在我的博客上,以前我經常談到SQL Serverl裡的書簽查找,還有它們帶來的很多問題。在今天的文章裡,我想從性能角度進一步談下書簽查找,還有它們如何拉低你整個SQL Server性能。
書簽查找——反復循環
如果你的非聚集索引不是個覆蓋非聚集索引,SQL Server的查詢優化器會引入書簽查找。對於從非聚集索引你返回的每一行,SQL Server需要在聚集索引裡或堆表裡進行額外的查找操作。
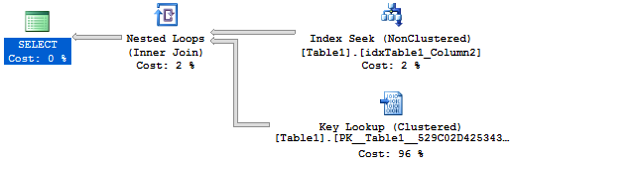
例如當你的的聚集索引包含3層,為了返回必要的信息,對於每一行,你需要3頁額外的讀取。因此,查詢優化器再執行計劃裡選擇書簽查找操作,僅在有意義的時候發生——基於你查詢的選擇度。下圖展示了有書簽查找操作的執行計劃。
通常人們不會太關注書簽查找,因為它們只執行幾次。如果你的查詢選擇度太低,查詢優化器會用聚集索引掃描或表掃描運算符直接掃描整個表。但只在SQL Server重用緩存的執行計劃,這個計劃是有多次不同運行值,包含書簽查找的(基於最初提供的輸入值),因此這個情況很容易發生,書簽查找反復執行。
為了演示這個性能問題,接下來的查詢我指定查詢優化器使用特定的非聚集索引。查詢本身返回80000行,因為對於每個查詢執行,SQL Server需要進行書簽查找80000次——反復執行。
CREATE PROCEDURE RetrieveData AS SELECT * FROM Table1 WITH (INDEX(idxTable1_Column2)) WHERE Column3 = 2 GO
下圖展示了查詢執行後的實際執行計劃。
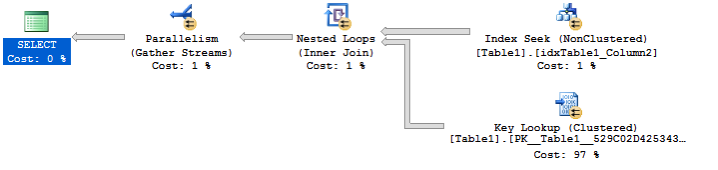
執行計劃看起來非常恐怖(查詢優化器甚至啟用了並行計劃!),因為書簽查找運算符這裡執行了80000次,查詢本身產生了超過165000個邏輯讀!(邏輯讀個數可以從STATISTIC IO裡獲取)。

接下來向你展示下,當你有很多並行用戶執行這個糟糕查詢時,SQL Server會發生什麼。我會使用ostress.exe(RML工具的一部分)來模擬100個並行用戶的查詢。
ostress.exe -Q”EXEC BookmarkLookupsPerformance.dbo.RetrieveData” -n100 -q
在我的測試系統上花費了近15秒來完成100個並行查詢。在此期間,CPU占用很高,因為SQL Server需要嵌套循環運算符來進行書簽查找操作。嵌套循環操作當然很占CPU資源。
現在讓我們修改索引設計,為這個查詢創建覆蓋非聚集索引。有了非聚集索引,查詢優化器不需要再執行計劃裡進行書簽查找。一個非聚集索引查找就可以返回同樣的結果:
CREATE NONCLUSTERED INDEX idxTable1_Column2 ON Table1(Column3) INCLUDE (Column2) WITH (DROP_EXISTING = ON) GO
這次當我們再次用ostress.exe執行同個查詢,我們看到每個查詢在5秒內完成。和我們剛才看到的15秒有很大的區別。這就是覆蓋非聚集索引的威力:在我們查詢裡氣門請求的數據都可以在非聚集索引裡直接找到,因此書簽查找就可以避免。
小結
在這個文章裡我向你展示了不好的書簽查找會傷及性能。因此,對於重要的查詢快速完成查詢非常重要——而使用並行的書簽查找的執行計劃並不是好的選擇。這裡覆蓋非聚集索引可以幫到你。下次設計索引時可以考慮下這個方法。
以上就是本文的全部內容,希望本文的內容對大家的學習或者工作能帶來一定的幫助,同時也希望多多支持!