說是最精確截取長度,其實我也不敢確定是否是最精確的,具體有多精確看下面的效果就知道了:
先上測試用的字符串:
<?php
header("Content-Type:text/html;charset=utf-8");
echo cn_substr_utf8('我是一個,和哈,哦也,,國家!',12);
echo '<br />',cn_substr_utf8('ai\'2145m a ch3我[是一,個,和哈,哦也,,國家!',12);
echo '<br />',cn_substr_utf8('【我,是一,個,和哈,哦也,,國家!',12);
echo '<br />',cn_substr_utf8('我是一,個,和哈,哦也,,國家!',12);
echo '<br />',cn_substr_utf8('我是,一,個,和哈,哦也,,國家!',12);
echo '<br />',cn_substr_utf8('我,是,一,個,和哈,哦也,,國家!',12);
echo '<br />',cn_substr_utf8('我是asd一,個,和哈,哦也,,國家!',12);
echo '<br />',cn_substr_utf8('【我i\'m[是一,個,和哈,哦也,,國家!',12);
echo '<br />',cn_substr_utf8('【i\'m a ch我[是一,個,和哈,哦也,,國家!',12);
echo '<br />',cn_substr_utf8('【i\'2145m a ch3我[是一,個,和哈,哦也,,國家!',12);
下面是精確截取字符串的效果圖:
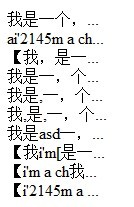
具體函數代碼如下:
//utf-8中文截取,單字節截取模式
function cn_substr_utf8($str,$length,$append='...',$start=0){
if(strlen($str)<$start+1){
return '';
}
preg_match_all("/./su",$str,$ar);
$str2='';
$tstr='';
//www.phpernote.com
for($i=0;isset($ar[0][$i]);$i++){
if(strlen($tstr)<$start){
$tstr.=$ar[0][$i];
}else{
if(strlen($str2)<$length + strlen($ar[0][$i])){
$str2.=$ar[0][$i];
}else{
break;
}
}
}
return $str==$str2?$str2:$str2.$append;
}
如果大家認為還不夠准確大家可以在此基礎上進行改進,或者是創新,希望這篇關於php截取字符串長度函數的文章對大家的學習有所幫助。