前面一篇文章講了Paxos協議,這篇文章講它的姊妹篇Raft協議,相對於Paxos協議,Raft協議更為簡單,也更容易工程實現。有關Raft協議和工程實現可以參考這個鏈接https://raft.github.io/,裡面包含了大量的論文,視屏已經動畫演示,非常有助於理解協議。
概念與術語
leader:領導者,提供客戶提供服務(生成寫日志)的節點,任何時候raft系統中只能有一個leader。
follower:跟隨者,被動接受請求的節點,不會發送任何請求,只會響應來自leader或者candidate的請求。如果接受到客戶請求,會轉發給leader。
candidate:候選人,選舉過程中產生,follower在超時時間內沒有收到leader的心跳或者日志,則切換到candidate狀態,進入選舉流程。
termId:任期號,時間被劃分成一個個任期,每次選舉後都會產生一個新的termId,一個任期內只有一個leader。termId相當於paxos的proposalId。
RequestVote:請求投票,candidate在選舉過程中發起,收到quorum(多數派)響應後,成為leader。
AppendEntries:附加日志,leader發送日志和心跳的機制
election timeout:選舉超時,如果follower在一段時間內沒有收到任何消息(追加日志或者心跳),就是選舉超時。
Raft協議主要包括三部分,leader選舉,日志復制和成員變更。
Raft協議的原則和特點
a.系統中有一個leader,所有的請求都交由leader處理,leader發起同步請求,當多數派響應後才返回客戶端。
b.leader從來不修改自身的日志,只做追加操作
c.日志只從leader流向follower,leader中包含了所有已經提交的日志
d.如果日志在某個term中達成了多數派,則以後的任期中日志一定會存在
e.如果某個節點在某個(term,index)應用了日志,則在相同的位置,其它節點一定會應用相同的日志。
f.不依賴各個節點物理時序保證一致性,通過邏輯遞增的term-id和log-id保證。
e.可用性:只要有大多數機器可運行並可相互通信,就可以保證可用,比如5節點的系統可以容忍2節點失效。
f.容易理解:相對於Paxos協議實現邏輯清晰容易理解,並且有很多工程實現,而Paxos則難以理解,也沒有工程實現。
g.主要實現包括3部分:leader選舉,日志復制,復制快照和成員變更;日志類型包括:選舉投票,追加日志(心跳),復制快照
leader選舉流程
關鍵詞:隨機超時,FIFO
服務器啟動時初始狀態都是follower,如果在超時時間內沒有收到leader發送的心跳包,則進入candidate狀態進行選舉,服務器啟動時和leader掛掉時處理一樣。為了避免選票瓜分的情況,比如5個節點ABCDE,leader A 掛掉後,還剩4個節點,raft協議約定,每個服務器在一個term只能投一張票,假設B,D分別有最新的日志,且同時發起選舉投票,則可能出現B和D分別得到2張票的情況,如果這樣都得不到大多數確認,無法選出leader。為了避免這種情況發生,raft利用隨機超時機制避免選票瓜分情況。選舉超時時間從一個固定的區間隨機選擇,由於每個服務器的超時時間不同,則leader掛掉後,超時時間最短且擁有最多日志的follower最先開始選主,並成為leader。一旦candidate成為leader,就會向其他服務器發送心跳包阻止新一輪的選舉開始。
發送日志信息:(term,candidateId,lastLogTerm,lastLogIndex)
candidate流程:
1.在超時時間內沒有收到leader的日志(包括心跳)
2.將狀態切換為candidate,自增currentTerm,設置超時時間
3.向所有節點廣播選舉請求,等待響應,可能會有以下三種情況:
(1).如果收到多數派回應,則成為leader
(2).如果收到leader的心跳,且leader的term>=currentTerm,則自己切換為follower狀態,
否則,保持Candidate身份
(3).如果在超時時間內沒有達成多數派,也沒有收到leader心跳,則很可能選票被瓜分,則會自增currentTerm,進行新一輪的選舉
follower流程:
1.如果term < currentTerm,說明有更新的term,返回給candidate。
2.如果還沒有投票,或者candidateId的日志(lastLogTerm,lastLogIndex)和本地日志一樣或更新,則投票給它。
注意:一個term周期內,每個節點最多只能投一張票,按照先來先到原則
日志復制流程
關鍵詞:日志連續一致性,多數派,leader日志不變更
leader向follower發送日志時,會順帶鄰近的前一條日志,follwer接收日志時,會在相同任期號和索引位置找前一條日志,如果存在且匹配,則接收日志;否則拒絕,leader會減少日志索引位置並進行重試,直到某個位置與follower達成一致。然後follower刪除索引後的所有日志,並追加leader發送的日志,一旦日志追加成功,則follower和leader的所有日志就保持一致。只有在多數派的follower都響應接受到日志後,表示事務可以提交,才能返回客戶端提交成功。
發送日志信息:(term,leaderId,prevLogIndex,prevLogTerm,leaderCommitIndex)
leader流程:
1.接收到client請求,本地持久化日志
2.將日志發往各個節點
3.如果達成多數派,再commit,返回給client。
備注:
(1).如果傳遞給follower的lastLogIndex>=nextIndex,則從nextIndex繼續傳遞
.如果返回成功,則更新follower對應的nextIndex和matchIndex
.如果失敗,則表示follower還差更多的日志,則遞減nextIndex,重試
(2).如果存在N>commitIndex,且多數派matchIndex[i]>=N, 且log[N].term == currentTerm,
設置commitIndex=N。
follower處理流程:
1.比較term號和自身的currentTerm,如果term<currentTerm,則返回false
2.如果(prevLogIndex,prevLogTerm)不存在,說明還差日志,返回false
3.如果(prevLogIndex,prevLogTerm)與已有的日志沖突,則以leader為准,刪除自身的日志
4.將leader傳過來的日志追加到末尾
5.如果leaderCommitIndex>commitIndex,說明是新的提交位點,回放日志,設置commitIndex =
min(leaderCommitIndex, index of last new entry)
備注:默認情況下,如果日志不匹配,會按logIndex逐條往前推進,直到找到match的位置,有一個簡單的思路是,每次往前推進一個term,這樣可以減少了網絡交互,盡快早點match的位置,代價是可能傳遞了一些多余的日志。
快照流程
避免日志占滿磁盤空間,需要定期對日志進行清理,在清理前需要做快照,這樣新加入的節點可以通過快照+日志恢復。
快照屬性:
1.最後一個已經提交的日志(termId,logIndex)
2.新的快照生成後,可以刪除之前的日志和以前的快照。
刪日志不能太快,否則,crash後的機器,本來可以通過日志恢復,如果日志不存在,需要通過快照恢復,比較慢。
leader發送快照流程
傳遞參數(leaderTermId, lastIndex, lastTerm, offset, data[], done_flag)
1.如果發現日志落後太遠(超過閥值),則觸發發送快照流程
備注:快照不能太頻繁,否則會導致磁盤IO壓力較大;但也需要定期做,清理非必要的日志,緩解日志的空間壓力,另外可以提高follower追趕的速度。
follower接收快照流程
1.如果leaderTermId<currentTerm, 則返回
2.如果是第一個塊,創建快照
3.在指定的偏移,將數據寫入快照
4.如果不是最後一塊,等待更多的塊
5.接收完畢後,丟掉以前舊的快照
6.刪除掉不需要的日志
集群配置變更
C(old): 舊配置
C(new): 新配置
C(old-new): 過渡配置,需要同時在old和new中達成多數派才行
原則:配置變更過程中,不會導致出現兩個leader
二階段方案:引入過渡階段C(old-new)
約定:任何一個follower在收到新的配置後,就采用新的配置確定多數派。
變更流程:
1.leader收到從C(old)切換到C(new)配置的請求
2.創建配置日志C(old-new),這條日志需要在C(old)和C(new)中同時達成多數派
3.任何一個follower收到配置後,采用的C(old-new)來確定日志是否達成多數派(即使C(old-new)這條日志還沒達成多數派)
備注:1,2,3階段只有可能C(old)節點成為leader,因為C(old-new)沒有可能成為多數派。
4.C(old-new)日志commit(達成多數派),則無論是C(old)還是C(new)都無法單獨達成多數派,即不會存在兩個leader
5.創建配置配置日志C(new),廣播到所有節點
6.同樣的,任何一個follower收到配置後,采用的C(new)來確定日志是否達成多數派
備注:在4,5,6階段,只有可能含有C(old-new)配置的節點成為leader。
7.C(new)配置日志commit後,則C(old-new)無法再達成多數派
8.對於不在C(new)配置的節點,就可以退出了,變更完成。
備注:在7,8階段,只有可能含有C(new)配置成為leader。
所以整個過程中永遠只會有一個leader。對於leader不在C(new)配置的情況,需要在C(new)日志提交後,自動關閉。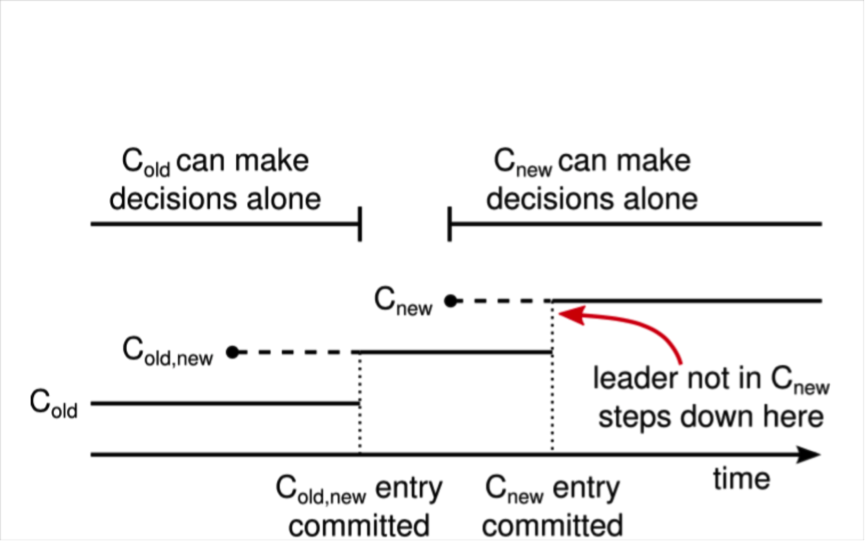
除了上述的兩階段方案,後續Raft作者又提出了一個相對簡單的一階段方案,每次只添加或者刪除一個節點,這樣設計不用引入過渡狀態,這裡不再贅述,有興趣的同學可以去看他的畢業論文,我會附在後面的參考文檔裡面。
Q&A
1.Raft協議中是否存在“活鎖”,如何解決?
活鎖是相對死鎖而言,所謂死鎖,就是兩個或多個線程相互鎖等待,導致都無法推進的情況,而活鎖則是多個工作線程(節點)都在運轉,但是整體系統的狀態無法推進,比如basic-paxos中某些情況下投票總是沒有辦法達成多數派。在Raft中,由於只要一階段提交,選主過程中,可能出現多個節點同時發起選主的情況,這樣導致選票瓜分,無法選出主,在下一輪選舉中依舊如此,導致系統狀態無法往前推進。Raft通過隨機超時解決這個“活鎖”問題。
2.Raft系統對於各個節點的物理時鐘強一致有要求嗎?
Raft協議對物理是時鐘一致性沒有要求,不需要通過原子鐘NTP來校准時間,但是對於超時時間的設置有要求,具體規則如下:
broadcastTime ≪ electionTimeout ≪ MTBF(Mean Time Between Failure)
首先,廣播時間要遠小於選舉超時時間,leader通過廣播不間斷給follower發送心跳,如果這個時間比超時時間短,就會導致follower誤以為leader掛了,觸發選主;然後是超時時間要遠小於機器的平均故障時間,如果MTBF比超時時間還短,則永遠會發生選主問題,而在選主完成之前,無法對外正常提供服務,因此需要保證。一般broadcastTime可以認為是一個網絡RTT,同城1ms以內,異地100ms以內,如果是跨國家,可能需要幾百ms;而機器平均故障時間至少是以月為單位,因此選舉超時時間需要設置1s到5s左右即可。
3.如何保證leader上擁有了所有日志?
一方面,對於leader不變場景,日志只能從leader流向follower,並且發生沖突時以leader的日志為准;另一方面,對於leader一直有變換的場景,通過選舉機制來保證,選舉時采用(LogTerm,LogIndex)誰更新的比對方式,並且要得到多數派的認可,說明新leader的日志至少是多數派中最新的,另一方面,提交的日志一定也是達成了多數派,所以推斷出leader有所有已提交的日志,不會漏。
4.Raft協議為什麼需要日志連續性,日志連續性有有什麼優勢和劣勢?
由Raft協議的選主過程可知,(termId,logId)一定在多數派中最新才可能成為leader,也就是說leader中一定已經包含了所有已經提交的日志。所以leader不需要從其它follower節點獲取日志,保證了日志永遠只從leader流向follower,簡化了邏輯。但缺陷在於,任何一個follower在接受日志前,都需要接受之前的所有日志,並且只有追趕上了,才能有投票權利【否則,復制日志時,不考慮它們是大多數】,如果日志差的比較多,就會導致follower需要較長的時間追趕。任何一個沒有追上最新日志的follower,沒有投票權利,導致網絡比較差的情況下,不容易達成多數派。而Paxos則允許日志有“空洞”,對網絡抖動的容忍性更好,但處理“空洞”的邏輯比較復雜。
5.Raft如何保證日志連續性?
leader向follower發送日志時,會順帶鄰近的前一條日志,follwer接受日志時,會在相同任期號和索引位置找前一條日志,如果存在且匹配,則接受日志,否則拒絕接受,leader會減少日志索引位置並進行重試,直到某個位置與follower達成一致。然後follower刪除索引後的所有日志,並追加leader發送的日志,一旦日志追加成功,則follower和leader的所有日志就保持一致。而Paxos協議沒有日志連續性要求,可以亂序確認。
6.如果TermId小的先達成多數派,TermId大的怎麼辦?可能嗎?
如果TermId小的達成了多數派,則說明TermId大的節點以前是leader,擁有最多的日志,但是沒有達成多數派,因此它的日志可以被覆蓋。但該節點會嘗試繼續投票,新leader發送日志給該節點,如果leader發現返回的termT>currentTerm,且還沒有達成多數派,則重新變為follower,促使TermId更大的節點成為leader。但並不保證擁有較大termId的節點一定會成為leader,因為leader是優先判斷是否達成多數派,如果已經達成多數派了,則繼續為leader。
7.達成多數派的日志就一定認為是提交的?
不一定,一定是在current_term內產生的日志,並且達成多數派才能認為是提交的,持久化的,不會變的。Raft中,leader保持原始日志的termId不變,任何一條日志,都有termId和logIndex屬性。在leader頻繁變更的情況下,有可能出現某條日志在某種狀態下達成了多數派,但日志最終可能被覆蓋掉,比如下圖:
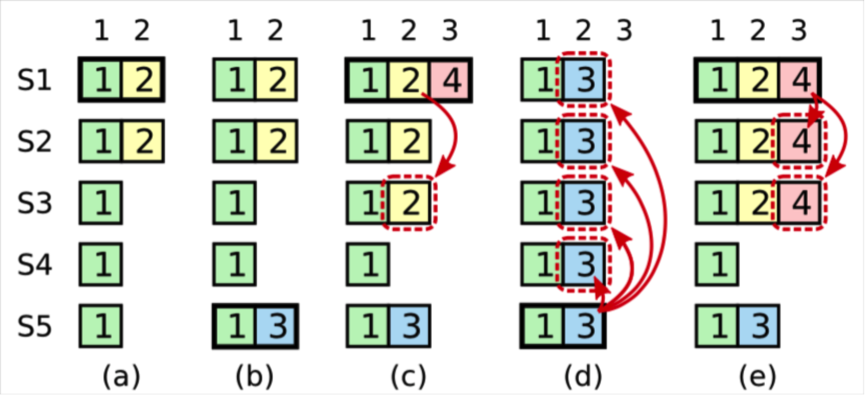
(a).S1是leader,termId是2,寫了一條日志到S1和S2,(termId,logIndex)為(2,2)
(b).S1 crash,S5利用S3,S4,S5當選leader,自增termId為3,本地寫入一條日志,(termId,logIndex)為(3,2)
(c).S5 crash,S1 重啟後重新當選leader,自增termId為4,將(2,2)重新復制到多數派,提交前crash
(d).S1 crash,S5利用S2,S3,S4當選leader,則將(3,2)的日志重新復制到多數派,並提交,這樣(2,2)這條日志曾經雖然達成多數派也會被覆蓋。
(e).假設S1在第一個任期內,將(2,2)達成多數派,則後面S3不會成為leader,也就不會出現覆蓋的情況。
參考文檔
https://raft.github.io/raft.pdf
https://ramcloud.stanford.edu/~ongaro/thesis.pdf
https://ramcloud.stanford.edu/~ongaro/userstudy/paxos.pdf