mysql double write (二次寫)是mysql innodb存儲引擎的一個重要特性,本人這兩天翻閱了相關的資料,結合自己已有的知識,說說自己對double write的理解,供各位看官參考。
頁斷裂(partial write)
double write技術innodb為解決頁斷裂(partial write)問題而生,所謂頁斷裂是數據庫宕機時(OS重啟,或主機掉電重啟),數據庫頁面只有部分寫入磁盤,導致頁面出現不一致的情況。數據庫,OS和磁盤讀寫的基本單位是塊,也可以稱之為(page size)block size。我們知道數據庫的塊一般為8K,16K;而OS的塊則一般為4K;IO塊則更小,linux內核要求IO block size<=OS block size。磁盤IO除了IO block size,還有一個概念是扇區(IO sector),扇區是磁盤物理操作的基本單位,而IO 塊是磁盤操作的邏輯單位,一個IO塊對應一個或多個扇區,扇區大小一般為512個字節。所以各個塊大小的關系可以梳理如下:
DB block > OS block >= IO block > 磁盤 sector,而且他們之間保持了整數倍的關系。比如我的系統各個塊的大小如下,DB以mysql為例,OS以linux為例。
DB block size
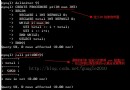
root@(none) 09:13:02>show variables like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
OS block size
[1 Single:CHECK: mysql ~ ]
$ getconf PAGESIZE
4096
IO block size
比如查看sdb1分區的IO block size
[root@chuckkkk]# blockdev --getbsz /dev/sdb1
4096
sector size
[root@chuckkkk]# fdisk -l | grep Sector
Sector size (logical/physical): 512 bytes / 512 bytes
從上面的結果可以看到DB page=4*OS page=IO page=8*sector size。
由於任何DB page的寫入,最終都會轉為sector的寫入,如果在寫磁盤的過程中,出現異常重啟,就可能會發生一個DB頁只寫了部分sector到磁盤,進而出現頁斷裂的情況。
頁斷裂與數據庫一致性
前面我們分析了異常重啟一定會導致頁斷裂,而頁斷裂就意味著數據庫頁面不完整,那麼數據庫頁面不完整是否就意味著數據庫不一致呢???我們知道,數據庫異常重啟時,自身有異常恢復機制,我這裡不打算展開講異常恢復機制,因為不同數據庫的異常恢復流程不同。主流數據庫基本原理類似:第一階段重做redo日志,恢復數據頁和undo頁到異常crash時的狀態;第二階段,根據undo頁的內容,回滾沒有提交事務的修改。通過兩個階段保證了數據庫的一致性。對於mysql而言,在第一階段,若出現頁斷裂問題,則無法通過重做redo日志恢復,進而導致恢復中斷,數據庫不一致。這裡大家可能會有疑問,數據庫的redo不是記錄了所有的變更,並且是物理的嗎?理論上來說,無論頁面是否斷裂,從上一個檢查點對應的redo位置開始,一直重做redo,頁面自然能恢復到正常狀態。對嗎?講清楚這個問題,先講講重做日志(redo)格式。
重做日志(redo)格式
數據庫系統實現日志主要有三種格式,邏輯日志(logical logging),物理日志(physical logging),物理邏輯日志(physiological logging),而對於redo日志,則主要采用物理日志和物理邏輯日志兩類。邏輯日志,記錄一個個邏輯操作,不涉及物理存儲位置信息,比如mysql的binlog;物理日志,則是記錄一個個具體物理位置的操作,比如在2號表空間,1號文件,48頁的233這個offset地方寫入了8個字節的數據,通過(group_id,file_id,page_no,offset)4元組,就能唯一確定數據存儲在磁盤的物理位置;物理邏輯日志是物理日志和邏輯日志的混合,如果一個數據庫操作(DDL,DML,DCL)產生的日志跨越了多個頁面,那麼會產生多個物理頁面的日志,但對於每個物理頁面日志,裡面記錄則是邏輯信息。這裡我舉一個簡單的INSERT操作來說明幾種日志形式。
比如innodb表T(c1,c2, key key_c1(c1)),插入記錄row1(1,’abc’)
邏輯日志:
<insert OP, T, 1,’abc’>
邏輯物理日志:
因為表T含有索引key_c1, 一次插入操作至少涉及兩次B樹操作,二次B樹必然涉及至少兩個物理頁面,因此至少有兩條日志
<insert OP, page_no_1, log_body>
<insert OP, page_no_2, log_body>
物理日志:
由於一次INSERT操作,物理上來說要修改頁頭信息(如,頁內的記錄數要加1),要修改相鄰記錄裡的鏈表指針,要修改Slot屬性等,因此對應邏輯物理日志的每一條日志,都會有N條物理日志產生。
< group_id,file_id,page_no,offset1, value1>
< group_id,file_id,page_no,offset2, value2>
……
< group_id,file_id,page_no,offsetN, valueN>
因此對於上述一個INSERT操作,會產生一條邏輯日志,二條邏輯物理日志,2*N條物理日志。從上面簡單的分析可以看出,邏輯日志的日志量最小,而物理日志的日志量最大;物理日志是純物理的;而邏輯物理日志則頁間物理,頁內邏輯,所謂physical-to-a-page, logical-within-a-page。
redo格式與數據一致性
回到“發生頁斷裂後,是否會影響數據庫一致性”的問題,發生頁斷裂後,對於利用純物理日志實現redo的數據庫不受影響,因為每一條redo日志完全不依賴物理頁的狀態,並且是冪等的(執行一次與N次,結果是一樣的)。另外要說明一點,redo日志的頁大小一般設計為512個字節,因此redo日志頁本身不會發生頁斷裂。而邏輯物理日志則不行,比如修改頁頭信息,頁內記錄數加1,slot信息修改等都依賴於頁面處於一個一致狀態,否則就無法正確重做redo。而mysql正是采用這種日志類型,所以發生頁面斷裂時,異常恢復就會出現問題,需要借助於double write技術來輔助處理。
double write處理頁斷裂
doublewrite是Innodb表空間內部分配的一片緩沖區,一般double write包含128個頁,對於pagesize為16k的頁,總共2MB,doublewrite頁與數據頁一樣有物理存儲空間,存在於共享表空間中。Innodb在寫出緩沖區中的數據頁時采用的是一次寫多個頁的方式,這樣多個頁就可以先順序寫入到doublewrite緩沖區,並調用fsync()保證這些數據被寫出到磁盤,然後數據頁才被寫出到它們實際的存儲位置並再次調用fsync()。故障恢復時Innodb檢查doublewrite緩沖區與數據頁原存儲位置的內容,若doublewrite頁處於頁斷裂狀態,則簡單的丟棄;若數據頁不一致,則會從doublewrite頁還原。由於doublewrite頁落盤與數據頁落盤在不同的時間點,不會出現doublewrite頁和數據頁同時發生斷裂的情況,因此doublewrite技術可以解決頁斷裂問題,進而保證了重做日志能順利進行,數據庫能恢復到一致的狀態。
oracle如何處理頁斷裂
oracle與mysql一樣,采用的redo日志也是邏輯物理格式,但沒有doublewrite技術。我一直就想著oracle這麼牛逼的數據庫,一定有它自己的方式來應對這種問題。也許這就是所謂的蠻目崇拜,找了N久資料,中文的英文的,包括咨詢何登成大神,基本能得出一個結論oracle遇到頁斷裂問題,一樣會掛,重啟不來。但是oracle有一個相對簡單的策略來恢復數據庫到一致狀態,備份+歸檔日志。備份保證了數據頁不發生頁斷裂,加上歸檔日志增量可以恢復到某個時間點。為什麼不做呢?我想一般使用oracle都會使用DataGuard做容災,主庫發生故障時,備庫會承擔起主庫的責任,然後異常主庫通過備份+歸檔日志的方式來恢復,雖然不如doublewrite技術快,但也是能恢復出來的。
其他方式解決頁斷裂
前面討論的都是基於一個假設,異常重啟後,一定會導致頁斷裂,其實在底層設施在一定程度上是可以解決這個問題的,比如文件系統層面,采用ZFS文件系統,ZFS通過日志的方式保證了OS頁面的完整性,從底層防止了頁斷裂問題;在磁盤層面,一般RAID卡都會有帶電緩存,即使OS異常重啟,緩存數據也不會立即丟失,因而也能保證不發生partial write問題。但是我在想,OS的pagesize比DB的pagesize要小,即使能保證OS page不發生頁斷裂,也不能保證DB page 不斷裂,個人感覺不能徹底解決。當然了,如果將DB pagesize設置成和OS pagesize一樣大,就沒問題了。
參考文檔
http://blog.csdn.net/oneyearlater/article/details/7720723
http://www.percona.com/blog/2006/08/04/innodb-double-write/
http://blog.itpub.net/22664653/viewspace-1140915/?page=2
http://www.vmcd.org/2014/09/1748/
二進制格式,write(b)這個就是你說的writeBytes
byte本身就是二進制了
double是64位的二進制,你當他文本讀自然是亂碼
如果你需要寫入文本可是的浮點數,應該把double轉成String類型,再寫入文件