Table statistics 包含兩個方面:
1) table stat 比如表內一共有多少條記錄(n_rows)。
此類信息保存在mysql.innodb_table_stats表中。
2) index stat 比如index中包含多少個page, 多少個leaf page,共有多少條完全不同的索引
此信息保存在mysql.innodb_index_stats表中。
在innodb中,一切都是基於index的,table stat 中n_rows的計算也是基於index的。
下面就分析一下innodb是如何對index進行統計的。
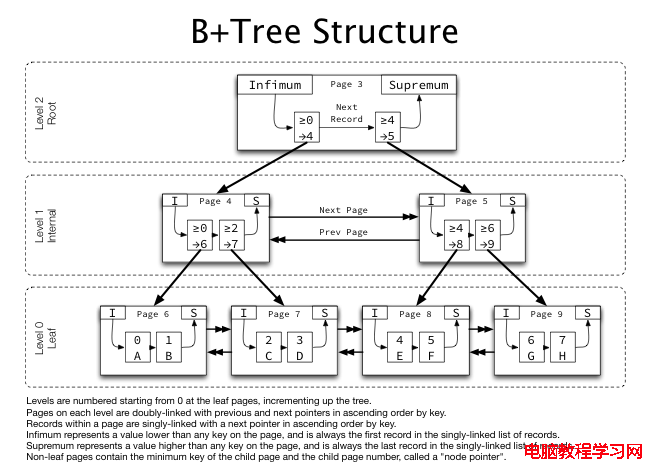
哎,還是先簡單介紹一下index的結構—B+ tree
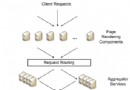
B+tree的結構如下圖:

這張圖是從 Wikipedia copy過來的,不必太執著於它。
Index在硬盤文件中的最基本保存單位是page(默認16K一頁),這些page在一起組成了B+ tree。 表中的每一個index,對應一個B+tree。
根據page的類型,可以分為三類:
1) Root page 最上面的一個page, 對B+ tree的訪問總是從它開始的。
2) leaf page 最下層的page. 儲存了真正的索引數據。如果是主鍵的話,還儲存了其它全部的字段。
3) non-leaf page 界於Root page與leaf page之間的page.
另外還有一個level的概念:
Leaf page 的level 為0, 每往上走一層,level就+1。
Root 的level最大,表示這個tree 的高度。
Leaf page 的簡單結構:
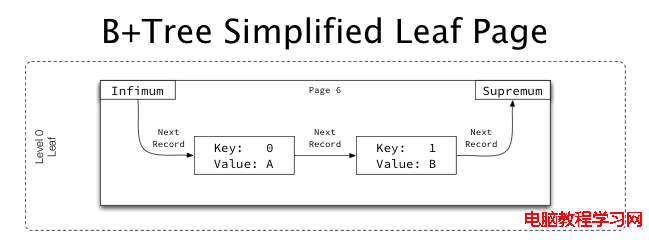
此page中的記錄,從Infimum開始,到Supremum結束,每個記錄都有一條指針指向下一條記錄,組成了一條單向升序的鏈表。 Infimum與Supremum為system記錄,表示page中記錄的開始和結束。它們之間的記錄為User記錄,保存了key(索引的值)與value(如果為主鍵索引,那麼value就是其它的全部字段的值;如果是非主鍵索引,value就是主鍵的值(Primary Key Value , PKV))。
Non-leaf page的簡單結構:
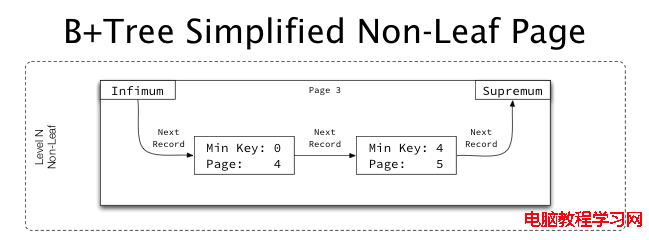
與leaf page的結構相似,只不過在每條記錄中,它保存的key的意思是:child page中最小的索引值。 然後也保存了child 的page num(相當於一個指向child page的指針)。每一條記錄,只有一個child page。
再來看一下level的概念:
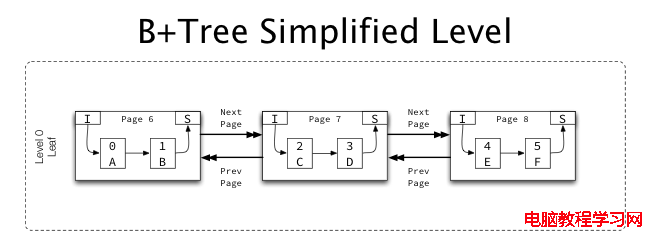
同一level中的page由二條指針組成了雙向的鏈表, 同時有了升序和降序。
最後從整體上把握一下:
CREATE TABLE t ( i INT NOT NULL, s CHAR(10) NOT NULL, PRIMARY KEY(i) ) ENGINE=InnoDB; INSERT INTO t (i, s) VALUES (0, "A"), (1, "B"), (2, "C"), (3, “D”),(4,”E”),(5,”F”),(6,”G”),(7,”H”);
如果需要對index進行統計,最簡單的辦法就是從頭到尾掃描此index對應的B+tree全部的leaf page中的全部記錄,看一下有多少條不相同的索引。優點是非常精確, 缺點是如果page相當多的話,掃描的速度會相當慢。
Mysql的做法是采樣,從全部leaf page中取出20個page 進行分析,
mysql> SELECT @@global.innodb_stats_persistent_sample_pages;
+-----------------------------------------------+
| @@global.innodb_stats_persistent_sample_pages |
+-----------------------------------------------+
| 20 |
+-----------------------------------------------+
1 ROW IN SET (0.00 sec)
當然這個變量是可以配置的, 它的值越大,統計的結果越精確,統計的速度也就越慢。把它記為A。
還是先用簡單的主鍵索引(clustered index )來分析吧。。。越來越亂了。
之所以說主鍵索引比較簡單,是因為在任意一個level中,全部page中的全部記錄的key都是不相同的。
從Root page開始,向下面的level遍歷它的全部child page,直到遇到這樣的一個level:
此level中至少包含A * 10條不相同的key。
把此level標記為LA。
然後從此level的全部記錄中隨機選出A條記錄。
順著這A條記錄向下,找到A個leaf page。 分析每個leaf page中含有多少個不同的key。對於主鍵索引來說,leaf page中有多少條記錄,就有多少個不同的key。
分析完這A個leaf page, 每個page中不同的key的數量保存到 P1, P2, P3, P4 … PA中。
那麼平均值 N_DIFF_AVG_LEAF 就是 (P1 + P2 + … + PA) / A。
再假設全部leaf page的數量為N,
那麼全部leaf page中不同的key的數量為 N * N_DIFF_AVG_LEAF。
對於主鍵索引,這個值剛好就是全部leaf page中的記錄數,也就是此表中的記錄數n_rows。
mysql> SELECT * FROM innodb_index_stats WHERE TABLE_NAME='xxxx2' AND index_name='PRIMARY';
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
| database_name | TABLE_NAME | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
| kaixin | xxxx2 | PRIMARY | 2013-05-08 15:55:04 | n_diff_pfx01 | 5207 | 20 | id |
| kaixin | xxxx2 | PRIMARY | 2013-05-08 15:55:04 | n_leaf_pages | 277 | NULL | NUMBER OF leaf pages IN the INDEX |
| kaixin | xxxx2 | PRIMARY | 2013-05-08 15:55:04 | SIZE | 353 | NULL | NUMBER OF pages IN the INDEX |
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
3 ROWS IN SET (0.00 sec)
mysql> SELECT * FROM innodb_table_stats WHERE TABLE_NAME='xxxx2';
+---------------+------------+---------------------+--------+----------------------+--------------------------+
| database_name | TABLE_NAME | last_update | n_rows | clustered_index_size | sum_of_other_index_sizes |
+---------------+------------+---------------------+--------+----------------------+--------------------------+
| kaixin | xxxx2 | 2013-05-08 15:55:04 | 5207 | 353 | 177 |
+---------------+------------+---------------------+--------+----------------------+--------------------------+
由於只是一個隨機的采樣,且樣本只有20個page, 准確度確實難以保證,但還是有一定的參考價值的。
mysql> SELECT COUNT(*) FROM kaixin.xxxx2;
+----------+
| COUNT(*) |
+----------+
| 5432 |
+----------+
1 ROW IN SET (0.00 sec)
最後來看比較復雜一點的secondary index。
假設表結構為
CREATE TABLE t (
i INT NOT NULL,
s CHAR(10) NOT NULL,
a INT NOT NULL,
b INT NOT NULL,
c INT NOT NULL,
PRIMARY KEY(i),
KEY (a,b,c)
) ENGINE=InnoDB;
在a b c 三個字段上定義了一個索引,不唯一,允許重復的值出現。
反映到此索引的B+tree中, 某一條記錄可能與它相鄰記錄的key值是相同的, 甚至某一個page中,key值都是相同的。
與Non-leaf page和level相關的一個概念:boring record:
如果non-leaf page中的一條記錄R的key與它右側(可跨越page,但要保證在同一個level上面)的記錄的key值相同,那麼認為此記錄R為boring record。
Boring record的特性:
在Boring record的全部child page,直至leaf page中,key值都是相同的,都與boring record的key值相同。
所以這種boring record就沒有分析的必要, 因為key值不同的記錄數肯定為1。
流程開始:
仍然是從Root page開始,向下面的level遍歷它的全部child page,直到遇到這樣的一個level:
此level中至少包含A * 10條不相同的key。
把此level標記為LA。
先定義一個數組boundaries[]
對於 level LA中具有相同key的記錄,只把最後一個記錄保存到數組中。遍歷此level之後,boundaries[]就包含了全部的不同的key的記錄,總數量記為n_diff_for_this_prefix。
#如果 A > n_diff_for_this_prefix, 則 A=n_diff_for_this_prefix。
然後把它們等分成A組,每組數量為 n_diff_for_this_prefix除以A。
然後從每一組中隨機選出一個記錄, 共選出A條記錄。
順著這A條記錄向下,找到A個leaf page。在這個向下的過程中, 遇到boring record就跳過。然後分析每個leaf page中含有多少個不同的key。
分析完這A個leaf page, 每個page中不同的key的數量保存到 P1, P2, P3, P4 … PA中。
那麼平均值 N_DIFF_AVG_LEAF 就是 (P1 + P2 + … + PA) / A。
Level LA中全部記錄總數為TOTAL_LA,
Level LA中不同記錄的數量為N_DIFF_LA
再假設全部leaf page的數量為N,
那麼全部leaf page中不同的key的數量為 (N_DIFF_LA / TOTAL_LA ) *N * N_DIFF_AVG_LEAF。
其實對於index(a,b,c) ,需要執行4次上面的分析過程。第一次是a, 第二次是(a,b),第三次是(a,b,c), 第四次是(a,b,c,i)。
mysql> SELECT * FROM innodb_index_stats WHERE TABLE_NAME='t' ;
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
| database_name | TABLE_NAME | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
| mysql | t | PRIMARY | 2013-05-08 16:23:05 | n_diff_pfx01 | 0 | 1 | i |
| mysql | t | PRIMARY | 2013-05-08 16:23:05 | n_leaf_pages | 1 | NULL | NUMBER OF leaf pages IN the INDEX |
| mysql | t | PRIMARY | 2013-05-08 16:23:05 | SIZE | 1 | NULL | NUMBER OF pages IN the INDEX |
| mysql | t | a | 2013-05-08 16:23:05 | n_diff_pfx01 | 0 | 1 | a |
| mysql | t | a | 2013-05-08 16:23:05 | n_diff_pfx02 | 0 | 1 | a,b |
| mysql | t | a | 2013-05-08 16:23:05 | n_diff_pfx03 | 0 | 1 | a,b,c |
| mysql | t | a | 2013-05-08 16:23:05 | n_diff_pfx04 | 0 | 1 | a,b,c,i |
| mysql | t | a | 2013-05-08 16:23:05 | n_leaf_pages | 1 | NULL | NUMBER OF leaf pages IN the INDEX |
| mysql | t | a | 2013-05-08 16:23:05 | SIZE | 1 | NULL | NUMBER OF pages IN the INDEX |
+---------------+------------+------------+---------------------+--------------+------------+-------------+-----------------------------------+
9 ROWS IN SET (0.00 sec)
還有一些優化和細節, 請看 代碼 。