最近遇見一個 MySQL 的慢查問題,於是排查了下,這裡把相關的過程做個總結。
我首先查看了 MySQL 的慢查詢日志,發現有這樣一條 query 耗時非常長(大概在 1 秒多),而且掃描的行數很大(10 多萬條數據,差不多是全表了):
SELECT * FROM tgdemand_demand t1
WHERE
(
t1.id IN
(
SELECT t2.demand_id
FROM tgdemand_job t2
WHERE (t2.state = 'working' AND t2.wangwang = 'abc')
)
AND
NOT (t1.state = 'needConfirm')
)
ORDER BY t1.create_date DESC
這個查詢不是很復雜,首先執行一個子查詢,取到任務的狀態(state)是 ‘working’ 並且任務的關聯人 (wangwang)是’abc’的所有需求 id(這個設計師進行中的任務對應的需求 id),然後再到主表 tgdemand_demand 中帶入剛才的 id 集合,查詢出需求狀態(state)不是 ‘needConfirm’ 的所有需求,最後進行一個排序。
按道理子查詢篩選出 id 後到主表過濾是直接使用到主鍵,應該是很快的啊。而且,我檢查了子查詢的 tgdemand_job 表的索引,where 中用到的查詢條件都已經增加了索引。怎麼會這樣呢?
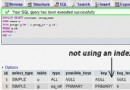
於是,我對這個 query 執行了一個 explain(輸出 sql 語句的執行計劃),看看 MySQL 的執行計劃是怎樣的。輸出如下:

我們看到,第一行是 t1 表,type 是 ALL(全表掃描),rows(影響行數)是 157089,沒有用到任何索引;第二行是 t2 表,用到了索引。和我之前理解的執行順序完全不一樣!
為什麼 MySQL 不是先執行子查詢,而是對 t1 表進行了全表掃描呢?我們仔細看第二行的 select_type,發現它的值是 DEPENDENT_SUBQUERY,意思是這個子查詢的查詢方式依賴外層的查詢。這是什麼意思?
實際上,MySQL 對於這種子查詢會進行改寫,上面的 SQL 會被改寫成下面的形式:
SELECT * FROM tgdemand_demand t1 WHERE EXISTS ( SELECT * FROM tgdemand_job t2 WHERE t1.id = t2.demand_id AND (t2.state = 'working' AND t2.wangwang = 'abc') ) AND NOT (t1.state = 'needConfirm') ORDER BY t1.create_date DESC;
這表示,SQL 會去掃描 tgdemand_demand 表的所有數據,每條數據再傳入到子查詢中與表 tgdemand_job 進行關聯,執行子查詢,子查詢根本不會先執行,而且子查詢會執行 157089 次(外層表的記錄數量)。還好我們的子查詢加了必要的索引,不然結果會更加慘不忍睹。
這個結果真是太坑爹,而且十分違反直覺。對於慢查詢,千萬不要想當然,還是多多 explain,看看數據庫實際上是怎麼去執行的。
既然子查詢會被改寫,那最簡單的解決方案就是不用子查詢,將內層獲取需求 id 的 SQL 單獨拿出來執行,取到結果後再執行一條 SQL 去獲取實際的數據。大概像這樣(下面的語句是不合法的,只是示意):
ids = SELECT t2.demand_id
FROM tgdemand_job t2
WHERE (t2.state = 'working' AND t2.wangwang = 'abc');
SELECT * FROM tgdemand_demand t1
WHERE
(
t1.id IN ids
AND
NOT (t1.state = 'needConfirm')
)
ORDER BY t1.create_date DESC;
說干咱就干,我找到了下面的代碼(是 python 語言寫的):
demand_ids = Job.objects.filter(wangwang=user['wangwang'], state='working').values_list("demand_id", flat=True)
demands = Demand.objects.filter(id__in=demand_ids).exclude(state__in=['needConfirm']).order_by('-create_date')
咦!這不是和我想得是一樣的嘛?先查出需求 id(代碼第一行),然後用 id 集合再去執行實際的查詢(代碼第二行)。為什麼經過 ORM 框架的處理後產出的 SQL 就不一樣了呢?
帶著這個問題我搜索了一番。原來 Django 自帶的 ORM 框架生成的 QuerySet 是懶執行的(lazy evaluated),我們可以將這種 QuerySet 到處傳,直到需要時才會實際的執行 SQL。
比如,我們代碼裡面的 Job.objects.filter(wangwang=user['wangwang'], state='working').values_list("demand_id", flat=True) 這個 QuerySet 實際上並沒有執行,就被作為參數傳遞給了 id__in,當 Demand.objects.filter(id__in=demand_ids).exclude(state__in=['needConfirm']).order_by('-create_date') 這個 QuerySet 執行時,剛才未執行的 QuerySet 才開始作為 SQL 執行,於是生成了最開始的 SQL 語句。
既然如此,我們的目的要讓 QuerySet 提前執行,獲得結果集。根據文檔,對 QuerySet 進行循環、slice、取 len、list 轉換的時候被執行。於是我將代碼更改為了下面的樣子:
demand_ids = list(Job.objects.filter(wangwang=user['wangwang'], state='working').values_list("demand_id", flat=True))
demands = Demand.objects.filter(id__in=demand_ids).exclude(state__in=['needConfirm']).order_by('-create_date')
終於,頁面打開速度恢復正常了。
實際上,我們也可以對 SQL 進行改寫來解決問題:
select * from tgdemand_demand t1, (select t.demand_id from tgdemand_job t where t.state = 'working' and t.wangwang = 'abc') t2 where t1.id=t2.demand_id and not (t1.state = 'needConfirm') order by t1.create_date DESC
思路是去掉子查詢,換用 2 個表進行 join 的方式來取得數據。這裡就不展開了。
框架可以提高生產率的前提是對背後的原理足夠了解,不然應用很可能就會在某個時間暴露出一些隱蔽的要命問題(這些問題在小規模階段可能根本都發現不了……)。保證應用的健壯真是個大學問,還有很多東西值得我們去探索