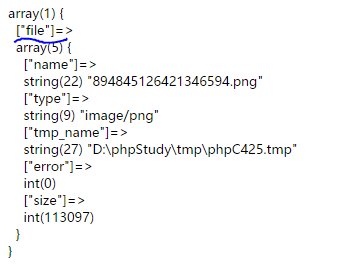
PHP的Hash采用的是目前最為普遍的DJBX33A (Daniel J. Bernstein, Times 33 with Addition), 這個算法被廣泛運用與多個軟件項目,Apache, Perl和Berkeley DB等。對於字符串而言這是目前所知道的最好的哈希算法,原因在於該算法的速度非常快,而且分類非常好(沖突小,分布均勻)
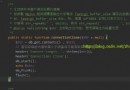
Hash Table是PHP的核心,這話一點都不過分。 PHP的數組,關聯數組,對象屬性,函數表,符號表,等等都是用HashTable來做為容器的。 PHP的HashTable采用的拉鏈法來解決沖突, 這個自不用多說, 我今天主要關注的就是PHP的Hash算法, 和這個算法本身透露出來的一些思想。 PHP的Hash采用的是目前最為普遍的DJBX33A (Daniel J. Bernstein, Times 33 with Addition), 這個算法被廣泛運用與多個軟件項目,Apache, Perl和Berkeley DB等. 對於字符串而言這是目前所知道的最好的哈希算法,原因在於該算法的速度非常快,而且分類非常好(沖突小,分布均勻). 算法的核心思想就是: 代碼如下: hash(i) = hash(i-1) * 33 + str[i] 在zend_hash.h中,我們可以找到在PHP中的這個算法: 代碼如下: static inline ulong zend_inline_hash_func(char *arKey, uint nKeyLength) { register ulong hash = 5381; /* variant with the hash unrolled eight times */ for (; nKeyLength >= 8; nKeyLength -= { hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; hash = ((hash << 5) + hash) + *arKey++; } switch (nKeyLength) { case 7: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 6: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 5: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 4: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 3: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 2: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */ case 1: hash = ((hash << 5) + hash) + *arKey++; break; case 0: break; EMPTY_SWITCH_DEFAULT_CASE() } return hash; } 相比在Apache和Perl中直接采用的經典Times 33算法: 代碼如下: hashing function used in Perl 5.005: # Return the hashed value of a string: $hash = perlhash("key") # (Defined by the PERL_HASH macro in hv.h) sub perlhash { $hash = 0; foreach (split //, shift) { $hash = $hash*33 + ord($_); } return $hash; } 在PHP的hash算法中, 我們可以看出很處細致的不同. 首先, 最不一樣的就是, PHP中並沒有使用直接乘33, 而是采用了: 代碼如下: hash << 5 + hash 這樣當然會比用乘快了. 然後, 特別要主意的就是使用的unrolled, 我前幾天看過一片文章講Discuz的緩存機制, 其中就有一條說是Discuz會根據帖子的熱度不同采用不同的緩存策略, 根據用戶習慣,而只緩存帖子的第一頁(因為很少有人會翻帖子). 於此類似的思想, PHP鼓勵8位一下的字符索引, 他以8為單位使用unrolled來提高效率, 這不得不說也是個很細節的,很細致的地方. 另外還有inline, register變量 … 可以看出PHP的開發者在hash的優化上也是煞費苦心 最後就是, hash的初始值設置成了5381, 相比在Apache中的times算法和Perl中的Hash算法(都采用初始hash為0), 為什麼選5381呢? 具體的原因我也不知道, 但是我發現了5381的一些特性: 代碼如下: Magic Constant 5381: 1. odd number 2. prime number 3. deficient number 看了這些, 我有理由相信這個初始值的選定能提供更好的分類.