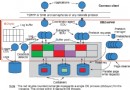
基於DB2及PHP的應用系統跨平台遷移 實例講解
本文主要介紹如何完成基於 DB2 的 PHP 應用系統從 AIX 平台到 Linux 平台的移植過程。文中包含了底層的 DB2 數據庫移植、上層的 PHP 應用系統移植的詳細步驟以及移植過程中可能遇到的問題和解決方法。
任務概述
系統遷移的工作主要分為以下幾個方面:
1.DB2 數據庫系統的跨平台遷移
2.apache 服務器與 PHP 應用系統的安裝和配置
下面我們就分 2 個方面分別介紹遷移和配置的具體步驟。
DB2 數據庫系統的跨平台遷移
數據庫環境
源環境:AIX+DB2 v8.1
目標環境:Linux+DB2 v8.1
其中源數據庫中包含了 2 個數據庫 Instance:SRCDB1 與 SRCDB2。在 SRCDB1/SRCDB2 數據庫中,均包含了上百張數據庫表,並有很多的索引、外鍵約束、觸發器、存儲過程以及一些含有自增字段的表(含有 GENERATED ALWAYS AS IDENTITY 定義字段的表)。更為困難的是,我們並沒有關於這些數據庫對象的准確創建腳本。
遷移方案的選擇
如果遷移的源系統與目的系統屬於同一類型操作系統,例如 Linux 之間的遷移,或者 AIX 系統之間的遷移,則情況相對簡單,DB2 本身已經提供相關的實用工具來實現這種同類型平台之間的數據庫移植,如: BACKUP 和 RESTORE 命令。當然,根據不同的情況還需要對實用工具所提供的參數有比較清楚的了解,譬如源系統與目標系統使用不同的表空間,就會涉及到表空間重定向的問題。由於本文的重點在於跨平台的移植,這種方案顯然無法滿足需求,在此不再熬述。
那麼,如何處理跨平台的數據庫遷移問題?是不是可以使用實用工具 db2move 呢? db2move 只能遷移表中的數據,而無法對索引、外鍵約束、觸發器和存儲過程等數據庫對象也實現遷移操作,而且對於包含自增字段數據的表來說,db2move 也有一定的限制。並且 db2move 只能把數據導入到已存在的數據庫的表中,無法顯示指定表空間的位置。由於在數據庫的系統遷移過程中,不僅需要遷移表中的數據,還有索引、外鍵約束、觸發器和存儲過程等數據庫對象,與本文所選方案相比,還是後者更具優勢。可以將 db2move 僅作為遷移表數據的一種備用方案。
而對於 export 和 import 來說,一次只能針對一張表進行導出導入操作,並且需要手動輸入 export 和 import 的命令以及需要導入導出的數據表名,在數據庫表的數量不多的情況下,這種方案也許還可以考慮,但也不並是最佳的方案。而在數據庫中表數量眾多的情況下,這種做法則是基本不現實的,而且 import 命令並不能保證自增字段的數據與原來的表數據保持一致。
本文根據 DB2 對數據庫對象的處理機制,采用將 db2look 與 DDL、DML 腳本相結合的方式,並針對原數據庫中的觸發器、存儲過程以及外鍵約束等分別處理,給出了一種跨平台 DB2 數據庫系統移植的可行方案。
下面我們以 SRCDB1 為例介紹一下這種情況下的數據庫整體遷移過程。SRCDB1 數據庫中有 SRCDB1、ASN、DB2DBG 和 SQLDBA 這四個數據庫模式。假設 SRCDB1 數據庫的用戶名為 user_srcdb1,密碼:pw_srcdb1。
在源系統 (AIX) 上的相關操作
1.使用 db2look 命令抽取生成數據庫對象的 DDL 腳本
清單 1. db2look 命令及參數
# db2look -d SRCDB1 -e -o srcdb1.ddl -a -i user_srcdb1 -w pw_srcdb1
db2look :生成 DDL 以便重新創建在數據庫中定義的對象
語法: db2look -d DBname [-e] [-u Creator] [-z Schema]
[-t Tname1 Tname2...TnameN] [-tw Tname] [-h] [-o Fname] [-a]
[-m] [-c] [-r] [-l] [-x] [-xd] [-f] [-fd] [-td x]
[-novIEw] [-i userID] [-w passWord]
[-v Vname1 Vname2 ... VnameN] [-wrapper WrapperName]
[-server ServerName] [-nofed]
-d : 數據庫名稱,必選參數
-e : 抽取復制數據庫所需要的 DDL 文件,此選項將生成包含 DDL 語句的腳本
-o : 將輸出重定向到給定的文件名,如果未指定 -o 選項,則輸出默認轉到 stdout
-a : 為所有創建程序生成統計信息,如果指定了此選項,則將忽略 -u 選項
-i : 指定登錄到數據庫所在服務器時所使用的用戶標識
-w : 指定登錄到數據庫所在服務器時所使用的密碼
2.根據不同類型對象,分化數據庫對象 DDL 腳本
由於源數據庫中的各個表數據已經是經過觸發器、存儲過程等數據庫對象處理過的數據,為保證數據庫中數據的一致性和完整性,這些數據庫對象應該在導入數據後再創建,以防止在導入表數據時重復執行觸發器和存儲過程等數據庫對象生成錯誤數據。使用文本編輯器編輯由 db2look 生成的 srcdb1.ddl,將創建表及索引的 DDL 語句,創建外鍵約束的 DDL 語句以及創建觸發器和創建存儲過程的語句分為四組,分別保存為下面四個 DDL 腳本:
srcdb1_tables.ddl srcdb1_forIEgnkeys.ddl
srcdb1_triggers.ddl srcdb1_procedures.ddl
srcdb1_tables.ddl :包含創建 SEQUENCE,UDF,TABLE,VIEW 等數據庫對象的 ddl 語句。
清單2. srcdb1_tables.ddl 語句
CREATE SEQUENCE "SRCDB1"."SAMPLE_SEQ_1" AS INTEGER
MINVALUE 1 MAXVALUE 9999999999
START WITH 1 INCREMENT BY 1;
CREATE FUNCTION " SRCDB1"." SAMPLE _FUNC_1"
(
VARCHAR(254),
VARCHAR(254),
VARCHAR(254)
) RETURNS VARCHAR(254)
SPECIFIC SAMPLE _FUNC_1 ……;
CREATE TABLE " SRCDB1"." SAMPLE _TAB_1" (
"TAB_COL1" CHAR(20) NOT NULL ,
"TAB_COL2" VARCHAR(70) NOT NULL ) ;
CREATE TABLE " SRCDB1"." SAMPLE _TAB_2" (……);
……
CREATE TABLE " SRCDB1"." SAMPLE _TAB_N" (……);
CREATE VIEW SRCDB1.SAMPLE_VIEW_1 (VIEW_COL1,VIEW_COL2) AS SELECT distinct
COL1 , COL2 FROM SAMPLE_TAB WHERE ……;
CREATE VIEW SRCDB1.SAMPLE_VIEW_2 ……;
……
CREATE VIEW SRCDB1.SAMPLE_VIEW_N ……;
srcdb1_forIEgnkeys.ddl :包含創建外鍵約束的 ddl 語句。
清單3. srcdb1_forIEgnkeys.ddl 語句
ALTER TABLE " SRCDB1"."SAMPLE_FK_1"
ADD CONSTRAINT "SQL030903143850120" FOREIGN KEY
("FK_COL1")
REFERENCES " SRCDB1"."SAMPLE_TABLE"
("COL1");
ALTER TABLE " SRCDB1"."SAMPLE_FK_2" ADD ……;
……
ALTER TABLE " SRCDB1"."SAMPLE_FK_N" ADD ……;
srcdb1_triggers.ddl :包含創建觸發器的 ddl 語句。
清單 4. srcdb1_triggers.ddl 語句
CREATE TRIGGER SRCDB1.SAMPLE_TRIG_1 AFTER UPDATE OF col1 ON SRCDB1.SAMPLE_TAB
REFERENCING NEW AS n FOR EACH ROW MODE DB2SQL WHEN ( n.col1 > 3)
BEGIN ATOMIC
update SAMPLE_TAB
set(col2) = 'anotherValue' where col1 = n.col1 ;--
END;
CREATE TRIGGER SRCDB1. SAMPLE_TRIG_2 ……;
……
CREATE TRIGGER SRCDB1. SAMPLE_TRIG_N ……;
srcdb1_procedures.ddl :包含創建 SQL 存儲過程以及 Java 存儲過程的 ddl 語句。
清單 5. srcdb1_procedures.ddl語句
CREATE PROCEDURE " SRCDB1"." Java_PROCEDURE_1"
(
OUT SQLSTATE CHARACTER(5),
OUT ROWS_SUBMITED INTEGER,
IN BATCH_ID INTEGER,
IN LEVEL VARCHAR(4000)
)
DYNAMIC RESULT SETS 0
SPECIFIC SUBMIT_BATCH
EXTERNAL NAME 'Submit_batch!submit_batch'
LANGUAGE Java
PARAMETER STYLE Java
NOT DETERMINISTIC
FENCED THREADSAFE
MODIFIES SQL DATA
NO DBINFO;
CREATE PROCEDURE " SRCDB1"."Java_PROCEDURE_2" ……;
……
CREATE PROCEDURE " SRCDB1"."Java_PROCEDURE_N" ……;
SET CURRENT SCHEMA = " SRCDB1";
SET CURRENT PATH = "SYSIBM","SYSFUN"," SRCDB1";
CREATE PROCEDURE SRCDB1.SQL_PROCEDURE_1 (
IN hostname varchar(4000),
IN username varchar(4000),
OUT SQLCODE_OUT int )
SPECIFIC SRCDB1.SQL_PROCEDURE_1
LANGUAGE SQL
-------------------------------------------------
-- SQL Stored Procedure
-------------------------------------------------
P1: BEGIN
……
END P1 ;
CREATE PROCEDURE SRCDB1.SQL_PROCEDURE_2 ……;
……
CREATE PROCEDURE SRCDB1.SQL_PROCEDURE_N ……;
需要注意的是,db2 v6 版本的 db2look 尚未實現抽取如 UDF,TRIGGER,UserSpace,NodeGroup,BufferPool 等數據庫對象的 ddl 語句。從 db2 v7 開始,db2look 可以抽取上述對象的 DDL,但是依然無法抽取創建存儲過程對象的 ddl 語句。從 db2 v8.2 開始,完善了對 db2look 功能的支持,實現了存儲過程 ddl 語句的抽取功能。由於本文所涉及的源數據庫系統的版本較低(DB2 v8.1),因此需要采取上述方案獲取所有數據庫對象的 DDL 信息:
1). 從某個 DB2 v8.2 系統對 SRCDB1(DB2 v8.1 版本)執行 CATALOG 操作:
db2 catalog db SRCDB1 as SRCDB1;
2). 從 DB2 v8.2 系統對 SRCDB1 進行 db2look 抽取過程:
db2look -d SRCDB1 -e -o srcdb1.ddl -a -i user_srcdb1 -w pw_srcdb1;
這樣就可以獲取完整的數據庫對象 DDL 信息。
3.生成數據導出export腳本
使用 shell 腳本生成並導出所有數據的 DML 腳本,並將其重定向到 srcdb1_export.sql 文件中。對於熟悉 DB2 的用戶來說,應該知道數據庫中創建的每個表、視圖、別名均對應 SYSCAT.TABLES 中一行記錄。因此可以通過相應的數據庫 select 語句就可以獲取所有需要的數據庫表信息。根據需要,下述 shell 腳本將從系統表 SYSCAT.TABLES 中根據 tabname 字段選出 SRCDB1 中所有 tabschema 表模式是 SRCDB1,ASN,SQLDBA,DB2DBG 的表名字,並根據它們的名字生成相應的 export 導出語句,到達批量導出的目的。rtrim 函數用於去除 tabname 字段數據的右邊的空格。
清單6. 生成export腳本
# db2 "select 'export to ' || rtrim(tabname) || '.ixf of ixf select * from ' ||
rtrim(tabname) || ';' from syscat.tables
where tabschema in('SRCDB1', 'ASN', 'SQLDBA', 'DB2DBG')" > srcdb1_export.sql ;
編輯生成的 srcdb1_export.sql,刪除頭部和尾部所顯示的統計信息,只保留必要的 export 語句。通過修改上述腳本中所包含的 tabschema 信息,可以指定需要導出的表的范圍,也即遷移過程中需要的所有表名。所生成的 export 導出語句具有如下的命令形式:
db2 export to tablename.ixf of ixf select * from tablename;
4.生成數據導入 load 腳本
使用 shell 腳本生成 load 腳本用於將數據導入目標系統:srcdb1_load.sql
清單7. 生成 load 腳本
# db2 "select 'load from ' || rtrim(tabname) || '.ixf of ixf insert into ' ||
rtrim(tabname) || ';' from syscat.tables
where tabschema in ('SRCDB1', 'ASN', 'SQLDBA', 'DB2DBG')" > srcdb1_load.sql;
編輯生成的 srcdb1_load.sql,刪除頭部和尾部的統計信息,只保留必要的 load 語句。與 export 導出語句類似,上述 shell 腳本從系統表中選出 SRCDB1 中所有表的名字,並根據它們的名字生成相應的 import 導入語句,到達批量導入的目的。所生成的 import 導入語句命令形式如下:
db2 load from tablename.ixf of ixf insert into tablename;
5.處理數據庫表中的自增字段
對於需要加載的含有自增字段的表,即該表的 ixf 數據文件中有自增列的值, 可以在 load 命令中加入如下參數控制自增字段值:
1). modifIEd by identityignore :加載的數據文件中有自增字段值,load 時忽略數據文件中自增字段值 ;
2). modifIEd by identitymissing :加載的數據文件中沒有自增字段值,load 時自動生成自增字段值 ;
3). modifIEd by identityoverride :加載的數據文件中有自增字段值,load 時使用數據文件中的自增字段值 。
為了使目標數據庫中含有自增字段的表中數據與源數據庫中的數據保持一致,本文實例中選擇使用 modifIEd by identityoverride 參數,在導入數據時使用數據文件中的自增字段值。讀者可以根據不同情況選擇適當的控制參數。
首先,在 srcdb1_tables.ddl 文件中查找所有包自增字段的表名 ( 含有 GENERATED ALWAYS AS IDENTITY 字段的表 ),然後在 srcdb1_load.sql 中將 modifIEd by identityoverride 語句片段插入到這些含有自增字段的表所對應的 load 命令行中。
清單8. load 腳本中自增字段處理
db2 load from test.ixf of ixf modifIEd by identityoverride insert into TEST;
6.執行導出腳本
執行導出腳本,導出所有表的數據 。
# db2 -tvf srcdb1_export.sql
導出的表數據以 ixf 格式存放於當前路徑下。
7.保存腳本和數據文件
將所有 DDL 腳本以及數據文件 *.ixf 復制到目標系統所在站點。
Linux 系統上的操作
1.通過命令行處理器(CLP)創建實例 SRCDB1:
# db2icrt SRCDB1
2.使用 CREATE DATABASE 命令創建數據庫 SRCDB1,創建必要的表空間及配置必要的數據庫參數。
# db2 create database SRCDB1
3.連接到數據庫 SRCDB1,執行 srcdb1_tables.ddl 腳本創建緩沖池,表空間,UDF,表以及 Index,Sequence,視圖等數據庫對象。
# db2 connect to srcdb1
# db2 -tvf srcdb1_tables.ddl
4.進入到放置 .ixf 數據文件的目錄,執行下面的命令導入表數據。
# db2 -tvf srcdb1_load.sql
5.使用 srcdb1_forIEgnkeys.ddl,srcdb1_triggers.ddl ,srcdb1_procedures.ddl 腳本文件創建外鍵約束,觸發器和存儲過程。
# db2 -tvf srcdb1_forIEgnkeys.ddl
# db2 -tvf srcdb1_triggers.ddl
# db2 -tvf srcdb1_procedures.ddl
成功完成上述步驟後,數據庫的遷移工作基本完成。
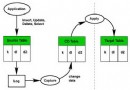
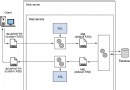
apache 服務器與 PHP 的安裝和配置
apache 服務器的安裝和配置
Apache HTTP 服務器是一個模塊化的軟件,管理員可以通過選擇服務器中包含的模塊進行功能增減。模塊可以在編譯時被靜態包含進httpd二進制文件,也可以編譯成獨立於httpd二進制文件的動態共享對象 (DSO)。DSO 模塊可以與服務器一起編譯,也可以用 Apache 擴展工具 (apxs) 單獨編譯。動態加載的方式相比靜態加載具有更高的靈活性。使用動態載入特性,apache 服務器必須以動態共享對象(DSO,Dynamic Shared Object)的方式編譯。Apache 對 DSO 的支持,是基於一個叫 mod_so 的模塊來實現的,為支持動態加載方式,這個模塊必須預先被靜態編譯到內核中。因此可以通過 mod_so 模塊檢測已安裝的 apache 是否支持 DSO:
清單9. mod_so 模塊檢測
# $apacheHOME/bin/httpd –l
Compiled in modules:
core.c
prefork.c
http_core.c
mod_so.c
如果在列出的模塊名中有 mod_so.c,則說明安裝的 Apache 已經支持 DSO,否則需要重新編譯 Apache。apache 的安裝和配置過程十分簡單,如下所示:
1.下載 httpd-2.0.54.tar.gz(http://httpd.apache.org/),並將其解壓到制定目錄
# tar zxvf httpd-2.0.54.tar.gz && cd httpd-2.0.54
2.編譯安裝 apache
# ./configure --prefix=/usr/local/apache2 --enable-module=so
-- prefix 指定 apache 的安裝路徑
--enable-module=so 將 so 模塊(mod_so)靜態編譯進 apache 服務器的內核,以支持 DSO 模式
# make && make install
3. 啟動 apache
# ln -s /usr/local/apache2/bin/apachectl /sbin/apachectl
# apachectl start
PHP 的安裝和配置
在 php 的安裝和配置過程中,有兩個方面需要注意,首先是 php 與 apache http server 的結合,其次是 PHP 與 db2 數據源的連接。
在 apache 環境下安裝 PHP 的時候,有三種安裝模式可供選擇:靜態模塊、動態模塊(DSO)和 CGI。建議以 DSO 模式安裝,這種模式的維護和升級都相對簡單,可以在無需重新編譯 Apache 的條件下,根據需求動態增加新功能模塊。當然,這樣做也會帶來一些運行效率上的下降,apache 服務器在啟動時會慢約 20%。
PHP 連接 DB2 數據源同樣有三種方式 : unifIEd ODBC driver、IBM_DB2 和 PDO(PHP data object)。
◆unifIEd ODBC driver 是最早的 PHP 訪問數據庫的擴展模塊之一。從 DB2 v7.2 開始,unified ODBC driver 就支持對其的訪問。對所有支持 ODBC 的數據庫,unified ODBC driver 提供了統一的數據訪問接口。為了保證接口的一般性,unifIEd ODBC driver 並未對不同類型的數據庫做特定的優化。
◆IBM_DB2 是由 IBM 開發和維護的與 DB2 數據源交互的擴展模塊,它遵守開源協議。對基於 DB2 UDB 和 PHP 4.x 的應用來說,IBM_DB2 是最優的選擇,因為它針對 DB2 UDB 進行了優化,同時避免了一些使用 unifIEd ODBC driver 時可能存在的兼容性問題。不過,IBM_DB2 只支持 DB2 v8.2.2 或更高版本。
◆PDO 則是 PHP 5.x 中即將支持的新的數據庫訪問方式。本文中,由於源數據庫與目標數據庫的版本均為 DB2 v8.1,並且源環境中采用 unified ODBC driver 的方式,為了保持環境配置的一致性,仍然選擇 unifIEd ODBC driver 作為 PHP 與數據源的訪問接口。
PHP 的安裝與配置過程具體如下:
1.下載並解壓 php-4.4.4.tar.gz(http://www.PHP.Net/)
# tar zxvf PHP-4.4.4.tar.gz
# cd PHP-4.4.4
2.配置編譯 PHP 源代碼
# ./configure --prefix=/usr/local/PHP --with-apxs2=/usr/sbin/apxs --without-MySQL --with-ibm-db2=/home/reportdb/sqllib
--prefix 指定 PHP 的安裝路徑
--with-apxs2 指定 apxs 程序的路徑 (apxs 是一個 perl 腳本,它可以脫離 apache 的源碼將 PHP 模塊編譯成 DSO 文件 )
--with-ibm-db2 指定 unifIEd ODBC driver 作為 PHP 與數據源的訪問接口,並指定 DB2 的實例安裝目錄。
--without-mysql 忽略 MySQL 數據庫缺省的安裝配置
#cp PHP.ini-dist /usr/local/lib
將 php 安裝文件中的 php.ini-dist 拷貝到 /usr/local/lib 下作為 PHP 的配置文件。
# make && make install
# cp php.ini-dist /usr/local/lib/PHP.ini
3.編輯 /usr/local/apache2/conf/httpd.conf 文件,做如下修改:
設置 Html 文件主目錄:用於存放網站所需 web 文件的主目錄
DocumentRoot "/home/web/www/"
設置 apache 的默認文件名的次序: apache 將按照由前至後的順序在當前路徑下查找其所支持的默認主頁文件
DirectoryIndex index.PHP index.html.var index.CGI index.Html
添加 php 解釋文件後綴:對於所有需要被 PHP 解釋的文件類型,需要將後綴添加至 AddType 配置項
AddType application/x-httpd-php .PHP .inc
加載 PHP 模塊:加載模塊目錄 modules 下的庫 libphp4.so,並將模塊結構名 PHP4_module 添加到活動模塊列表中
LoadModule php4_module modules/libPHP4.so
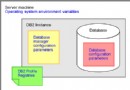
4.編輯配置文件 /usr/local/apache2/bin/apachectl :
為保證與 DB2 數據庫的連通,啟動 apache 服務時,需要同時初始化 DB2 客戶機實例環境。創建 DB2 實例時,DB2 會自動生成 shell 腳本用於初始化所需的 DB2 實例環境,只需直接調用即可:
if test -f /home/reportdb/sqllib/db2profile; then
. /home/reportdb/sqllib/db2profile
fi
5.然後,重新啟動 apache 服務器以繼承上面的配置更改。
# apachectl restart
6.編寫 PHP 的測試文件 test.PHP,內容如下:
echo PHPinfo();
?>
將其存放在 apache 的 Html 文件主目錄 /home/web/www 下,通過浏覽器訪問該網頁,若能正常訪問,則配置工作全部完成。
結束語
本文主要涵蓋了一個基於 php 和 DB2 UDB 的應用系統的跨平台移植過程,詳細介紹了 DB2 數據庫系統的跨平台遷移以及 apache 服務器與 PHP 應用系統的安裝和配置過程。基於實踐經驗,為 DB2 數據庫系統的跨平台遷移問題提供了一個可行的解決方案。對於移植過程中可能出現的問題,本文也給予詳細的描述並提供相應的解決方案。雖然本文所涉及的只是從 AIX 系統到 Linux 系統的應用系統移植過程,讀者亦可以參考具體的移植過程,將其應用於其它平台之上。