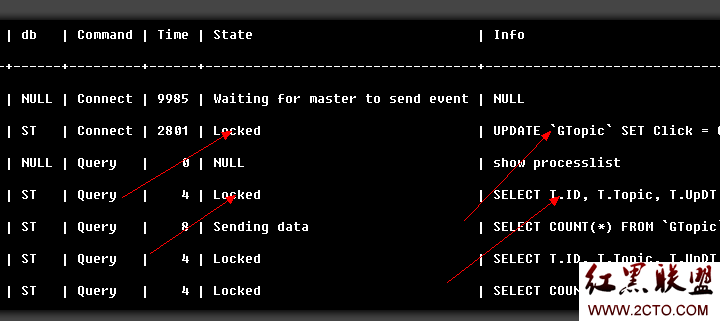
怎樣解決MySQL數據庫主從復制延遲的問題 像Facebook、開心001、人人網、優酷、豆瓣、淘寶等高流量、高並發的網站,單點數據庫很難支撐得住,WEB2.0類型的網站中使用MySQL的居多,要麼用MySQL自帶的MySQL NDB Cluster(MySQL5.0及以上版本支持MySQL NDB Cluster功能),或者用MySQL自帶的分區功能(MySQL5.1及以上版本支持分區功能),我所知道的使用這兩種方案的很少,一般使用主從復制,再加上MySQL Proxy實現負載均衡、讀寫分離等功能,在使用主從復制的基礎上,再使用垂直切分及水平切分;或者不使用主從復制,完全使用垂直切分加上水平切分再加上類似Memcached的系統也可以解決問題。 1.優酷的經驗 數據庫采用水平擴展,主從復制,隨著從數據庫的增多,復制延遲越來越厲害,最終無法忍受。 最終還是采用數據庫的sharding,把一組用戶相關的表和數據放到一組數據庫上。 使用SSD來優化mysql的I/O,性能提升明顯,每塊16G,6塊SSD做RAID。 數據庫的類型選用MYISAM 數據庫的拆分策略,先縱向按照業務或者模塊拆分。對於一些特別大的表,再采用垂直拆分 根據用戶進行分片,盡可能不要跨篇查詢。如果確實要跨片查詢,可以考慮搜索的方案,先索引再搜索。 分布式的數據庫方案太復雜,否掉。 優酷使用的是數據庫分片技術,而拋棄了由於數據量的越來越多導致復制延遲的問題。按照user_id進行分片,這樣必須有一個全局的表來管理用戶與shard的關系,根據user_id可以得到share_id,然後根據share_id去指定的分片查詢指定的數據。 假如此表的表名為sharding_manager,如果網站的用戶數太多,比如千萬級的或甚至更大比如億級的用戶,此時此表也許也會成為一個瓶頸,因為查詢會非常頻繁,所有的動態請求都要讀此表,這時可以用其它的解決方案,比如用Memcached、Tokyo Cabinet、Berkeley DB或其它的性能更高的方案來解決。 具體怎麼定位到哪台db服務器,定位到哪個數據庫,定位到哪個shard(就是userN,msgN,videoN),優酷網的架構文檔中說得不是很仔細,這裡只能猜測一下了。 根據優酷的架構圖,一共有2台db服務器,每台db服務器有2個數據庫,每個數據庫有3個shard,這樣一共是2 * 2 * 3 = 12個shard。 user_id一般是自增型字段,用戶注冊的時候可以自動生成,然後看有幾台db服務器,假如有m台db服務器,則用 user_id % m便可以分配一台db服務器(例如0對應100,1對應101,以此類推,字段mysql_server_ip的值確定),假設每台服務器有n個數據庫,則用user_id % n可以定位到哪個數據庫(字段database_name的值確定),假設每個數據庫有i個shard,則用user_id % i可以定位到哪個shard(字段shard_id的值確定),這樣就可以進行具體的數據庫操作了。 user_id share_id mysql_server_ip database_name 101 2 192.168.1.100 shard_db1 105 0 192.168.1.100 shard_db2 108 0 192.168.1.101 shard_db3(或shard_db1) 110 1 192.168.1.101 shard_db4(或shard_db2) 如上述user_id為101的用戶,連接數據庫服務器192.168.1.100,使用其中的數據庫為shard_db1,使用其中的表系列為user2,msg2,video2 如果上述的m,n,i發生變化,比如網站的用戶不斷增長,需要增加db服務器,此時則需要進行數據庫遷移。 因為表位於不同的數據庫中,所以不同的數據庫中表名可以相同 server1(192.168.1.100) shard_db1 user0 msg0 video0 user1 msg1 video1 ... userN msgN videoN shard_db2 user0 msg0 video0 user1 msg1 video1 ... userN msgN videoN 因為表位於不同的數據庫服務器中,所以不同的數據庫服務器中的數據庫名可以相同 server2(192.168.1.101) shard_db3(這裡也可以用shard_db1) user0 msg0 video0 user1 msg1 video1 ... userN msgN videoN shard_db4(這裡也可以用shard_db2) user0 msg0 video0 user1 msg1 video1 ... userN msgN videoN 2.豆瓣的經驗 由於從主庫到輔庫的復制需要時間 更新主庫後,下一個請求往往就是要讀數據(更新數據後刷新頁面) 從輔庫讀會導致cache裡存放的是舊數據(不知道這個cache具體指的是什麼,如果是Memcached的話,如果更新的數據的量很大,難道把所有更新過的數據都保存在Memcached裡面嗎?) 解決方法:更新數據庫後,在預期可能會馬上用到的情況下,主動刷新緩存 不完美,but it works 豆瓣後來改為雙MySQL Master+Slave說是能解決Replication Delay的問題,不知道是怎麼解決的,具體不太清楚。 3.Facebook的經驗 下面一段內容引用自www.dbanotes.net 大量的 MySQL + Memcached 服務器,布署簡示: California (主 Write/Read)............. Virginia (Read Only) 主數據中心在 California ,遠程中心在 Virginia 。這兩個中心網絡延遲就有 70ms,MySQL 數據復制延遲有的時候會達到 20ms. 如果要讓只讀的信息從 Virginia 端發起,Memcached 的 Cache 數據一致性就是個問題。 1 用戶發起更新操作,更名 "Jason" 到 "Monkey" ; 2 主數據庫寫入 "Monkey",刪除主端 Memcached 中的名字值,但Virginia 端 Memcached 不刪;(這地方在 SQL 解析上作了一點手腳,把更新的操作"示意"給遠程); 3 在 Virginia 有人查看該用戶 Profile ; 4 在 Memcached 中找到鍵值,返回值 "Jason"; 5 復制追上更新 Slave 數據庫用戶名字為 "Monkey",刪除 Virginia Memcached 中的鍵值; 6 在 Virginia 有人查看該用戶 Profile ; 7 Memcache 中沒找到鍵值,所以從 Slave 中讀取,然後得到正確的 "Monkey" 。 Via 從上面3可以看出,也仍然存在數據延遲的問題。同時master中數據庫更新的時候不更新slave中的memcached,只是給slave發個通知,說數據已經改變了。 那是不是可以這樣,當主服務器有數據更新時,立即更新從服務器中的Memcached中的數據,這樣即使有延遲,但延遲的時間應該更短了,基本上可以忽略不計了。 4.Netlog的經驗 對於比較重要且必須實時的數據,比如用戶剛換密碼(密碼寫入 Master),然後用新密碼登錄(從 Slaves 讀取密碼),會造成密碼不一致,導致用戶短時間內登錄出錯。所以在這種需要讀取實時數據的時候最好從 Master 直接讀取,避免 Slaves 數據滯後現象發生。還好,需要讀取實時數據的時候不多,比如用戶更改了郵件地址,就沒必要馬上讀取,所以這種 Master-Slaves 架構在多數情況下還是有效的。