簡介
本文做了如下假設:
您具有一個 DB2 DPF 環境並且熟悉 DB2 DPF 的概念。
您正在設計一個將被哈希分區的新表,或者您已經有了一個哈希分區的表,並且此表有可能會存在數據傾斜問題。
本文將幫助您實現如下任務:
在定義和填充一個表之前,選擇正確的初始分區鍵(PK)
評估表上已有 PK 的質量
評估已有表上的候選替換 PK 的質量
在保持表在線的情況下,更改此 PK
本文提供了如下這類幫助:
回顧概念和關注點
設計准則
新例程用來評估已有的和新的分區鍵的數據傾斜
哈希分區的快速浏覽
在 DPF 環境中,大型表一般要跨多個數據庫分區。對表進行分區的方法有幾種,但本文只著重於哈希方式的分區。
哈希分區基於的是分區鍵。一個分區鍵由在表創建時定義的一個或多個列組成。對於每個新插入的記錄,分區鍵會決定這個記錄應該存儲在哪個數據庫分區。這種安置是由一個內部的哈希函數決定的,該函數接受定義為分區鍵的列內的值並返回數據庫分區號。哈希函數是一個確定性 函數,這意味著對於相同的分區鍵值,它總是假設對數據庫分區組的定義沒有更改並總是會生成相同的分區安置。
如下的語法示例展示了創建一個哈希分區表所需步驟:
創建一個數據庫分區組來指定要參加分區的那些數據庫分區。如下的例子展示了如何在數據庫分區 1、2、 3 和 4 上創建一個數據庫分區組 PDPG:
CREATE DATABASE PARTITION GROUP pdpg1 ON DBPARTITIONNUMS(1 to 4)
根據 IBM Smart Analytics System 和 IBM InfoSphere™ Balanced Warehouse 的最佳實踐,被哈希分區的表應該在 coordinator 或 administration 分區(數據庫分區 0)上創建。數據庫分區 0 通常用於存儲小型的非分區的查找表。
創建數據庫分區組內的表空間。在此表空間內創建的所有對象都將跨在數據庫分區組定義內指定的這些數據庫分區:
CREATE TABLESPACE tbsp1 IN pdpg1 ...
在表空間內創建表。至此,此表的定義與數據庫分區組的定義相關聯。更改此關系的惟一方式是丟棄此表並在與不同的數據庫分區組相關聯的一個不同的表空間內重新創建它。
在如下的例子中,Table1 創建於數據庫分區 1、2、3 和 4 並且會基於列 COL1 上的一個分區鍵重新分配:
CREATE TABLE table1(col1 INTEGER NOT NULL, col2 SMALLINT NOT NULL, col3 CHAR(10),
PRIMARY KEY (col1,col2) ) IN tbsp1
DISTRIBUTE BY HASH (col1)
請記住,數據庫分區組定義可以更改。比如,可以添加新的數據庫分區。如果發生更改,那麼在此次更改之前定義的哈希分區表將不會使用這個新的分區,直到此數據庫分區組被 REDISTRIBUTE DATABASE PARTITION GROUP 命令重新分配。
定義分區鍵
分區鍵由 CREATE TABLE 命令內的 DISTRIBUTED BY HASH 子句定義。分區鍵定義後,就不能更改。更改它的惟一辦法是重新創建此表。
如下的規則和建議適用於分區鍵定義:
表的主鍵和所有惟一索引都必須是相關分區鍵的超集。換句話說,作為分區鍵一部分的所有列都必須出現在主鍵或惟一索引定義中。列的順序可任意。
一個分區鍵應該包括一至三個列。通常列越少越好。
整型分區鍵要比字符鍵高效,而字符鍵又比小數鍵高效。
如果在 CREATE TABLE 命令內沒有顯式地提供分區鍵,那麼就會使用如下的這些默認值:
如果在 CREATE TABLE 語句中指定了一個主鍵,那麼主鍵的首列會被用作分配鍵。
如果沒有主鍵,就會使用非長型字段的首列。
為何選擇正確的分區鍵如此重要
選擇正確的分區鍵之所以如此關鍵,有兩方面的原因:
它改善了使用哈希分區的那些查詢的性能
它平衡了所有分區的存儲需求
數據平衡
數據平衡指的是存儲在各個數據庫分區的記錄的相對數量。理想情況下,一個哈希分區表內的每個數據庫分區都應具有相同數量的記錄。如果各數據庫分區存儲的記錄數不均,就會導致不均衡的存儲需求和性能問題。之所以會出現性能問題是因為查詢均獨立在每個數據庫分區完成,但是查詢的結果則要由協調代理進行整合,而該代理必須等所有數據庫分區均返回結果集後才開始整合。換言之,整體的性能受制於最慢的數據庫分區的性能。
表數據傾斜 指的是特定的一些數據庫分區上的某個表內的記錄數與這個表所跨的所有數據庫分區的平均記錄數之間的差額。所以,對於本例,如果某個表在數據庫分區 1 上的表數據傾斜是 60%, 那麼這意味著此數據庫分區包含的該表的行要比平均的數據庫分區多出 60%。
從最佳實踐的角度來看,各個數據庫分區上的表數據傾斜應該不多於 10%。為了實現此目標,分區鍵應該在具有較高基數(換言之,即包含大量不同值)的列上選擇。
如果表的統計信息是最新的,那麼就可以通過如下語句快速檢查現有表內列的基數:
清單 1. 檢查現有表內列的基數
SELECT colname, colcard FROM syscat.columns
WHERE tabname='CUSTOMER' AND tabschema = 'BCULinux' ORDER BY colno
COLNAME COLCARD
------------------------------------------------------------------------ ---------------
C_CUSTOMER_SK 100272
C_CUSTOMER_ID 25068
C_CURRENT_CDEMO_SK 25068
C_CURRENT_HDEMO_SK 6912
C_CURRENT_ADDR_SK 19456
C_FIRST_SHIPTO_DATE_SK 3651
C_FIRST_SALES_DATE_SK 3584
... [remainder of the output omitted from this example]
並置
一個查詢內的兩個合並表之間的並置意味著兩個表的匹配行將總是處於相同的數據庫分區內。如果這種合並不加以並置,數據庫管理器就必須通過網絡將記錄從一個數據庫分區運送至另一個分區,這樣一來,就會導致性能的不甚理想。為了數據庫管理器能夠使用並置合並,有一些條件必須要滿足:
被合並的表必須在相同的數據庫分區組內定義。
每個被合並的表的分區鍵都必須匹配。換言之,它們必須包含相同數量和順序的列。
對於被合並的表的分區鍵內的每列,必須存在一個同等連接的謂語。
如果基於查詢工作負載選擇一個分區鍵,那麼此分區鍵通常應該包含一個合並列或常被用於很多查詢的一組列。
雖然經並置的表通常都會獲得最健壯的性能,但是在實際中,不太可能對所有表都進行並置。此外,基於為數不多的 SQL 語句選擇分區鍵也不是一個好的做法。在決策支持的環境中,查詢通常無法預測。在這種環境下,應該查看數據模型來決定分區鍵的最佳選擇。這個數據模型以及表間的業務關系可以提供一種比 SQL 語句更為穩定的選擇分區鍵的方式。
在選擇分區鍵時,可以畫出一個數據模型,用來顯示數據庫內的這些表之間的關系。標示出頻繁合並和常用表。基於數據模型,選擇那些有利於頻繁合並且基於主鍵的分區鍵。理想情況下,還應該並置頻繁合並的表。改善合並並置的另一個策略是復制每個數據庫分區上的較小的表。
並置與數據平衡間的對比
在某些情況下,您可能會發現根據並置和數據平衡選擇恰當的分區鍵的准則會相互矛盾。在這些情況下,建議您基於數據平衡選擇分區鍵。
驗證現有表上的分區鍵
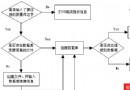
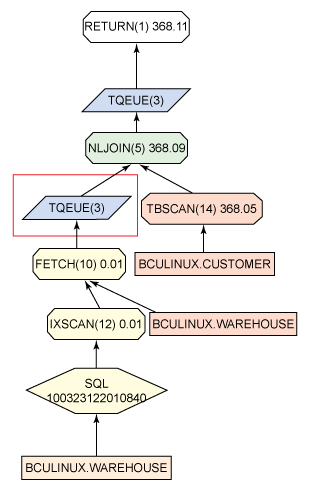
如果想要驗證分區鍵的好壞,可以查看工作負載內查詢是否已經被並置以及數據是否已經被很好地平衡。隨著時間的推移,因數據的改變,舊的分區鍵有可能會不如之前那麼好。可以通過查看由 DB2 Explain 生成的訪問計劃來檢查查詢合並的並置情況。如果查詢沒有經過並置,通常會看到 TQUEUE(表查詢)操作符送到這個合並,如圖 1 所示:
圖 1. 包含了 TQUEUE 操作符的解釋圖
為了檢查表內的數據是否跨數據庫分區進行了適當的均衡,可以借助 DBPARTITIONNUM 函數在按此數據庫分區 ID 分組的表上運行一個簡單的計數。
也可以使用定制存儲過程 ESTIMATE_EXISTING_DATA_SKEW 例程(在 下載 部分可以找到),它提供了更為用戶友好的輸出,其中包括一個數據庫分區列表、相對於平均值的傾斜百分比等。這個例程可以在原始數據的樣本上運行以獲得更快速的性能。(參見 附錄 獲得完整的例程描述。)
若計劃在一個生產環境內運行此例程,可以考慮在維護窗口期間或是當系統處於輕負載的情況下運行它。為了估算此例程需要花費多久才能返回結果,不妨在一個較小的表上用示例值 1% 嘗試此例程。
示例 1
這個示例測試的是分區鍵被更改為 S_NATIONKEY 的場景中的數據傾斜。這個示例只使用了樣本中 25% 的數據。 正如從結果中看到的,數據大量傾斜,某些數據庫分區內的數據量居然有 60% 的傾斜。
清單 2. 測量單個表的現有數據傾斜
$ db2 "set serveroutput on"
$ db2 "CALL estimate_existing_data_skew('TPCD', 'SUPPLIER', 25)"
CALL estimate_existing_data_skew('TPCD', 'SUPPLIER', 25)
Return Status = 0
DATA SKEW ESTIMATION REPORT FOR TABLE: TPCD.SUPPLIER
Accuracy is based on 25% sample of data
------------------------------------------------------------------------
TPCD.SUPPLIER
Estimated total number of records in the table: : 19,994,960
Estimated average number of records per partition : 2,499,368
Row count at partition 1 : 1,599,376 (Skew: -36.00%)
Row count at partition 2 : 2,402,472 (Skew: 3.87%)
Row count at partition 3 : 4,001,716 (Skew: 60.10%)
Row count at partition 4 : 2,394,468 (Skew: -4.19%)
Row count at partition 5 : 1,600,028 (Skew: -35.98%)
Row count at partition 6 : 1,599,296 (Skew: -36.01%)
Row count at partition 7 : 2,397,116 (Skew: -4.09%)
Row count at partition 8 : 4,000,488 (Skew: 60.05%)
Number of partitions: 8 (1, 2, 3, 4, 5, 6, 7, 8)
------------------------------------------------------------------------
Total execution time: 20 seconds
示例 2
這個示例展示了通配符在 ESTIMATE_EXISTING_DATA_SKEW 例程中的使用。 清單 3 報告了具有模式 TPCD 且表名以 “PART” 開頭的所有表的現有數據傾斜。由於這些表相對比較大,這個例子構建於 1% 的數據以減少性能的損失。
清單 3. 測量多個表的現有數據傾斜
$ db2 "set serveroutput on"
$ db2 "CALL estimate_existing_data_skew('TPCD', 'PART%', 1)"
CALL estimate_existing_data_skew('TPCD', 'PART%', 1)
Return Status = 0
DATA SKEW ESTIMATION REPORT FOR TABLE: TPCD.PART%
This report is based on the existing partitioning key
Accuracy is based on 1% sample of data
------------------------------------------------------------------------
TPCD.PART
Estimated total number of records in the table: : 399,799,400
Estimated average number of records per partition : 49,974,900
Row count at partition 1 : 50,051,800 (Skew: 0.15%)
Row count at partition 2 : 49,951,200 (Skew: -0.04%)
Row count at partition 3 : 49,862,500 (Skew: -0.22%)
Row count at partition 4 : 49,986,500 (Skew: -0.02%)
Row count at partition 5 : 50,096,400 (Skew: 0.24%)
Row count at partition 6 : 49,993,900 (Skew: -0.03%)
Row count at partition 7 : 49,955,900 (Skew: -0.03%)
Row count at partition 8 : 49,901,200 (Skew: -0.14%)
Number of partitions: 8 (1, 2, 3, 4, 5, 6, 7, 8)
------------------------------------------------------------------------
TPCD.PARTSUPP
Estimated total number of records in the table: : 1,600,374,100
Estimated average number of records per partition : 200,046,700
Row count at partition 1 : 200,298,100 (Skew: 0.12%)
Row count at partition 2 : 200,154,900 (Skew: 0.05%)
Row count at partition 3 : 200,006,700 (Skew: 0.01%)
Row count at partition 4 : 199,831,600 (Skew: -0.10%)
Row count at partition 5 : 199,962,200 (Skew: -0.04%)
Row count at partition 6 : 200,083,900 (Skew: 0.01%)
Row count at partition 7 : 199,910,300 (Skew: -0.06%)
Row count at partition 8 : 200,126,400 (Skew: 0.03%)
Number of partitions: 8 (1, 2, 3, 4, 5, 6, 7, 8)
------------------------------------------------------------------------
TPCD.SUPPLIER
Estimated total number of records in the table: : 20,000,000
Estimated average number of records per partition : 2,500,000
Row count at partition 1 : 2,498,411 (Skew: -0.06%)
Row count at partition 2 : 2,498,837 (Skew: -0.04%)
Row count at partition 3 : 2,500,996 (Skew: 0.03%)
Row count at partition 4 : 2,500,170 (Skew: 0.00%)
Row count at partition 5 : 2,501,254 (Skew: 0.05%)
Row count at partition 6 : 2,499,654 (Skew: -0.01%)
Row count at partition 7 : 2,501,429 (Skew: 0.05%)
Row count at partition 8 : 2,499,249 (Skew: -0.03%)
Number of partitions: 8 (1, 2, 3, 4, 5, 6, 7, 8)
------------------------------------------------------------------------
Total execution time: 51 seconds
評估已有表上的候選替換 PK 的質量
如果決定更改現有的一個分區鍵,那麼很重要的一點是要確認這個新的分區鍵將會帶來好的查詢並置及數據的均衡分配。
為了查看查詢並置,建議您收集能體現工作負載的那些查詢,將這些查詢放入一個文件,然後運行一個 db2advis 報告來獲得對新分區鍵的建議:
db2advis -d <database name> -i <workload file> -m P
還可以使用如下形式的 db2advis 實用工具基於尚處於包緩存中的最新執行的查詢運行一個報告:
db2advis -d <database name> -g -m P
清單 4 給出了一個示例 db2advis 輸出:
清單 4. db2advis 輸出
bcuLinux> db2advis -d tpcds -g -m P
Using user id as default schema name. Use -n option to specify schema
execution started at timestamp 2010-04-06-11.33.04.271678
Recommending partitionings...
Cost of workload with all recommendations included [1761.000000] timerons
1 partitionings in current solution
[1761.0000] timerons (without recommendations)
[1736.0000] timerons (with current solution)
[1.42%] improvement
--
--
-- LIST OF MODIFIED CREATE-TABLE STATEMENTS WITH RECOMMENDED PARTITIONING KEYS AND
TABLESPACES AND/OR RECOMMENDED MULTI-DIMENSIONAL CLUSTERINGS
-- ===========================
-- CREATE TABLE "BCULinux"."ITEM" ( "I_ITEM_SK" INTEGER NOT NULL ,
-- "I_ITEM_ID" CHAR(16) NOT NULL ,
-- "I_REC_START_DATE" DATE ,
-- "I_REC_END_DATE" DATE ,
-- "I_ITEM_DESC" VARCHAR(200) ,
-- "I_CURRENT_PRICE" DECIMAL(7,2) ,
-- "I_WHOLESALE_COST" DECIMAL(7,2) ,
-- "I_BRAND_ID" INTEGER ,
-- "I_BRAND" CHAR(50) ,
-- "I_CLASS_ID" INTEGER ,
-- "I_CLASS" CHAR(50) ,
-- "I_CATEGORY_ID" INTEGER ,
-- "I_CATEGORY" CHAR(50) ,
-- "I_MANUFACT_ID" INTEGER ,
-- "I_MANUFACT" CHAR(50) ,
-- "I_SIZE" CHAR(20) ,
-- "I_FORMULATION" CHAR(20) ,
-- "I_COLOR" CHAR(20) ,
-- "I_UNITS" CHAR(10) ,
-- "I_CONTAINER" CHAR(10) ,
-- "I_MANAGER_ID" INTEGER ,
-- "I_PRODUCT_NAME" CHAR(50) )
-- ---- DISTRIBUTE BY HASH("I_ITEM_SK")
-- ---- IN "HASHTS"
-- DISTRIBUTE BY HASH (I_ITEM_SK)
-- IN USERSPACE1
-- ;
-- COMMIT WORK ;
-- ===========================
為了查看使用新的分區鍵是否能很好地均衡數據,可以使用 下載 部分提供的 ESTIMATE_NEW_DATA_SKEW 例程。這個例程用新的分區鍵創建了現有表的一個副本並用來自原始表的數據對它進行部分或全部加載。例程然後會為了進行現有數據傾斜的估計運行相同的報告並且最後還會丟棄這個副本表。請注意包含原始表的表空間必須能夠保存來自原始表最少 1% 的數據,因為復制版本是在相同的表空間內創建的。
示例 3
這個示例測試的是分區鍵從 S_NATIONKEY 更改為 S_ID 的場景中的數據傾斜。這個例子使用了樣本中 100% 的數據。正如這個示例所展示的,新的分區鍵帶來了極少的數據傾斜,因此比示例 1 中的原始 S_NATIONAL 鍵好很多。
清單 5. 評估新分區鍵的數據傾斜
$ db2 "set serveroutput on"
$ db2 "CALL estimate_new_data_skew('TPCD', 'SUPPLIER', 'S_ID', 100)"
CALL estimate_new_data_skew('TPCD', 'SUPPLIER', 'S_ID ', 100)
Return Status = 0
DATA SKEW ESTIMATION REPORT FOR TABLE: TPCD.SUPPLIER
This report is based on the new partitioning key: S_NATIONKEY
Accuracy is based on 100% sample of data
------------------------------------------------------------------------
TPCD.SUPPLIER
Estimated total number of records in the table: : 20,000,000
Estimated average number of records per partition : 2,500,000
Row count at partition 1 : 2,498,411 (Skew: 0.06%)
Row count at partition 2 : 2,498,837 (Skew: 0.04%)
Row count at partition 3 : 2,500,996 (Skew: 0.03%)
Row count at partition 4 : 2,500,170 (Skew: 0.00%)
Row count at partition 5 : 2,501,254 (Skew: 0.05%)
Row count at partition 6 : 2,499,654 (Skew: 0.01%)
Row count at partition 7 : 2,501,429 (Skew: 0.05%)
Row count at partition 8 : 2,499,249 (Skew: 0.03%)
Number of partitions: 8 (1, 2, 3, 4, 5, 6, 7, 8)
------------------------------------------------------------------------
Total execution time: 20 seconds
在保持表在線的情況下更改 PK
在 DB2 9.7 內有一個名為 ADMIN_MOVE_TABLE 的新例程,可用來自動更改表的分區鍵,同時又能保持表對讀寫的完全可訪問性。除了更改分區鍵,這個過程能夠將表移到不同的表空間、更改列定義等。
示例 4
這個示例將 TPCD.PART 表的分區鍵從 COL1 更改為 (COL2, COL3)。它還使用 LOAD 選項來提高 ADMIN_MOVE_TABLE 例程的性能。
清單 6. 更改分區鍵
CALL SYSPROC.ADMIN_MOVE_TABLE
('TPCD', 'PART', '', '', '',
'', 'COL2, COL3', '', '',
'COPY_USE_LOAD, FORCE', 'MOVE')
Result set 1
--------------
KEY VALUE
-------------------------------- ----------------------------
AUTHID TPCD
CLEANUP_END 2010-03-12-12.40.17.360000
CLEANUP_START 2010-03-12-12.37.43.297000
COPY_END 2010-03-12-12.37.42.704000
COPY_OPTS OVER_INDEX,LOAD,WITH_INDEXES
COPY_START 2010-03-12-11.18.40.563000
COPY_TOTAL_ROWS 400000000
INDEX_CREATION_TOTAL_TIME 0
INDEXNAME PROD_ID_PK
INDEXSCHEMA TPCD
INIT_END 2010-03-12-12.59.40.266000
INIT_START 2010-03-12-12.40.39.172000
REPLAY_END 2010-03-12-11.18.43.125000
REPLAY_START 2010-03-12-11.18.42.704000
REPLAY_TOTAL_ROWS 0
REPLAY_TOTAL_TIME 0
STATUS COMPLETE
SWAP_END 2010-03-12-11.18.43.250000
SWAP_RETRIES 0
SWAP_START 2010-03-12-11.18.43.125000
VERSION 09.07.0000
21 record(s) selected.
在 ADMIN_MOVE_TABLE 過程運行時,TPCD.PART 表是完全可訪問的並且分區鍵的更改對於終端用戶是透明的。
結束語
選擇適當的分區鍵對於優化基於 DB2 軟件的分區環境中的數據庫性能非常關鍵。本文提供了如何根據您自己的需要選擇最佳分區鍵的指導和工具。
本文描述了:
與分區鍵有關的概念以及創建分區鍵的規則和建議
可幫助您評估新的和已有分區鍵的數據傾斜的例程
在保持表的可訪問性的情況下如何更改分區鍵
附錄:例程參考文檔
前提條件
ESTIMATE_EXISTING_DATA_SKEW 和 ESTIMATE_NEW_DATA_SKEW 這兩個過程在 DB2 9.7 或更高版本中均受支持。用於實際移動表的例程 ADMIN_MOVE_TABLE 則隨核心 DB2 9.7 產品或更高版本附帶。對於 ESTIMATE_NEW_DATA_SKEW 例程,包含原始表的表空間內必須要有足夠的空間來存儲樣例數據。
部署指導
從 下載 部分下載並保存 estimate_data_skew.sql 文件。
從命令行連接到數據庫並使用如下命令部署例程:
$ db2 -td@ -vf estimate_data_skew.sql
ESTIMATE_NEW_DATA_SKEW 過程
ESTIMATE_NEW_DATA_SKEW 例程基於一個新分區鍵估算已有表的各數據庫分區的數據傾斜。為了改進性能並降低例程的存儲要求,估算可使用頁面級的極快速取樣基於數據的一個子集。
語法
>>-ESTIMATE_DATA_SKEW--(--tabschema--,--tabname--,---------------->
>--new_partitioning_keys--,--sampling_percentage--)-------->