如果漫不經心,什麼東西也照顧不好。房子、汽車、寵物、朋友和家庭都需要我們加以關注才能保持良好的狀態,數據庫管理系統也是如此。
如果不加以注意和照料,DBMS 會支離破碎,性能下降,最終由於運行成本太高而不得不關閉。保持最新的維護級別以利用技術改進是一回事兒,而應用正確的技術是另一回事兒。本文討論通過適當地維護系統、使用適當的工具和注意細節降低 DB2 運行成本的五種方法。
1. 使用適當的 SQL —— 確保您知道它的作用
編寫產生所需結果的查詢有許多方法;關鍵是要找到能夠發揮您的 DBMS 的長處的方法。這看似簡單,但是並不容易實現,因為可用的工具和技術會隨著時間改變。
幾年前,我的一個客戶繼承了一個客戶關系管理 (CRM) 應用程序,它已經移植到 DB2 for z/OS Version 8 子系統上了。有一個程序給公司的 IBM System z9 造成了很大的負擔,它每天占用全部 CPU 周期的 25%。這個程序有 10 個 CREATED Global Temporary Tables,其中大多數嵌入在遞歸的 SQL 語句中。根據銷售鏈的深度不同,其中六個臨時表包含 10,000 到 100,000 行,而且程序反復訪問它們。
但是,在 DB2 for z/OS 上有另一種 Global Temporary Table:DECLARED。在 DB2 9 之前,CREATED 臨時表無法使用任何索引技術,但是 DECLARED 表可以。因此,我建議客戶把六個 CREATED 臨時表改為帶聚簇索引的 DECLARED 臨時表。余下的四個 CREATED 臨時表是合適的,因為它們只包含很少的行,而且程序只訪問它們一次。這一改動把完成每個事務所需的時間從 1.78 秒降低到了 0.07 秒,考慮到這個程序每天至少執行 6,000 次,改進的效果相當顯著。一個小小的改動就能每天節省 2.8 個 CPU 小時。效果如此驚人以致於客戶的高級 DBA 開玩笑說他們用不著新的 z9 了,想要退貨!
這發生在三年前。目前,這個客戶使用 DB2 9,DB2 9 會自動地在反復訪問的工作文件(包括臨時表)上生成稀疏索引。但是,這種改進的機會隨時都會出現。SQL 是一個 “移動的靶子”,必須及時掌握新的發展:在 1983 年剛誕生時,DB2 SQL 是一種非常粗糙的查詢語言,當時只支持內聯結、子查詢、GROUP BY 子句、HAVING 子句、ORDER BY 子句和大約 21 個內置函數。27 年後的今天,DB2 9 for z/OS 可以使用的 SQL 特性已經極其豐富了(見邊欄 “DB2 SQL 已經成熟了”)。
一些 SQL 特性作用相同,但是大多數特性提供獨特的功能。一定要及時了解並充分利用新特性,因為許多新特性可以提高性能和降低應用程序運行成本。
DB2 SQL 已經成熟了
當最初引入 DB2 SQL 時,只能使用很少幾個功能。現在,可以選用的特性非常多:
TABLE EXPRESSIONS, COMPLEX CORRELATION, GLOBAL TEMPORARY TABLES, CASE, 100+ BUILT-IN FUNCTIONS, LIMITED FETCH, SCROLLABLE CURSORS, UNION EVERYWHERE, MIN/MAX SINGLE INDEX SUPPORT, SELF REFERENCING UPDATES WITH SUBQUERIES, SORT AVOIDANCE FOR ORDER BY, AND ROW EXPRESSIONS, 2M STATEMENT LENGTH, GROUP BY EXPRESSION, SEQUENCES, SC ALAR FULLSELECT, MATERIALIZED QUERY TABLES, COMMON TABLE EXPRESSIONS, RECURSIVE SQL, CURENT PA CKAGE PA TH, VOLATILE TABLE SUPPORT, STAR JOIN SPARSE INDEX, QUALIFIED COLUMN NAMES, MULTIPLE DISTINCT CLAUSES, IS NOT DISTINCT FROM, ON COMIT DROP, TRANSPARENT ROWID COLUMN, GET DIAGNOSTICS, STAGE1 UNLIKE DATA TYPES, MULTI-ROW INSERT, MULTI-ROW FETCH, DYNAMIC SCROLLABLE CURSORS, MULTIPLE CCSIDS PER STATEMENT, ENHANCED UNICODE, AND PARALLEL SORT, TRUN CATE, DECIMAL FLOAT, VARBINARY , OPTIMISTIC LOCKING, FETCH CONTINUE, MERGE, CALL FROM TRIGG ER, STATEMENT ISOLATION, FOR READ ONLY KEEP UPDATE LOCKS, SET CURENT SCHEMA, CLIENT SPECIAL REGISTERS, LONG SQL OBJECT NAMES, SELECT FROM INSERT, UPDATE, DELETE, MERGE, INSTEAD OF TRIGGER, NATIVE SQL PROCEDURE LANGUAGE, BIGINT, FILE REFERENCE VARIABLES, XML, FETCH FIRST & ORDER BY IN SUBSELECT AND FULLSELECT, CASELESS COMPARISONS, INTERSECT, EXCEPT, NOT LOGGED TABLES
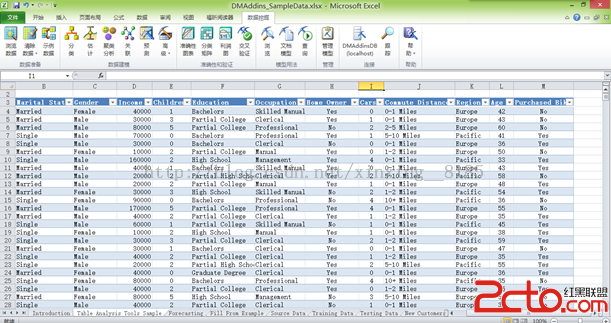
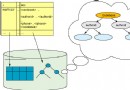
搜索靜態和動態 SQL 的關鍵字是衡量生產 SQL 集合的水平的有效方法。圖 1 和圖 2 是通過搜索在客戶當前的生產環境中運行的 SQL 生成的 SQL 報告卡。客戶 XYZ 在 3,000 個財務報告應用程序中只使用很少幾種 SQL 技術。它用基本 SQL 實現應用程序中執行的幾乎所有關系業務規則和篩選,而沒有利用高性能 SQL 函數。
圖 1. 客戶 XYZ 的 SQL 報告卡(DB2 7 for z/OS)
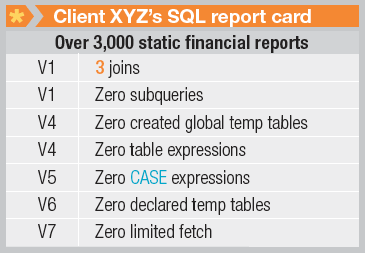
圖 2. 客戶 ABC 的 SQL 報告卡(DB2 8 for z/OS)
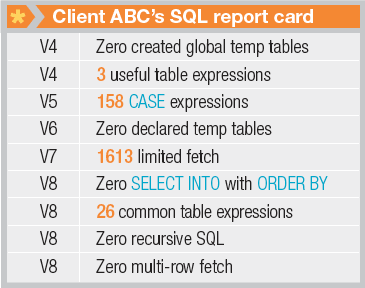
客戶 ABC 的 SQL 報告卡要好得多,但是仍然沒有實現帶 ORDER BY 的 SELECT INTO 和多行抓取。這些特性通常可以分別降低 CPU 需求 30% 和 50%。對於多次執行的許多查詢,客戶 ABC 仍然使用陳舊的單行抓取而不是最新技術。他們需要提高 SQL 編寫技巧,從而讓最新技術在生產環境中發揮作用。
遷移到 DB2 9 之後,您可以使用許多新特性,包括:
TRUNCATE、
MERGE
SELECT FROM UPDATE/DELETE/MERGE
EXCEPTINTERSECT、DENSE_RANK、ROW_NUM
RANK
子選擇中的 ORDER BY / FETCH FIRST
如果不使用這些特性(尤其是在數據倉庫環境中),就需要使用外部工具提供所需的功能。這會增加許可證費等成本,還會顯著影響性能,因為許多工具需要把數據傳輸到 DB2 之外進行處理。(評估 SQL 集合所用的搜索還可以用來判斷將要購買的應用程序包是否使用了高級特性。)
2. 創建最優的索引設計
基本的表索引是防止性能問題的第一道防線。最常用或最重要的事務和服務應該有適當的索引,能夠支持所需的所有聯結、篩選和排序任務。篩選和聯結都需要大量資源,缺少索引會嚴重影響這些操作的性能。
請考慮以下場景:一家公司有一個供其客戶訪問的網頁,當客戶登錄時按共同的模式執行一系列服務並存儲結果,這樣當客戶單擊相關的選項卡時就可以方便地顯示結果。這種流行的 “P-Search” 架構讓客戶能夠快速訪問常用的功能,但是如果執行的服務沒有使用適當的索引,這種策略的開銷會很高。
對於這家公司,P-Search 服務在 IBM System z10 上在 DB2 方面花費的時間原來是 9.9 CPU 秒;在高峰時間段,客戶要等待 10 到 40 秒才能看到網頁。這個 P-Search 服務包含一個動態的查詢,它是消耗 CPU 的主要部分:一個簡單的對 TABLEA、TABLEB 和 TABLEC 的三表聯結。這三個表都按單一列 SEQEN_NR 進行分區和聚簇;但是,任何其他索引中都沒有添加 SEQEN_NR。這迫使優化器在篩選和聯結之間做出選擇。
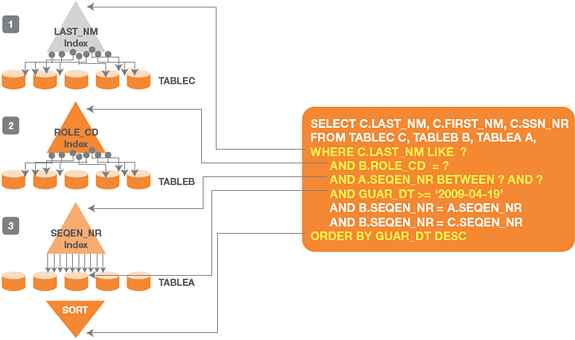
圖 3. 訪問的第一個表 TABLEC 在非聚簇索引上應用 LAST_NM 篩選,推遲獲取 SEQEN_NR。訪問的第二個表 TABLEB 應用 ROLE_CD 篩選,推遲聯結。訪問的第三個表 TABLEA 在聚簇索引上應用聯結篩選,推遲 GUAR_DT 篩選
查看原圖(大圖)
圖 3 說明發生的情況:
步驟 1. TABLEC 是訪問的第一個表。DB2 優化器選擇應用局部篩選 LAST_NM,但是因為所選的索引中不包含 SEQEN_NR,DB2 優化器會決定通過隨機的 I/O 獲取聯結 TABLEB 表所需的所有 SEQEN_NR。因為沒有使用包含 LAST_NM 和 SEQEN_NR 的索引結構執行聯結,所以聯結會推遲到獲取數據頁面時。(見圖 3 中的 No. 1。)
步驟 2. 訪問的第二個表 TABLEB 也會由於這樣的索引設計損害性能,它應用局部篩選 ROLE_CD,在應用聯結謂詞之前也執行隨機 I/O。因為沒有使用索引結構執行聯結,所以聯結也會推遲到獲取數據頁面時。(見圖 3 中的 No. 2。)
步驟 3. 訪問的最後一個表 TABLEA 也會受害,但是這一次使用主/聚簇索引執行聯結,使用連續 I/O 獲取數據頁面,應用局部篩選 GUAR_DT,然後用 ORDER BY 執行排序。(見圖 3 中的 No. 3。)
訪問的三個表都把篩選或聯結推遲到訪問數據頁面時。這是因為沒有同時滿足篩選和聯結需要的復合索引,DB2 優化器不得不在篩選和聯結之間做出選擇。
對於這個常用的重要的服務,解決方案包括以下步驟:
修改 LAST_NM.FIRST_NM 索引,在其中添加 SEQEN_NR 和 SSN_NR,從而實現純索引訪問,完全避免對數據頁面執行隨機 I/O。
修改 ROLE_CD 索引,在其中添加 SEQEN_NR,從而把篩選和聯結組合起來。
在 TABLEA 上添加第五個索引 GUAR_DT.SEQEN_NR,從而把篩選和聯結組合起來並避免 ORDER BY 排序。
新的索引解決方案根據所有篩選、聯結和排序操作組合索引結構,這把 CPU 時間降低到了 0.02 秒。
3. 監視 RID 池失效
某些訪問路徑必須先完成許多步驟,然後才能返回一個結果行,這種訪問路徑開銷很大。這些訪問路徑常常需要通過行標識符 (RID) 排序消除隨機 I/O,它們被稱為 List Prefetch、Multiple Index Access 和 Hybrid Join - Type N。這些訪問路徑在訪問之前使用 RID 池對數據頁面號進行預排序。RID 池資源是有限制的,超過這些限制時會發生表掃描。
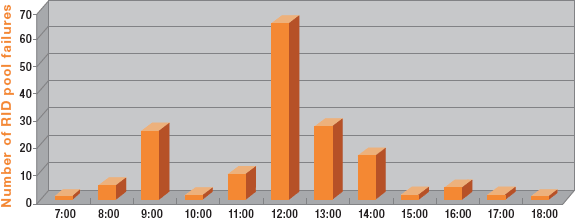
由任意數量的程序添加到 RID 池中的 RID 越多,出現失效的概率就越大,RID 池失效會導致表掃描。RID 池失效的現象之一是連續預抓取數量出現意外的高峰。跟蹤連續預抓取數量是查明失效的一種方法。更好的方法是使用在線監視器。圖 4 給出在線監視器監視一個使用 Hybrid Join - Type N 的程序在一小時內得到的數據,它發現了 61 次 RID 池失效。
圖 4. 一個使用 Hybrid Join - Type N 訪問路徑的程序在中午 12 點到下午 1 點之間出現了 61 次 RID 池失效
查看原圖(大圖)
對這個問題的一個解決方案是增加 RID 池的大小,但是這只能暫時減少失效;更糟糕的是,這可能根本無效。更好的解決方案是使用 DB2 跟蹤或在線監視器查明高度依賴於 RID 池的查詢。每個查詢需要通過一直抓取到整個結果集的末尾來證明它對 RID 池的使用是適當的。無法通過這項測試的任何查詢都需要關閉使用 RID 池的訪問路徑,方法是在查詢的末尾添加 OPTIMIZE FOR n ROWS 或 FETCH FIRST n ROWS ONLY 子句。DB2 10 將利用外部工作文件處理溢出,從而減輕失效的影響,因此不再需要分析查詢。但是,最好在遷移到 DB2 10 之前找出並解決這種問題,否則會使用大量工作文件。
4. 壓制凍結的或性能差的 SQL
凍結的 SQL 就是嵌入在購買的應用程序中您無法修改的 SQL。凍結的 SQL 中的查詢有時候不符合性能規則,但是您只能忍受它們。需要讓這些查詢使用盡可能少的資源。例如,WHERE DATE(col_TS) BETWEEN :date1 AND :date2 是一個 Stage 2/Residual 條件。這個謂詞應該改寫為 WHERE col_TS BETWEEN TIMESTAMP(:date1, '00:00:00')AND TIMESTAMP(:date2, '59:59:99'),這是可以使用索引的 Stage 1/Sargable。但是,您無法做修改。
一種解決方案是提前完成工作並把結果存儲在磁盤上。對於 DB2 8 系統,一種解決方案是用 SELECTS DATE(col_TS)as NEW_COL FROM TABLE 創建物化查詢表 (MQT) 並在 NEW_COL 列上創建索引。現在,所有動態查詢將使用這個索引。對於 DB2 9 系統,另一個基於磁盤的解決方案是使用 Index on Expression 特性 — CREATE INDEX on DATE(col_TS)。這只用一個結構產生相同的結果,而且靜態和動態查詢都可以使用它。
這些技術也適用於運行開銷極大、計算極復雜或運行極頻繁的非凍結查詢。如果您的站點無法采用這兩種結構中的一種,那麼在減少 CPU 需求方面就沒什麼好辦法了。
另一個目前還不可用的解決方案是基於內存的,根據 IBM 實驗室和客戶的 beta 測試經驗,這可以把長時間運行的查詢的速度加快 5 到 10 倍,而不需要修改應用程序。具體方法是:使用 IBM Data Studio(可免費使用)把一個事實表和維表預先裝載到內存中。這把數據倉庫的一部分復制並壓縮成一個完全位於內存中與網絡相連的用具,形成一個加速查詢表 (AQT)。這個特性稱為 IBM Smart Analytics Optimizer,當前處於 beta 測試階段。把查詢由基本表/索引轉向 MQT/索引所用的 DB2 9 Query Router 將能夠透明地讓 INNER/LEFT JOIN 查詢使用 AQT。這種基於內存的技術將隨著時間的推移逐漸增強,能夠重定向更多的查詢,實現更顯著的查詢加速。可伸縮性需要一個智能的性能層;MQT、Index on Expression 和 AQT 將組成這個性能層。
5. 根據工作負載模式創建最優的模式設計
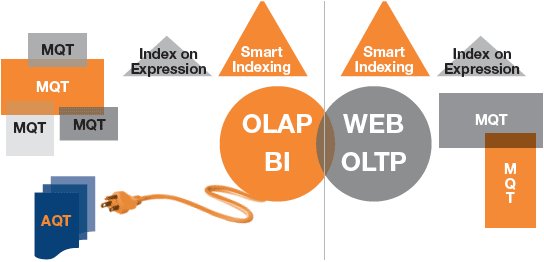
可伸縮性還需要智能的模式設計,它應該能夠高效地適應工作負載模式。例如,聯機事務處理 (OLTP) 和內部網應用程序最好采用第三范式表設計,從而減輕無規律的更新/刪除操作的影響,還應該經常檢查索引。這種規范的設計適用於靜態的集中的業務問題。聯機分析處理 (OLAP) 和商業智能 (BI) 應用程序最好采用星形模式和非規范化。事實表和維表設計適用於涉及海量數據的特殊業務問題。這些環境應該采用完全不同的基本表設計、索引設計、MQT、 Index on Expression 和 AQT,從而根據工作負載模式充分利用 DB2 提供的特性(見圖 5)。
圖 5. Web 和 OLTP 應用程序需要智能的索引策略(包括 Index on Expression)以處理大量小查詢。OLAP 和 BI 應用程序應該利用 MQT 和 AQT 處理涉及海量數據的寬泛的業務問題
了解您照料的數據庫
組織應該非常熟悉他們的 DBMS,對數據庫進行適當的維護並注意細節。為了保持可伸縮性,打包的 DB2 應用程序也需要符合性能規則。應該使用適當的 SQL、索引、訪問路徑、MQT、表設計和 AQT,只要遵守這些簡單的規則,就能大大降低數據管理成本。實現這些規則需要花費時間和精力,在當今快速的應用程序開發周期中往往顧不上考慮它們。但是,如果忽視這些工作,您的 DBMS 很快就會不堪重負。