簡介
在有效地使用數據資料庫之前,通常需要從很多數據源創建或者更新資料庫。最常見的情況是,在外部系統上累積數據(供以後更新資料庫使用),這些數據的格式也與資料庫的要求有所不同。獲得這些數據並將其轉化成有用、一致、准確的數據的過程通常稱為 ETL,其中的三個字母分別代表提取(Extraction)、轉換(Transformation)和加載(Load)。
提取就是從源系統中獲取數據(無論是何種格式)。這個過程可能很簡單,只需要從數據庫或者電子表格轉儲文本文件(flat file);也可能很復雜,需要建立與外部系統的聯系,然後控制數據到目標系統的傳輸。
轉換通常不僅僅是數據格式的轉換(雖然這是將數據導入系統的關鍵一步)。外部系統中的數據可能包含不一致或者不正確的信息,這取決於外部系統上實施的檢查和平衡。轉換步驟的一部分是"淨化"或"拒絕"不符合條件的數據。這個階段常用的技術包括字符檢查(拒絕包含字符的數值性數據)和范圍檢查(拒絕超出可接受范圍的數據)。被拒絕的記錄通常存放在單獨的文件中,然後使用更復雜的工具處理,或者手工改正問題。然後將這些數據合並到已轉換集合中。
加載階段將獲取並轉換的數據存放到新的數據存儲中(數據倉庫、數據集市等)。對於 DB2 UDB,該過程可以用 SQL 命令(IMPORT)、工具(LOAD)或集成工具(Data Warehouse Manager 和 Information Integrator)來完成。另外,整個 ETL 過程也可使用第三方應用程序來完成,這樣做通常可以減少編程,或者不需要自己編程。
ETL 過程可能非常簡單,只需要將一些數據從一個表傳遞到相同系統中的另一個表。也可能非常復雜,需要從數千英裡之外的完全不同的系統獲取數據,然後重新安排和重新格式化,使其符合完全不同的系統。下面將描述完整的 ETL 到 DB2 UDB 的方法(但不一定沒有遺漏)。只要有可能,我會提供有關該方法的詳細信息的鏈接。
DB2 IMPORT
DB2 UDB 導入(IMPORT)工具使用 SQL INSERT 語句將輸入文件中的數據寫入表或者視圖中。如果目標表或視圖已經包含這些數據,那麼可以選擇替換原來的數據或者將這些數據追加到原有數據後面。
導入工具把輸入文件中的數據插入表或者可更新的視圖。如果接收到入數據的表或視圖已經包含數據,可以代替原來的數據或者追加。
導入數據需要以下信息:
輸入文件的路徑和名稱。
目標表或者視圖的名稱或別名。
輸入文件中的數據格式,這種格式可以是 IXF、WSF、DEL 或 ASC。
輸入數據要插入表中,還是要插入視圖中,要輸入數據更新還是替換表或視圖中的原有數據。
如果通過應用程序編程接口(API)aqluimpr 調用該工具,那麼還需要一個信息文件名。
如果處理類型化的表,可能需要提供處理所有結構化類型的方法或順序。從上到下、從左到右地處理上級表,按層次結構處理子表,這樣的順序稱為遍歷順序。在表層次結構間移動數據時,這個順序很重要,因為它決定了移動的數據相對於其他數據的位置。在處理類型化的表時,可能還需要提供子表清單。該清單指出將哪一個子表或者屬性導入數據。
您還可以規定:
導入數據的方法:列位置、列名或相對列位置。
向表提交更改前插入的行數。定期請求 COMMIT 會減少重要操作中因為失敗或者出現 ROLLBACK 所損失的行數。還可以防止因為處理的輸入文件過大而導致 DB2 日志被填滿。
開始導入前要跳過的文件記錄數。如果出現錯誤,可以從成功導入並提交的最後一行後面重新開始導入操作。
要插入數據的表或視圖的列名。
信息文件名。DB2 執行數據導出、導入、加載、綁定或恢復操作時,可以指定一個信息文件,DB2 會創建該文件中包含與這些操作有關的錯誤、警告和提示信息。應在 MESSAGES 參數中指定這些文件名。這些信息文件是標准的 ASCII 文本文件。信息文件中的每條信息都從一個新行開始,包含 DB2 信息檢索設施所提供的信息。可以使用操作系統提供的打印過程進行打印,並且可以使用任何 ASCII 編輯器進行查看。
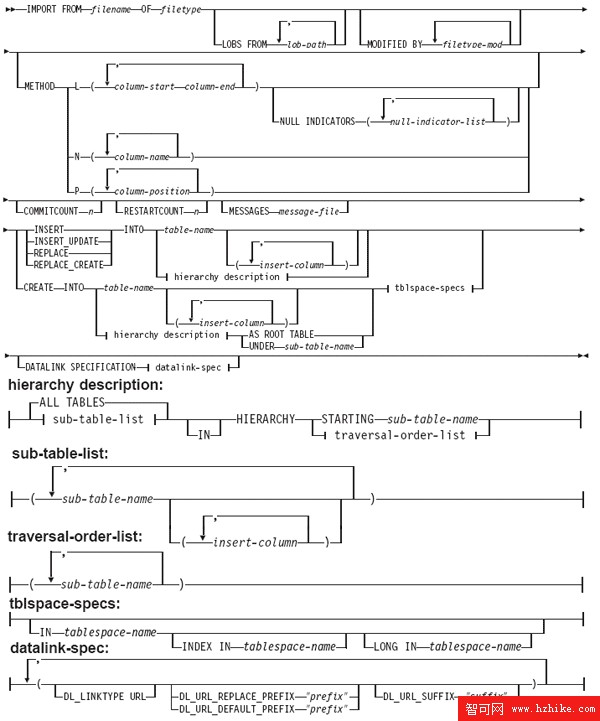
DB2 IMPORT 命令
圖 1. DB2 IMPORT 命令
DB2 IMPORT 例子
DB2 IMPORT 要求要填充的表已經存在。一旦執行了數據庫的 DDL,將逗號分隔數據導入多個表的典型 DB2 腳本如下所示:
CONNECT TO Library;
DELETE FROM Volume;
IMPORT FROM Volume.csv OF DEL INSERT INTO Volume;
DELETE FROM Story;
IMPORT FROM Story.csv OF DEL INSERT INTO Story;
DELETE FROM Volume_Title;
IMPORT FROM Volume_Title.csv OF DEL INSERT INTO Volume_Title;
DELETE FROM Volume_Publisher;
IMPORT FROM Volume_Publisher.csv OF DEL INSERT INTO Volume_Publisher;
DELETE FROM Author;
IMPORT FROM Author.csv OF DEL INSERT INTO Author;
DELETE FROM Story_Title;
IMPORT FROM Story_Title.csv OF DEL INSERT INTO Story_Title;
COMMIT;
TERMINATE;
DB2 LOAD
LOAD 工具可以高效地將大量數據轉移到新建表中,或者插入已經包含數據的表中。該工具能夠處理大多數數據類型,其中包括大型對象(LOB)和用戶定義類型(UDT)。LOAD 工具比 IMPORT 工具速度快,因為它直接將格式化的頁寫入數據庫,而 IMPORT 工具要執行 SQL INSERT 操作。LOAD 工具不會激活觸發器,也不執行參照檢查或表約束檢查(除了驗證索引的惟一性)。LOAD 過程包括 4 個不同的階段。
加載過程的 4 個階段(加載、構建、刪除和索引復制)
Load 操作開始執行時,目標表處於 load-in-progress 狀態。如果表有約束條件,那麼表會進入 check-pending 狀態。如果指定 ALLOW READ ACCESS 選項,那麼表會進入 read-Access-only 狀態。
圖 2. DB2 LOAD 的執行階段

加載階段將數據寫入表。加載過程中,數據被裝載到表中,如果需要的話,還可以搜集索引鍵和表的統計信息。按照 LOAD 命令中的 SAVECOUNT 參數指定的時間間隔來建立保存點(save point)或者一致性點(point of consistency)。保存點上生成信息,說明當前已經成功加載了多少行。對於使用 FILE LINK CONTROL 定義的 DATALINK 列,可以對非空列值執行鏈接操作。如果操作失敗,可以重新啟動加載操作,RESTART 選項自動從上一次成功的一致性點重新啟動加載操作。TERMINATE 選項滾回失敗的加載操作。
構建階段生成索引。在構建階段,按照加載階段搜集的索引鍵生成索引。加載過程中索引鍵被排序,並且收集了索引的統計信息(如果 INDEXES 選項指定了 STATISTICS YES)。這些統計信息與 RUNSTATS 命令收集的信息類似。如果構建階段失敗,RESTART 選項自動從適當的位置重新啟動加載操作。
刪除階段將表中造成惟一鍵沖突或者 DATALINK 沖突的行刪除。如果指定了異常表,則有惟一鍵沖突的行會被放在異常表中,關於被拒絕行的信息被寫入信息文件。加載過程結束後,還要查看這些信息,解決存在的問題,然後向表中插入正確的行。不要試圖刪除或修改加載工具創建的任何臨時文件。某些臨時文件對於刪除階段非常重要。如果刪除階段失敗,RESTART 選項可以從適當的位置重新啟動加載操作。提示:每個刪除事件都記錄到日志中,如果有大量記錄違反了惟一性條件,那麼刪除階段中日志文件可能被填滿。
索引復制階段將索引數據從系統臨時表空間復制到原始表空間。只有在加載操作中指定 READ Access 選項,並為索引創建指定了系統臨時表空間時,才會執行這個步驟。
加載數據需要以下信息:
輸入文件、命名管道或設備的路徑和名稱。
目標表的名稱或別名。
輸入源的格式,可以是 DEL、ASC、PC/IXF 或 CURSOR。
輸入數據是追加到表中,還是代替原來的數據。
如果通過應用程序編程接口(API)db2Load 調用該工具,那麼還需要指定信息文件名。
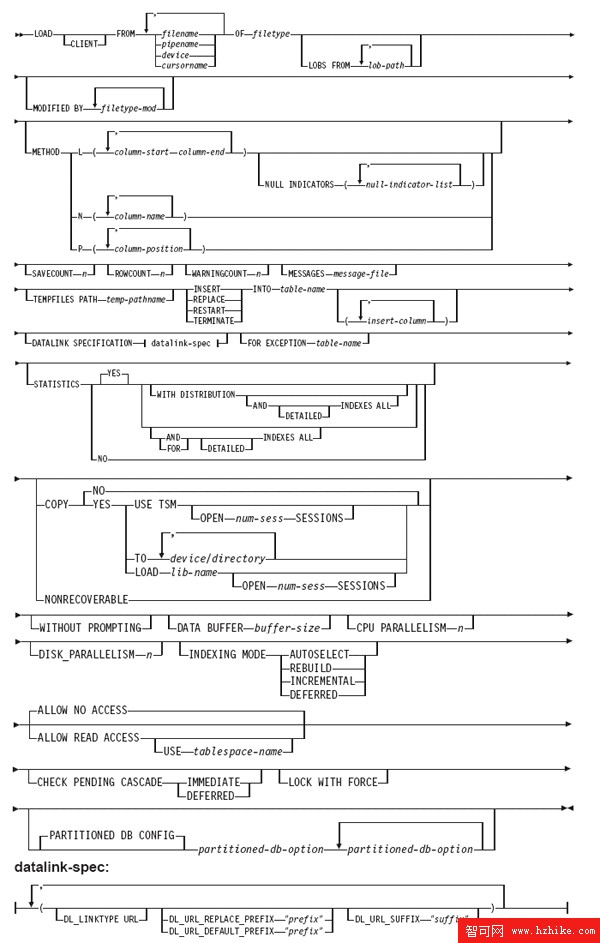
DB2 LOAD 命令
圖 3. DB2 LOAD 命令
DB2 LOAD 例子
與 IMPORT 相同,LOAD 工具也要求表的結構已經建立。對於 附錄 A 中定義的數據庫,將逗號分隔的數據 LOAD 到多個表中的典型腳本如下所示:
CONNECT TO Library;
DELETE FROM Volume;
LOAD FROM Volume.csv OF DEL INSERT INTO Volume;
DELETE FROM Story;
LOAD FROM Story.csv OF DEL INSERT INTO Story;
DELETE FROM Volume_Title;
LOAD FROM Volume_Title.csv OF DEL INSERT INTO Volume_Title;
DELETE FROM Volume_Publisher;
LOAD FROM Volume_Publisher.csv OF DEL INSERT INTO Volume_Publisher;
DELETE FROM Author;
LOAD FROM Author.csv OF DEL INSERT INTO Author;
DELETE FROM Story_Title;
LOAD FROM Story_Title.csv OF DEL INSERT INTO Story_Title;
COMMIT;
TERMINATE;
在數據分區環境中加載數據
在分區數據庫中,大量的數據分散在多個分區中。分區鍵用來確定數據的各部分位於哪一個數據庫分區中。將數據加載到正確的數據庫分區之前,必須先對數據進行分區。
分區加載的概念和術語
討論在分區數據庫環境中加載工具的行為和操作時,要用到以下術語:
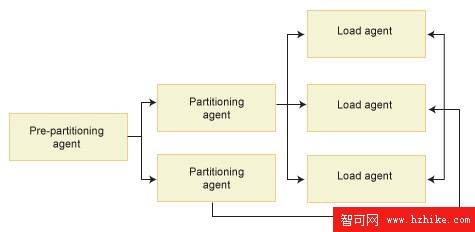
調度分區是用戶連接並在其上執行加載操作的數據庫分區。在 PARTITION_AND_LOAD、PARTITION_ONLY 和 ANALYZE 模式下,通常會假定數據文件在這個分區上,除非加載命令中指定了 CLIENT 選項。指定加載命令的 CLIENT 選項表明要加載的數據位於遠程連接的客戶機上。
在 PARTITION_AND_LOAD、PARTITION_ONLY 和 ANALYZE 模式下,預分區代理將讀入用戶數據,並以輪詢的方式將這些數據分發給數據分區的分區代理。這些過程都是在調度分區上執行的。任何加載操作都只允許每個分區最多能有一個分區代理。
在 PARTITION_AND_LOAD、LOAD_ONLY 和 LOAD_ONLY_VERIFY_PART 模式下,加載代理在每個輸出分區上運行並調度該分區上的數據加載。
PARTITION_ONLY 加載操作過程中,文件代理加載在每個輸出分區上運行。它們從分區代理接收數據並寫入所在分區的文件。
文件傳輸命令代理在調度分區上運行,負責執行文件傳輸命令。
圖 4. 分區數據庫加載概略圖。預分區代理讀入源數據,數據被近似地分成兩半傳遞給兩個分區代理,分區代理對數據進行分區,並將它們發送到三個數據庫分區中的一個分區中。每個分區的加載代理加載數據。
在分區數據庫環境中加載數據時,加載工具可以執行以下操作:
並行對輸入數據分區。
在相應的數據庫分區中同時加載數據。
從一個系統將數據傳輸到另一個系統。
分區數據庫加載操作發生在兩個階段:建立階段獲取分區資源(如表鎖),加載階段將數據裝入分區。可以使用 LOAD 命令 ISOLATE_PART_ERRS 選項決定這兩個階段出現錯誤時該如何處理,一個或多個分區的錯誤對其他沒有錯誤的分區的加載操作有什麼影響。
將數據加載到分區數據庫可以選擇使用以下模式:
PARTITION_AND_LOAD:對數據進行分區(可以並行),並將它們加載到相應的數據庫分區中。
PARTITION_ONLY:對數據進行分區(可以並行),並將它們輸出到寫入每個加載分區上的指定位置的文件中。每個文件都包括分區頭,規定數據是如何分區的,可以使用 LOAD_ONLY 模式將這些文件加載到數據庫中。
LOAD_ONLY:假設數據已經分區,跳過分區過程,將數據同時加載到相應的數據庫分區中。
LOAD_ONLY_VERIFY_PART:假定數據已經分區,但數據文件沒有包含分區頭。跳過分區過程,數據被同時裝載到相應的數據庫分區中。在加載過程中,要檢查每一行,查看它們是否在正確的分區中。如果制定轉儲文件類型限定符,那麼包含分區沖突的行將存放到一個轉儲文件中。否則就要拋棄這些行。如果某個加載分區存中發生分區沖突,那麼要將一個警告寫入該分區的加載信息文件中。
ANALYZE:生成優化的可能跨越所有數據庫分區的分區映射。
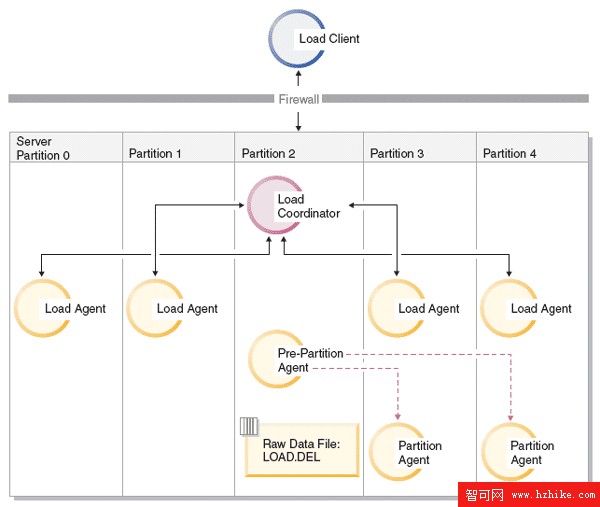
DPF LOAD 的例子
下面的例子將 附錄 A 所述的 "Story" 數據裝載到一個 5 分區系統的兩個分區中。
LOAD FROM LOAD.DEL OF DEL
REPLACE INTO Story
PARTITIONED DB CONFIG
PARTITIONING_DBPARTNUMS (3,4)
下圖說明了處理這個多分區加載任務所產生的不同代理。
圖 5. 分區加載過程
DB2 Business Intelligence 產品
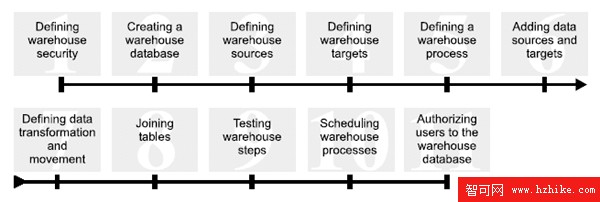
IMPORT 和 LOAD 工具只能處理 ETL 的加載部分,與此相比,DB2 Business Intelligence Products 提供了更健壯的 ETL 方法。Data Warehouse Center 提供了一個完整的過程,支持數據倉庫的創建、數據源和目標的定義、數據的轉換和移動,以及數據倉庫的日常維護。Data Warehouse Manager 又添加了 Information Catalog 來管理元數據。最後,DB2 UDB Data Warehouse Edition (DWE) 結合了 DB2、OLAP Tools 和 Information Integration Tools 的所有這些特性,並且可以統一安裝。
圖 6. 創建數據倉庫的步驟
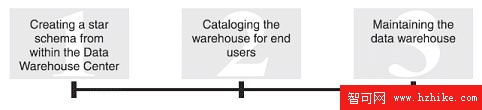
另一個 DB2 手冊 BI Tutorial: Extended Lessons in Data Warehousing ,描述了其他過程,如下圖所示。
圖 7. 其他數據倉庫步驟
在上面幾節中,手工定義了 Library 數據倉庫中的表,然後使用調用 IMPORT 或 LOAD 工具的腳本填充這些表。通過 Data Warehouse Center,這些任務可以用圖形化的界面完成。下面幾節將簡要說明如何利用 WDC 開發和維護 Library 數據倉庫。有關的更多細節,請參閱上面提到的教程手冊。
定義倉庫安全性
數據倉庫安全由倉庫控制數據庫來管理。一旦指定了該數據庫,它就會保存倉庫的元數據,其中包括用戶和口令。因此,在訪問 Data Warehouse Center (DWC) 之前,必須指定或創建一個倉庫控制數據庫,然後定義用戶和組,並分配適當的權限。
創建倉庫數據庫
倉庫將建立在一個名為 Library 的數據庫中。DWC 通過 ODBC 與倉庫數據庫進行通信,因此一定要將倉庫和控制數據注冊為支持 ODBC 訪問的數據庫。
定義倉庫源
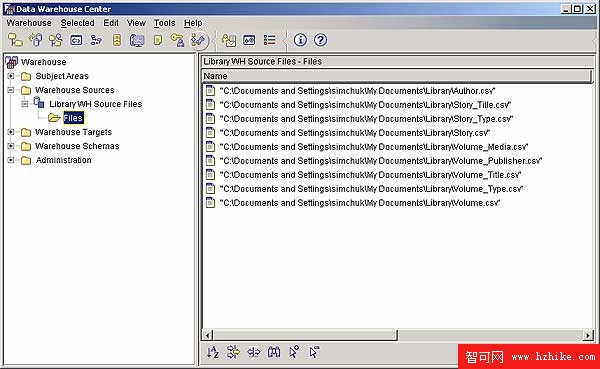
Library 倉庫的所有源數據都來自從 Excel 電子表格中提取的逗號分隔文件(參見 附錄 A 中的示例數據)。DWC 從這些文件導入數據之前,這些文件必須被定義成倉庫源。支持的源類型有多種,這裡選擇本地文本文件作為每個表的源。定義所有的源之後,DWC Sources 將如下所示:
圖 8. 倉庫源文件
定義倉庫目標
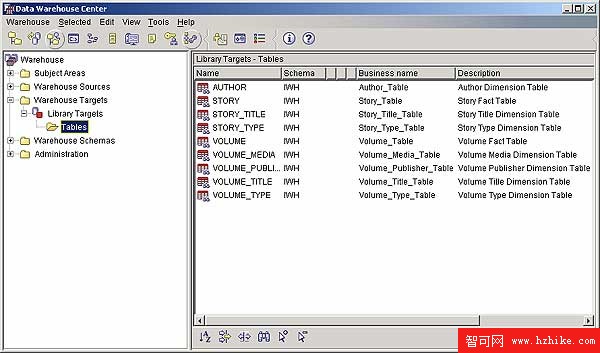
倉庫目標通常是倉庫中包含維(dimension)和實際數據的表,該例中要定義與每個源文件匹配的表。
圖 9. 倉庫目標表
定義倉庫過程
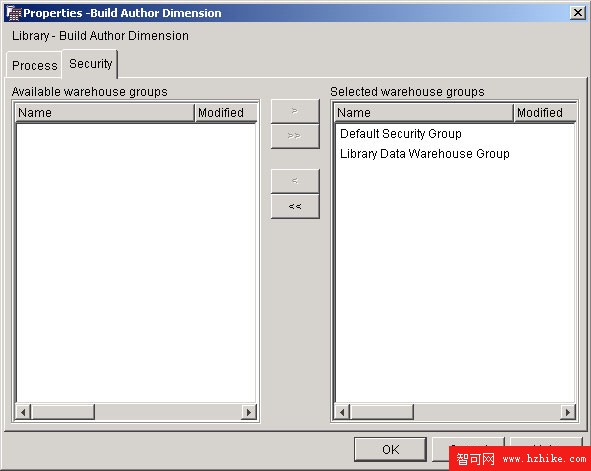
現在已經定義了源和目標,還需要一種將其連接起來的方法。該例中使用 9 個不同的過程,每個過程都講一個文本文件映射到相應的 DB2 表。這些過程是按照 DWC 中的 Subject Areas 組織的。首先創建一個 Subject Area (Library)。這樣將在 Library 下自動創建一個 Processes 文件夾。右擊 Processes 文件夾創建需要的 9 個過程。一定要將您的組移動到每個定義適當的 Security 選項卡中。現在創建的僅僅是占位符,以後還要添加源、目標和操作。Author 數據的 Process and Security 選項卡應該如下圖所示:
圖 10. 定義倉庫過程
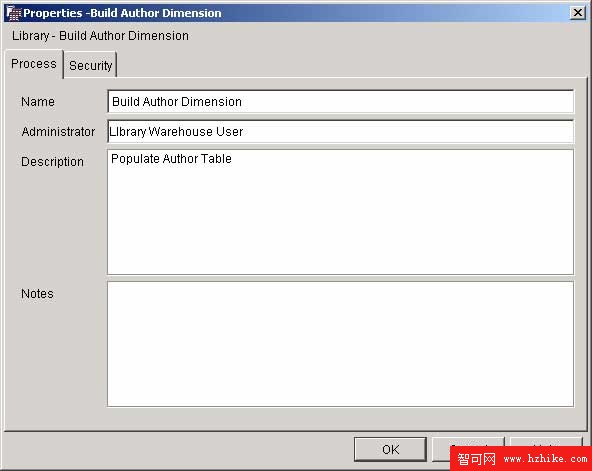
圖 11. 定義倉庫過程的安全性
定義所有的過程之後,DWC 樹看起來將如下所示:
圖 12. 倉庫過程
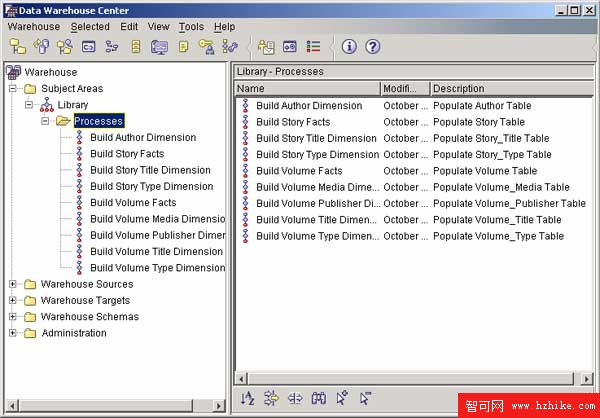
向過程中添加數據源和目標
DWC 支持用圖像化的方式構建過程。因為要創建 9 個類似的過程,這裡只討論開發 Author 過程的步驟。其他過程的開發都與此類似。
在 Processes 樹中,雙擊 Build Author Dimension 項打開圖形化界面,在這裡可以規定源、目標、操作和數據路徑。這項操作要用到三個圖標:
圖 13. 過程定義圖標
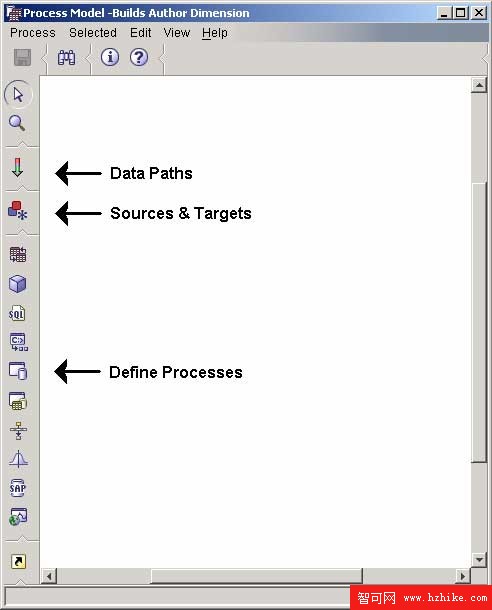
首先選擇 Sources and Targets 圖標,然後再次單擊希望出現的位置。從彈出的窗口的 Warehouse Sources 樹上選擇文件,對目標表(Author)重復這個過程。
在 Define Processes 圖標中依次選擇 DB2 UDB 、Load。
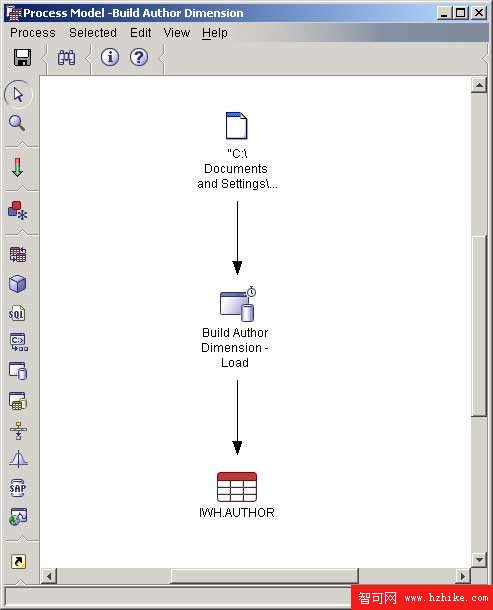
這就定義了一個 DB2 LOAD 過程,然後通過 Data Paths 將其連接到源表和目標表。選中 Data Paths 圖標並選擇 Data Link 彈出菜單,鼠標指針變成一個下箭頭,單擊 Source File,並將其拖動到 Load Process 中。然後重復這個操作,再將其從 Load Process 拖動到 Target Table 。保存過程前,一定要將 PropertIEs 窗口中的 Load Mode 從 INSERT 改為 REPLACE。這樣就可以定期更新數據,而不需要成批管理它們(因為數據量很少,可以每周重新加載一次,而不必執行遞增更新)。
畫面如下圖所示:
圖 14. 過程定義
測試倉庫步驟
右擊 Load Process,並將 Mode 從 Development 改為 Test。注意,過程和目標表上現在都出現了一把鎖。如果右擊目標表請求顯示示例內容,就會看到一個空的窗口(因為還沒有填充表)。