Map-Reduce是一種計算模型,簡單的說就是將大批量的工作(數據)分解(MAP)執行,然後再將結果合並成最終結果(REDUCE)。
MongoDB提供的Map-Reduce非常靈活,對於大規模數據分析也相當實用。
以下是MapReduce的基本語法:
>db.collection.mapReduce(
function() {emit(key,value);}, //map 函數
function(key,values) {return reduceFunction}, //reduce 函數
{
out: collection,
query: document,
sort: document,
limit: number
}
)
使用 MapReduce 要實現兩個函數 Map 函數和 Reduce 函數,Map 函數調用 emit(key, value), 遍歷 collection 中所有的記錄, 將key 與 value 傳遞給 Reduce 函數進行處理。
Map 函數必須調用 emit(key, value) 返回鍵值對。
參數說明:
考慮以下文檔結構存儲用戶的文章,文檔存儲了用戶的 user_name 和文章的 status 字段:
>db.posts.insert({
"post_text": "菜鳥教程,最全的技術文檔。",
"user_name": "mark",
"status":"active"
})
WriteResult({ "nInserted" : 1 })
>db.posts.insert({
"post_text": "菜鳥教程,最全的技術文檔。",
"user_name": "mark",
"status":"active"
})
WriteResult({ "nInserted" : 1 })
>db.posts.insert({
"post_text": "菜鳥教程,最全的技術文檔。",
"user_name": "mark",
"status":"active"
})
WriteResult({ "nInserted" : 1 })
>db.posts.insert({
"post_text": "菜鳥教程,最全的技術文檔。",
"user_name": "mark",
"status":"active"
})
WriteResult({ "nInserted" : 1 })
>db.posts.insert({
"post_text": "菜鳥教程,最全的技術文檔。",
"user_name": "mark",
"status":"disabled"
})
WriteResult({ "nInserted" : 1 })
>db.posts.insert({
"post_text": "菜鳥教程,最全的技術文檔。",
"user_name": "runoob",
"status":"disabled"
})
WriteResult({ "nInserted" : 1 })
>db.posts.insert({
"post_text": "菜鳥教程,最全的技術文檔。",
"user_name": "runoob",
"status":"disabled"
})
WriteResult({ "nInserted" : 1 })
>db.posts.insert({
"post_text": "菜鳥教程,最全的技術文檔。",
"user_name": "runoob",
"status":"active"
})
WriteResult({ "nInserted" : 1 })
現在,我們將在 posts 集合中使用 mapReduce 函數來選取已發布的文章(status:"active"),並通過user_name分組,計算每個用戶的文章數:
>db.posts.mapReduce(
function() { emit(this.user_name,1); },
function(key, values) {return Array.sum(values)},
{
query:{status:"active"},
out:"post_total"
}
)
以上 mapReduce 輸出結果為:
{
"result" : "post_total",
"timeMillis" : 23,
"counts" : {
"input" : 5,
"emit" : 5,
"reduce" : 1,
"output" : 2
},
"ok" : 1
}
結果表明,共有4個符合查詢條件(status:"active")的文檔, 在map函數中生成了4個鍵值對文檔,最後使用reduce函數將相同的鍵值分為兩組。
具體參數說明:
使用 find 操作符來查看 mapReduce 的查詢結果:
>db.posts.mapReduce(
function() { emit(this.user_name,1); },
function(key, values) {return Array.sum(values)},
{
query:{status:"active"},
out:"post_total"
}
).find()
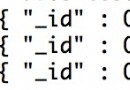
以上查詢顯示如下結果,兩個用戶 tom 和 mark 有兩個發布的文章:
{ "_id" : "mark", "value" : 4 }
{ "_id" : "runoob", "value" : 1 }
用類似的方式,MapReduce可以被用來構建大型復雜的聚合查詢。
Map函數和Reduce函數可以使用 JavaScript 來實現,使得MapReduce的使用非常靈活和強大。