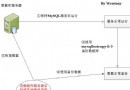
幾個常用用例
幾個有用的示例語句:
select concat('XX',prd_id,'XX',prd_name,'XX') AS ID_TITLE from test.product ORDER BY prd_id into outfile "d:/ID_TITLE.txt";
MySQL -q -s -e "select COLUMNNAME,COLUMNNAME from DATABASENAME.TABLENAME" > D:/mydata.txt
]
一、備份數據庫:(命令在DOS的MySQL\bin目錄下執行)
MySQLdump --opt school>school.bbb
注釋:將數據庫school備份到school.bbb文件,school.bbb是一個文本文件,文件名任取,打開看看你會有新發現。
1.導出整個數據庫
MySQLdump -u 用戶名 -p 數據庫名 > 導出的文件名
MySQLdump -u root -p aikersql> aiker.sql
2.導出一個表
MySQLdump -u 用戶名 -p 數據庫名 表名> 導出的文件名
MySQLdump -u aiker -p aikersql users> aiker_users.sql
3.導出一個數據庫結構
MySQLdump -u root -p -d --add-drop-table aikersql>d:\aiker_db.sql -d 沒有數據 --add-drop-table 在每個create語句之前增加一個drop table 二.導入數據庫
常用source 命令
進入mysql數據庫控制台,如mysql -u root -p MySQL>use 數據庫然後使用source命令,後面參數為腳本文件(如這裡用到的.sql)
mysql>source d:\aiker_db.sql 也可以用 MySQL -uroot -Ddb1 <d:\aiker_db.sql 三、將文本數據轉到數據庫中
1、文本數據應符合的格式:字段數據之間用tab鍵隔開,null值用n來代替. 3 rose 深圳二中 1976-10-10
4 mike 深圳一中 1975-12-23
2、數據傳入命令 load data local infile "文件名" into table 表名;
注意:你最好將文件復制到MySQLbin目錄下,並且要先用use命令打表所在的庫。
MySQL數據導入導出方法與工具介紹(1- myslqimport utility)
MySQLimport文本文件導入工具介紹
本文內容來自Sam's Teach Yourself MySQL in 21 Days一書的部分內容,by Mark Maslakowski
英文原文版權屬原作者所有,中文的部分翻譯有略有增刪;原書講的過於清楚的地方有刪,講的不清楚的地方有增;如果有翻譯的不妥或者不正確的地方,請指正。 翻譯者:David Euler,SCU.
時間:2004/04/24於川大 1).MySQLimport的語法介紹:
mysqlimport位於mysql/bin目錄中,是MySQL的一個載入(或者說導入)數據的一個非常有效的工具。這是一個命令行工具。有兩個參數 以及大量的選項可供選擇。這個工具把一個文本文件(text file)導入到你指定的數據庫和表中。比方說我們要從文件Customers.txt中把 數據導入到數據庫Meet_A_Geek中的表Custermers中:
MySQLimport Meet_A_Geek Customers.txt
注意:這裡Customers.txt是我們要導入數據的文本文件,
而Meet_A_Geek是我們要操作的數據庫,
數據庫中的表名是Customers,這裡文本文件的數據格式必須與Customers表中的記錄格式一致,否則mysqlimport命令將會出錯。 MySQLimport Meet_A_Geek Cus.to.mers.txt
那麼我們將把文件中的內容導入到數據庫Meet_A_Geek 中的Cus表中。
上面的例子中,都只用到兩個參數,並沒有用到更多的選項,下面介紹mysqlimport的選項 2).MySQLimport的常用選項介紹: -d or --delete 新數據導入數據表中之前刪除數據數據表中的所有信息
-f or --force 不管是否遇到錯誤,MySQLimport將強制繼續插入數據
-i or --ignore MySQLimport跳過或者忽略那些有相同唯一 -l or -lock-tables 數據被插入之前鎖住表,這樣就防止了, -r or -replace 這個選項與-i選項的作用相反;此選項將替代 --fIElds-enclosed- by= char 數據以雙引號括起。 默認的情況下數據是沒有被字符括起的。
--fIElds-terminated- by=char 分隔符是句號。您可以用此選項指定數據之間的分隔符。
默認的分隔符是跳格符(Tab)
--lines-terminated- by=str 或者字符。 默認的情況下MySQLimport以newline為行分隔符。 一個新行或者一個回車。
MySQLimport命令常用的選項還有-v 顯示版本(version), -p 提示輸入密碼(passWord)等。 3).例子:導入一個以逗號為分隔符的文件 "1", "ORD89876", "1 Dozen Roses", "19991226"
我們的任務是要把這個文件裡面的數據導入到數據庫Meet_A_Geek中的表格Orders中, bin/MySQLimport –prl –fields-enclosed-by=" –fIElds-terminated-by=, Meet_A_Geek Orders.txt
這個命令可能看起來很不爽,不過當你熟悉了之後,這是非常簡單的。第一部分,bin/mysqlimport ,告訴操作系統你要運行的命令是 mysql/bin目錄下的MySQLimport,選項p是要求輸入密碼,這樣就要求你在改動數據庫之前輸入密碼,操作起來會更安全。 我們用了r選項 是因為我們想要把表中的唯一關鍵字與文件記錄中有重復唯一關鍵字的記錄替換成文件中的數據。我們表單中的數據不是最新的,需要用文件中的數據去更新,因而 就用r這個選項,替代數據庫中已經有的記錄。l選項的作用是在我們插入數據的時候鎖住表,這樣就阻止了用戶在我們更新表的時候對表進行查詢或者更改的操 作。
MySQL數據導入導出方法與工具介紹(2-import from sql files)
批處理導入文件,從sql文件導入數據到數據庫中 翻譯聲明:
本文內容來自Sam's Teach Yourself MySQL in 21 Days一書的部分內容,by Mark Maslakowski
英文原文版權屬原作者所有,中文的部分翻譯有略有增刪;原書講的過於清楚的地方有刪,講的不清楚的地方有增;如果有翻譯的不妥或者不正確的地方,請指正。 翻譯者:David Euler,SCU.
時間:2004/04/24於川大 批處理是一種非交互式運行mysql程序的方法,如同您在mysql中使用的命令一樣,你仍然將使用這些命令。 為了實現批處理,您重定向一個文件到mysql程序中,首先我們需要一個文本文件,這個文本文件包含有與我們在MySQL中輸入的命令相同的文本。
比如我們要插入一些數據,使用包含下面文本的文件(文件名為New_Data.sql,當然我們也可以取名為New_Data.txt及任何其他的合法名字,並不一定要以後綴sql結尾):
USE Meet_A_Geek;
INSERT INTO Customers (Customer_ID, Last_Name) VALUES(NULL, "Block");
INSERT INTO Customers (Customer_ID, Last_Name) VALUES(NULL, "Newton");
INSERT INTO Customers (Customer_ID, Last_Name) VALUES(NULL, "Simmons"); 上面的USE命令選擇數據庫,INSERT命令插入數據。 下面我們要把上面的文件導入到數據庫中,導入之前要確認數據庫已經在運行,即是mysqld進程(或者說服務,Windows NT下面稱為”服務“,unix下面為”進程“)已經在運行。 bin/MySQL –p < /home/mark/New_Data.sql
接著按提示輸入密碼,如果上面的文件中的語句沒有錯誤,那麼這些數據就被導入到了數據庫中。 命令行中使用LOAD DATA INFILE 從文件中導入數據到數據庫:
現在您可能會問自己,"究竟為什麼我要輸入所有的這些SQL語句到文件中,然後通過程序運行它們呢?”
這樣看起來好像需要大量的工作。很好,你這樣想很可能就對了。但是假如你有從所有這些命令中產生的log記錄呢?現在這樣就很棒,嗯,大多數數據庫都會自 動產生數據庫中的事件記錄的log。而大部分log都包含有用過的原始的SQL命令。因此,如果您不能從您現在的數據庫中導出數據到新的MySQL數據庫 中使用,那麼您可以使用log和MySQL的批處理特性,來快速且方便地導入您地數據。當然,這樣就省去了打字的麻煩。 LOAD DATA INFILE
這是我們要介紹的最後一個導入數據到MySQL數據庫中的方法。這個命令與mysqlimport非常相似,但這個方法可以在mysql命令行中使用。也就是說您可以在所有使用API的程序中使用這個命令。使用這種方法,您就可以在應用程序中導入您想要導入的數據。 使用這個命令之前,MySQLd進程(服務)必須已經在運行。
啟動MySQL命令行:
bin/MySQL –p
按提示輸入密碼,成功進入MySQL命令行之後,輸入下面的命令:
USE Meet_A_Geek;
LOAD DATA INFILE "/home/mark/data.sql" INTO TABLE Orders;
簡單的講,這樣將會把文件data.sql中的內容導入到表Orders中,如MySQLimport工具一樣,這個命令也有一些可以選擇的參數。比如您需要把自己的電腦上的數據導入到遠程的數據庫服務器中,您可以使用下面的命令:
LOAD DATA LOCAL INFILE "C:\MyDocs\SQL.txt" INTO TABLE Orders; 上面的LOCAL參數表示文件是本地的文件,服務器是您所登陸的服務器。
這樣就省去了使用FTP來上傳文件到服務器,MySQL替你完成了.
您也可以設置插入語句的優先級,如果您要把它標記為低優先級(LOW_PRIORITY),那麼MySQL將會等到沒有其他人讀這個表的時候,才把插入數據。可以使用如下的命令:
LOAD DATA LOW_PRIORITY INFILE "/home/mark/data.sql" INTO TABLE Orders; 您也可以指定是否在插入數據的時候,取代或者忽略文件與數據表中重復的鍵值。替代重復的鍵值的語法:
LOAD DATA LOW_PRIORITY INFILE "/home/mark/data.sql" REPLACE INTO TABLE Orders;
上面的句子看起來有點笨拙,但卻把關鍵字放在了讓您的剖析器可以理解的地方。 下面的一對選項描述了文件的記錄格式,這些選項也是在mysqlimport工具中可以用的。他們在這裡看起來有點不同。首先,要用到FIELDS關鍵字,如果用到這個關鍵字,MySQL剖析器希望看到至少有下面的一個選項:
TERMINATED BY character
ENCLOSED BY character
ESCAPED BY character
這些關鍵字與它們的參數跟MySQLimport中的用法是一樣的. The
TERMINATED BY 描述字段的分隔符,默認情況下是tab字符(\t)
ENCLOSED BY描述的是字段的括起字符。比方以引號括起每一個字段。
ESCAPED BY 描述的轉義字符。默認的是反些槓(backslash:\ ).
下面仍然使用前面的MySQLimport命令的例子,用LOAD DATA INFILE語句把同樣的文件導入到數據庫中:
LOAD DATA INFILE "/home/mark/Orders.txt" REPLACE INTO TABLE Orders FIELDS TERMINATED BY ',' ENCLOSED BY '"';
LOAD DATA INFILE語句中有一個MySQLimport工具中沒有特點:
LOAD DATA INFILE 可以按指定的列把文件導入到數據庫中。
當我們要把數據的一部分內容導入的時候,這個特點就很重要。比方說,我們要從Access數據庫升級到MySQL數據庫的時候,需要加入一些欄目(列/字段/fIEld)到MySQL數據庫中,以適應一些額外的需要。
這個時候,我們的Access數據庫中的數據仍然是可用的,但是因為這些數據的欄目(fIEld)與MySQL中的不再匹配,因此而無法再使用 MySQLimport工具。盡管如此,我們仍然可以使用LOAD DATA INFILE,下面的例子顯示了如何向指定的欄目(fIEld)中導入數 據:
LOAD DATA INFILE "/home/Order.txt" INTO TABLE Orders(Order_Number, Order_Date, Customer_ID); 如您所見,我們可以指定需要的欄目(fIElds)。這些指定的字段依然是以括號括起,由逗號分隔的,如果您遺漏了其中任何一個,MySQL將會提醒您^_^ Importing Data from Microsoft Access (從Access中導入數據,略)
MySQL數據導入導出方法與工具介紹(3-Exporting Data)
導出數據的方法:Methods of Exporting Data 翻譯聲明:
本文內容來自Sam's Teach Yourself MySQL in 21 Days一書的部分內容,by Mark Maslakowski
英文原文版權屬原作者所有,中文的部分翻譯有略有增刪;原書講的過於清楚的地方有刪,講的不清楚的地方有增;如果有翻譯的不妥或者不正確的地方,請指正。 翻譯者:David Euler,SCU.
時間:2004/04/24於川大 您可以看到MySQL有很多可以導入數據的方法,然而這些只是數據傳輸中的一半。另外的一般是從MySQL數據庫中導出數據。有許多的原因我們需要導出數 據。一個重要的原因是用於備份數據庫。數據的造價常常是昂貴的,需要謹慎處理它們。經常地備份可以幫助防止寶貴數據地丟失;另外一個原因是,也許您希望導 出數據來共享。 在這個信息技術不斷成長的世界中,共享數據變得越來越常見。 比方說Macmillan USA維護護著一個將要出版的書籍的大型數據庫。這個數據庫在許多書店之間共享,這樣他們就知道哪些書將會很快出版。醫院越來 越走向采用無紙病歷記錄,這樣這些病歷可以隨時跟著你。世界變得越來越小,信息也被共享得越來越多。有很多中導出數據得方法,它們都跟導入數據很相似。因 為,畢竟,這些都只是一種透視得方式。從數據庫導出的數據就是從另一端導入的數據。這裡我們並不討論其他的數據庫各種各樣的導出數據的方法,您將學會如何 用MySQL來實現數據導出。 使用mysqldump: (mysqldump命令位於MySQL/bin/目錄中)
mysqldump工具很多方面類似相反作用的工具mysqlimport。它們有一些同樣的選項。但mysqldump能夠做更多的事情。它可以把整個 數據庫裝載到一個單獨的文本文件中。這個文件包含有所有重建您的數據庫所需要的SQL命令。這個命令取得所有的模式(Schema,後面有解釋)並且將其 轉換成DDL語法(CREATE語句,即數據庫定義語句),取得所有的數據,並且從這些數據中創建INSERT語句。這個工具將您的數據庫中所有的設計倒 轉。因為所有的東西都被包含到了一個文本文件中。這個文本文件可以用一個簡單的批處理和一個合適SQL語句導回到MySQL中。這個工具令人難以置信地簡 單而快速。決不會有半點讓人頭疼地地方。 因此,如果您像裝載整個數據庫Meet_A_Geek的內容到一個文件中,可以使用下面的命令:
bin/MySQLdump –p Meet_A_Geek > MeetAGeek_Dump_File.txt 這個語句也允許您指定一個表進行dump(備份/導出/裝載?)。如果您只是希望把數據庫Meet_A_Geek中的表Orders中的整個內容導出到一個文件,可以使用下面的命令:
bin/MySQLdump –p Meet_A_Geek Orders >MeetAGeek_Orders.txt 這個非常的靈活,您甚至可以使用WHERE從句來選擇您需要的記錄導出到文件中。要達到這樣的目的,可以使用類似於下面的命令:
bin/mysqldump –p –where="Order_ID > 2000" Meet_A_Geek Orders > Special_Dump.txt MySQLdump工具有大量的選項,部分選項如下表:
選項/Option 作用/Action Performed
--add-drop-table
這個選項將會在每一個表的前面加上DROP TABLE IF EXISTS語句,這樣可以保證導回MySQL數據庫的時候不會出錯,因為每次導回的時候,都會首先檢查表是否存在,存在就刪除
--add-locks
這個選項會在INSERT語句中捆上一個LOCK TABLE和UNLOCK TABLE語句。這就防止在這些記錄被再次導入數據庫時其他用戶對表進行的操作 -c or - complete_insert
這個選項使得MySQLdump命令給每一個產生INSERT語句加上列(fIEld)的名字。當把數據導出導另外一個數據庫時這個選項很有用。
--delayed-insert 在INSERT命令中加入DELAY選項
-F or -flush-logs 使用這個選項,在執行導出之前將會刷新MySQL服務器的log.
-f or -force 使用這個選項,即使有錯誤發生,仍然繼續導出
--full 這個選項把附加信息也加到CREATE TABLE的語句中
-l or -lock-tables 使用這個選項,導出表的時候服務器將會給表加鎖。
-t or -no-create- info
這個選項使的MySQLdump命令不創建CREATE TABLE語句,這個選項在您只需要數據而不需要DDL(數據庫定義語句)時很方便。 -d or -no-data 這個選項使的MySQLdump命令不創建INSERT語句。
在您只需要DDL語句時,可以使用這個選項。
--opt 此選項將打開所有會提高文件導出速度和創造一個可以更快導入的文件的選項。
-q or -quick 這個選項使得MySQL不會把整個導出的內容讀入內存再執行導出,而是在讀到的時候就寫入導文件中。
-T path or -tab = path 這個選項將會創建兩個文件,一個文件包含DDL語句或者表創建語句,另一個文件包含數據。DDL文件被命 名為table_name.sql,數據文件被命名為table_name.txt.路徑名是存放這兩個文件的目錄。目錄必須已經存在,並且命令的使用者 有對文件的特權。 -w "WHERE Clause" or -where = "Where clause " 導出文件的數據。 假定您需要為一個表單中要用到的帳號建立一個文件,經理要看今年(2004年)所有的訂單(Orders),它們並不對DDL感興趣,並且需要文件有逗號分隔,因為這樣就很容易導入到Excel中。 為了完成這個人物,您可以使用下面的句子:
bin/MySQLdump –p –where "Order_Date >='2000-01-01'"
–tab = /home/mark –no-create-info –fIElds-terminated-by=, Meet_A_Geek Orders
這將會得到您想要的結果。 schema:模式
The set of statements, expressed in data definition language, that completely describe the structure of a data base.
一組以數據定義語言來表達的語句集,該語句集完整地描述了數據庫的結構。 SELECT INTO OUTFILE :
如果您覺得mysqldump工具不夠酷,就使用SELECT INTO OUTFILE吧, MySQL同樣提供一個跟 LOAD DATA INFILE命令有相反作用的命令,這就是SELECT INTO OUTFILE 命令,這兩個命令有很多的相似之處。首先,它們 有所有的選項幾乎相同。現在您需要完成前面用mysqldump完成的功能,可以依照下面的步驟進行操作: 1. 確保MySQLd進程(服務)已經在運行
2. cd /usr/local/MySQL
3. bin/mysqladmin ping ;// 如果這個句子通不過,可以用這個:MySQLadmin -u root -p ping
mysqladmin ping用於檢測MySQLd的狀態,is alive說明正在運行,出錯則可能需要用戶名和密碼。
4. 啟動MySQL 監聽程序.
5. bin/mysql –p Meet_A_Geek;// 進入MySQL命令行,並且打開數據庫Meet_A_Geek,需要輸入密碼
6. 在命令行中,輸入一下命令:
SELECT * INTO OUTFILE '/home/mark/Orders.txt'
FIELDS
TERMINATED BY = ','
FROM Orders
WHERE Order_Date >= '2000-01-01' 在你按了Return(回車)之後,文件就創建了。這個句子就像一個規則的SELECT語句,只是把想屏幕的輸出重定向到了文件中。這意味這您可以使用JOIN來實現多表的高級查詢。這個特點也可以被用作一個報表產生器。
比方說,您可以組合這一章中討論的方法來產生一個非常有趣的查詢,試試這個: 在MySQL目錄建立一個名為Report_G.rpt 的文本文件,加入下面的行:
USE Meet_A_Geek;
INSERT INTO Customers (Customer_ID, Last_Name, First_Name)
VALUES (NULL, "Kinnard", "Vicky");
INSERT INTO Customers (Customer_ID, Last_Name, First_Name)
VALUES (NULL, "Kinnard", "Steven");
INSERT INTO Customers (Customer_ID, Last_Name, First_Name)
VALUES (NULL, "Brown", "Sam");
SELECT Last_Name INTO OUTFILE '/home/mark/Report.rpt'
FROM Customers WHERE Customer_ID > 1;
然後確認 mysql進程在運行,並且您在MySQL目錄中, 輸入下面的命令:
bin/MySQL < Report_G.rpt檢查您命名作為輸出的文件,這個文件將會包含所有您在Customers表中輸入的顧客的姓。 如您所見,您可以使用今天學到的導入/導出(import/export)的方法來幫助得到報表
MySQL備份和恢復
來源:MySQL手冊版本 5.0.20,轉載http://www.ad0.cn/netfetch/default.ASP。
本文討論 MySQL 的備份和恢復機制,以及如何維護數據表,包括最主要的兩種表類型:MyISAM 和 Innodb,文中設計的 MySQL 版本為 5.0.22。
本文介紹的是使用MySQL自帶免費備份工具備份,當然你可以選擇一些更方便的第三方工具進行備份和恢復MySQL數據庫。目前 MySQL 支持的免費備份工具有:mysqldump、mysqlhotcopy,還可以用 SQL 語法進行備份:BACKUP TABLE 或者 Select INTO OUTFILE,又或者備份二進制日志(binlog),還可以是直接拷貝數據文件和相關的配置文件。MyISAM 表是 保存成文件的形式,因此相對比較容易備份,上面提到的幾種方法都可以使用。Innodb 所有的表都保存在同一個數據文件 ibdata1 中(也可能是 多個文件,或者是獨立的表空間文件),相對來說比較不好備份,免費的方案可以是拷貝數據文件、備份 binlog,或者用 mysqldump。 1、MySQLdump
1.1 備份
mysqldump 是采用SQL級別的備份機制,它將數據表導成 SQL 腳本文件,在不同的 MySQL 版本之間升級時相對比較合適,這也是最常用的備份方法。
現在來講一下 MySQLdump 的一些主要參數: --compatible=name
它告訴 MySQLdump,導出的數據將和哪種數據庫或哪個舊版本的 MySQL 服務器相兼容。值可以為 ansi、mysql323、 MySQL40、postgresql、Oracle、mssql、db2、maxdb、no_key_options、 no_tables_options、no_fIEld_options 等,要使用幾個值,用逗號將它們隔開。當然了,它並不保證能完全兼容,而是盡量 兼容。 --complete-insert,-c
導出的數據采用包含字段名的完整 Insert 方式,也就是把所有的值都寫在一行。這麼做能提高插入效率,但是可能會受到 max_allowed_packet 參數的影響而導致插入失敗。因此,需要謹慎使用該參數,至少我不推薦。 --default-character-set=charset
指定導出數據時采用何種字符集,如果數據表不是采用默認的 latin1 字符集的話,那麼導出時必須指定該選項,否則再次導入數據後將產生亂碼問題。 --disable-keys
告訴 MySQLdump 在 Insert 語句的開頭和結尾增加 /*! 40000 Alter TABLE table DISABLE KEYS */; 和 /*! 40000 Alter TABLE table ENABLE KEYS */; 語句,這能大大提高插入語句的速度,因為它是在插入完所有數據後才重 建索引的。該選項只適合 MyISAM 表。 --extended-insert = true|false
默認情況下,MySQLdump 開啟 --complete-insert 模式,因此不想用它的的話,就使用本選項,設定它的值為 false 即可。 --hex-blob
使用十六進制格式導出二進制字符串字段。如果有二進制數據就必須使用本選項。影響到的字段類型有 BINARY、VARBINARY、BLOB。 --lock-all-tables,-x
在開始導出之前,提交請求鎖定所有數據庫中的所有表,以保證數據的一致性。這是一個全局讀鎖,並且自動關閉 --single-transaction 和 --lock-tables 選項。 --lock-tables
它和 --lock-all-tables 類似,不過是鎖定當前導出的數據表,而不是一下子鎖定全部庫下的表。本選項只適用於 MyISAM 表,如果是 Innodb 表可以用 --single-transaction 選項。 --no-create-info,-t
只導出數據,而不添加 Create TABLE 語句。 --no-data,-d
不導出任何數據,只導出數據庫表結構。 --opt
這只是一個快捷選項,等同於同時添加 --add-drop-tables --add-locking --create-option -- disable-keys --extended-insert --lock-tables --quick --set-charset 選項。本選 項能讓 mysqldump 很快的導出數據,並且導出的數據能很快導回。該選項默認開啟,但可以用 --skip-opt 禁用。注意,如果運行 MySQLdump 沒有指定 --quick 或 --opt 選項,則會將整個結果集放在內存中。如果導出大數據庫的話可能會出現問題。 --quick,-q
該選項在導出大表時很有用,它強制 MySQLdump 從服務器查詢取得記錄直接輸出而不是取得所有記錄後將它們緩存到內存中。 --routines,-R
導出存儲過程以及自定義函數。 --single-transaction
該選項在導出數據之前提交一個 BEGIN SQL語句,BEGIN 不會阻塞任何應用程序且能保證導出時數據庫的一致性狀態。它只適用於事務表,例如 InnoDB 和 BDB。
本選項和 --lock-tables 選項是互斥的,因為 LOCK TABLES 會使任何掛起的事務隱含提交。
要想導出大表的話,應結合使用 --quick 選項。 --triggers
同時導出觸發器。該選項默認啟用,用 --skip-triggers 禁用它。其他參數詳情請參考手冊,我通常使用以下 SQL 來備份 MyISAM 表: /usr/local/mysql/bin/MySQLdump -uyejr -pyejr --default-character-set=utf8 --opt --extended-insert=false \
--triggers -R --hex-blob -x db_name > db_name.sql
使用以下 SQL 來備份 Innodb 表: /usr/local/mysql/bin/MySQLdump -uyejr -pyejr --default-character-set=utf8 --opt --extended-insert=false \
--triggers -R --hex-blob --single-transaction db_name > db_name.sql 1.2 還原
用 mysqldump 備份出來的文件是一個可以直接倒入的 SQL 腳本,有兩種方法可以將數據導入。直接用 MySQL 客戶端
例如: /usr/local/mysql/bin/MySQL -uyejr -pyejr db_name < db_name.sql
用 SOURCE 語法
其實這不是標准的 SQL 語法,而是 MySQL 客戶端提供的功能,例如: SOURCE /tmp/db_name.sql;
這裡需要指定文件的絕對路徑,並且必須是 mysqld 運行用戶(例如 nobody)有權限讀取的文件。 2、 MySQLhotcopy
2.1 備份
mysqlhotcopy 是一個 PERL 程序,最初由Tim Bunce編寫。它使用 LOCK TABLES、FLUSH TABLES 和 cp 或 scp 來快速備份數據庫。它是備份數據庫或單個表的最快的途徑,但它只能運行在數據庫文件(包括數據表定義文件、數據文件、索引文件)所在 的機器上。mysqlhotcopy 只能用於備份 MyISAM,並且只能運行在 類Unix 和 NetWare 系統上。 mysqlhotcopy 支持一次性拷貝多個數據庫,同時還支持正則表達。以下是幾個例子: root#/usr/local/mysql/bin/MySQLhotcopy -h=localhost -u=yejr -p=yejr db_name /tmp (把數據庫目錄 db_name 拷貝到 /tmp 下)
root#/usr/local/mysql/bin/MySQLhotcopy -h=localhost -u=yejr -p=yejr db_name_1 ... db_name_n /tmp
root#/usr/local/mysql/bin/MySQLhotcopy -h=localhost -u=yejr -p=yejr db_name./regex/ /tmp
更詳細的使用方法請查看手冊,或者調用下面的命令來查看 mysqlhotcopy 的幫助: perldoc /usr/local/mysql/bin/MySQLhotcopy
注意,想要使用 MySQLhotcopy,必須要有 Select、RELOAD(要執行 FLUSH TABLES) 權限,並且還必須要能夠有讀取 datadir/db_name 目錄的權限。 2.2 還原
MySQLhotcopy 備份出來的是整個數據庫目錄,使用時可以直接拷貝到 mysqld 指定的 datadir (在這裡是 /usr/local/mysql/data/)目錄下即可,同時要注意權限的問題,如下例: root#cp -rf db_name /usr/local/MySQL/data/
root#chown -R nobody:nobody /usr/local/mysql/data/ (將 db_name 目錄的屬主改成 MySQLd 運行用戶) 3、 SQL 語法備份
3.1 備份
BACKUP TABLE 語法其實和 MySQLhotcopy 的工作原理差不多,都是鎖表,然後拷貝數據文件。它能實現在線備份,但是效果不理想,因此不推薦使用。它只拷貝表結構文件和數據文件,不同時拷貝索引文件,因此恢復時比較慢。
例子: BACK TABLE tbl_name TO '/tmp/db_name/';
注意,必須要有 FILE 權限才能執行本SQL,並且目錄 /tmp/db_name/ 必須能被 MySQLd 用戶可寫,導出的文件不能覆蓋已經存在的文件,以避免安全問題。 Select INTO OUTFILE 則是把數據導出來成為普通的文本文件,可以自定義字段間隔的方式,方便處理這些數據。
例子: Select INTO OUTFILE '/tmp/db_name/tbl_name.txt' FROM tbl_name;
注意,必須要有 FILE 權限才能執行本SQL,並且文件 /tmp/db_name/tbl_name.txt 必須能被 MySQLd 用戶可寫,導出的文件不能覆蓋已經存在的文件,以避免安全問題。 3.2 恢復
用 BACKUP TABLE 方法備份出來的文件,可以運行 RESTORE TABLE 語句來恢復數據表。
例子: RESTORE TABLE FROM '/tmp/db_name/';
權限要求類似上面所述。用 Select INTO OUTFILE 方法備份出來的文件,可以運行 LOAD DATA INFILE 語句來恢復數據表。
例子: LOAD DATA INFILE '/tmp/db_name/tbl_name.txt' INTO TABLE tbl_name;
權限要求類似上面所述。倒入數據之前,數據表要已經存在才行。如果擔心數據會發生重復,可以增加 REPLACE 關鍵字來替換已有記錄或者用 IGNORE 關鍵字來忽略他們。 4、 啟用二進制日志(binlog)
采用 binlog 的方法相對來說更靈活,省心省力,而且還可以支持增量備份。啟用 binlog 時必須要重啟 mysqld。首先,關閉 MySQLd,打開 my.cnf,加入以下幾行: server-id = 1
log-bin = binlog
log-bin-index = binlog.index
然後啟動 mysqld 就可以了。運行過程中會產生 binlog.000001 以及 binlog.index,前面的文件是 mysqld 記錄 所有對數據的更新操作,後面的文件則是所有 binlog 的索引,都不能輕易刪除。關於 binlog 的信息請查看手冊。需要備份時,可以先執行一下 SQL 語句,讓 mysqld 終止對當前 binlog 的寫入,就可以把文件直接備份,這樣的話就能達到增量備份的目的了: FLUSH LOGS;如果是備份復制系統中的從服務器,還應該備份 master.info 和 relay-log.info 文件。備份出來的 binlog 文件可以用 MySQL 提供的工具 mysqlbinlog 來查看,如: /usr/local/mysql/bin/MySQLbinlog /tmp/binlog.000001
該工具允許你顯示指定的數據庫下的所有 SQL 語句,並且還可以限定時間范圍,相當的方便,詳細的請查看手冊。恢復時,可以采用類似以下語句來做到: /usr/local/mysql/bin/mysqlbinlog /tmp/binlog.000001 | MySQL -uyejr -pyejr db_name
把 MySQLbinlog 輸出的 SQL 語句直接作為輸入來執行它。如果你有空閒的機器,不妨采用這種方式來備份。由於作為 slave 的機器性能要求相對不是那麼高,因此成本低,用低成本就能實現增量備份而且還能分擔一部分數據查詢壓力,何樂而不為呢? 5、 直接備份數據文件
相較前幾種方法,備份數據文件最為直接、快速、方便,缺點是基本上不能實現增量備份。為了保證數據的一致性,需要在靠背文件前,執行以下 SQL 語句: FLUSH TABLES WITH READ LOCK;也就是把內存中的數據都刷新到磁盤中,同時鎖定數據表,以保證拷貝過程中不會有新的數據寫入。這種方法備份出來的數據恢復也很簡單,直接拷貝回原來的數據庫目錄下即可。注意,對於 Innodb 類型表來說,還需要備份其日志文件,即 ib_logfile* 文件。因為當 Innodb 表損壞時,就可以依靠這些日志文件來恢復。 6、 備份策略
對於中等級別業務量的系統來說,備份策略可以這麼定:第一次全量備份,每天一次增量備份,每周再做一次全量備份,如此一直重復。而對於重要的且繁忙的系統 來說,則可能需要每天一次全量備份,每小時一次增量備份,甚至更頻繁。為了不影響線上業務,實現在線備份,並且能增量備份,最好的辦法就是采用主從復制機 制(replication),在 slave 機器上做備份。 7、 數據維護和災難恢復
作為一名DBA最重要的工作內容之一是保證數據表能安全、穩定、高速使用。因此,需要定期維護你的數據表。以下 SQL 語句就很有用: CHECK TABLE 或 REPAIR TABLE,檢查或維護 MyISAM 表
OPTIMIZE TABLE,優化 MyISAM 表
ANALYZE TABLE,分析 MyISAM 表
當然了,上面這些命令起始都可以通過工具 myisamchk 來完成,在這裡不作詳述。 Innodb 表則可以通過執行以下語句來整理碎片,提高索引速度: Alter TABLE tbl_name ENGINE = Innodb;
這其實是一個 NULL 操作,表面上看什麼也不做,實際上重新整理碎片了。通常使用的 MyISAM 表可以用上面提到的恢復方法來完成。如果是索引壞了,可以用 myisamchk 工具來重建索引。而對於 Innodb 表 來說,就沒這麼直接了,因為它把所有的表都保存在一個表空間了。不過 Innodb 有一個檢查機制叫模糊檢查點,只要保存了日志文件,就能根據日志文件 來修復錯誤。可以在 my.cnf 文件中,增加以下參數,讓 MySQLd 在啟動時自動檢查日志文件: innodb_force_recovery = 4
關於該參數的信息請查看手冊。 8、 總結
做好數據備份,定只好合適的備份策略,這是一個DBA所做事情的一小部分,萬事開頭難,就從現在開始吧!