對於高性能數據庫操作,只靠設計最優的庫表結構、建立最好的索引是不夠的,還需要合理的設計查詢。如果查詢寫得很糟糕,即使庫表結構再合理、索引再合適,也無法實現高性能。查詢優化、索引優化、庫表結構優化需要齊頭並進,一個不落。
6.1 為什麼查詢速度會慢
通常來說,查詢的生命周期大致可以按照順序來看:從客戶端>>服務器>>在服務器上進行解析>>生成執行計劃>>執行>>返回結果給客戶端。其中執行可以認為是整個生命周期中最重要的階段,這其中包括了大量為了檢索數據到存儲引擎的調用以及調用後的數據處理,包括排序、分組等。了解查詢的生命周期、清楚查詢的時間消耗情況對於優化查詢有很大的意義。
6.2 優化數據訪問
查詢性能低下的最基本的原因是訪問的數據太多。大部分性能低下的查詢都可以通過減少訪問的數據量的方式進行優化。
1.確認應用程序是否在檢索大量超過需要的數據。這通常意味著訪問了太多的行,但有時候也可能是訪問了太多的列。
2.確認MySQL服務器層是否在分析大量超過需要的數據行。
6.2.1 是否向數據庫請求了不需要的數據
請求多余的數據會給MySQL服務器帶來額外的負擔,並增加網絡開銷,另外也會消耗應用服務器的CPU內存和資源。這裡有一些典型案例:
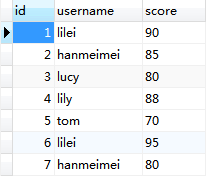
1、查詢不需要的記錄:例如在新聞網站中取出100條記錄,但是只是在頁面上顯示10條。實際上MySQL會查詢出全部的結果烏鴉,客戶端的應用程序會接收全部的結果集數據,然後拋棄其中大部分數據。最簡單有效的解決方法就是在這樣的查詢後面加上LIMIT。
2、多表關聯時返回全部列,例如:
3、總是取出全部的列:每次看到SELECT *的時候都需要懷疑是不是真的需要返回全部的列?取出全部列,會主優化器無法完成索引覆蓋掃描這類優化,還會為服務器帶來額外的IO、內存和CPU的消耗。如果應用程序使用了某種緩存機制,或者有其他考慮,獲取超過需要的數據也可能有其好處,但不要忘記這樣做的代價是什麼。獲取並緩存所有的列的查詢,相比多個獨立的只獲取部分列的查詢可能就更有好處。
4、重復查詢相同的數據:不要不斷地重復執行相同的查詢,然後每次都返回完全相同的數據。當初次查詢的時候將這個數據緩存起來,需要的時候從緩存中取出,這樣性能顯然更好。
6.2.2 MySQL是否在掃描額外的記錄
對於MySQL,最簡單的衡量查詢開銷的三個指標有:響應時間、掃描的行數、返回的行數。這三個指標都會記錄到MySQL的慢日志中,所以檢查慢日志記錄是找出掃描行數過多的查詢的好辦法。
響應時間
響應時間是兩個部分之和:服務時間和排隊時間,一般常見和重要的等待是IO和鎖等待。
掃描的行數和返回的行數
分析查詢時,查看該查詢掃描的行數是非常有幫助的。一定程度上能夠說明該查詢找到需要的數據的效率高不高。理想的情況下掃描的行數和返回的行數應該是相同的。當然這只是理想情況。一般來說掃描的行數對返回的行數的比率通常很小,一般在1:1到10:1之間。
掃描的行數和訪問類型
MySQL有好幾種訪問方式可以查找並返回一行結果。有些訪問方式可能需要掃描很多行才能返回一行結果,也有些訪問方式可能無須掃描就能返回結果。
在EXPLAIN語句的TYPE列返回了訪問類型。如果查詢沒有辦法找到合適的訪問類型,那麼解決的最好辦法通常就是增加一個合適的索引。索引讓MySQL以最高效、掃描行最少的方式找到需要的記錄。
一般MySQL能夠使用如下三種方式應用WHERE條件,從好到壞依次為:
1、在索引中使用WHERE條件來過濾不匹配的記錄。這是在存儲引擎層完成的。
2、使用索引覆蓋掃描(在extra列中出現了using index)來返回記錄,直接從索引中過濾不需要的記錄並返回命中的結果。這是在MySQL服務器層完成的,但無須回表查詢記錄。
3、從數據表中返回數據,然後過濾不滿足條件的記錄(在extra列中出現using where)。這在MySQL服務器層完成,MySQL需要先從數據表讀出記錄然後過濾。
6.3 重構查詢的方式
6.3.1 一個復雜查詢還是多個簡單查詢
MySQL內部每秒能夠掃描內存中上百萬行數據,相比之下,MySQL響應數據給客戶端就慢得多了。在其他條件都相同的時候,使用盡可能少的查詢當然是更好的。但是有時候,將一個大查詢分解為多個小查詢也是很有必要的。
6.3.2 切分查詢
有時候對於一個大查詢我們需要“分而治之”,對於刪除舊數據,如果用一個大的語句一次性完成的話,則可能需要一次性鎖住很多數據、占滿整個事務日志、耗盡系統資源、阻塞很多小的但重要的查詢。將一個大的DELETE語句切分成多個較小的查詢可以盡可能小地影響MySQL性能,同時還可以減少MySQL復制的延遲。例如我們需要每個月運行一次下面的查詢:
那麼可以用類似下面的辦法來完成同樣的工作:
6.3.3 分解關聯查詢
乍一看這樣做並沒有什麼好處,但其有如下優勢:
1、讓緩存的效率更高。對MySQL的查詢緩存來說,如果關聯中的某個表發生了變化 ,那麼就無法使用查詢緩存了,而拆分後,如果某個表很少改變,那麼該表的查詢緩存能重復利用 。
2、將查詢後,執行單個查詢可以減少鎖的競爭。
3、查詢性能也有所提升,使用IN()代替關聯查詢,可以讓MySQL按照ID順序進行查詢,這比隨機的關聯要更高效。
6.4 查詢執行的基礎
當希望MySQL能夠能更高的性能運行查詢時,最好的辦法就是弄清楚MySQL是如何優化和執行查詢的。
6.4.1 MySQL客戶端/服務端通信協議
MySQL客戶端和服務器之間的通信協議是“半雙工”的,在任何一個時刻,要麼由服務器向客戶端向服務端發送數據,要麼是由客戶端向服務器發送數據,這兩個動作不能同時發生。
一旦客戶端發送了請求,它能做的事情就只是等待結果了,如果查詢太大,服務端會拒絕接收更多的數據並拋出相應錯誤,所以參數max_allowed_packet就特別重要。相反,一般服務器響應給用戶的數據通常很多,由多個數據包組成。當服務器開始響應客戶端請求時,客戶端必須完整地接收整個返回結果,而不能簡單地只取前面幾條結果,然後主服務器停止發送數據。這種情況下,客戶端若接收完整的結果,然後取前面幾條需要的結果,或者接收完幾條結果然後粗暴地斷開連接,都不是好主意。這也是必要的時候需要在查詢中加上limit限制的原因。
換一種方式解釋這種行為:當客戶端從服務器取數據時,看起來是一個拉數據的過程,但實際上是MySQL在向客戶端推數據的過程。客戶端不斷地接收從服務器推送的數據,客戶端也沒法讓服務器停下來。
當使用多數連接MySQL的庫函數從MySQL獲取數據時,其結果看起來都像是從MySQL服務器獲取數據,而實際上都是從這個庫函數的緩存獲取數據。多數情況下這沒什麼問題,但是如果需要返回一個很大的結果集時,這樣做並不好,因為庫函數會花很多時間和內存來存儲所有的結果集。如果能盡早開始處理這些數據,就能大大減少內在的消耗,這種情況下可以不使用緩存來記錄結果而是直接處理。PHP的 mysql_query(),此時數據已經到了PHP的緩存中,而mysql_unbuffered_query()不會緩存結果。
查詢狀態:可以使用SHOW FULL PROCESSLIST命令查看查詢的執行狀態。Sleep、Query、Locked、Analyzing and statistics、Copying to tmp table[on disk]、Sorting result、Sending data
6.4.2 查詢緩存
在解析一個查詢語句之前,如果查詢緩存是打開的,那麼MySQL會優先檢查這個查詢是否命中查詢緩存中的數據。這是檢查是通過一個對大小寫敏感的哈希查找實現的。如果當前的查詢恰好命中了查詢緩存,那麼在返回查詢結果之前MySQL會檢查一次用戶權限。如果權限沒有問題,MySQL會跳過執行階段,直接從緩存中拿到結果並返回給客戶端。
6.4.3 查詢優化處理
查詢生命周期的下一步是將一個SQL轉換成一個執行計劃,MySQL再依照這個執行計劃和存儲引擎進行交互。這包括多個子階段:解析SQL、預處理、優化SQL執行計劃。
1、語法解析器和預處理首先MySQL通過關鍵字將SQL語句進行解析,並生成一棵解析樹。MySQL解析器將使用MySQL語法規則驗證和解析查詢。例如是否使用錯誤的關鍵字,或者使用關鍵字的順序是否正確,引號是否能前後正確匹配等。
2、預處理器則根據一些MySQL規則進一步檢查解析樹是否合法,例如檢查數據表和數據列是否存在,還會解析名字和別名看它們是否有歧義。
3、一下步預處理會驗證權限。
查詢優化器:一條語句 可以有很多種執行方式,最後都返回相同的結果。優化器的作用就是找到最好的執行計劃。MySQL使用基於成本的優化器,它將嘗試預測一個查詢使用某種執行計劃時的成本,並選擇其中成本最小的一個。成本的最小單位是隨機讀取一個4K的數據頁的成本,並加入一些因子來估算某引動操作的代價。可以通過查詢當前會話的Last_query_cost的值來得知MySQL計算的當前查詢的成本。
這是根據一系列的統計信息計算得來的:每個表或者索引的頁面個數、索引的基數(索引中不同值的數量)、索引和數據行的長度、索引分布情況。
當然很多原因會導致MySQL優化器選擇錯誤的執行計劃:例如統計信息不准確或執行計劃中的成本估算不等同於實際執行的成本。
MySQL如何執行關聯查詢:MySQL對任何關聯都執行嵌套循環關聯操作,即MySQL先在一個表中循環取出單條數據,然後再嵌套循環到一個表中尋找匹配的行,依次下去直到找到的有匹配的行為止。然後根據各個表匹配的行,返回查詢中需要的各個列。(嵌套循環關聯)
執行計劃:MySQL生成查詢的一棵指令樹,然後通過存儲引擎執行完成這棵指令樹並返回結果。最終的執行計劃包含了重構查詢的全部信息。如果對某個查詢執行EXPLAIN EXTENDED,再執行SHOW WARNINGS,就可以看到重構出的查詢。
MySQL的執行計劃是一棵左側深度優先的樹。
不過,如果有超過n個表的關聯,那麼需要檢查n的階乘種關聯順序。我們稱之為所有可能的執行計劃的“搜索空間”。實際上,當需要關聯的表超過optimizer_search_depth的限制的時候,就會選擇“貪婪”搜索模式。
排序優化:無論如何排序都是一個成本很高的操作,所以從性能角度考慮,應盡可能避免排序或者盡可能避免對大量數據進行排序。如果需要排序的數據量小於排序緩沖區,MySQL使用內存進行“快速排序”操作。如果內存不夠排序,那麼MySQL會先將數據分塊,對每個獨立的塊使用“快速排序”進行排序,並將各個塊的排序結果存放在磁盤上,然後將各個排序的塊進行合並,最手返回排序結果。
MySQL有兩種排序方法:
兩次傳輸排序(舊版),讀取行指針和需要排序的字段,對其進行排序,然後再根據排序結果讀取所需要的數據行。顯然是兩次傳輸,特別是讀取排序後的數據時(第二次)大量隨機I/O,所以兩次傳輸成本高。
MySQL在進行文件排序時需要使用的臨時存儲空間可能會比想象的要大得多,因為MySQL在排序時,對每一個排序記錄都會分配一個足夠長的定長空間來存放。這個定長空間必須足夠以容納其中最長的字符串。
在關聯查詢的時候如果需要排序,MySQL會分兩種情況來處理這樣的文件排序。如果ORDER BY子句的所有列都來自關聯的第一個表,那麼MySQL在關聯處理第一個表時就進行文件排序。如果是這樣那麼在MySQL的EXPLAIN結果中可以看到Extra字段會有Using filesort。除此之外的所有情況,MySQL都會將關聯的結果存放在一個臨時表中,然後在所有的關聯都結束後,再進行文件排序。這種情況下Extra字段可以看到Using temporary;Using filesort。如果查詢中有LIMIT的話,LIMIT也會在排序之後應用,所以即使需要返回較少的數據,臨時表和需要排序的數據量仍然會非常大。
6.4.4 查詢執行引擎
相對於查詢優化,查詢執行簡單些了,MySQL只根據執行計劃輸出的指令逐步執行。指令都是調用存儲引擎的API來完成,一般稱為 handler API,實際上,MySQL優化階段為每個表都創建了一個 handler 實例,用 handler 實例獲取表的相關信息(列名、索引統計信息等)。
存儲引擎接口有著非常豐富的功能,但是底層接口卻只有幾十個,這些接口像搭積木一樣能夠完成查詢的大部分操作。例如,有一個查詢某個索引的第一行的接口,再有一個查詢某個索引條件的下一條目的功能,有了這兩個功能就可以完成全索引掃描操作。
6.4.5 返回結果給客戶端
查詢執行的最後一個階段就是將結果返回給客戶端。即使查詢不需要返回結果集給客戶端,MySQL仍然會返回這個查詢的一些信息,例如該查詢影響到的行數。
MySQL將結果集返回客戶端是一個增量、逐步返回的過程。一旦服務器處理完最後一個關聯表,開始生成第一條結果時,MySQL就可以開始向客戶端逐步返回結果集了。
這樣處理有兩個好處:服務端無須存儲太多的結果,也就不會因為要返回太多結果而消耗太多內存。另外,這樣的處理也讓MySQL客戶端第一時間獲得返回的結果。
當然,優化器存在其局限性,以及某些特定的優化類型,有興趣的可以在書中找到答案。