MySQL的loose index scan
眾所周知,InnoDB采用IOT(index organization table)即所謂的索引組織表,而葉子節點也就存放了所有的數據,這就意味著,數據總是按照某種順序存儲的。所以問題來了,如果是這樣一個語句,執行起來應該是怎麼樣的呢?語句如下:
select count(distinct a) from table1;
列a上有一個索引,那麼按照簡單的想法來講,如何掃描呢?很簡單,一條一條的掃描,這樣一來,其實做了一次索引全掃描,效率很差。這種掃描方式會掃描到很多很多的重復的索引,這樣說的話優化的辦法也是很容易想到的:跳過重復的索引就可以了。於是網上能搜到這樣的一個優化的辦法:
select count(*) from (select distinct a from table1) t;
從已經搜索到的資料看,這樣的執行計劃中的extra就從using index變成了using index for group-by。
但是,但是,但是,好在我們現在已經沒有使用5.1的版本了,大家基本上都是5.5以上了,這些現代版本,已經實現了loose index scan:
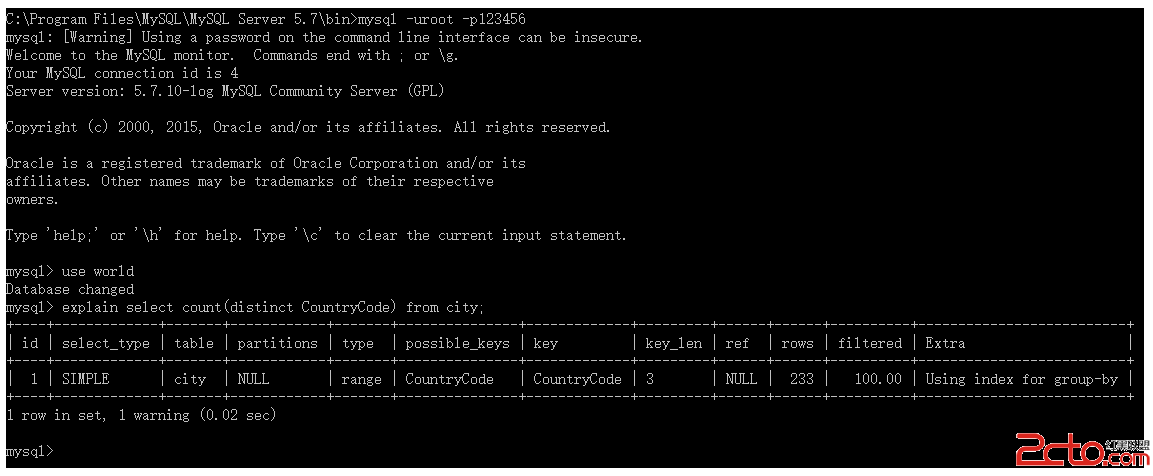
很好很好,就不需要再用這種奇技淫巧去優化SQL了。
文檔裡關於group by這裡寫的有點意思,說是最大眾化的辦法就是進行全表掃描並且創建一個臨時表,這樣執行計劃就會難看的要命了,肯定有ALL和using temporary table了。