轉載請注明: TheViper http://www.cnblogs.com/TheViper
這篇說下mysql查詢語句優化
典型案例:查詢不需要的記錄,多表關聯時返回全部列,總是取出全部列,重復查詢相同的數據。
最簡單的衡量查詢開銷的指標。
在評估查詢開銷時,需要考慮下從表中找到某一行數據的成本,mysql有好多種方式可以查找並返回一行結果。有些訪問方式可能需要掃描很多行才能返回一行結果,也有些方式可能無須掃描就能返回結果。
在EXPLAIN語句中type列反應了訪問類型。訪問類型有很多種,從全表掃描到索引掃描,范圍掃描,唯一索引查詢,常數引用等。這裡列的這些,速度是從慢到快,掃描的行數也是從小到大。
因此,要盡力避免讓每一條sql做全表掃描。
如果查詢沒辦法找到合適的訪問類型,那麼解決的最好方式通常就是增加一個合適的索引,這個上一篇裡說到過。索引讓mysql以最高效,掃描行數最少的方式找到需要的記錄。
一般mysql有三種方式應用where條件。從好到壞依次為
如果發現查詢中掃描大量的數據卻只返回少量的行。可以嘗試下面方法優化。
一個復雜查詢還是多個簡單查詢?
在傳統實現中,總是強調數據庫層完成盡可能多的工作,這樣做的邏輯在於以前總是認為網絡通信,查詢解析,優化是一件代價很高的事。
但是這樣的想法對於mysql並不適用,mysql從設計上讓連接和斷開連接都很輕量,在返回一個小的查詢結果方面很高效。另外,現在的網絡速度比以前快的多,無論是寬帶還是延遲。在某些版本的mysql上,即便在一個通用的服務器上,也能運行每秒超過10萬的查詢。即使是一個千兆網卡也能輕松滿足每秒超過2000次的查詢。
切分查詢
即所謂的分而治之,將大查詢切分成小查詢,每個查詢功能完全一樣,每次只返回一小部分結果。
刪除舊的數據就是個很好的例子,定期的清理大量數據時,如果用一個大語句一次性完成的話,則可能一次鎖住很多數據,占滿整個事務日志,耗盡系統資源,阻塞很多小的但很重要的查詢。
因此可以


分解關聯查詢
簡單說,就是對每個表進行一次單表查詢,然後將結果在應用程序中進行關聯。例如

可以將其分解成下面查詢來替代

乍一看,這樣做沒有好處。事實上,有下面這些優勢
mysql中“關聯”一詞所包含的意義比一般理解上要更廣泛。總的來說,mysql認為任何一個查詢都是一次“關聯”,並不僅僅是一個查詢需要到兩個表匹配才叫關聯。所以,在mysql中,每個查詢,每個片段(包括子查詢,甚至基於單表的select)都可能是關聯。
下面看下mysql如何執行關聯查詢。
先看union查詢。mysql先將一系列的單個查詢結果放到一個臨時表中,然後再重新讀取臨時表數據完成union查詢。在mysql概念中,每個查詢都是一次關聯,所以讀取結果臨時表也是一次關聯。
mysql對任何關聯都執行嵌套循環關聯策略,即mysql先在一個表中循環取出單條數據,然後再嵌套循環到下一個表中尋找匹配的行,依次下去,直到所有表中匹配的行為止。然後根據各個表匹配的行,返回查詢中所需要的各個列。


可以看到查詢是從actor表開始的,這是mysql關聯查詢優化器自動做的選擇。現在用STRAIGHT_JOIN關鍵字,不讓mysql自動優化關聯。

這次的關聯順序倒轉過來,可以看到,倒轉後第一個關聯表只需要掃描很少的行數。而且第二個,第三個關聯表都是根據索引查詢,速度都很快。
最後,確保任何的group by,order by中的表達式只涉及到一個表中的列,這樣mysql才有可能使用索引優化這個過程。
無論如何排序都是一個成本很高的操作。所以從性能角度考慮,應盡可能避免排序或避免對大量數據進行排序。
上一篇說到了如何通過索引排序。當不能使用索引生成排序結果時,mysql需要自己進行排序,如果數據量小,就在內存中進行,數據量大,則需要使用磁盤。mysql統一將這一過程稱為文件排序(filesort)。
在關聯查詢時如果需要排序,mysql會分兩種情況處理文件排序。
1.如果order by子句中的所有列都來自關聯的第一個表,mysql在關聯處理第一個表時就進行文件排序。如果是這樣,在EXPLAIN結果中的Extra字段會有Using filesort.
2.除此之外的所有情況,mysql都會先將關聯的結果存放到一個臨時表中,然後在所有的關聯結束後再進行文件排序。如果是這樣,在EXPLAIN結果中的Extra字段會有Using temporary;Using filesort.如果查詢中有LIMIT的話,LIMIT也會在排序之後應用。所以即使需要返回較少的行數,臨時表和需要排序的數據量仍然會非常大。
mysql5.6在這裡做了很多重要的改進。當只需要返回部分排序結果的時候,例如,使用LIMIT子句,mysql不再所有結果排序,而是根據實際情況,選擇拋棄不滿足條件的結果,然後再排序。
mysql的子查詢實現非常糟糕,最糟糕的一類查詢是where條件中包含in的子查詢語句。
mysql對in()列表中的選項有專門的優化策略,一般會認為,mysql會先執行子查詢。但是,很不幸,mysql會先將相關的外層表押到子查詢中。例如

mysql會將查詢改成這樣


可以看到,mysql會先對film進行全表掃描,然後根據返回的film_id逐個執行子查詢。如果外層表是個非常大的表,那這個查詢的性能會非常糟糕。當然很容易重寫這個查詢,直接用關聯就可以了。

另一個優化方法是使用函數GROUP_CONCAT()在IN()中構造一個由逗號分隔的列表。
另外,通常建議用EXISTS()等效的改寫IN()子查詢。

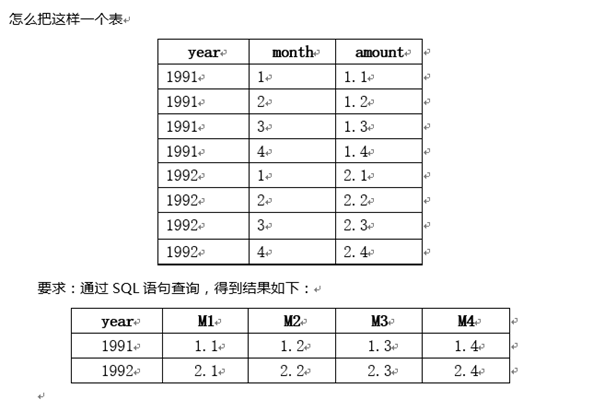
並不是所有的關聯子查詢性能都會很差。寫好之後,先測試,然後做出自己的判斷。有時候,子查詢也會快些,例如當返回結果中只有一個表的某些列時,假設要返回所有包含同一個演員參演的電影,因為一個電影會有很多演員參演,所以可能會返回些重復記錄。

使用DISTINCT和GROUP BY移除重復的記錄
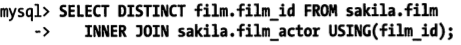
如果用EXISTS的話,就不需要使用DISTINCT和GROUP BY,也不會產生重復的結果集。我們知道一旦使用DISTINCT和GROUP BY,那麼在執行過程中,通常會參數臨時中間表。

測試,看哪種寫法快點

可以看到在這個案例中,子查詢速度要快些。
對於MIN(),MAX(),mysql的優化做的並不好,例如
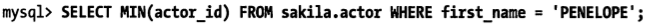
mysql不能夠進行主鍵掃描,只有全表掃描了。這時可以用LIMIT重寫查詢。

這樣可以讓mysql掃描盡可能少的表
它們都可以使用索引優化,這也是最有效的辦法。當無法使用索引時,group by使用兩種策略完成:使用臨時表或文件排序來做分組。
對關聯查詢分組,通常用查找表的標識符分組的效率比其他列更高。例如

下面的效率更高

這個查詢利用了演員姓名和id直接相關的特點,所以改寫後的結果不受影響。
如果不相關的話,可以用MIN(),MAX().繞過這種限制。但一定要清楚,select後面出現的非分組列一定是直接依賴分組列的,並且在每個組內的值是唯一的。

實在較真的話,寫成這樣

不過這樣成本有點高。因為子查詢需要創建和填充臨時表,而創建的臨時表是沒有任何索引的。
最簡單的辦法是盡可能使用索引覆蓋掃描,而不是查詢所有的列。然後根據需要做一次關聯操作,再返回所需的列。例如

如果這個表非常大,最好改寫成這樣
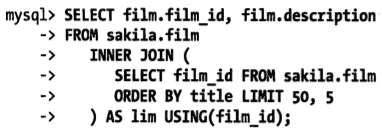
這裡的”延遲關聯“將大大提升效率,讓mysql掃描盡可能少的頁面,獲取需要訪問的記錄後再根據關聯列回原表查詢需要的所有列。這個也可以用來優化關聯查詢裡面的limit.
有時候也可以將limit查詢轉換為已知位置的查詢,讓mysql通過范圍掃描獲得結果。例如
在一個位置列上有索引,並且預先計算出了邊界值。

另外,limit和offset的問題,會導致mysql掃描了大量不需要的行然後在拋棄掉,比如select .... limit 1000,20.
這時可以有變通方法,例如圖書館按照租借記錄翻頁,獲取第一頁。

因為rental_id是遞增的,而查看記錄的時候都是從離當前時間最近的地方開始的。後面的頁就可以用類似於下面的查詢實現