Beautiful Soup是一個用來解析HTML和XML的python庫,它可以按照你喜歡的方式去解析文件,查找並修改解析樹。它可以很好的處理不規范標記並生成剖析樹(parse tree). 它提供簡單又常用的導航(navigating),搜索以及修改剖析樹的操作。
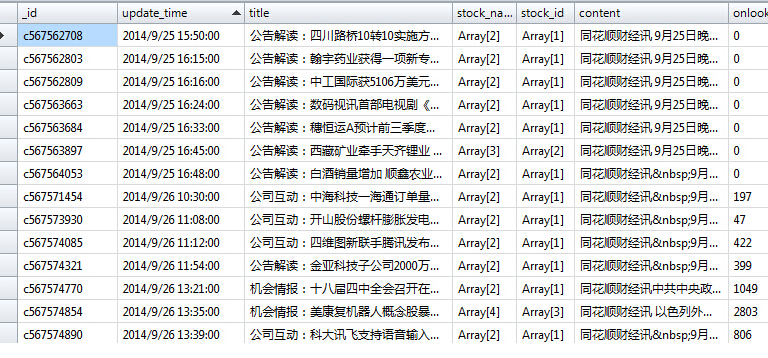
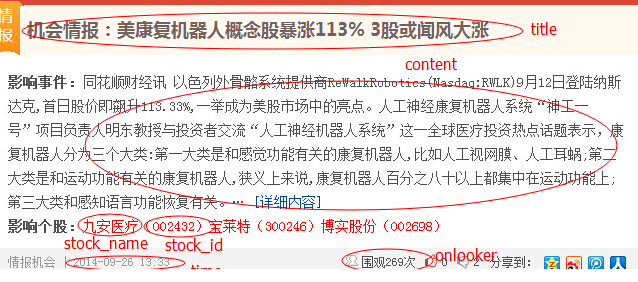
如圖使用urllib2與BS4模塊爬取html頁面數據,分別為標題、內容、股票名稱、股票ID、發布時間、圍觀人數。
Example:
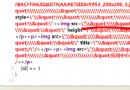
代碼如下##-coding:utf-8-##
import time
from bs4 import BeautifulSoup
import urllib2
import pymongo
import re
import datetime
def update():
datas = {}
connection = pymongo.Connection('192.168.1.2', 27017)
#連接mongodb
db = connection.test_hq
#創建或連接test_hq庫
for i in soup.find_all("div", class_="item"):
datas['_id'] = str(i.h2.a['href']).split('/')[-1].split('.')[0]
#獲取html頁面名稱為id號
datas['title'] = i.h2.get_text()
#獲取標題
url2 = i.h2.a['href']
#獲取標題內容url地址
html2 = urllib2.urlopen(url2)
html_doc2 = html2.read()
soup2 = BeautifulSoup(html_doc2)
datas['content'] = soup2.find(attrs={"name":"description"})['content']
#獲取文章內容
stock_name = []
stock_id = []
for name in re.findall(u"[u4e00-u9fa5]+",i.find(class_="stocks").get_text()):
stock_name.append(name)
#獲取影響股票名稱,已數組方式保存對應股票id號,mongo支持數組插入
datas['stock_name'] = stock_name
for id in re.findall("d+",i.find(class_="stocks").get_text()):
stock_id.append(id)
#獲取影響股票id
datas['stock_id'] = stock_id
datas['update_time'] = datetime.datetime.strptime(re.search("w+.*w+", i.find(class_="fl date").span.get_text()).group(), '%Y-%m-%d %H:%M') - datetime.timedelta(hours=8)
#獲取發布時間,轉換為mongo時間格式
datas['onlooker'] = int(re.search("d+",i.find(class_="icons ic-wg").get_text()).group())
#獲取圍觀數
db.test.save(datas)
#插入數據庫
def get_data():
title = str(soup.h2.a['href']).split('/')[-1].split('.')[0]
#獲取html頁面名稱做更新判斷
with open('update.txt', 'r') as f:
time = f.readline()
if title == time:
print 'currently no update', title
else:
with open('update.txt', 'w') as f:
f.write(title)
update()
while True:
if __name__ == '__main__':
url = 'http://www.ipython.me/qingbao/'
html = urllib2.urlopen(url)
html_doc = html.read()
soup = BeautifulSoup(html_doc)
get_data()
time.sleep(30)
#每30秒刷新一次