Paxos算法是萊斯利·蘭伯特(Leslie Lamport)1990年提出的一種基於消息傳遞的一致性算法。Paxos算法解決的問題是一個分布式系統如何就某個值(決議)達成一致。在工程實踐意義上來說,就是可以通過Paxos實現多副本一致性,分布式鎖,名字管理,序列號分配等。比如,在一個分布式數據庫系統中,如果各節點的初始狀態一致,每個節點執行相同的操作序列,那麼他們最後能得到一個一致的狀態。為保證每個節點執行相同的命令序列,需要在每一條指令上執行一個“一致性算法”以保證每個節點看到的指令一致。本文首先會講原始的Paxos算法(Basic Paxos),主要描述二階段提交過程,然後會著重講Paxos算法的變種(Multi Paxos),它是對Basic Paxos的優化,而且更適合工程實踐,最後我會通過Q&A的方式,給出我在學習Paxos算法中的疑問,以及我對這些疑問的理解。
概念與術語
Proposer:提議發起者,處理客戶端請求,將客戶端的請求發送到集群中,以便決定這個值是否可以被批准。
Acceptor:提議批准者,負責處理接收到的提議,他們的回復就是一次投票,會存儲一些狀態來決定是否接收一個值。
replica:節點或者副本,分布式系統中的一個server,一般是一台單獨的物理機或者虛擬機,同時承擔paxos中的提議者和接收者角色。
ProposalId:每個提議都有一個編號,編號高的提議優先級高。
Paxos Instance:Paxos中用來在多個節點之間對同一個值達成一致的過程,比如同一個日志序列號:logIndex,不同的logIndex屬於不同的Paxos Instance。
acceptedProposal:在一個Paxos Instance內,已經接收過的提議
acceptedValue:在一個Paxos Instance內,已經接收過的提議對應的值。
minProposal:在一個Paxos Instance內,當前接收的最小提議值,會不斷更新
Basic-Paxos算法
基於Paxos協議構建的系統,只需要系統中超過半數的節點在線且相互通信正常即可正常對外提供服務。它的核心實現Paxos Instance主要包括兩個階段:准備階段(prepare phase)和提議階段(accept phase)。如下圖所示:

1.獲取一個ProposalId,為了保證ProposalId遞增,可以采用時間戳+serverId方式生成;
2.提議者向所有節點廣播prepare(n)請求;
3.接收者比較n和minProposal,如果n>minProposal,表示有更新的提議,minProposal=n;否則將(acceptedProposal,acceptedValue)返回;
4.提議者接收到過半數請求後,如果發現有acceptedValue返回,表示有更新的提議,保存acceptedValue到本地,然後跳轉1,生成一個更高的提議;
5.到這裡表示在當前paxos instance內,沒有優先級更高的提議,可以進入第二階段,廣播accept(n,value)到所有節點;
6.接收者比較n和minProposal,如果n>=minProposal,則acceptedProposal=minProposal=n,acceptedValue=value,本地持久化後,返回;
否則,返回minProposal
7.提議者接收到過半數請求後,如果發現有返回值>n,表示有更新的提議,跳轉1;否則value達成一致。
從上述流程可知,並發情況下,可能會出現第4步或者第7步頻繁重試的情況,導致性能低下,更嚴重者可能導致永遠都無法達成一致的情況,就是所謂的“活鎖”,如下圖所示:
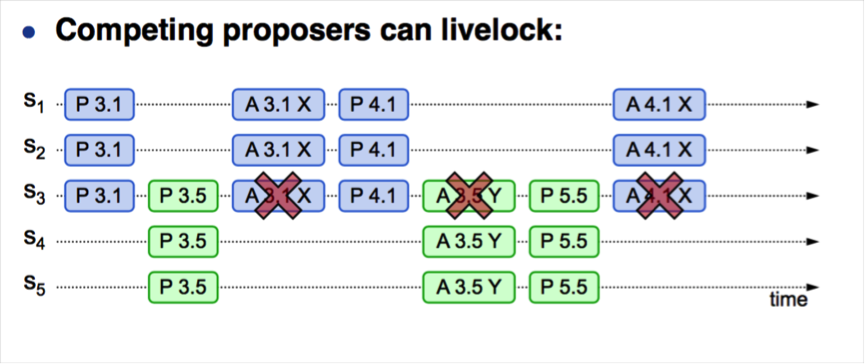
1.S1作為提議者,發起prepare(3.1),並在S1,S2和S3達成多數派;
2.隨後S5作為提議者 ,發起了prepare(3.5),並在S3,S4和S5達成多數派;
3.S1發起accept(3.1,value1),由於S3上提議 3.5>3.1,導致accept請求無法達成多數派,S1嘗試重新生成提議
4.S1發起prepare(4.1),並在S1,S2和S3達成多數派
5.S5發起accpet(3.5,value5),由於S3上提議4.1>3.5,導致accept請求無法達成多數派,S5嘗試重新生成提議
6.S5發起prepare(5.5),並在S3,S4和S5達成多數派,導致後續的S1發起的accept(4.1,value1)失敗
......
prepare階段的作用
從Basic-Paxos的描述可知,需要通過兩階段來最終確定一個值,由於輪回多,導致性能低下,至少兩次網絡RTT。那麼prepare階段能否省去?如下圖所示:
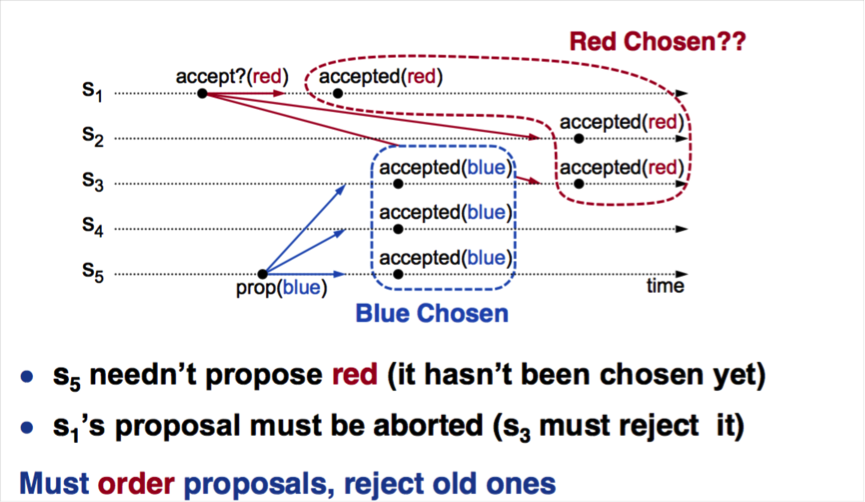
1.S1首先發起accept(1,red),並在S1,S2和S3達成多數派,red在S1,S2,S3上持久化
2.隨後S5發起accept(5,blue),對於S3而言,由於接收到更新的提議,會將acceptedValue值改為blue
3.那麼S3,S4和S5達成多數派,blue在S3,S4和S5持久化
4.最後的結果是,S1和S2的值是red,而S3,S4和S5的值是blue,沒有達成一致。
所以兩階段必不可少,Prepare階段的作用是阻塞舊的提議,並且返回已經接收到的acceptedProposal。同時也可以看到的是,假設只有S1提議,則不會出現問題,這就是我們下面要講的Multi-Paxos。
Multi-paxos算法
Paxos是對一個值達成一致,Multi-Paxos是連續多個paxos instance來對多個值達成一致,這裡最核心的原因是multi-paxos協議中有一個Leader。Leader是系統中唯一的Proposal,在lease租約周期內所有提案都有相同的ProposalId,可以跳過prepare階段,議案只有accept過程,一個ProposalId可以對應多個Value,所以稱為Multi-Paxos。
選舉
首先我們需要有一個leader,其實選主的實質也是一次Paxos算法的過程,只不過這次Paxos確定的“誰是leader”這個值。由於任何一個節點都可以發起提議,在並發情況下,可能會出現多主的情況,比如A,B先後當選為leader。為了避免頻繁選主,當選leader的節點要馬上樹立自己的leader權威(讓其它節點知道它是leader),寫一條特殊日志(start-working日志)確認其身份。根據多數派原則,只有一個leader的startworking日志可以達成多數派。leader確認身份後,可以通過了lease機制(租約)維持自己的leader身份,使得其它proposal不再發起提案,這樣就進入了leader任期,由於沒有並發沖突,因此可以跳過prepare階段,直接進入accept階段。通過分析可知,選出leader後,leader任期內的所有日志都只需要一個網絡RTT(Round Trip Time)即可達成一致。
新主恢復流程
由於Paxos中並沒有限制,任何節點都可以參與選主並最終成為leader,這就無法保證新選出的leader包含了所有日志,可能存在空洞,因此在真正提供服務前,還存在一個獲取所有已提交日志的恢復過程。新主向所有成員查詢最大logId的請求,收到多數派響應後,選擇最大的logId作為日志恢復結束點,這裡多數派的意義在於恢復結束點包含了所有達成一致的日志,當然也可能包含了沒有達成多數派的日志。拿到logId後,從頭開始對每個logId逐條進行paxos協議,因為在新主獲得所有日志之前,系統是無法提供服務的。為了優化,引入了confirm機制,就是將已經達成一致的logId告訴其它acceptor,acceptor寫一條confirm日志到日志文件中。那麼新主在重啟後,掃描本地日志,對於已經擁有confirm日志的log,就不會重新發起paxos了。同樣的,在響應客戶端請求時,對於沒有confirm日志的log,需要重新發起一輪paxos。由於沒有嚴格要求confirm日志的位置,可以批量發送。為了確保重啟時,不需要對太多已提價的log進行paxos,需要將confirm日志與最新提交的logId保持一定的距離。
性能優化
Basic-Paxos一次日志確認,需要至少2次磁盤寫操作(prepare,promise)和2次網絡RTT(prepare,promise)。Multi-Paxos利用一階段提交(省去Prepare階段),將一次日志確認縮短為一個RTT和一次磁盤寫;通過confirm機制,可以縮短新主的恢復時間。為了提高性能,我們還可以實現一批日志作為一個組提交,要麼成功一批,要麼都不成功,這點類似於group-commit,通過RT換取吞吐量。
安全性(異常處理)
1.Leader異常
Leader在任期內,需要定期給各個節點發送心跳,已告知它還活著(正常工作),如果一個節點在超時時間內仍然沒有收到心跳,它會嘗試發起選主流程。Leader異常了,則所有的節點先後都會出現超時,進入選主流程,選出新的主,然後新主進入恢復流程,最後再對外提供服務。我們通常所說的異常包括以下三類:
(1).進程crash(OS crash)
Leader進程crash和Os crash類似,只要重啟時間大於心跳超時時間都會導致節點認為leader掛了,觸發重新選主流程。
(2).節點網絡異常(節點所在網絡分區)
Leader網絡異常同樣會導致其它節點收不到心跳,但有可能leader是活著的,只不過發生了網絡抖動,因此心跳超時不能設置的太短,否則容易因為網絡抖動造成頻繁選主。另外一種情況是,節點所在的IDC發生了分區,則同一個IDC的節點相互還可以通信,如果IDC中節點能構成多數派,則正常對外服務,如果不能,比如總共4個節點,兩個IDC,發生分區後會發現任何一個IDC都無法達成多數派,導致無法選出主的問題。因此一般Paxos節點數都是奇數個,而且在部署節點時,IDC節點的分布也要考慮。
(3).磁盤故障
前面兩種異常,磁盤都是OK的,即已接收到的日志以及對應confirm日志都在。如果磁盤故障了,節點再加入就類似於一個新節點,上面沒有任何日志和Proposal信息。這種情況會導致一個問題就是,這個節點可能會promise一個比已經promise過的最大proposalID更小的proposal,這就違背了Paxos原則。因此重啟後,節點不能參與Paxos Instance,它需要先追上Leader,當觀察到一次完整的paxos instance時該節點結束不能promise/ack狀態。
2.Follower異常(宕機,磁盤損壞等)
對於Follower異常,則處理要簡單的多,因為follower本身不對外提供服務(日志可能不全),對於leader而言,只要能達成多數派,就可以對外提供服務。follower重啟後,沒有promise能力,直到追上leader為止。
Q&A
1.Paxos協議數據同步方式相對於基於傳統1主N備的同步方式有啥區別?
一般情況下,傳統數據庫的高可用都是基於主備來實現,1主1備2個副本,主庫crash後,通過HA工具來進行切換,提升備庫為主庫。在強一致場景下,復制可以開啟強同步,Oracle和Mysql都是類似的復制模式。但是如果備庫網絡抖動,或者crash,都會導致日志同步失敗,服務不可用。為此,可以引入1主N備的多副本形式,我們對比都是3副本的情況,一個是基於傳統的1主2備,另一種基於paxos的1主2備。傳統的1主兩備,進行日志同步時,只要有一個副本接收到日志並就持久化成功,就可以返回,在一定程度上解決了網絡抖動和備庫crash問題。但如果主庫出問題後,還是要借助於HA工具來進行切換,那麼HA切換工具的可用性如何來保證又成為一個問題。基於Paxos的多副本同步其實是在1主N備的基礎上引入了一致性協議,這樣整個系統的可用性完全有3個副本控制,不需要額外的HA工具。而實際上,很多系統為了保證多節點HA工具獲取主備信息的一致性,采用了zookeeper等第三方接口來實現分布式鎖,其實本質也是基於Paxos來實現的。
2.分布式事務與Paxos協議的關系?
在數據庫領域,提到分布式系統,就會提到分布式事務。Paxos協議與分布式事務並不是同一層面的東西。分布式事務的作用是保證跨節點事務的原子性,涉及事務的節點要麼都提交(執行成功),要麼都不提交(回滾)。分布式事務的一致性通常通過2PC來保證(Two-Phase Commit, 2PC),這裡面涉及到一個協調者和若干個參與者。第一階段,協調者詢問參與者事務是否可以執行,參與者回復同意(本地執行成功),回復取消(本地執行失敗)。第二階段,協調者根據第一階段的投票結果進行決策,當且僅當所有的參與者同意提交事務時才能提交,否則回滾。2PC的最大問題是,協調者是單點(需要有一個備用節點),另外協議是阻塞協議,任何一個參與者故障,都需要等待(可以通過加入超時機制)。Paxos協議用於解決多個副本之間的一致性問題。比如日志同步,保證各個節點的日志一致性,或者選主(主故障情況下),保證投票達成一致,選主的唯一性。簡而言之,2PC用於保證多個數據分片上事務的原子性,Paxos協議用於保證同一個數據分片在多個副本的一致性,所以兩者可以是互補的關系,絕不是替代關系。對於2PC協調者單點問題,可以利用Paxos協議解決,當協調者出問題時,選一個新的協調者繼續提供服務。工程實踐中,Google Spanner,Google Chubby就是利用Paxos來實現多副本日志同步。
3.如何將Paxos應用於傳統的數據庫復制協議中?
復制協議相當於是對Paxos的定制應用,通過對一系列日志進行投票確認達成多數派,就相當於日志已經在多數派持久化成功。副本通過應用已經持久化的日志,實現與Master節點同步。由於數據庫ACID特性,本質是由一個一致的狀態到另外一個一致的狀態,每次事務操作都是對應數據庫狀態的變更,並生成一條日志。由於client操作有先後順序,因此需要保證日志的先後的順序,在任何副本中,不僅僅要保證所有日志都持久化了,而且要保證順序。對於每條日志,通過一個logID標示,logID嚴格遞增(標示順序),由leader對每個日志進行投票達成多數派,如果中途發生了leader切換,對於新leader中logID的“空洞”,需要重新投票,確認日志的有效性。
4.Multi-Paxos的非leader節點可以提供服務嗎?
Multi-Paxos協議中只有leader確保包含了所有已經已經持久化的日志,當然本地已經持久化的日志不一定達成了多數派,因此對於沒有confirm的日志,需要再進行一次投票,然後將最新的結果返回給client。而非leader節點不一定有所有最新的數據,需要通過leader確認,所以一般工程實現中,所有的讀寫服務都由leader提供。
5.客戶端請求過程中失敗了,如何處理?
client向leader發起一次請求,leader在返回前crash了。對於client而言,這次操作可能成功也可能失敗。因此client需要檢查操作的結果,確定是否要重新操作。如果leader在本地持久化後,並沒有達成多數派時就crash,新leader首先會從各個副本獲取最大的logID作為恢復結束點,對於它本地沒有confirm的日志進行Paxos確認,如果此時達成多數派,則應用成功,如果沒有則不應用。client進行檢查時,會知道它的操作是否成功。當然具體工程實踐中,這裡面涉及到client超時時間,以及選主的時間和日志恢復時間。
參考文檔
https://ramcloud.stanford.edu/~ongaro/userstudy/paxos.pdf
http://www.cs.utexas.edu/users/lorenzo/corsi/cs380d/papers/paper2-1.pdf
http://research.microsoft.com/en-us/um/people/lamport/pubs/paxos-simple.pdf
https://zhuanlan.zhihu.com/p/20417442
http://my.oschina.net/hgfdoing/blog/666781
http://www.cnblogs.com/foxmailed/p/5487533.html
http://www.wtoutiao.com/p/1a7mSx6.html