表鍵以外的所有含有Oracle的鍵。
9、我的電腦–>屬性–>高級–>環境變量,刪除環境變量CLASSPATH和PATH中有關Oracle的設定。
10、從桌面上、STARTUP(啟動)組、程序菜單中,刪除所有有關Oracle的組和圖標。
11、刪除所有與Oracle相關的目錄(如果刪不掉,重啟計算機後再刪就可以了)包括:
1.C:\Program file\Oracle目錄。
2.ORACLE_BASE目錄(oracle的安裝目錄)。
3.C:\WINDOWS\system32\config\systemprofile\Oracle目錄。
4.C:\Users\Administrator\Oracle或C:\Documents and Settings\Administrator\Oracle目錄。
5.C:\WINDOWS下刪除以下文件ORACLE.INI、oradim73.INI、oradim80.INI、oraodbc.ini等等。
6.C:\WINDOWS下的WIN.INI文件中若有[ORACLE]的標記段,刪除該段。
12、如有必要,刪除所有Oracle相關的ODBC的DSN
13、到事件查看器中,刪除Oracle相關的日志 說明: 如果有個別DLL文件無法刪除的情況,則不用理會,重新啟動,開始新的安裝,安裝時,選擇一個新的目錄,則,安裝完畢並重新啟動後,老的目錄及文件就可以刪除掉了。
2.1 創建用戶
注:創建用戶只能在管理員下完成
CREATE USER 用戶名 IDENTIFIED BY 密碼。
|-CREATE USER demo IDENTIFIED BY 123456;
2.2 用戶分類
|-管理員和普通用戶
|-管理員
|-超級管理員:sys/bluedot
|-管理員:system/bluedot
|-普通用戶:scott/tiger
hr/hr
|–常見角色:sysdba、sysoper
2.3 用戶登錄
2.3.1 在命令行窗口登錄[c/s]
步驟:
運行 sqlplus /nolog
conn demo/123456
2.3.2 另外的一種登錄方式【B/S】
輸入網址—-https://localhost:1158/em
輸入用戶名密碼進入主界面
2.4 修改用戶密碼
注:修改密碼必須要在級別高的用戶下進行修改
ALTER USER 用戶名 IDENTIFIED BY 密碼;
conn sys/bluedot as sysdba
ALTER USER demo IDENTIFIED BY 654321;
2.5 查詢用戶
2.5.1查看用戶信息
1、SELECT * FROM DBA_USERS;——–查看所有用戶的詳細信息
2、SELECT * FROM ALL_USERS;——-查看所有用戶簡要信息
3、SELECT * FROM USER_USERS;————查看當前用戶的所用信息
2.5.2 查看用戶或角色系統權限(直接賦值給用戶或角色的系統權限)
SELECT * FROM DBA_SYS_PRIVS;———-全部
SELECT * FROM USER_SYS_PRIVS; ———當前用戶
2.5.3 查看角色(登錄用戶擁有的角色)所包含的的權限
SELECT * FROM ROLE_SYS_PRIVS;
2.5.4 查看用戶對象權限
SELECT * FROM DBA_TAB_PRIVS;
SELECT * FROM ALL_TAB_PRIVS;
SELECT * FROM USER_TAB_PRIVS;
2.5.5 查看所有角色
SELECT * FROM DBA_ROLES;
SELECT * FROM DBA_ROLE_PRIVS;
SELECT * FROM USER_ROLE_PRIVS;
2.5.6 查看哪些用戶有sysdba或sysoper系統權限(查詢時需要相應權限)
SELECT * FROM V$PWFILE_USERS;
2.5.7 查看Oracle提供的系統權限
SELECT name FROM SYS.SYSTEM_PRIVSILEGE_MAP;
2.6 密碼失效
提示用戶第一次連接的時候需要修改密碼,讓用戶的密碼到期
|- ALTER USER 用戶名 PASSWORD expire ;
2.7 授權
GRANT 權限/角色 TO 用戶
給 demo 用戶以創建 session 的權限:GRANT create session TO demo;
角色:————-角色就是一堆權限的集合
Create role myrole;
Grant create table to myrole;
Drop role myrole; 刪除角色
1.CONNECT, RESOURCE, DBA
這些預定義角色主要是為了向後兼容。其主要是用於數據庫管理。oracle建議用戶自己設計數據庫管理和安全的權限規劃,而不要簡單的使用這些預定角色。將來的版本中這些角色可能不會作為預定義角色。
2.DELETE_CATALOG_ROLE, EXECUTE_CATALOG_ROLE, SELECT_CATALOG_ROLE 這些角色主要用於訪問數據字典視圖和包。
3.EXP_FULL_DATABASE, IMP_FULL_DATABASE 這兩個角色用於數據導入導出工具的使用。
GRANT 權限(select、update、insert、delete) ON schema.table TO 用戶
|- GRANT select ON scott.emp TO test ;
|- Grant all on scott.emp to test; –將表相關的所有權限付給 test
|- Grant update(ename) on emp to test; 可以控制到列(還有 insert)
2.8 收權
REVOKE 權限/角色 ON schema.table FROM 用戶
|- REVOKE select ON scott.emp FROM test ;
2.9 鎖住一個用戶
ALTER USER 用戶名 ACCOUNT LOCK|UNLOCK
|- ALTER USER test ACCOUNT LOCK ;
|- ALTER USER test ACCOUNT UNLOCK ;
2.10 刪除用戶
|-DROP USER 用戶名;
|-Drop user demo;
如果該用戶下面已經存在表等一些數據庫對象。則必須用級聯刪除
|-DROP USER 用戶名 CASCADE;
|-Drop user demo cascade;
備注:幫助
help index
help conn ——–顯示具體的
eidt—————進入編輯文檔
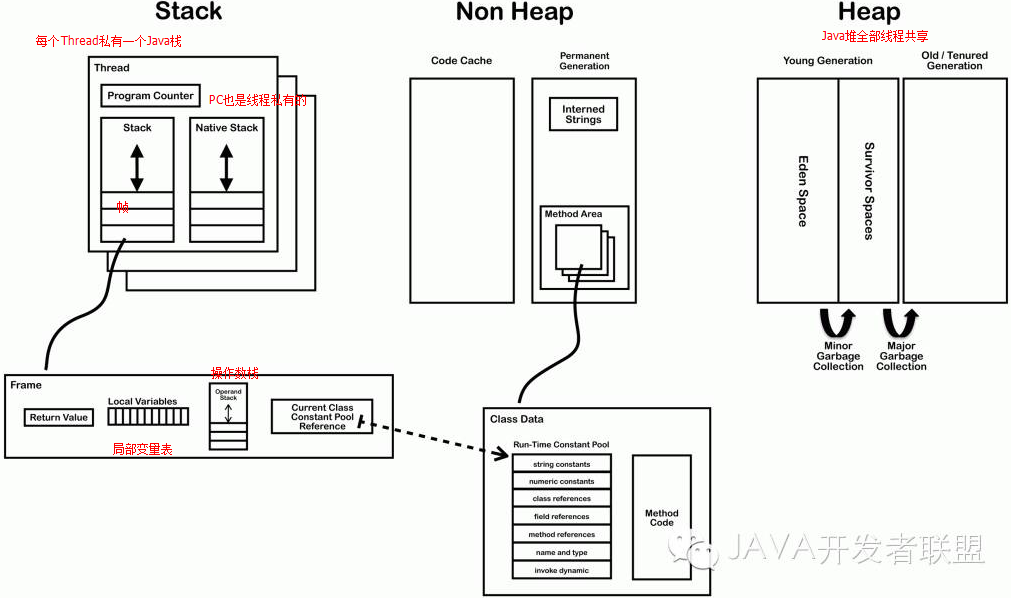
3.1 Oracle數據庫的整體架構 (DBA)
┌──────────────────────────────┐
┌────┐ │ Instance │
│ User │ │ ┌──────────────────────────┐ │
│ process│ │ │ ┌────────┐ SGA │ │
└────┘ │ │ │ Shared Pool │ │ │
↓ │ │ │ ┌─────┐ │ ┌────┐ ┌────┐ │ │
↓ │ │ │ │Library │ │ │Database│ │ Redo │ │ │
┌────┐ │ │ │ │ Cache │ │ │Buffer │ │ Log │ │ │
│ Server │ │ │ │ └─────┘ │ │Cache │ │ Buffer │ │ │
│process │ │ │ │ ┌─────┐ │ │ │ │ │ │ │
└────┘ │ │ │ │Data Dict │ │ └────┘ └────┘ │ │
↓ │ │ │ │ Cache │ │ │ │
→→→→→→│ │ │ └─────┘ │ │ │
│ │ └────────┘ │ │
│ └──────────────────────────┘ │
│ ┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌───┐│
│ │PMON│ │SNON│ │DBWR│ │LGWR│ │CHPT│ │OTHERS││
│ └──┘ └──┘ └──┘ └──┘ └──┘ └───┘│
└──────────────────────────────┘
↑ ↓
┌─────┐ ┌───────────────────┐
│Parameter │ │┌───┐ ┌────┐ ┌────┐│
│ file │ ││Data │ │control │ │Redo Log││ ┌─────┐
└─────┘ ││files │ │ files │ │ files ││ │Archived │
┌─────┐ │└───┘ └────┘ └────┘│ │Log files │
│ Password │ │ Database │ └─────┘
│ file │ │ │
└─────┘ └───────────────────┘
由上圖可知,Oracle數據庫由實例和數據庫組成。
3.2 數據庫存儲結構
3.2.1 數據庫存儲結構
Oracle數據庫有物理結構和邏輯結構。數據庫的物理結構是數據庫中的操作系統文件的集合。數據庫的物理結構由數據文件、控制文件和重做日志文件組成。
1、數據文件:數據文件是數據的存儲倉庫。
2、重做日志文件:重做日志文件包含對數據庫所做的更改記錄,在發生故障時能夠恢復數據。重做日志按時間順序存儲應用於數據庫的一連串的變更向量。其中僅包含重建(重做)所有已完成工作的最少限度信息。如果數據文件受損,則可以將這些變更向量應用於數據文件備份來重做工作,將它恢復到發生故障的那一刻前的狀態。重做日志文件包含聯機重做日志文件(對於連續的數據庫操作時必須的)和歸檔日志文件(對於數據庫操作是可選的,但對於時間點恢復是必須的)。
3、控制文件:控制文件包含維護和驗證數據庫完整性的必要的信息。控制文件雖小,但作用非常大。它包含指向數據庫其余部分的指針:聯機重做日志文件和數據文件的位置,以及更新的歸檔日志文件的位置。它還存儲著維護數據庫完整性所需的信息。控制文件不過數MB,卻起著至關重要的作用。
除了三個必須的文件外數據庫還能有其它非必須的文件如:參數文件、口令文件及歸檔日志文件。
1、實例參數文件:當啟動oracle實例時,SGA結構會根據此參數文件的設置內置到內存,後台進程會據此啟動。
2、口令文件:用戶通過提交用戶名和口令來建立會話。Oracle根據存儲在數據字典的用戶定義對用戶名和口令進行驗證。
3、歸檔重做日志文件:當重做日志文件滿時將重做日志文件進行歸檔以便還原數據文件備份。
3.2.2 Oracle數據庫結構的16個要點(表空間–>段–>區–>塊)
1、一個數據文件只能歸到某一個表空間上,每個表空間可以含一個或多個數據文件。包括系統數據和用戶數據。
2、表空間是包括一個或多個數據文件的邏輯結構。用於存放數據庫表、索引、回滾段等對象的磁盤邏輯空間
3、數據庫文件是存放實際數據的物理文件。包括實例和數據庫。
4、數據文件可以在創建表空間時創建,也可以以增加的方式創建。
5、數據文件的大小一般與操作系統限制有關。
6、控制文件是Oracle的重要文件,主要存放數據文件、日志文件和數據庫的基本信息,一般在數據打開時訪問。
7、日志文件在數據庫活動時使用。
8、臨時表空間是用於存放排序段的磁間;臨時表空間由一個或多個臨時文件組成。
9、歸檔日志文件由歸檔進程將聯機日志文件讀出並寫到一個路徑上的文件。
10、Oracle實例由一組後台進程和內存結構組成。
11、Oracle實例的內存結構常叫系統全局區,簡稱SGA。
12、DBA_開頭的數據字典存放的字符信息都是大寫,而V
16、SGA分為數據緩沖區、共享池和日志緩沖區。
3.2.3 Oracle邏輯結構及表空間
1.ORACLE邏輯結構
ORACLE將數據邏輯地存放在表空間,物理地存放在數據文件中。
一個表空間任何一個時刻只能屬於一個數據庫。
數據庫——表空間——段——區——ORACLE塊
每個數據庫由一個或多個表空間組成,至少一個。
每個表空間基於一個或多個操作系統的數據文件,至少一個,一個操作系統的數據文件只能屬於一個表空間。一個表空間可以存放一個或多個段 segment。
每個段由一個或多個區段extent組成。
每個區段由一個或多個連續的ORACLE數據庫塊組成。
每個ORACLE數據塊由一個或多個連續的操作系統數據塊組成。
每個操作系統數據文件由一個或多個區段組成,由一個或多個操作系統數據塊組成。
⑴、表空間(tablespace)
表空間是數據庫中最大的邏輯單位,每一個表空間由一個或多個數據文件組成,一個數據文件只能與一個表空間相聯系。每一個數據庫都有一個SYSTEM表空間,該表空間是在數據庫創建或數據庫安裝時自動創建的,用於存儲系統的數據字典表,程序系統單元,過程函數,包和觸發器等,也可用於存儲用戶數據表,索引對象。表空間具有在線(online)和離線(offline)屬性,可以將除SYSTME以外的其他任何表空間置為離線。
⑵、段(segment)
數據庫的段可以分為四類:數據段、索引段、回退段和臨時段。
⑶、區
區是磁盤空間分配的最小單位。磁盤按區劃分,每次至少分配一個區。區存儲與段中,它由連續的數據塊組成。
⑷、數據塊
數據塊是數據庫中最小的數據組織單位與管理單位,是數據文件磁盤存儲空間單位,也是數據庫I/O的最小單位,數據塊大小由DB_BLOCK_SIZE參數決定,不同的Oracle版本DB_BLOCK_SIZE的默認值是不同的。
⑸、模式對象
模式對象是一種應用,包括:表、聚簇、視圖、索引序列生成器、同義詞、哈希、程序單元、數據庫鏈等。
最後,在來說一下Oracle的用戶、表空間和數據文件的關系:
一個用戶可以使用一個或多個表空間,一個表空間也可以供多個用戶使用。用戶和表空間沒有隸屬關系,表空間是一個用來管理數據存儲的邏輯概念,表空間只是和數據文件發生關系,數據文件是物理的,一個表空間可以包含多個數據文件,而一個數據文件只能隸屬一個表空間。
總結:解釋數據庫、表空間、數據文件、表、數據的最好辦法就是想象一個裝滿東西的櫃子。數據庫其實就是櫃子,櫃中的抽屜是表空間,抽屜中的文件夾是數據文件,文件夾中的紙是表,寫在紙上的信息就是數據。
2.兩類表空間:
系統SYSTEM表空間 非系統表空間 NON-SYSTEM表空間
系統SYSTEM表空間與數據庫一起建立,在系統表空間中有數據字典,系統還原段。可以存放用戶數據但是不建議。
非系統表空間NON-SYSTEM表空間 由管理員創建。可以方便管理。
3.3 實例的整體架構
實例整體架構圖:
┌──────────────────────────────┐
│ Instance │
│ ┌──────────────────────────┐ │
│ │ ┌────────┐ SGA │ │
│ │ │ Shared Pool │ │ │
│ │ │ ┌─────┐ │ ┌────┐ ┌────┐ │ │
│ │ │ │Library │ │ │Database│ │ Redo │ │ │
│ │ │ │ Cache │ │ │Buffer │ │ Log │ │ │
│ │ │ └─────┘ │ │Cache │ │ Buffer │ │ │
│ │ │ ┌─────┐ │ │ │ │ │ │ │
│ │ │ │Data Dict │ │ └────┘ └────┘ │ │
│ │ │ │ Cache │ │ │ │
│ │ │ └─────┘ │ │ │
│ │ └────────┘ │ │
│ └──────────────────────────┘ │
│ ┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌───┐│
│ │PMON│ │SNON│ │DBWR│ │LGWR│ │CHPT│ │OTHERS││
│ └──┘ └──┘ └──┘ └──┘ └──┘ └───┘│
└──────────────────────────────┘
實例由內存和後台進程組成,它暫時存在於RAM和CPU中。當關閉運行的實例時,實例將隨即消失。數據庫由磁盤上的物理文件組成,不管在運行狀態還是停止狀態,這些文件就一直存在。因此,實例的生命周期就是其在內存中存在的時間,可以啟動和停止。一旦創建數據庫,數據庫將永久存在。通俗的講數據庫就相當於平時安裝某個程序所生成的安裝目錄,而實例就是運行某個程序時所需要的進程及消耗的內存。
Oracle的內存架構包含兩部分系統全局區(SGA)和程序全局區(PGA)。
3.3.1 程序全局區
3.3.2 系統全局區
在操作系統提供的共享內存段實現的內存結構稱為系統全局區(SGA)。SGA在實例啟動時分配,在關閉時釋放。在一定范圍內,可以在實例運行時通過自動方式或響應DBA的指令,重新調整11g實例中的SGA及其中的組件的大小。
由上圖可知SGA至少包含三種數據結構:數據庫緩沖區緩存、日志緩沖區及共享池。還可能包括:大池、JAVA池。可以使用show sga,查看sga的狀態。
1、共享池
a.庫緩存是內存區域,按其已分析的格式存儲最近執行的代碼。分析就是將編程人員編寫的代碼轉換為可執行的代碼,這是oracle根據需要執行的一個過程。通過將代碼緩存在共享池,可以在不重新分析的情況下重用,極大地提高性能。
b.數據字典緩存有時稱為“行緩存”,它存儲最近使用的對象定義:表、索引、用戶和其他元數據定義的描述。
c.PL/SQL區:存儲的PL/SQL對象是過程、函數、打包的過程、打包的函數、對象類型定義和觸發器。
2、數據庫緩沖區
數據庫緩沖區是oracle用來執行SQL的工作區域。
3、日志緩沖區
日志緩沖區是小型的、用於短期存儲將寫入到磁盤上的重做日志的變更向量的臨時區域。日志緩沖區在啟動實例時分配,如果不重新啟動實例,就不能在隨後調整其大小。
後台進程有:
1、PMON—–程序監控器
2、SMON—–系統監控區
3、DBWR—–數據寫進程
4、LGWR—–日志寫進程
5、CKPT—–檢查點進程
6、Others—歸檔進程
SQL 全名是結構化查詢語言(Structured Query Language),是用於數據庫中的標准數據查詢語言,IBM 公司最早使用在其開發的數據庫系統中。1986 年 10 月,美國 ANSI 對 SQL 進行規范後,以此作為關系式數據庫管理系統的標准語言 (ANSI X3. 135-1986),1987 年得到國際標准組織的支持下成為國際標准。不過各種通行的數據庫系統在其實踐過程中都對 SQL 規范作了某些編改和擴充。所以,實際上不同數據庫系統之間的 SQL 語言不能完全相互通用
DML 語句(數據操作語言)Insert、Update、 Delete、Select
DDL 語句(數據定義語言)Create、Alter、 Drop
DCL 語句(數據控制語言)Grant、Revoke
TCL 事務控制語句 Commit 、Rollback、Savepoint
4.1 入門語句
普通用戶連接: Conn scott/tiger
超級管理員連接: Conn “sys/bluesot as sysdba”
Disconnect; 斷開連接————-disc
Save c:\1.txt 把 SQL 存到文件
Ed c:\1.txt 編輯 SQL 語句
@ c:\1.txt 運行 SQL 語句
Desc emp; 描述 Emp 結構
Select * from tab; 查看該用戶下的所有對象
Show user; 顯示當前用戶
如果在 sys 用戶下: 查詢 Select * from emp; 會報錯,原因:emp 是屬於 scott,所以此時必須使用:select * from scott.emp; / 運行上一條語句
4.2 DDL(數據定義語言)—-改變表結構
4.2.1 創建表
CREATE TABLE name (
tid VARCHAR2(5),
tname VARCHAR2(20),
tdate DATE,
as VARCHAR(7,2)
);
4.2.2 添加一列
ALTER TABLE 表名 ADD 列名 屬性;
ALTER TABLE student ADD age number(5);
4.2.4 刪除一列
ALTER TABLE table_name DROP COLUMN column_name;
ALTER TABLE student DROP COLUMN age;
4.2.5 修改一列的屬性
ALTER TABLE table_name MODIFY column_name type;
修改列名
ALTER TABLE table_name RENAME COLUMN columnname TO newname;
修改表名
ALTER TABLE table_name RENAME TO newname;
4.2.6 查看表中數據
DESC table_name;
4.2.7 刪除表
DROP TABLE table_name;
4.3 DCL(數據控制語言)
4.3.1 授權
GRANT 權限/角色 TO 用戶
給 demo 用戶以創建 session 的權限:GRANT create session TO demo;
角色:————-角色就是一堆權限的集合Create role myrole;
Grant create table to myrole;
Drop role myrole; 刪除角色
1.CONNECT, RESOURCE, DBA
這些預定義角色主要是為了向後兼容。其主要是用於數據庫管理。oracle建議用戶自己設計數據庫管理和安全的權限規劃,而不要簡單的使用這些預定角色。將來的版本中這些角色可能不會作為預定義角色。
2.DELETE_CATALOG_ROLE, EXECUTE_CATALOG_ROLE, SELECT_CATALOG_ROLE 這些角色主要用於訪問數據字典視圖和包。
3.EXP_FULL_DATABASE, IMP_FULL_DATABASE 這兩個角色用於數據導入導出工具的使用。
GRANT 權限(select、update、insert、delete) ON schema.table TO 用戶
|- GRANT select ON scott.emp TO test ;
|- Grant all on scott.emp to test; –將表相關的所有權限付給 test
|- Grant update(ename) on emp to test; 可以控制到列(還有 insert)
4.3.2 收權
REVOKE 權限/角色 ON schema.table FROM 用戶
|- REVOKE select ON scott.emp FROM test ;
4.4 TCL(事務控制語言)
事務的概念:事務是一系列對數據庫操作命令的集合,它有邊界(commit—commit)
事務的特征:A ——原子性—–不可分割性——-要麼執行要麼不執行
C——一致性—–rollback
I——-隔離性—–鎖的機制來保證的,鎖有粒度【表、行】———只讀、修改鎖
上鎖—SELECT * FROM DEMO1 FOR UPDATE;
釋放——commit、rollback
D —–持久性——-commit
系統時間—–sysdate
to_date(‘2013/11/09’,‘yyyy/mm/dd’)——–修改日期格式
轉換函數
1、To_char
select to_char(sysdate,’yyyy’) from dual;
select to_char(sysdate,’fmyyyy-mm-dd’) from dual;
select to_char(sal,’L999,999,999’) from emp;
select to_char(sysdate,’D’) from dual;//返回星期
2、To_number
select to_number(‘13’)+to_number(‘14’) from dual;
3、To_date
Select to_date(‘20090210’,‘yyyyMMdd’) from dual;
4.4.1 ROLLBACK
回滾——回滾到它上面的離它最近的commit
4.4.2 COMMIT
提交———–將數據緩沖區的數據提交到文件中去
4.4.3 SAVEPOINT——保存點
回滾點例子:
INSERT INTO DEMO1(TID,TNAME) VALUES(11,’AS’);
SAVEPOINT P1;
INSERT INTO DEMO1(TID,TNAME) VALUES(22,’AS’);
INSERT INTO DEMO1(TID,TNAME) VALUES(33,’AS’);
SAVEPOINT P2;
INSERT INTO DEMO1(TID,TNAME) VALUES(44,’AS’);
ROLLBACK TO P2;
COMMIT;
INSERT INTO DEMO1(TID,TNAME) VALUES(55,’AS’);
ROLLBACK TO P1;———-無法回滾
————查詢結果:11,22,33 由於55沒有提交所以沒有寫入文件
4.5 DML(數據操作語言)———改變數據結構
4.5.1 insert 語句
INSERT INTO table_name() VALUES();
INSERT INTO table_name VALUES();
插入空值時,用三種格式
1、INSERT INTO demo VALUES(”);
2、INSERT INTO demo VALUES(’ ‘);
3、INSERT INTO demo VALUES(NULL);
INSERT INTO demo(tid,tname,tdate) VALUES(1,null,sysdate);
INSERT INTO demo(tid,tname,tdate) VALUES(1,”,to_date(sysdate,’yyyy-mm-dd’));
INSERT INTO demo VALUES(1,”,to_date(‘2013/11/11’,’yyyy/mm/dd’));
注意:
1、字符串類型的字段值必須用單引號括起來,如:‘rain’;
2、如果字段值裡包含單引號需要進行字符串轉換,把它替換成兩個單引號‘’,如:‘”c”’ 數據庫中將插入‘c’;
3、字符串類型的字段值超過定義長度會報錯,最好在插入前進行長度校驗;
4、日期字段的字段值可以使用當前數據庫的系統時間sysdate,精確到秒;
5、INSERT時如果要用到從1開始自動增長的序列號,應該先建立一個序列號。
4.5.2 update 語句
UPDATE table_name SET column_name=值 WHERE 查詢條件
UPDATE demo SET tname=’張三’ WHERE tid=1;
COMMIT;——是更新生效
4.5.3 delete 語句—–不能回退
DELETE TABLE table_name;————–只能刪除數據,不能釋放空間
TRUNCATE TABLE table_name;—————刪除數據並釋放空間
DELETE TABLE demo;
TRUNCATE TABLE demo;
4.5.4 select 語句
A 、簡單的 Select 語句
SELECT * FROM table_name;
SELECT * FROM demo;
B、空值 is null
SELECT * FROM demo where tname is null;
結構: 執行順序
SELECT * 5
FROM table_name 1
WHERE —–分組前的條件 2
GROUP BY 3
HAVING —–分組後的條件 4
ORDER BY column_name ASC/DESC; 6 —————————– 子句、聚合函數、友好列 列名 AS 別名
5.1 簡單查詢
5.1.1 查看表結構
DESC table_name;
DESC emp;
5.1.2查看所有的列
SELECT * FROM table_name;
SELECT * FROM emp;
5.1.3 查看指定列
SELECT 列名 FROM table_name;
SELECT empno FROM emp;
5.1.4 查看指定行
SELECT * FROM table_name WHERE column_name=值;
SELECT * FROM emp WHERE empno=7369;
5.1.5 使用算術表達式 + 、- 、/ 、*
SELECT ename,sal+1 FROM EMP;
ENAME SAL+1
SMITH 801
ALLEN 1601
WARD 1251
SELECT ename,sal-2 FROM EMP;
ENAME SAL-1
SMITH 799
ALLEN 1599
WARD 1249
SELECT ename,sal*2 FROM EMP;
ENAME SAL*2
SMITH 1600
ALLEN 3200
WARD 2500
SELECT ename,sal/2 FROM EMP;
ENAME SAL/2
SMITH 400
ALLEN 800
WARD 625
nvl(comm,0)的意思是,如果comm中有值,則nvl(comm,0)=comm; comm中無值,則nvl(comm,0)=0
5.1.3 連接運算符 ||
SELECT ‘how’||’do’ ||sno;
5.1.4 使用字段別名 AS
SELECT * FROM DEMO1 “Asd”;——-帶引號可以保證輸入的結果有大小寫
SELECT * FROM DEMO1 asd;
5.1.5 空值 IS NULL、 IS NOT NULL
SQL>SELECT * FROM EMP WHERE COMM IS NOT NULL AND SAL IN(SELECT ENAME,sal FROM emp WHERE ENAME LIKE ‘_O%’) ;
5.1.6 去除重復行 DISTINCT
SQL>SELECT DISTINCT DEPTNO FROM EMP ORDER BY DEPTNO
SQL>SELECT DEPTNO FROM EMP GROUP BY DEPTNO ORDER BY DEPTNO
5.1.7 查詢結果排序 ORDER BY ASC/DESC
逆序:
SQL> SELECT * FROM emp WHERE job=’CLERK’ OR ename=’MILLER’ ORDER BY SAL DESC;
順序:
SQL> SELECT * FROM emp WHERE job=’CLERK’ OR ename=’MILLER’ ORDER BY SAL ASC;
SQL> SELECT * FROM emp WHERE job=’CLERK’ OR ename=’MILLER’ ORDER BY SAL ;
5.1.8 關系運算符 >、 < 、=、(!= or <>) MOD(模,類似於%)、BETWEEN AND、 NOT BETWEEN AND
SQL> SELECT DISTINCT MGR FROM emp WHERE MGR<>7788;
SQL>SELECT DISTINCT MGR FROM emp WHERE MGR BETWEEN 7788 AND 7902;
SQL>SELECT * FROM emp WHERE MOD(DEPTNO,100)=2;
SQL>SELECT * FROM EMP1 WHERE EMPNO NOT BETWEEN 7369 AND 7521;
SQL>SELECT * FROM EMP1 WHERE EMPNO>=7369 AND EMPNO<=7521;
5.1.9 操作 IN、NOT IN
SQL> SELECT ENAME,SAL FROM EMP WHERE SAL IN(SELECT MAX(SAL) FROM EMP1 GROUP BY DEPTNO);
5.1.10 模糊查詢 LIKE、NOT LIKE—-只針對字符型
% 表示零或多個字符
_ 表示一個字符
對於特殊符號可使用ESCAPE 標識符來查找
select * from emp where ename like ‘%_%’ escape ‘’
上面的escape表示*後面的那個符號不當成特殊字符處理,就是查找普通的_符號
5.1.11 邏輯運算符 AND、OR、NOT
SQL> select * from emp where job=’CLERK’ OR ename=’MILLER’;
SQL> select * from emp where job=’CLERK’ AND ename=’MILLER’;
5.1.12 ANY、ALL
SQL>SELECT * FROM EMP WHERE EMPNO IN(7369,7521,7782);
SQL>SELECT * FROM EMP WHERE EMPNO >ANY(7369,7521,7782);–大於min
SQL>SELECT * FROM EMP WHERE EMPNO >ALL(7369,7521,7782);–大於max
SQL>SELECT * FROM EMP WHERE EMPNO< ANY(7369,7521,7782);–小於max
SQL>SELECT * FROM EMP WHERE EMPNO< ALL(7369,7521,7782);–小於min
5.1.13 練習
1、選擇在部門30中員工的所有信息
Select * from emp where deptno=30;
2、列出職位為(MANAGER)的員工的編號,姓名
Select empno,ename from emp where job =”Manager”;
3、找出獎金高於工資的員工
Select * from emp where comm>sal;
4、找出每個員工獎金和工資的總和
Select sal+comm,ename from emp;
5、找出部門10中的經理(MANAGER)和部門20中的普通員工(CLERK)
Select * from emp where (deptno=10 and job=?MANAGER?) or (deptno=20 and job=?CLERK?);
6、找出部門10中既不是經理也不是普通員工,而且工資大於等於2000的員工
Select * from emp where deptno=10 and job not in(‘MANAGER’) and sal>=2000;
7、找出有獎金的員工的不同工作
Select distinct job from emp where comm is not null and comm>0;
8、找出沒有獎金或者獎金低於500的員工
Select * from emp where comm<500 or comm is null;
9、顯示雇員姓名,根據其服務年限,將最老的雇員排在最前面
select ename from emp order by hiredate ;
10、SQL>SELECT DEPTNO,MAX(SAL) AS tot,
MIN(COMM) AS MCOMM,
SUM(COMM) SUMC,
TRUNC(AVG(SAL+NVL(COMM,0)))TAVG,
ROUND(AVG(SAL+NVL(COMM,0)),2)RAVG,
COUNT(*)
FROM EMP
HAVING COUNT(*) >3
GROUP BY DEPTNO
ORDER BY DEPTNO
11、SQL>SELECT ENAME,SAL
FROM EMP
WHERE SAL IN(SELECT MAX(SAL)
FROM EMP1
GROUP BY DEPTNO);
5.2 多表查詢
INNER JOIN:內連接
JOIN: 如果表中有至少一個匹配,則返回行
LEFT JOIN: 即使右表中沒有匹配,也從左表返回所有的行
RIGHT JOIN: 即使左表中沒有匹配,也從右表返回所有的行
FULL JOIN: 只要其中一個表中存在匹配,就返回行
5.2.1、笛卡爾集(Cross Join)————列相加,行相乘
Select * from emp,dept;
5.2.2、等值連接(Equijoin)(Natural join..on)———隱式內聯
select empno, ename, sal, emp.deptno, dname from emp, dept where emp.deptno = dept.deptno;
5.2.3、非等值連接(Non-Equijoin)
select ename,empno,grade from emp,salgrade where sal between losal and hisal;
5.2.4、自聯接(Self join)
select column_name from table_name1,table_name2 where 條件;
select e.empno,e.ename,m.empno,m.ename from emp e,emp m where m.mgr = e.empno;
5.2.5、內聯接(Inner Join)———-顯式外聯
SELECT column_name(s)
FROM table_name1
INNER JOIN table_name2
ON table_name1.column_name=table_name2.column_name
5.2.6、 左外聯接(Left Outer Join )
左外連接:在內聯接的基礎上,增加左表中沒有匹配的行,也就是說,左表中的記錄總會出現在最終結果集中
SELECT column_name(s)
FROM table_name1
LEFT JOIN table_name2
ON table_name1.column_name=table_name2.column_name
select s.sid,s.sname,s1.sid,s1.sname from student s,student1 s1 where s.sid=s1.sid(+);
1、先通過from自句判斷左表和右表;
2、接著看加號作用在那個表別名上;
3、如果作用在右表上,則為左外連接,否則為右外連接
select empno,ename,dname from emp left outer join dept on emp.deptno = dept.deptno;
5.2.7、右外聯接(Right Outer Join)
右外連接:在內聯接的基礎上,增加右表中沒有匹配的行,也就是說,右表中的記錄總會出現在最終結果集中
SELECT column_name(s)
FROM table_name1
RIGHT JOIN table_name2
ON table_name1.column_name=table_name2.column_name
右外聯接轉換為內聯接
SELECT column_name(s)
FROM table_name1
RIGHT JOIN table_name2
ON table_name1.column_name=table_name2.column_name WHERE table_name1.column_name is not null;
select s.sid,s.sname,s1.sid,s1.sname from student s,student1 s1 where s.sid(+)=s1.sid;
select empno,ename,dname from emp right outer join dept on emp.deptno= dept.deptno;
select * from emp1 e right join dept d on e.deptno=d.deptno where e.deptno is not null;
5.2.8、全外聯接(Full Outer Join)
SELECT column_name(s)
FROM table_name1
FULL JOIN table_name2
ON table_name1.column_name=table_name2.column_name
select empno,ename,dname from emp full outer join dept on emp.deptno = dept.deptno;
5.2.9、集合操作
· UNION:並集,所有的內容都查詢,重復的顯示一次
·UNION ALL:並集,所有的內容都顯示,包括重復的
· INTERSECT:交集:只顯示重復的
· MINUS:差集:只顯示對方沒有的(跟順序是有關系的)
SELECT column_name(s) FROM table_name1
UNION/INTERSECT/MINUS
SELECT column_name(s) FROM table_name2
首先建立一張只包含 20 部門員工信息的表:
CREATE TABLE emp20 AS SELECT * FROM emp WHERE deptno=20 ;
1、驗證 UNION 及 UNION ALL
UNION:SELECT * FROM emp UNION SELECT * FROM emp20 ;
使用此語句重復的內容不再顯示了
UNION ALL:SELECT * FROM emp UNION ALL SELECT * FROM emp20 ;
重復的內容依然顯示
2、驗證 INTERSECT
SELECT * FROM emp INTERSECT SELECT * FROM emp20 ; 只顯示了兩個表中彼此重復的記錄。
MINUS:返回差異的記錄
SELECT * FROM emp MINUS SELECT * FROM emp20 ; 只顯示了兩張表中的不同記錄滿鏈接也可以用以下的方式來表示:
select t1.id,t2.id from table1 t1,table t2 where t1.id=t2.id(+) union
select t1.id,t2.id from table1 t1,table t2 where t1.id(+)=t2.id
5.3 子查詢
5.3.1、單行子查詢
select * from emp
where sal > (select sal from emp where empno = 7566);
5.3.2、 子查詢空值/多值問題
如果子查詢未返回任何行,則主查詢也不會返回任何結果
(空值)select * from emp where sal > (select sal from emp where empno = 8888);
如果子查詢返回單行結果,則為單行子查詢,可以在主查詢中對其使用相應的單行記錄比較運算符
(正常)select * from emp where sal > (select sal from emp where empno = 7566);
如果子查詢返回多行結果,則為多行子查詢,此時不允許對其使用單行記錄比較運算符
(多值)select * from emp where sal > (select avg(sal) from emp group by deptno);//非法—-錯誤的
5.3.3、 多行子查詢
select * from emp where sal > any(select avg(sal) from emp group by deptno);
select * from emp where sal > all(select avg(sal) from emp group by deptno);
select * from emp where job in (select job from emp where ename = ‘MARTIN’ or ename = ‘SMITH’);
5.3.4、 分頁查詢
Oracle分頁
①采用rownum關鍵字(三層嵌套)
SELECT * FROM(
SELECT A.*,ROWNUM num FROM (
SELECT * FROM t_order)A
WHERE ROWNUM<=15)
WHERE num>=5; –返回第5-15行數據
②采用row_number解析函數進行分頁(效率更高)
SELECT xx.* FROM(
SELECT t.*,row_number() over(ORDER BY o_id)AS num
FROM t_order t
)xx
WHERE num BETWEEN 5 AND 15;
ROWID和ROWNUM的區別
1、ROWID是物理地址,用於定位ORACLE中具體數據的物理存儲位置是唯一的18位物理編號,而ROWNUM則是根據sql查詢後得到的結果自動加上去的
2、ROWNUM是暫時的並且總是從1開始排起,而ROWID是永久的。
解析函數能用格式
函數() over(pertion by 字段 order by 字段);
ROW_NUMBER(): Row_number函數返回一個唯一的值,當碰到相同數據時,排名按照記錄集中記錄的順序依次遞增。 row_number()和rownum差不多,功能更強一點(可以在各個分組內從1開時排序),因為row_number()是分析函數而rownum是偽列所以row_number()一定要over而rownum不能over。
RANK():Rank函數返回一個唯一的值,除非遇到相同的數據,此時所有相同數據的排名是一樣的,同時會在最後一條相同記錄和下一條不同記錄的排名之間空出排名。rank()是跳躍排序,有兩個第二名時接下來就是第四名(同樣是在各個分組內)。
DENSE_RANK():Dense_rank函數返回一個唯一的值,除非當碰到相同數據,此時所有相同數據的排名都是一樣的。
dense_rank()是連續排序,有兩個第二名時仍然跟著第三名。他和row_number的區別在於row_number是沒有重復值的。
dense_rank()是連續排序,有兩個第二名時仍然跟著第三名。他和row_number的區別在於row_number是沒有重復值的。
下面舉個例子:
SQL> select * from user_order order by customer_sales;
REGION_ID CUSTOMER_ID CUSTOMER_SALES
10 30 1216858
5 2 1224992
9 24 1224992
9 23 1224992
8 18 1253840
【3】row_number()、rank()、dense_rank()這三個分析函數的區別實例
SQL>SELECT empno, deptno, SUM(sal) total,
RANK() OVER(ORDER BY SUM(sal) DESC) RANK,
dense_rank() OVER(ORDER BY SUM(sal) DESC)dense_rank,
row_number() OVER(ORDER BY SUM(sal) DESC)row_number
FROM emp1 GROUP BY empno, deptno;
1 7839 10 5000 1 1 1
2 7902 20 3000 2 2 2
3 7788 20 3000 2 2 3
4 7566 20 2975 4 3 4
5 7698 30 2850 5 4 5
6 7782 10 2450 6 5 6
7 7499 30 1600 7 6 7
比較上面3種不同的策略,我們在選擇的時候就要根據客戶的需求來定奪了:
①假如客戶就只需要指定數目的記錄,那麼采用row_number是最簡單的,但有漏掉的記錄的危險
②假如客戶需要所有達到排名水平的記錄,那麼采用rank或dense_rank是不錯的選擇。至於選擇哪一種則看客戶的需要,選擇dense_rank或得到最大的記錄
Mysql分頁采用limt關鍵字
select * from t_order limit 5,10; #返回第6-15行數據
select * from t_order limit 5; #返回前5行
select * from t_order limit 0,5; #返回前5行
Mssql 2000分頁采用top關鍵字(20005以上版本也支持關鍵字rownum)
Select top 10 * from t_order where id not in (select id from t_order where id>5 ); //返回第6到15行數據其中10表示取10記錄 5表示從第5條記錄開始取
sql server 分頁采用top關鍵字
5.3.5、 in 、exists
EXISTS 的執行流程
select * from t1 where exists ( select null from t2 where y = x )
可以理解為:
for x in ( select * from t1 ) loop
if ( exists ( select null from t2 where y = x.x ) then
OUTPUT THE RECORD
end if;
end loop;
對於 in 和 exists 的性能區別:
如果子查詢得出的結果集記錄較少,主查詢中的表較大且又有索引時應該用 in,反之如果外層的主查詢記錄較少,子查詢中的表大,又有索引時使用 exists。
其實我們區分 in 和 exists 主要是造成了驅動順序的改變(這是性能變化的關鍵),如果是 exists,那麼以外層表為驅動表,先被訪問,如果是 IN,那麼先執行子查詢,所以我們會以驅動表的快速返回為目標,那麼就會考慮到索引及結果集的關系了 另外 IN 是不對 NULL 進行處理
如:
select 1 from dual where not in (0,1,2,null) 為空
約束就是指對插入數據的各種限制,例如:人員的姓名不能為空,人的年齡只能在0~150 歲之間。約束可以對數據庫中的數據進行保護。 約束可以在建表的時候直接聲明,也可以為已建好的表添加約束。
6.1、NOT NULL:非空約束 例如:姓名不能為空
CREATE TABLE person(
pid NUMBER ,
name VARCHAR2(30) NOT NULL
) ;
alter table emp
– 插入數據
INSERT INTO person(pid,name) VALUES (11,’張三’);
– 錯誤的數據,會受到約束限制,無法插入
INSERT INTO person(pid) VALUES (12);
6.2、 PRIMARY KEY:主鍵約束
· 不能重復,不能為空 · 例如:身份證號不能為空。 現在假設pid字段不能為空,且不能重復。
DROP TABLE person ;
CREATE TABLE person
(
pid NUMBER PRIMARY KEY , name VARCHAR(30) NOT NULL
) ;
– 插入數據
INSERT INTO person(pid,name) VALUES (11,’張三’);
– 主鍵重復了
INSERT INTO person(pid,name) VALUES (11,’李四’);
6.3、UNIQUE:唯一約束,值不能重復(空值除外) 人員中有電話號碼,電話號碼不能重復。
DROP TABLE person ;
CREATE TABLE person
(
pid NUMBER PRIMARY KEY NOT NULL , name VARCHAR(30) NOT NULL , tel VARCHAR(50) UNIQUE
) ;
– 插入數據
INSERT INTO person(pid,name,tel) VALUES (11,’張三’,’1234567’);
– 電話重復了
INSERT INTO person(pid,name,tel) VALUES (12,’李四’,’1234567’);
6.4、CHECK:條件約束,插入的數據必須滿足某些條件
例如:人員有年齡,年齡的取值只能是 0~150 歲之間
DROP TABLE person ;
CREATE TABLE person(
pid NUMBER PRIMARY KEY NOT NULL ,
name VARCHAR2(30) NOT NULL ,
tel VARCHAR2(50) NOT NULL UNIQUE ,
age NUMBER CHECK(age BETWEEN 0 AND 150)
) ;
– 插入數據
INSERT INTO person(pid,name,tel,age) VALUES (11,’張三’,’1234567’,30);
– 年齡的輸入錯誤
INSERT INTO person(pid,name,tel,age) VALUES (12,’李四’,’2345678’,-100);
alter table product
add constriant chk_product_unitprice check(unitprice>0);
6.5、Foreign Key:外鍵
例如:有以下一種情況:
· 一個人有很多本書:
|- Person 表
|- Book 表:而且book 中的每一條記錄表示一本書的信息,一本書的信息屬於一個人
CREATE TABLE book(
bid NUMBER PRIMARY KEY NOT NULL ,
name VARCHAR(50) ,
– 書應該屬於一個人 pid NUMBER
) ;
如果使用了以上的表直接創建,則插入下面的記錄有效:
INSERT INTO book(bid,name,pid) VALUES(1001,’JAVA’,12) ;
以上的代碼沒有任何錯誤,但是沒有任何意義,因為一本書應該屬於一個人,所以在此處的pid的取值應該與person 表中的pid一致。
此時就需要外鍵的支持。修改book 的表結構
DROP TABLE book ;
CREATE TABLE book
(
bid NUMBER PRIMARY KEY NOT NULL , name VARCHAR(50) ,
– 書應該屬於一個人 pid NUMBER REFERENCES person(pid) ON DELETE CASCADE
– 建立約束:book_pid_fk,與person中的pid 為主-外鍵關系
–CONSTRAINT book_pid_fk FOREIGN KEY(pid) REFERENCES person(pid)
) ;
INSERT INTO book(bid,name,pid) VALUES(1001,’JAVA’,12) ;
6.6、級聯刪除
此時如果想完成刪除person 表的數據同時自動刪除掉book 表的數據操作,則必須使用級聯刪除。
在建立外鍵的時候必須指定級聯刪除(ON DELETE CASCADE)。
CREATE TABLE book
(
bid NUMBER PRIMARY KEY NOT NULL , name VARCHAR(50) ,
– 書應該屬於一個人
pid NUMBER ,
– 建立約束:book_pid_fk,與person中的pid 為主-外鍵關系
CONSTRAINT book_pid_fk FOREIGN KEY(pid) REFERENCES person(pid) ON DELETE CASCADE
) ;
DROP TABLE book ;
DROP TABLE person ;
CREATE TABLE person(
pid NUMBER ,
name VARCHAR(30) NOT NULL ,
tel VARCHAR(50) ,
age NUMBER
) ;
CREATE TABLE book(
bid NUMBER ,
name VARCHAR2(50) ,
pid NUMBER
) ;
以上兩張表中沒有任何約束,下面使用 alter 命令為表添加約束
ALTER TABLE table_name ADD CONSTRAINT column_name 約束;
1、 為兩個表添加主鍵:
· person 表 pid 為主鍵:
ALTER TABLE person ADD CONSTRAINT person_pid_pk PRIMARY KEY(pid) ;
· book 表 bid 為主鍵:
ALTER TABLE book ADD CONSTRAINT book_bid_pk PRIMARY KEY(bid) ;
2、 為 person 表中的 tel 添加唯一約束:
ALTER TABLE person ADD CONSTRAINT person_tel_uk UNIQUE(tel) ;
3、 為 person 表中的 age 添加檢查約束:
ALTER TABLE person ADD CONSTRAINT person_age_ck CHECK(age BETWEEN 0 AND
150) ;
4、 為 book 表中的 pid 添加與 person 的主-外鍵約束,要求帶級聯刪除
ALTER TABLE book ADD CONSTRAINT person_book_pid_fk FOREIGN KEY (pid)
REFERENCES person(pid) ON DELETE CASCADE ;
Q:如何用alter添加非空約束
A:用 check約束
6.7、刪除約束:
ALTER TABLE book DROP CONSTRAINT person_book_pid_fk ;
alter table student drop unique(tel);
6.8、 啟用約束
ALTER TABLE book enable CONSTRAINT person_book_pid_fk ;
6.9、 禁用約束
ALTER TABLE book disable CONSTRAINT person_book_pid_fk ;
7.1 單行函數
1、字符函數
Upper ——-大寫
SELECT Upper (‘abcde’) FROM dual ;
SELECT * FROM emp WHERE ename=UPPER(‘smith’) ;
Lower ——–小寫
SELECT lower(‘ABCDE’) FROM dual ;
Initcap——–首字母大寫
Select initcap(ename) from emp;
Concat—-聯接
Select concat(‘a’,’b’) from dual;
Select ‘a’||’b’ from dual;
Substr——截取
Select substr(‘abcde’,length(‘abcde’)-2) from dual;
Select substr(‘abcde’,-3,3) from dual;
Length——長度
Select length(ename) from emp;
Replace——替代
Select replace(ename,’a’,’A’) from emp;
Instr———- indexof
Select instr(‘Hello World’,’or’) from dual;
Lpad————左側填充 lpad() *****Smith
lpad(‘Smith’,10,’*’)
Rpad————-右側填充 rpad()Smith*****
rpad(‘Smith’,10,’*’)
Trim————-過濾首尾空格 trim() Mr Smith
trim(’ Mr Smith ‘)
2、數值函數
Round
select round(412,-2) from dual; –400
select round(412.313,2) from dual;
Mod
select MOD(412,3) from dual;
Trunc
select trunc(412.13,-2) from dual;
3、日期函數
Months_between()
select months_between(sysdate,hiredate) from emp;
Add_months()
select add_months(sysdate,1) from dual;
Next_day()
select next_day(sysdate,’星期一’) from dual;
Last_day
select last_day(sysdate) from dual;
4.4、轉換函數
To_char
select to_char(sysdate,’yyyy’) from dual; select to_char(sysdate,’fmyyyy-mm-dd’) from dual; select to_char(sal,’L999,999,999’) from emp; select to_char(sysdate,’D’) from dual;//返回星期
To_number
select to_number(‘13’)+to_number(‘14’) from dual;
To_date
Select to_date(?20090210?,?yyyyMMdd?) from dual;
5、通用函數
NVL()函數
select nvl(comm,0) from emp;
NULLIF()函數
如果表達式 exp1 與 exp2 的值相等則返回 null,否則返回 exp1 的值
NVL2()函數 select empno, ename, sal, comm, nvl2(comm, sal+comm, sal) total from emp;
COALESCE()函數
依次考察各參數表達式,遇到非 null 值即停止並返回該值。
select empno, ename, sal, comm, coalesce(sal+comm, sal, 0)總收入 from emp;
CASE 表達式——區間
SQL>select empno,
ename,
sal,
case deptno
when 10 then ‘財務部’
when 20 then ‘研發部’
when 30 then ‘銷售部’
else ‘未知部門’
end 部門
from emp;
SQL>SELECT e.*,
CASE
WHEN sal>=3000 THEN ‘高’
WHEN sal>=2000 AND sal<3000 THEN ‘中’
WHEN sal<2000 AND sal>0 THEN ‘高’
ELSE ‘un’
END ca
FROM emp1 e;
DECODE()函數————離散的值
SQL>select empno, ename, sal,
decode(deptno,
10, ‘財務部’,
20, ‘研發部’,
30, ‘銷售部’,
‘未知部門’) 部門
from emp;
單行函數嵌套
select empno, lpad(initcap(trim(ename)),10,’ ‘) name, job, sal from emp;
7.2 分組函數
1、COUNT
如果數據庫表的沒有數據,count(*)返回的不是 null,而是 0
2、Avg,max,min,sum
3、nvl—-分組函數與空值
分組函數省略列中的空值
select avg(comm) from emp; select sum(comm) from emp;
可使用 NVL()函數強制分組函數處理空值 select avg(nvl(comm, 0)) from emp;
4、GROUP BY 子句
出現在 SELECT 列表中的字段或者出現在 order by 後面的字段,如果不是包含在分組函數中,那麼該字段必須同時在 GROUP BY 子句中出現。包含在 GROUP BY 子句中的字段則不必須出現在 SELECT 列表中。
可使用 where 字句限定查詢條件,可使用 Order by 子句指定排序方式
如果沒有 GROUP BY 子句,SELECT 列表中不允許出現字段(單行函數)與分組函數混用的情況。
select empno, sal from emp; //合法 select avg(sal) from emp; //合法 select empno, initcap(ename), avg(sal) from emp; //非法
不允許在 WHERE 子句中使用分組函數。 select deptno, avg(sal) from emp where avg(sal) > 2000; group by deptno;
5、HAVING 子句
select deptno, job, avg(sal)
from emp
where hiredate >= to_date(‘1981-05-01’,’yyyy-mm-dd’) group by deptno,job having avg(sal) > 1200 order by deptno,job;
6、分組函數嵌套
select max(avg(sal)) from emp group by deptno;
1、聲明變量
變量一般都在PL/SQL塊的聲明部分聲明,引用變量前必須首先聲明,要在執行或異常處理部分使用變量,那麼變量必須首先在聲明部分進行聲明。
聲明變量的語法如下:
Variable_name [CONSTANT] databyte [NOT NULL][:=|DEFAULT expression]
注意:可以在聲明變量的同時給變量強制性的加上NOT NULL約束條件,此時變量在初始化時必須賦值。
2、給變量賦值
給變量賦值有兩種方式:
. 直接給變量賦值
X:=200;
Y=Y+(X*20);
. 通過SQL SELECT INTO 或FETCH INTO給變量賦值
SELECT SUM(SALARY),SUM(SALARY*0.1)
INTO TOTAL_SALARY,TATAL_COMMISSION
FROM EMPLOYEE
WHERE DEPT=10;
3、常量
常量與變量相似,但常量的值在程序內部不能改變,常量的值在定義時賦予,,他的聲明方式與變量相似,但必須包括關鍵字CONSTANT。常量和變量都可被定義為SQL和用戶定義的數據類型。
ZERO_VALUE CONSTANT NUMBER:=0;
4、標量(scalar)數據類型
標量(scalar)數據類型沒有內部組件,他們大致可分為以下四類:
. number
. char
. date/time
. boolean
表1 Numer
Datatype Range Subtypes description
BINARY_INTEGER -214748-2147483647 NATURAL
NATURAL
NPOSITIVE
POSITIVEN
SIGNTYPE
用於存儲單字節整數。
要求存儲長度低於NUMBER值。
用於限制范圍的子類型(SUBTYPE):
NATURAL:用於非負數
POSITIVE:只用於正數
NATURALN:只用於非負數和非NULL值
POSITIVEN:只用於正數,不能用於NULL值
SIGNTYPE:只有值:-1、0或1.
NUMBER 1.0E-130-9.99E125 DEC
DECIMAL
DOUBLE
PRECISION
FLOAT
INTEGERIC
INT
NUMERIC
REAL
SMALLINT 存儲數字值,包括整數和浮點數。可以選擇精度和刻度方式,語法:
number[([,])]。
缺省的精度是38,scale是0.
PLS_INTEGER -2147483647-2147483647 與BINARY_INTEGER基本相同,但采用機器運算時,PLS_INTEGER提供更好的性能 。
表2 字符數據類型
datatype rang subtype description
CHAR 最大長度32767字節 CHARACTER 存儲定長字符串,如果長度沒有確定,缺省是1
LONG 最大長度2147483647字節 存儲可變長度字符串
RAW 最大長度32767字節 用於存儲二進制數據和字節字符串,當在兩個數據庫之間進行傳遞時,RAW數據不在字符集之間進行轉換。
LONGRAW 最大長度2147483647 與LONG數據類型相似,同樣他也不能在字符集之間進行轉換。
ROWID 18個字節 與數據庫ROWID偽列類型相同,能夠存儲一個行標示符,可以將行標示符看作數據庫中每一行的唯一鍵值。
VARCHAR2 最大長度32767字節 STRINGVARCHAR 與VARCHAR數據類型相似,存儲可變長度的字符串。聲明方法與VARCHAR相同
表3 DATE和BOOLEAN
datatype range description
BOOLEAN TRUE/FALSE 存儲邏輯值TRUE或FALSE,無參數
DATE 01/01/4712 BC 存儲固定長的日期和時間值,日期值中包含時間
LOB數據類型
LOB(大對象,Large object) 數據類型用於存儲類似圖像,聲音這樣的大型數據對象,LOB數據對象可以是二進制數據也可以是字符數據,其最大長度不超過4G。LOB數據類型支持任意訪問方式,LONG只支持順序訪問方式。LOB存儲在一個單獨的位置上,同時一個”LOB定位符”(LOB locator)存儲在原始的表中,該定位符是一個指向實際數據的指針。在PL/SQL中操作LOB數據對象使用ORACLE提供的包DBMS_LOB.LOB數據類型可分為以下四類:
. BFILE—————-二進制文件
. BLOB————–二進制對象
. CLOB—————字符型對象
. NCLOB————-nchar類型對象
操作符
PL/SQL有一系列操作符。操作符分為下面幾類:
. 算術操作符
. 關系操作符
. 比較操作符
. 邏輯操作符
算術操作符如表4所示
operator operation
+ 加
- 減
/ 除
* 乘
** 乘方
關系操作符主要用於條件判斷語句或用於where子串中,關系操作符檢查條件和結果是否為true或false,
表5PL/SQL中的關系操作符
operator operation
< 小於操作符
<= 小於或等於操作符
大於操作符
= 大於或等於操作符
= 等於操作符
!= 不等於操作符
<> 不等於操作符
:= 賦值操作符
表6 顯示的是比較操作符
operator operation
IS NULL 如果操作數為NULL返回TRUE
LIKE 比較字符串值
BETWEEN 驗證值是否在范圍之內
IN 驗證操作數在設定的一系列值中
表7顯示的是邏輯操作符
operator operation
AND 兩個條件都必須滿足
OR 只要滿足兩個條件中的一個
NOT 取反
PL/SQL動態SQL(原創)
概念:動態SQL,編譯階段無法明確SQL命令,只有在運行階段才能被識別
動態SQL和靜態SQL兩者的異同
靜態SQL為直接嵌入到PL/SQL中的代碼,而動態SQL在運行時,根據不同的情況產生不同的SQL語句。
靜態SQL在執行前編譯,一次編譯,多次運行。動態SQL同樣在執行前編譯,但每次執行需要重新編譯。
靜態SQL可以使用相同的執行計劃,對於確定的任務而言,靜態SQL更具有高效性,但缺乏靈活性;動態SQL使用了不同的執行計劃,效率不如靜態SQL,但能夠解決復雜的問題。
動態SQL容易產生SQL注入,為數據庫安全帶來隱患。
動態SQL語句的幾種方法
a.使用EXECUTE IMMEDIATE語句
包括DDL語句,DCL語句,DML語句以及單行的SELECT 語句。該方法不能用於處理多行查詢語句。
b.使用OPEN-FOR,FETCH和CLOSE語句
對於處理動態多行的查詢操作,可以使用OPEN-FOR語句打開游標,使用FETCH語句循環提取數據,最終使用CLOSE語句關閉游標。
c.使用批量動態SQL
即在動態SQL中使用BULK子句,或使用游標變量時在fetch中使用BULK ,或在FORALL語句中使用BULK子句來實現。
d.使用系統提供的PL/SQL包DBMS_SQL來實現動態SQL
動態SQL的語法
下面是動態SQL常用的語法之一
EXECUTE IMMEDIATE dynamic_SQL_string
[INTO defined_variable1, defined_variable2, …]
[USING [IN | OUT | IN OUT] bind_argument1, bind_argument2,…]
[{RETURNING | RETURN} field1, field2, … INTO bind_argument1,
bind_argument2, …]
語法描述
dynamic_SQL_string:存放指定的SQL語句或PL/SQL塊的字符串變量
defined_variable1:用於存放單行查詢結果,使用時必須使用INTO關鍵字,類似於使用
SELECT ename INTO v_name FROM scott.emp;
只不過在動態SQL時,將INTO defined_variable1移出到dynamic_SQL_string語句之外。
bind_argument1:用於給動態SQL語句傳入或傳出參數,使用時必須使用USING關鍵字,IN表示傳入的參數,OUT表示傳出的參數,IN OUT則既可以傳入,也可傳出。
RETURNING | RETURN 子句也是存放SQL動態返回值的變量。
使用要點
a.EXECUTE IMMEDIATE執行DML時,不會提交該DML事務,需要使用顯示提交(COMMIT)或作為EXECUTE IMMEDIATE自身的一部分。
b.EXECUTE IMMEDIATE執行DDL,DCL時會自動提交其執行的事務。
c.對於多行結果集的查詢,需要使用游標變量或批量動態SQL,或者使用臨時表來實現。
d.當執行SQL時,其尾部不需要使用分號,當執行PL/SQL 代碼時,其尾部需要使用分號。
f.動態SQL中的占位符以冒號開頭,緊跟任意字母或數字表示。
動態SQL的使用(DDL,DCL,DML以及單行結果集)
DECLARE
v_table VARCHAR2(30):=’emp1’;
v_sql LONG:=’SELECT ename FROM emp1 WHERE empno=:1’;–占位符\可以用任何符號(數字或字母)
–v_no emp1.empno%TYPE:=’&請輸入號碼’;–&是變量綁定符 綁定的數據是字符串類型時必須要加引號
–v_no emp1.empno%TYPE:=&請輸入號碼;
v_name emp1.ename%TYPE;
BEGIN
–EXECUTE IMMEDIATE v_sql INTO v_name USING IN v_no;
dbms_output.put_line(‘ename=’||v_name);
–EXECUTE IMMEDIATE ‘create table emp2 as select * from emp’;
–EXECUTE IMMEDIATE ‘drop table ‘||v_table;
–EXECUTE IMMEDIATE ‘alter table emp enable row movement’;
END;
BULK子句和動態SQL的使用
動態SQL中使用BULK子句的語法
EXECUTE IMMEDIATE dynamic_string –dynamic_string用於存放動態SQL字符串
[BULK COLLECT INTO define_variable[,define_variable…]] –存放查詢結果的集合變量
[USING bind_argument[,argument…]] –使用參數傳遞給動態SQL
[{RETURNING | RETURN} –返回子句
BULK COLLECT INTO return_variable[,return_variable…]]; –存放返回結果的集合變量
使用bulk collect into子句處理動態SQL中T的多行查詢可以加快處理速度,從而提高應用程序的性能。當使用bulk子句時,集合類型可以是PL/SQL所支持的索引表、嵌套表和VARRY,但集合元 素必須使用SQL數據類型。常用的三種語句支持BULK子句,分別為EXECUTE IMMEDIATE,FETCH 和FORALL。
使用EXECUTE IMMEDIATE 結合BULK子句處理多行查詢。使用了BULK COLLECT INTO來傳遞結果。
SQL>declare
type ename_table_type is table of emp1.ename%type index by binary_integer;
type sal_table_type is table OF emp1.sal%type index by binary_integer;
ename_table ename_table_type;
sal_table sal_table_type;
sql_stat varchar2(100);
v_dno number := 7369;
begin
sql_stat := ‘select ename,sal from emp1 where deptno = :v_dno’; –動態DQL語句,未使用RETURNING子句
execute immediate sql_stat
bulk collect into ename_table,sal_table using v_dno;
for i in 1..ename_table.count loop
dbms_output.put_line(‘Employee ’ || ename_table(i) || ’ Salary is: ’ || sal_table(i));
end loop;
end;
使用FETCH子句結合BULK子句處理多行結果集
下面的示例中首先定義了游標類型,游標變量以及復合類型,復合變量,接下來從動態SQL中OPEN游標,然後使用FETCH將結果存放到復合變量中。即使用OPEN,FETCH代替了EXECUTE IMMEDIATE來完成動態SQL的執行。
SQL> declare
2 type empcurtype is ref cursor;
3 emp_cv empcurtype;
4 type ename_table_type is table of tb2.ename%type index by binary_integer;
5 ename_table ename_table_type;
6 sql_stat varchar2(120);
7 begin
8 sql_stat := ‘select ename from tb2 where deptno = :dno’;
9 open emp_cv for sql_stat using &dno;
10 fetch emp_cv bulk collect into ename_table;
11 for i in 1..ename_table.count loop
12 dbms_output.put_line(‘Employee Name: ’ || ename_table(i));
13 end loop;
14 close emp_cv;
15* end;
在FORALL語句中使用BULK子句
下面是FORALL子句的語法
FORALL index IN lower bound..upper bound –FORALL循環計數
EXECUTE IMMEDIATE dynamic_string –結合EXECUTE IMMEDIATE來執行動態SQL語句
USING bind_argument | bind_argument(index) –綁定輸入參數
[bind_argument | bind_argument(index)]…
[{RETURNING | RETURN} BULK COLLECT INTO bind_argument[,bind_argument…]]; –綁定返回結果集
FORALL子句允許為動態SQL輸入變量,但FORALL子句僅支持的DML(INSERT,DELETE,UPDATE)語句,不支持動態的SELECT語句。
下面的示例中,首先聲明了兩個復合類型以及復合變量,接下來為復合變量ename_table賦值,以形成動態SQL語句。緊接著使用FORALL子句結合EXECUTE IMMEDIATE 來提取結果集。
SQL> declare
2 type ename_table_type is table of tb2.ename%type;
3 type sal_table_type is table of tb2.sal%type;
4 ename_table ename_table_type;
5 sal_table sal_table_type;
6 sql_stat varchar2(100);
7 begin
8 ename_table := ename_table_type(‘BLAKE’,’FORD’,’MILLER’);
9 sql_stat := ‘update tb2 set sal = sal * 1.1 where ename = :1’
10 || ’ returning sal into :2’;
11 forall i in 1..ename_table.count
12 execute immediate sql_stat using ename_table(i) returning bulk collect into sal_table;
13 for j in 1..sal_table.count loop
14 dbms_output.put_line(‘The ’ || ename_table(j) || ”” || ‘s new salalry is ’ || sal_table(j));
15 end loop;
16* end;
常見錯誤
1、使用動態DDL時,不能使用綁定變量。
EXECUTE IMMEDIATE ‘CREATE TABLE dsa ‘||’as select * from :1’ USING IN v_table;
解決辦法,將綁定變量直接拼接,如下:
EXECUTE IMMEDIATE ‘CREATE TABLE dsa ‘||’as select * from ‘|| v_table;
2、不能使用schema對象作為綁定參數,下面的示例中,動態SQL語句查詢需要傳遞表名,因此收到了錯誤提示。
EXECUTE IMMEDIATE ‘SELECT COUNT(*) FROM:tb_name ’ into v_count;
解決辦法,將綁定變量直接拼接,如下:
EXECUTE IMMEDIATE ‘SELECT COUNT(*) FROM ’ || tb_name into v_count;
3、動態SQL塊不能使用分號結束(;)
execute immediate ‘select count(*) from emp;’ –此處多出了分號,應該去掉
4、動態PL/SQL塊不能使用正斜槓來結束塊,但是塊結尾處必須要使用分號(;)
SQL> declare
2 plsql_block varchar2(300);
3 begin
4 plsql_block := ‘Declare ’ ||
5 ’ v_date date; ’ ||
6 ’ begin ’ ||
7 ’ select sysdate into v_date from dual; ’ ||
8 ’ dbms_output.put_line(to_char(v_date,”yyyy-mm-dd”)); ’ ||
9 ’ end;
10 /’; –此處多出了/,應該將其去掉
11 execute immediate plsql_block;
12* end;
4、空值傳遞的問題
下面的示例中對表tb_emp更新,並將空值更新到sal列,直接使用USING NULL收到錯誤提示。
execute immediate sql_stat using null,v_empno;
正確的處理方法
v_sal tb2.sal%type; –聲明一個新變量,但不賦值
execute immediate sql_stat using v_sal,v_empno;
5、日期和字符型必須要使用引號來處理
DECLARE
sql_stat VARCHAR2(100);
v_date DATE :=TO_DATE(‘2013-11-21’,’yyyy-mm-dd’);
v_empno NUMBER :=7900;
v_ename emp.ename%TYPE;
v_sal emp.sal%TYPE;
BEGIN
sql_stat := ‘SELECT ename,sal FROM emp WHERE hiredate=:v_date’;
EXECUTE IMMEDIATE sql_stat
INTO v_ename,v_sal
USING v_date;
DBMS_OUTPUT.PUT_LINE(‘Employee Name ‘||v_ename||’, sal is ‘||v_sal);
END;
6、單行SELECT 查詢不能使用RETURNING INTO返回
下面的示例中,使用了動態的單行SELECT查詢,並且使用了RETURNING子句來返回值。事實上,RETURNING coloumn_name INTO 子句僅僅支持對DML結果集的返回,因此,收到了錯誤提示。
SQL>declare
v_empno emp.empno%type := &empno;
v_ename emp.ename%type;
begin
execute immediate ‘select ename from emp where empno = :eno’ into v_ename using v_empno;
dbms_output.put_line(‘Employee name: ’ || v_ename);
end;
游標的使用
在 PL/SQL 程序中,對於處理多行記錄的事務經常使用游標來實現。
4.1 游標概念
對於不同的SQL語句,游標的使用情況不同:
SQL語句
游標
非查詢語句
隱式的
結果是單行的查詢語句
隱式的或顯示的
結果是多行的查詢語句
顯示的
游標名%屬性名
顯式游標的名字右用戶定義,隱式游標名為SQL
隱式游標只是一個狀態
4.1.1 處理顯式游標
顯式游標處理
語法格式:
CURSOR cursor_name is select * from emp;
OPEN cursor_name;
FETCH cursor_name INTO variables_list;
CLOSE cursor_name;
例1:
DECLARE
v_deptno NUMBER:=&inputno;
v_row emp1%ROWTYPE;
CURSOR v_cursor IS SELECT * FROM emp1 WHERE deptno=v_deptno;
BEGIN
–打開
OPEN v_cursor;
–提取
LOOP
FETCH v_cursor INTO v_row;–先提取
EXIT WHEN v_cursor%NOTFOUND;
dbms_output.put_line(‘Employee Name: ’ || v_row.ename || ’ ,Salary: ’ || v_row.sal);
END LOOP;
–關閉
CLOSE v_cursor;
END;
顯式游標處理需四個 PL/SQL步驟:
l 定義/聲明游標:就是定義一個游標名,以及與其相對應的SELECT 語句。
格式:
CURSOR cursor_name[(parameter[, parameter]…)]
[RETURN datatype]
IS
select_statement;
select_statement;
游標參數只能為輸入參數,其格式為:
parameter_name [IN] datatype [{:= | DEFAULT} expression]
在指定數據類型時,不能使用長度約束。如NUMBER(4),CHAR(10) 等都是錯誤的。
[RETURN datatype]是可選的,表示游標返回數據的數據。如果選擇,則應該嚴格與select_statement中的選擇列表在次序和數據類型上匹配。一般是記錄數據類型或帶“%ROWTYPE”的數據。
l 打開游標:就是執行游標所對應的SELECT 語句,將其查詢結果放入工作區,並且指針指向工作區的首部,標識游標結果集合。如果游標查詢語句中帶有FOR UPDATE選項,OPEN 語句還將鎖定數據庫表中游標結果集合對應的數據行。
格式:
OPEN cursor_name[([parameter =>] value[, [parameter =>] value]…)];
在向游標傳遞參數時,可以使用與函數參數相同的傳值方法,即位置表示法和名稱表示法。PL/SQL 程序不能用OPEN 語句重復打開一個游標。
l 提取游標數據:就是檢索結果集合中的數據行,放入指定的輸出變量中。
格式:
FETCH cursor_name INTO {variable_list | record_variable };
執行FETCH語句時,每次返回一個數據行,然後自動將游標移動指向下一個數據行。當檢索到最後一行數據時,如果再次執行FETCH語句,將操作失敗,並將游標屬性%NOTFOUND置為TRUE。所以每次執行完FETCH語句後,檢查游標屬性%NOTFOUND就可以判斷FETCH語句是否執行成功並返回一個數據行,以便確定是否給對應的變量賦了值。
l 對該記錄進行處理;
l 繼續處理,直到活動集合中沒有記錄;
l 關閉游標:當提取和處理完游標結果集合數據後,應及時關閉游標,以釋放該游標所占用的系統資源,並使該游標的工作區變成無效,不能再使用FETCH 語句取其中數據。關閉後的游標可以使用OPEN 語句重新打開。
格式:
CLOSE cursor_name;
注:定義的游標不能有INTO 子句。
例1. 查詢前10名員工的信息。
DECLARE
CURSOR c_cursor
IS SELECT first_name || last_name, Salary FROM EMPLOYEES WHERE rownum<11;
v_ename EMPLOYEES.first_name%TYPE;
v_sal EMPLOYEES.Salary%TYPE;
BEGIN
OPEN c_cursor;
FETCH c_cursor INTO v_ename, v_sal;
WHILE c_cursor%FOUND LOOP
DBMS_OUTPUT.PUT_LINE(v_ename||’—’||to_char(v_sal) );
FETCH c_cursor INTO v_ename, v_sal;
END LOOP;
CLOSE c_cursor;
END;
2.游標屬性
Cursor_name%FOUND 布爾型屬性,當最近一次提取游標操作FETCH成功則為 TRUE,否則為FALSE;
Cursor_name%NOTFOUND 布爾型屬性,與%FOUND相反;
Cursor_name%ISOPEN 布爾型屬性,當游標已打開時返回 TRUE;
Cursor_name%ROWCOUNT 數字型屬性,返回已從游標中讀取的記錄數。
例2:沒有參數且沒有返回值的游標。
DECLARE
v_f_name employees.first_name%TYPE;
v_j_id employees.job_id%TYPE;
CURSOR c1 –聲明游標,沒有參數沒有返回值
IS
SELECT first_name, job_id FROM employees WHERE department_id = 20;
BEGIN
OPEN c1; –打開游標
LOOP
FETCH c1 INTO v_f_name, v_j_id; –提取游標
IF c1%FOUND THEN
DBMS_OUTPUT.PUT_LINE(v_f_name||’的崗位是’||v_j_id);
ELSE
DBMS_OUTPUT.PUT_LINE(‘已經處理完結果集了’);
EXIT;
END IF;
END LOOP;
CLOSE c1; –關閉游標
END;
例3:有參數且沒有返回值的游標。
DECLARE
v_f_name employees.first_name%TYPE;
v_h_date employees.hire_date%TYPE;
CURSOR c2(dept_id NUMBER, j_id VARCHAR2) –聲明游標,有參數沒有返回值
IS
SELECT first_name, hire_date FROM employees WHERE department_id = dept_id AND job_id = j_id;
BEGIN
OPEN c2(90, ‘AD_VP’); –打開游標,傳遞參數值
LOOP
FETCH c2 INTO v_f_name, v_h_date; –提取游標
IF c2%FOUND THEN
DBMS_OUTPUT.PUT_LINE(v_f_name||’的雇傭日期是’||v_h_date);
ELSE
DBMS_OUTPUT.PUT_LINE(‘已經處理完結果集了’);
EXIT;
END IF;
END LOOP;
CLOSE c2; –關閉游標
END;
例4:有參數且有返回值的游標。
DECLARE
TYPE emp_record_type IS RECORD(
f_name employees.first_name%TYPE,
h_date employees.hire_date%TYPE);
v_emp_record EMP_RECORD_TYPE;
v_emp_record EMP_RECORD_TYPE;
CURSOR c3(dept_id NUMBER, j_id VARCHAR2) –聲明游標,有參數有返回值
RETURN EMP_RECORD_TYPE
IS
SELECT first_name, hire_date FROM employees WHERE department_id = dept_id AND job_id = j_id;
BEGIN
OPEN c3(j_id => ‘AD_VP’, dept_id => 90); –打開游標,傳遞參數值
LOOP
FETCH c3 INTO v_emp_record; –提取游標
IF c3%FOUND THEN
DBMS_OUTPUT.PUT_LINE(v_emp_record.f_name||’的雇傭日期是’||v_emp_record.h_date);
ELSE
DBMS_OUTPUT.PUT_LINE(‘已經處理完結果集了’);
EXIT;
END IF;
END LOOP;
CLOSE c3; –關閉游標
END;
例5:基於游標定義記錄變量。
DECLARE
CURSOR c4(dept_id NUMBER, j_id VARCHAR2) –聲明游標,有參數沒有返回值
IS
SELECT first_name f_name, hire_date FROM employees WHERE department_id = dept_id AND job_id = j_id;
–基於游標定義記錄變量,比聲明記錄類型變量要方便,不容易出錯
v_emp_record c4%ROWTYPE;
BEGIN
OPEN c4(90, ‘AD_VP’); –打開游標,傳遞參數值
LOOP
FETCH c4 INTO v_emp_record; –提取游標
IF c4%FOUND THEN
DBMS_OUTPUT.PUT_LINE(v_emp_record.f_name||’的雇傭日期是’||v_emp_record.hire_date);
ELSE
DBMS_OUTPUT.PUT_LINE(‘已經處理完結果集了’);
EXIT;
END IF;
END LOOP;
CLOSE c4; –關閉游標
END;
3. 游標的FOR循環
PL/SQL語言提供了游標FOR循環語句,自動執行游標的OPEN、FETCH、CLOSE語句和循環語句的功能;當進入循環時,游標FOR循環語句自動打開游標,並提取第一行游標數據,當程序處理完當前所提取的數據而進入下一次循環時,游標FOR循環語句自動提取下一行數據供程序處理,當提取完結果集合中的所有數據行後結束循環,並自動關閉游標。
格式:
FOR index_variable IN cursor_name[(value[, value]…)] LOOP
– 游標數據處理代碼
END LOOP;
其中:
index_variable為游標FOR 循環語句隱含聲明的索引變量,該變量為記錄變量,其結構與游標查詢語句返回的結構集合的結構相同。在程序中可以通過引用該索引記錄變量元素來讀取所提取的游標數據,index_variable中各元素的名稱與游標查詢語句選擇列表中所制定的列名相同。如果在游標查詢語句的選擇列表中存在計算列,則必須為這些計算列指定別名後才能通過游標FOR 循環語句中的索引變量來訪問這些列數據。
注:不要在程序中對游標進行人工操作;不要在程序中定義用於控制FOR循環的記錄。
例6:當所聲明的游標帶有參數時,通過游標FOR 循環語句為游標傳遞參數。
DECLARE
CURSOR c_cursor(dept_no NUMBER DEFAULT 10)
IS
SELECT department_name, location_id FROM departments WHERE department_id <= dept_no;
BEGIN
DBMS_OUTPUT.PUT_LINE(‘當dept_no參數值為30:’);
FOR c1_rec IN c_cursor(30) LOOP
DBMS_OUTPUT.PUT_LINE(c1_rec.department_name||’—’||c1_rec.location_id);
END LOOP;
DBMS_OUTPUT.PUT_LINE(CHR(10)||’使用默認的dept_no參數值10:’);
FOR c1_rec IN c_cursor LOOP
DBMS_OUTPUT.PUT_LINE(c1_rec.department_name||’—’||c1_rec.location_id);
END LOOP;
END;
例7:PL/SQL還允許在游標FOR循環語句中使用子查詢來實現游標的功能。
BEGIN
–隱含打開游標
FOR r IN (SELECT * FROM emp1 WHERE deptno=v_deptno) LOOP
–隱含執行一個FETCH語句
dbms_output.put_line(‘Employee Name: ’ || r.ename || ’ ,Salary: ’ || r.sal);
–隱含監測c_sal%NOTFOUND
END LOOP;
–隱含關閉游標
END;
4.1.2 處理隱式游標
對於非查詢語句,如修改、刪除操作,則由ORACLE 系統自動地為這些操作設置游標並創建其工作區,這些由系統隱含創建的游標稱為隱式游標,隱式游標的名字為SQL,這是由ORACLE 系統定義的。對於隱式游標的操作,如定義、打開、取值及關閉操作,都由ORACLE 系統自動地完成,無需用戶進行處理。用戶只能通過隱式游標的相關屬性,來完成相應的操作。在隱式游標的工作區中,所存放的數據是與用戶自定義的顯示游標無關的、最新處理的一條SQL 語句所包含的數據。
格式調用為: SQL%
注:INSERT, UPDATE, DELETE, SELECT(單查詢) 語句中不必明確定義游標。
隱式游標屬性
屬性
值
SELECT
INSERT
UPDATE
DELETE
SQL%ISOPEN
FALSE
FALSE
FALSE
FALSE
SQL%FOUND
TRUE
有結果
成功
成功
SQL%FOUND
FALSE
沒結果
失敗
失敗
SQL%NOTFUOND
TRUE
沒結果
失敗
失敗
SQL%NOTFOUND
FALSE
有結果
成功
失敗
SQL%ROWCOUNT
返回行數,只為1
插入的行數
修改的行數
刪除的行數
例8: 通過隱式游標SQL的%ROWCOUNT屬性來了解修改了多少行。
DECLARE
v_rows NUMBER;
BEGIN
–更新數據
UPDATE employees SET salary = 30000
WHERE department_id = 90 AND job_id = ‘AD_VP’;
–獲取默認游標的屬性值
v_rows := SQL%ROWCOUNT;
DBMS_OUTPUT.PUT_LINE(
DBMS_OUTPUT.PUT_LINE(‘更新了’||v_rows||’個雇員的工資’);
–回退更新,以便使數據庫的數據保持原樣
ROLLBACK;
END;
4.1.3 使用游標更新和刪除數據
游標修改和刪除操作是指在游標定位下,修改或刪除表中指定的數據行。這時,要求游標查詢語句中必須使用FOR UPDATE選項,以便在打開游標時鎖定游標結果集合在表中對應數據行的所有列和部分列。
為了對正在處理(查詢)的行不被另外的用戶改動,ORACLE 提供一個 FOR UPDATE 子句來對所選擇的行進行鎖住。該需求迫使ORACLE鎖定游標結果集合的行,可以防止其他事務處理更新或刪除相同的行,直到您的事務處理提交或回退為止。
語法:
SELECT column_list FROM table_list FOR UPDATE [OF column[, column]…] [NOWAIT]
如果使用 FOR UPDATE 聲明游標,則可在DELETE和UPDATE 語句中使用
WHERE CURRENT OF cursor_name子句,修改或刪除游標結果集合當前行對應的數據庫表中的數據行。
例9:從EMPLOYEES表中查詢某部門的員工情況,將其工資最低定為 1500;
DECLARE
V_deptno employees.department_id
V_deptno employees.department_id%TYPE :=&p_deptno;
CURSOR emp_cursor
IS
SELECT employees.employee_id, employees.salary FROM employees WHERE employees.department_id=v_deptno FOR UPDATE NOWAIT;
BEGIN
FOR emp_record IN emp_cursor LOOP
IF emp_record.salary < 1500 THEN
UPDATE employees SET salary=1500 WHERE CURRENT OF emp_cursor;
END IF;
END LOOP;
COMMIT;
END;
4.2 游標變量
與游標一樣,游標變量也是一個指向多行查詢結果集合中當前數據行的指針。但與游標不同的是,游標變量是動態的,而游標是靜態的。游標只能與指定的查詢相連,即固定指向一個查詢的內存處理區域,而游標變量則可與不同的查詢語句相連,它可以指向不同查詢語句的內存處理區域(但不能同時指向多個內存處理區域,在某一時刻只能與一個查詢語句相連),只要這些查詢語句的返回類型兼容即可。
4.2.1 聲明游標變量
游標變量為一個指針,它屬於參照類型,所以在聲明游標變量類型之前必須先定義游標變量類型。在PL/SQL中,可以在塊、子程序和包的聲明區域內定義游標變量類型。
語法格式為:
1.定義游標變量
TYPE cursortype IS REF CURSOR;
cursor_variable cursortype;
2.打開游標變量
OPEN cursor_variable FOR dynamic_string
[USING bind_argument[,bind_argument]…]
3.循環提取數據
FETCH cursor_variable INTO {var1[,var2]…| record_variable};
EXIT WHEN cursor_variable%NOTFOUND
4.關閉游標變量
CLOSE cursor_variable;
例10:使用游標變量(沒有RETURN子句)
DECLARE
–定義一個游標數據類型
TYPE emp_cursor_type IS REF CURSOR;
–聲明一個游標變量
c1 EMP_CURSOR_TYPE;
–聲明兩個記錄變量
v_emp_record employees%ROWTYPE;
v_reg_record regions%ROWTYPE;
BEGIN
OPEN c1 FOR SELECT * FROM employees WHERE department_id = 20;
LOOP
FETCH c1 INTO v_emp_record;
EXIT WHEN c1%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(v_emp_record.first_name||’的雇傭日期是’||v_emp_record.hire_date);
END LOOP;
–將同一個游標變量對應到另一個SELECT語句
OPEN c1 FOR SELECT * FROM regions WHERE region_id IN(1,2);
LOOP
FETCH c1 INTO v_reg_record;
EXIT WHEN c1%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(v_reg_record.region_id||'表示'||v_reg_record.region_name);
END LOOP;
CLOSE c1;
END;
例11:使用游標變量(有RETURN子句)
DECLARE
–定義一個與employees表中的這幾個列相同的記錄數據類型
TYPE emp_record_type IS RECORD(
f_name employees.first_name
f_name employees.first_name%TYPE,
h_date employees.hire_date
h_date employees.hire_date%TYPE,
j_id employees.job_id
j_id employees.job_id%TYPE);
–聲明一個該記錄數據類型的記錄變量
v_emp_record EMP_RECORD_TYPE;
–定義一個游標數據類型
TYPE emp_cursor_type IS REF CURSOR
RETURN EMP_RECORD_TYPE;
–聲明一個游標變量
c1 EMP_CURSOR_TYPE;
BEGIN
OPEN c1 FOR SELECT first_name, hire_date, job_id FROM employees WHERE department_id = 20;
LOOP
FETCH c1 INTO v_emp_record;
EXIT WHEN c1%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(‘雇員名稱:’||v_emp_record.f_name||’ 雇傭日期:’||v_emp_record.h_date||’ 崗位:’||v_emp_record.j_id);
END LOOP;
CLOSE c1;
END;