Order by desc/asc limit M是我在mysql sql優化中經常遇到的一種場景,其優化原理也非常的簡單,就是利用索引的有序性,優化器沿著索引的順序掃描,在掃描到符合條件的M行數據後,停止掃描;看起來非常的簡單,但是我經常看到很多性能較差的sql沒有利用這個優化規律,下面將結合一些實際的案例來分析說明:
案例一:
一條sql執行非常的慢,執行時間為:
root@test 02:00:44 SELECT * FROM test_order_desc WHERE END_TIME>now() ORDER BY GMT_CREATE DESC,count_num DESC LIMIT 12, 12; +---------+-----------+------------+------+---------------------+---------------------+------------------- Data1..................................................................................................... Data2..................................................................................................... +---------+-----------+------------+------+---------------------+---------------------+------------------- 12 ROWS IN SET (0.49 sec)
執行計劃如下:
root@test_db01:53:23 EXPLAIN SELECT * FROM test_order_desc WHERE END_TIME > now() ORDER BY GMT_CREATE DESC,count_num DESC LIMIT 12, 12; +----+-------------+----------+-------+-----------------+-----------------+---------+------+--------+----- | id | select_type | TABLE | TYPE | possible_keys | KEY | key_len | REF | ROWS | Extra | +----+-------------+----------+-------+-----------------+-----------------+---------+------+--------+----- | 1 | SIMPLE | test_order_desc | range | ind_hot_endtime | ind_hot_endtime | 9 | NULL | 113549 | USING WHERE; USING filesort | +----+-------------+----------+-------+-----------------+-----------------+---------+------+--------+-----
Ind_hot_endtime索引為:
root@test_db01:52:45:SHOW INDEX FROM test_order_desc; Ind_hot_endtime(end_time,count_num)
在注意到sql中滿足過濾條件end_time>now()的有113549行,在加上剩余的條件中含有order by,這樣會造成排序的結果集非常的大,執行非常的耗費資源;於是分析sql,在sql中包括了order by desc limit這樣的排序條件後,新增適當的索引滿足排序的條件,同時由於有limit的限制結果集,當掃描到滿足條件的行數後退出查詢,那麼我們來看看優化效果:
添加索引:
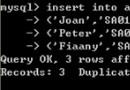
root@test 02:01:06:ALTER TABLE test_order_desc ADD INDEX ind_gmt_create(gmt_create,count_num); Query OK, 211945 ROWS affected (6.71 sec) Records: 211945 Duplicates: 0 Warnings: 0
再次執行sql,觀察其執行時間:
root@test 02:01:35: SELECT * FROM test_order_desc WHERE END_TIME > now() ORDER BY GMT_CREATE DESC,count_num DESC LIMIT 12, 12; +---------+-----------+------------+------+---------------------+---------------------+ col2................................................................................... +---------+-----------+------------+------+---------------------+---------------------+ Data1.................................................................................. Data2.................................................................................. +---------+-----------+------------+------+---------------------+---------------------+ 12 ROWS IN SET (0.00 sec)
可以看到執行時間已經降到了毫秒以下,查看其執行計劃:
root@test 02:01:42: EXPLAIN SELECT * FROM test_order_desc WHERE END_TIME > now() ORDER BY GMT_CREATE DESC,count_num DESC LIMIT 12, 12; +----+-------------+----------+-------+-----------------+----------------+---------+------+------+-------------+ | id | select_type | TABLE | TYPE | possible_keys | KEY | key_len | REF | ROWS | Extra | +----+-------------+----------+-------+-----------------+----------------+---------+------+------+-------- | 1 | SIMPLE | test_order_desc | INDEX | ind_hot_endtime | ind_gmt_create | 14 | NULL | 48 | USING WHERE |
可以看到優化器已經選擇了ind_gmt_create索引掃描,這樣的話就避免了對結果集進行排序的過程,同時優化器預估掃描14行數據就會得到滿足查詢條件的數據(END_TIME > now()),執行計劃非常的理想。
root@127.0.0.1 : test_db 16:05:15: EXPLAIN SELECT b.*,a.*,k.* FROM instance b LEFT OUTER JOIN image a ON b.image_id=a.image_id LEFT OUTER JOIN key_pair k ON b.key_pair_id=k.key_pair_id LEFT OUTER JOIN region_alias r_a ON r_a.region_no=b.region_no WHERE b.STATUS IN (1,8) AND b.user_id = 21 AND r_a.big_region_no='regeion_xx' ORDER BY b.instance_no ASC LIMIT 37300,50;
案例二:
root@127.0.0.1 : test_db 16:05:15: EXPLAIN SELECT b.*,a.*,k.* FROM instance b LEFT OUTER JOIN image a ON b.image_id=a.image_id LEFT OUTER JOIN key_pair k ON b.key_pair_id=k.key_pair_id LEFT OUTER JOIN region_alias r_a ON r_a.region_no=b.region_no WHERE b.STATUS IN (1,8) AND b.user_id = 21 AND r_a.big_region_no='regeion_xx' ORDER BY b.instance_no ASC LIMIT 37300,50;
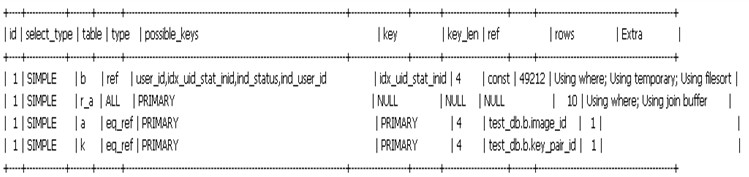
B表的idx_uid_stat_inid的索引列包括了(user_id,status,instance_no):

我們從執行計劃上分析來看,表的連接順序為:b—>r_a—>a—>k,可以看到執行計劃的第一行中需要掃描49212行的數據,同時由於status采用的是in的方式,instance_no即使在索引中也用不上,這樣就導致了排序使用到了臨時表,這也是導致sql執行慢的原因。我們看到sql中的最後一個排序為order by b.instance_no asc limit 37300,50,這裡我們好像可以看到優化的曙光,調整數據庫的索引以滿足B表的排序需求:
root@127.0.0.1 : test_db 16:05:04 ALTER TABLE instance ADD INDEX ind_user_id(user_id,instance_no); Query OK, 0 ROWS affected (0.56 sec)
調整索引後查看執行計劃:
root@127.0.0.1 : test_db 16:09:42 EXPLAIN SELECT b.*,a.*,k.* FROM instance b LEFT OUTER JOIN image a ON b.image_id=a.image_id LEFT OUTER JOIN key_pair k ON b.key_pair_id=k.key_pair_id LEFT OUTER JOIN region_alias r_a ON r_a.region_no=b.region_no WHERE b.STATUS IN (1,8) AND b.user_id = 21 AND r_a.big_region_no='regeion_xx' ORDER BY b.instance_no ASC LIMIT 37300,50;
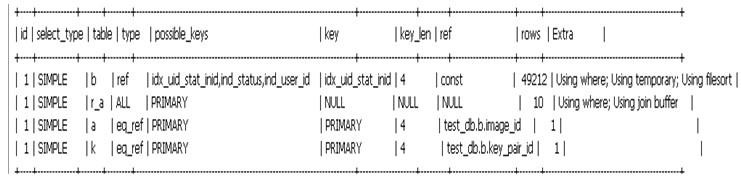
我們加上force index強制走我們新加的索引:
root@127.0.0.1 : test_db 16:10:24 EXPLAIN SELECT b.*,a.*,k.* FROM instance b force INDEX (ind_user_id) LEFT OUTER JOIN image a ON b.image_id=a.image_id LEFT OUTER JOIN key_pair k ON b.key_pair_id=k.key_pair_id LEFT OUTER JOIN region_alias r_a ON r_a.region_no=b.region_no WHERE b.STATUS IN (1,8) AND b.user_id = 21 AND r_a.big_region_no='regeion_xx' ORDER BY b.instance_no ASC LIMIT 37300,50;

可以看到在加上提示符後,使用到了我們新加的索引,掃描的行數為54580行,執行時間:
root@127.0.0.1 : test_db 16:10:30 SELECT b.*,a.*,k.* FROM instance b force INDEX (ind_user_id) LEFT OUTER JOIN image a ON b.image_id=a.image_id LEFT OUTER JOIN key_pair k ON b.key_pair_id=k.key_pair_id LEFT OUTER JOIN region_alias r_a ON r_a.region_no=b.region_no WHERE b.STATUS IN (1,8) AND b.user_id = 21 AND r_a.big_region_no='regeion_xx' ORDER BY b.instance_no ASC LIMIT 37300,50; (0.49 sec)
原始的執行時間:
root@127.0.0.1 : test_db 16:10:51: SELECT b.*,a.*,k.* FROM instance b LEFT OUTER JOIN image a ON b.image_id=a.image_id LEFT OUTER JOIN key_pair k ON b.key_pair_id=k.key_pair_id LEFT OUTER JOIN region_alias r_a ON r_a.region_no=b.region_no WHERE b.STATUS IN (1,8) AND b.user_id = 21 AND r_a.big_region_no='regeion_xx' ORDER BY b.instance_no ASC LIMIT 37300,50; (1.28 sec)
總結:
Order by desc/asc limit的優化技術有時候在你無法建立很好索引的時候,往往會得到意想不到的優化效果,但有時候有一定的局限性,優化器可能不會按照你既定的索引路徑掃描,優化器需要考慮到查詢列的過濾性以及limit的長度,當查詢列的選擇性非常高的時候,使用sort的成本是不高的,當查詢列的選擇性很低的時候,那麼使用order by +limit的技術是很有效的。