本文配套源碼
簡介
為了執行查詢或 DML 語句(INSERT、UPDATE、DELETE),DB2 必須創建一個訪問計劃(Access plan)。訪問計劃定義按什麼順序訪問表,使用哪些索引,以及用何種連接(join)方法來關聯數據。好的訪問計劃對於 SQL 語句的快速執行至關重要。DB2 優化器可以創建訪問計劃。這是一種基於成本的優化器,這意味著它是根據表和索引的相關統計信息來作出決策的。DB2 在生成統計信息時,不但能提供基本統計信息,還允許創建所謂的分布統計信息。不但數據庫管理員要理解分布統計信息,而且應用程序開發人員也要理解分布統計信息。應用程序開發人員必須小心謹慎,因為在某些情況下分布統計信息對於 DB2 優化器來說非常重要。主變量或參數標記(在 Java 中為 Java.sql.PreparedStatement)的使用可能會造成阻礙,使優化器無法最大限度地利用分布統計信息。本文解釋什麼是分布統計信息、分布統計信息在哪些情況下尤為重要,以及應用程序開發人員應該考慮些什麼,才能使 DB2 優化器創建有效的訪問計劃。
基本統計信息和分布統計信息
在研究分布統計信息之前,我們先來看看基本統計信息,只要執行 RUNSTATS 即可收集這些表的相關統計信息。
表的相關統計信息:
當前使用的頁面數
包含記錄行的頁面數
溢出的行數
表中的行數(基數)
對於 MDC 表,還有包含數據的塊(block)數
表中各列的相關統計信息:
列的基數
列的平均長度
列中第二大的值
列中第二小的值
列中 NULL 值的個數
通常,執行 RUNSTATS 時,不但可以收集到關於表的統計信息,而且還可以收集到相應的索引的相關統計信息。要了解為索引而收集的統計信息,請參閱 DB2 Administration Guide: Performance - Statistical information that is collected。
觀察一個表的基本統計信息,您可以看到,DB2 優化器知道一個表由多少行組成(表的基數),以及一個列包含多少個不同的值(列的基數)。但是,還有一些信息是基本統計信息無法提供的。例如,基本統計信息不能告訴優化器一個列中某些值出現的頻率。假設表 TABLE_X 有大約 1,000,000 行,在該表上執行這樣一條查詢:
SELECT * FROM TABLE_X WHERE COLUMN_Y = 'VALUE_Z'
難道 DB2 優化器知道 TABLE_X 中有多少行滿足條件 COLUMN_Y = 'VALUE_Z' 不重要嗎?換句話說:知道這個查詢將返回 1 行、100 行、1000 行還是 10000 行有什麼不好呢?
實際上,通過基本統計信息,DB2 優化器只能估計 'VALUE_Z' 在 COLUMN_Y 中出現的頻率。在這種情況下,優化器認為所有值在 COLUMN_Y 中是平均分布的,這意味著它認為所有的值都有相同的出現頻率。如果事實碰巧如此,這樣估計並無大礙。但是,如果有些值比其他值出現得更頻繁一些(例如,如果 'VALUE_Z' 出現 900,000 次,即占所有行的 90%),那麼優化器不能考慮到這一點,因而生成的訪問計劃就不是最優的。而分布統計信息可以填補這一空白。分布統計信息可以提供關於數據出現頻率及其分布情況的信息,如果數據庫中存儲了很多重復值,並且數據在表中並非平均分布的時候,分布統計信息對於基本統計信息是一個重要的補充。
分布統計信息的類型 —— 頻率(frequency)統計信息和分位數(quantile)統計信息
有兩種不同類型的分布統計信息 —— 頻率統計信息和分位數統計信息。讓我們通過一個示例表來研究一下這兩種不同類型的分布統計信息。
示例表 “CARS” 表示一家汽車制造商,對於生產的每一輛汽車,在表中都有相應的一行。每輛汽車可以由它的 ID 來標識,因此 “ID” 是表 “CARS” 的主鍵(PK)。此外,表中有一個 “STATE” 列,表明汽車當前處在制造流程中的哪一步。一輛汽車的制造流程從第 1 步開始,然後是第 2 步、第 3 步,...、第 49 步、第 50 步、第 51 步、...、第 98 步、第 99 步,一直到第 100 步 —— 第 100 步意味著汽車已經完工了。已完工的汽車所對應的行仍然保留在表中,後續流程(例如投訴管理、質量保證等)仍要用到這些行。汽車制造商生產 10 種不同型號(“TYPE” 列)的汽車。為了簡化問題,在這個示例表中,各種汽車型號命名為 A、B、C、D、...、J。除主鍵索引(在 “ID” 列上)之外,“STATE” 列上也有一個索引(“I_STATE”),在 “TYPE” 列上還有一個索引(“I_TYPE”)。實際上,一個 “CARS” 表包含的列遠不止 “ID”、“STATE” 和 “TYPE”。為簡單起見,示例表中沒有出現其他這些列。
頻率統計信息
假設表 CARS 現在有大約 1,000,000 條記錄,不同的型號在表中出現的頻率如下所示:
表 1. 表 CARS 中 TYPE 列的頻率統計信息
TYPE COUNT(TYPE) A 506135 B 301985 C 104105 D 52492 E 19584 F 10123 G 4876 H 4589 I 4403 J 3727
型號為 A 的汽車最受購買者的青睐,因此生產的汽車中大約有 50% 是這種型號。型號 B 和型號 C 僅次於型號 A ,分別占所有汽車的 30% 和 10%。其他所有型號加在一起僅占 10%。
上面的表顯示了 “TYPE” 列的頻率統計信息。通過基本統計信息,DB2 優化器只能了解到該表包含 1,000,000 行(表的基數)和 10 種不同的值(型號),即 A 到 J。如果沒有分布統計信息,優化器會認為每種值以相同的頻率出現,大約都是出現 100,000 次。而一旦生成了關於 “TYPE” 列的分布統計信息,優化器即可了解每種型號真正的出現頻率。因此,優化器清楚各種已有型號出現的不同頻率。
優化器使用頻率統計信息來計算用於檢查相等或不等的謂詞的過濾因子。例如:
SELECT * FROM CARS WHERE TYPE = 'H'
分位數統計信息
與頻率統計信息不同,分位數統計信息與不同值的出現頻率無關,而與一個表中有多少行小於或大於某個值(或者有多少行介於兩個值之間)相關。分位數統計信息提供關於一個列中的值是否聚合的信息。為獲得這樣的信息,DB2 假定列中的值是按升序排列的,並根據正則行間隔確定相應的值。
我們來看看表 CARS 中的 “STATE” 列,該列按升序排列。根據正則行間隔,即可確定 “STATE” 的對應值。
表 2. CARS 表中 STATE 列的分位數統計信息
COUNT(row) STATE ASC 5479 1 54948 10 109990 21 159885 31 215050 42 265251 52 320167 63 370057 73 424872 84 475087 94 504298 100 ... 100 1012019 100
由於已完工的汽車仍然沒有從表中刪除,因此狀態為 100 (=完工)的汽車數量比所有處於其他狀態的汽車總和還多。已完工的汽車占表中所有記錄的 50%。
注意: 在實際情況下,已完工的汽車數量甚至還要更多(例如超過 99%)。在後文中的具體例子中可看到這種情況。
上表顯示了 “STATE” 列的分位數統計信息。有了這種關於有多少行分別小於和大於確定值的信息,優化器即可計算出用於測試小於(小於等於)、大於(大於等於)或介於兩值之間的謂詞的過濾因子。例如:
SELECT * FROM CARS WHERE STATE < 100
SELECT * FROM CARS WHERE STATE BETWEEN 50 AND 70
根據已有的分位數統計信息計算出來的過濾因子不是很精確,但即使只收集 20 個值,其誤差仍然低於 5%。
DB2優化器對分布統計信息的使用 —— 示例
我們來看一個完整的示例,在此例中,DB2 優化器可以使用分布統計信息來更合理地估計過濾因子,以便生成更好的訪問計劃。
這個示例查詢從已經定義好的 CARS 表中讀取數據。對於表 CARS 中的汽車數據,有以下假設:
該表的基數為 1,000,000,也就是說該表包含 1,000,000 行。
表中 99.9% 的汽車是已經完工(“STATE” 列 = 100)的,這些汽車的信息相關必須保留,以用於後續處理(投述管理、質量保證等)。剩下的 1,000 輛汽車目前還處在制造流程中。
在該表中,制造商提供的從 A 到 J 的 10 種不同汽車型號(“TYPE” 列)幾乎以相同的頻率出現。
注意: 腳本 create_table_cars.sql 用於創建前述 CARS 表,包括 “STATE” 列和 “TYPE” 列上的索引,該腳本可以通過本文 下載。這個示例表是在 DB2 SAMPLE 數據庫中(命令 db2sampl),使用 DBM CFG 和 DB CFG 的默認設置創建的。
示例查詢選擇型號為 A 且正處在制造流程中、尚未完工的所有汽車:
SELECT * FROM CARS WHERE STATE < 100 AND TYPE = 'A'
首先來分析一下,在沒有分布統計信息,而只有 CARS 表的基本統計信息及其索引的情況下,優化器選擇的訪問計劃是怎樣的。
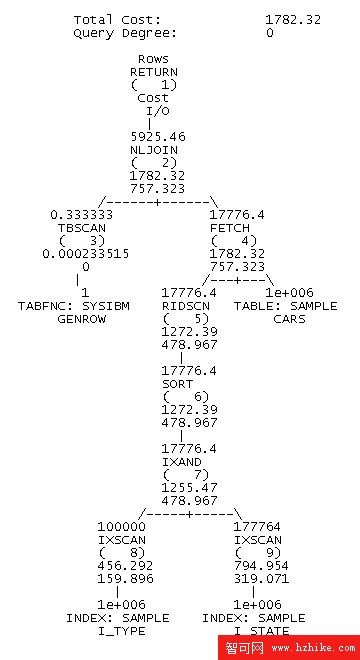
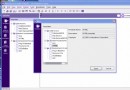
圖 1. 沒有分布統計信息時示例查詢的訪問計劃

這個訪問計劃的成本明顯低於沒有分布統計信息時的成本:前者為 203.809,而後者為 3242.63。這是因為優化器現在知道,謂詞 STATE < 100 有一個較高的過濾因子,因而只會返回大約 1,000 輛正處在生產流程中尚未完工的汽車。因此,在這種情況下,CARS 表不是使用索引 I_TYPE 來訪問的,而是使用索引 I_STATE 來訪問的。此外,現在可以正確地估計結果集中的總行數。現有 1,000 輛汽車尚未完工,不同的型號出現頻率相同。故結果集中包含大約 100 行。
有分布統計信息時的訪問計劃要優於沒有分布統計信息時的訪問計劃。但是,這是否會影響查詢的執行時間?清單 2 包含相應的監視器數據快照:
清單 2. 有分布統計信息時的示例查詢快照
Number of executions = 1
Number of compilations = 1
Worst preparation time (ms) = 9
Best preparation time (ms) = 9
Internal rows deleted = 0
Internal rows inserted = 0
Rows read = 1000
Internal rows updated = 0
Rows written = 0
Statement sorts = 1
Statement sort overflows = 0
Total sort time = 5
Buffer pool data logical reads = 11
Buffer pool data physical reads = 10
Buffer pool temporary data logical reads = 0
Buffer pool temporary data physical reads = 0
Buffer pool index logical reads = 12
Buffer pool index physical reads = 9
Buffer pool temporary index logical reads = 0
Buffer pool temporary index physical reads = 0
Total execution time (sec.ms) = 0.014597
Total user cpu time (sec.ms) = 0.000000
Total system cpu time (sec.ms) = 0.010014
Statement text = SELECT ID, TYPE, STATE FROM SAMPLE.CARS
WHERE STATE < 100 AND TYPE = 'A'
表 3 比較了有分布統計信息和沒有分布統計信息這兩種不同情況下的快照監視器值:
表 3. 比較快照監視器值
快照值 無分布統計信息 有分布統計信息 Rows read 99,336 1,000 Buffer pool data logical reads 8,701 11 Buffer pool index logical reads 165 12 Total execution time (sec.ms) 0.530903 0.014597
您可以看到,有分布統計信息的情況下,DB2 執行查詢時需要計算的行數更少。這對於 CPU 成本和 I/O 成本都有積極的影響。最重要的是總執行成本,因為總執行成本關系到應用程序的響應時間。在具有分布統計信息的情況下,這個時間是 0.014597 秒,而在沒有分布統計信息的情況下,這個時間是 0.530903,相差 36 倍之多。
在我們的示例中,兩種情況下的執行時間分別為 0.014597 秒和 0.530903 秒,這個差距還不夠明顯,因為這兩個值只是次秒級的。然而,這樣的差距不應被忽略。如果要執行更復雜的查詢,或者要連續執行多個查詢,那麼執行時間的差距就不是次秒級的,而是以秒甚至分鐘來計算的。
分布統計信息的生成
如前所述,在使用 RUNSTATS 命令生成統計信息時,並不是 總會收集分布統計信息。這是有意義的,因為僅在存在很多重復值或者數據分布不均勻的情況下,分布統計信息才重要。而在其他情況下,分布統計信息並不能帶來多大的好處。
下面的 RUNSTATS 命令只收集 CARS 表(在模式 SAMPLE 中)和相應索引的基本統計信息:
RUNSTATS ON TABLE SAMPLE.CARS AND INDEXES ALL
此外,如果需要收集 CARS 表中所有列的分布統計信息(頻率統計信息和分位數統計信息),那麼可以執行以下命令:
RUNSTATS ON TABLE SAMPLE.CARS WITH DISTRIBUTION AND INDEXES ALL
生成分布統計信息意味著給 DB2 帶來額外的、可觀的開銷,從而影響 RUNSTATS 命令的執行時間。所以,應該只為那些需要分布統計信息的列生成分布統計信息。
RUNSTATS ON TABLE SAMPLE.CARS WITH DISTRIBUTION ON COLUMNS (TYPE, STATE) AND INDEXES ALL
應為滿足以下條件的列收集分布統計信息:
該列有很多重復的值(頻率統計信息),或者該列的值分布不均勻,即它們在某些局部是聚合的(分位數統計信息)。
檢查等於或不等於的謂詞中使用到該列(頻率統計信息),或者檢查小於(小於等於)、大於(大於等於)或介於兩個值之間的謂詞中使用到該列(分位數統計信息)。
對於頻率統計信息,重要的是定義好收集多少個值的重復數。如果為一個列中的所有值收集頻率統計信息,那麼成本就太高了。如果在執行 RUNSTATS 時沒有顯式定義數量,那麼 DB2 將使用由數據庫參數 NUM_FREQVALUES 提供的默認數量。由於 NUM_FREQVALUES 的默認值為 10,DB2 將為列中出現最頻率的 10 個值收集重復次數,這裡假定 RUNSTATS 是在沒有顯式定義數量,且數據庫參數 NUM_FREQVALUES 沒有被修改的情況下執行的。
與頻率統計信息類似,也必須為分位數統計信息定義一個數量,以保證精確性。分位數統計信息定義應該使用多少 “度量值(measurement)“。列中的值被認為是按升序排列的,並且有一個正則的行間隔,相應的值是確定的。使用的度量值越多,優化器對於檢查范圍(<、>、<=、>=、BETWEEN)的謂詞的過濾因子的估計就越准確。如果在執行 RUNSTATS 時沒有明確指定一個值,那麼 DB2 將使用由數據庫參數 NUM_QUANTILES 提供的默認數量。NUM_QUANTILES 的默認值是 20,也就是說使用 20 個度量值。這已經是一個較好的值,因為它可以保證優化器在使用分位數統計信息的情況下對確定過濾因子的估計誤差最大只有 5%。
如果數據庫配置(DB CFG)不能提供 NUM_FREQVALUES 和 NUM_QUANTILES 的值,那麼可以在執行 RUNSTATS 時顯式定義:
RUNSTATS ON TABLE SAMPLE.CARS WITH DISTRIBUTION ON COLUMNS (TYPE NUM_FREQVALUES 10 NUM_QUANTILES 20, STATE NUM_FREQVALUES 15 NUM_QUANTILES 30) AND INDEXES ALL
如何檢查是否存在分布統計信息
為檢查某個表的分布統計信息是否已收集,可以查看分類視圖 SYSCAT.COLDIST 的內容:
SELECT * FROM SYSCAT.COLDIST WHERE TABSCHEMA = 'SAMPLE' AND TABNAME = 'CARS'
視圖 SYSCAT.COLDIST 結構如下:
表 4. SYSCAT.COLDIST 的結構
列名 數據類型 是否可以為空 描述 TABSCHEMA VARCHAR(128) 不可以 本條目對應的表的限定符 TABNAME VARCHAR(128) 不可以 本條目對應的表的名稱 COLNAME VARCHAR(128) 不可以 本條目對應的列的名稱 TYPE CHAR(1) 不可以 F = Frequency(最大頻率)
Q = 分位數值
SEQNO SMALLINT 不可以 如果 TYPE = F,則該列中的 N 表示第 N 頻繁的值如果 TYPE = Q,那麼該列中的 N 表示第 N 個分位數值
COLVALUE VARCHAR(254) 可以 數據值,其形式為字符字面值,或者一個 NULL 值 VALCOUNT BIGINT 不可以 如果 TYPE = F,那麼 VALCOUNT 是 COLVALUE 出現在該列中的次數如果 TYPE = Q,那麼 VALCOUNT 是其值小於或等於 COLVALUE 的行的數量
DISTCOUNT BIGINT 可以 如果 TYPE = Q,那麼該列記錄小於或等於 COLVALUE 的不同值的數量(如果沒有,則為 NULL)僅在收集了一個表中至少一個列的分布統計信息時,SYSCAT.COLDIST 才會包含關於該表的條目。如果在沒有 WITH DISTRIBUTION 的情況下再次執行 RUNSTATS,那麼 SYSCAT.COLDIST 中與該表對應的條目將被刪除。
分布統計信息和參數標記/主變量
JDBC 提供了兩種途徑來執行動態 SQL,因而也提供了兩種不同的接口:
Java.sql.Statement
Java.sql.PreparedStatement
PreparedStatement 是 Statement 的子接口,它允許使用參數標記(= 占位符;在其他編程語言中,此類占位符也被稱為主變量) —— 而不是 Statement。在使用 PreparedStatement 的情況下,首先編譯要執行的包括參數標記的 SQL 語句,然後將值綁定到參數標記,最後執行 SQL 語句。
下面的代碼片段顯示使用 Statement 與使用 PreparedStatement 的不同之處。
清單 3. 使用 JDBC Statement 接口執行動態 SQL
Java.sql.Connection con = ...;
Java.sql.Statement stmt1 = con.createStatement();
String insert1 = "INSERT INTO TABLE_X (COL_Y) VALUES ('ABC')";
stmt1.executeUpdate(insert1);
Java.sql.Statement stmt2 = con.createStatement();
String insert2 = "INSERT INTO TABLE_X (COL_Y) VALUES ('XYZ')";
stmt2.executeUpdate(insert2);
con.commit();
清單 4. 使用 JDBC PreparedStatement 接口執行動態 SQL
Java.sql.Connection con = ...;
String insert = "INSERT INTO TABLE_X (COL_Y) VALUES (?)";
Java.sql.PreparedStatement pstmt = con.prepareStatement(insert);
pstmt.setString(1, "ABC");
pstmt.executeUpdate();
pstmt.setString(1, "XYZ");
pstmt.executeUpdate();
con.commit();
如果一條簡單 SQL 語句執行多次(例如示例中的 INSERT 語句),那麼使用 PreparedStatement 有優勢,因為數據庫只需編譯該語句一次,即可多次執行,而不需要重復編譯。假設在示例中需要插入數千行記錄,那麼使用 PreparedStatement 可以交付更短的執行時間,因為只需一次准備/編譯時間,而不需要數千次。
然而,Java 開發人員使用 PreparedStatement 往往是因為需要在運行時提供值/過濾器標准時,使用這種接口編寫的代碼更為優雅。請看如下代碼片段:
清單 5. 使用字符串串聯填充過濾標准
int state = 100;
String type = "A";
...
Java.sql.Connection con = ...;
Java.sql.Statement stmt = con.createStatement();
String select = "SELECT * FROM CARS WHERE
STATE < " + state + " AND TYPE = '" + type + "'";
Java.sql.ResultSet rs = stmt.executeQuery(select);
while (rs.next()) {
...
}
清單 6. 使用參數標記填充過濾標准
int state = 100;
String type = "A";
...
Java.sql.Connection con = ...;
String select = "SELECT * FROM CARS WHERE STATE < ? AND TYPE = ?";
Java.sql.PreparedStatement pstmt = con.prepareStatement(select);
pstmt.setInt(1, state);
pstmt.setString(2, type);
Java.sql.ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
...
}
使用 PreparedStatement 的那種代碼片段在編碼方面更為優雅,因為在將 STATE 和 TYPE 的值置入 SQL 語句時,不需要進行字符串運算。但這種方法存在一個缺點,在綁定 WHERE 子句中謂詞的值之前,需要編譯 SELECT(創建訪問計劃)。為使優化器能夠使用可用的分布統計信息,帶有具體值的謂詞極為重要。
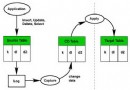
讓我們再次看看 CARS 表的查詢示例,但這次使用參數標記,而不是具體值:
SELECT * FROM CARS WHERE STATE < ? AND TYPE = ?
CARS 表的分布統計信息仍然可用,因為在此期間這些統計信息也已經被收集。然而,使用參數標記時,將生成另一個訪問計劃。
圖 3. 有參數標記和分布統計信息時示例查詢的訪問計劃