MySQL 5.6 GTID新特征理論。本站提示廣大學習愛好者:(MySQL 5.6 GTID新特征理論)文章只能為提供參考,不一定能成為您想要的結果。以下是MySQL 5.6 GTID新特征理論正文
GTID簡介
甚麼是GTID
GTID(Global Transaction ID)是關於一個已提交事務的編號,而且是一個全局獨一的編號。
GTID現實上是由UUID+TID構成的。個中UUID是一個MySQL實例的獨一標識。TID代表了該實例上曾經提交的事務數目,而且跟著事務提交單調遞增。上面是一個GTID的詳細情勢
3E11FA47-71CA-11E1-9E33-C80AA9429562:23
更具體的引見可以拜見:官方文檔
GTID的感化
那末GTID功效的目標是甚麼呢?詳細歸結重要有以下兩點:
依據GTID可以曉得事務最後是在哪一個實例上提交的GTID的存在便利了Replication的Failover 這裡具體說明下第二點。我們可以看下在MySQL 5.6的GTID湧現之前replication failover的操作進程。假定我們有一個以下圖的情況

此時,Server A的辦事器宕機,須要將營業切換到Server B上。同時,我們又須要將Server C的復制源改成Server B。復制源修正的敕令語法很簡略即CHANGE MASTER TO MASTER_HOST='xxx', MASTER_LOG_FILE='xxx', MASTER_LOG_POS=nnnn。而難點在於,因為統一個事務在每台機械上地點的binlog名字和地位都紛歧樣,那末怎樣找到Server C以後同步停滯點,對應Server B的master_log_file和master_log_pos是甚麼的時刻就成了困難。這也就是為何M-S復制集群須要應用MMM,MHA如許的額定治理對象的一個主要緣由。
這個成績在5.6的GTID湧現後,就顯得異常的簡略。因為統一事務的GTID在一切節點上的值分歧,那末依據Server C以後停滯點的GTID就可以獨一定位到Server B上的GTID。乃至因為MASTER_AUTO_POSITION功效的湧現,我們都不須要曉得GTID的詳細值,直接應用CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION敕令便可以直接完成failover的任務。 So easy不是麼?
基於GTID的主從復制簡介
搭建
搭建應用了mysql_sandbox劇本為基本,先創立了一個一主三從的基於地位復制的情況。然後經由過程設置裝備擺設修正,將全部架構專為基於GTID的復制。
依據MySQL官方文檔給出的GTID搭建建議。須要一次對主從節點做設置裝備擺設修正,偏重啟辦事。如許的操作,明顯在production情況停止進級時是弗成接收的。Facebook,Booking.com,Percona都對此經由過程patch做了優化,做到了更優雅的進級。詳細的操作方法會在今後的博文傍邊引見到。這裡我們就依照官方文檔,停止一次試驗性的進級。
重要的進級步調會有以下幾步:
確保主從同步在master上設置裝備擺設read_only,包管沒有新數據寫入修正master上的my.cnf,偏重啟辦事修正slave上的my.cnf,偏重啟辦事在slave上履行change master to並帶上master_auto_position=1啟用基於GTID的復制因為是試驗情況,read_only和辦事重啟並沒有年夜礙。只需依照官方的GTID搭建建議做就可以順遂完成進級,這裡就不贅述具體進程了。上面羅列了一些在進級進程中輕易碰到的毛病。
罕見毛病
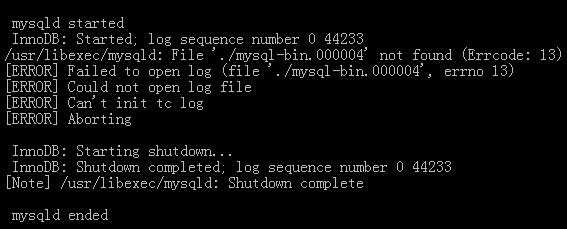
gtid_mode=ON,log_slave_updates,enforce_gtid_consistency這三個參數必定要同時在my.cnf中設置裝備擺設。不然在mysql.err中會湧現以下的報錯
2016-10-08 20:11:08 32147 [ERROR] --gtid-mode=ON or UPGRADE_STEP_1 or UPGRADE_STEP_2 requires --log-bin and --log-slave-updates
2016-10-08 20:13:53 32570 [ERROR] --gtid-mode=ON or UPGRADE_STEP_1 requires --enforce-gtid-consistency
change master to 後的warnings
在依照文檔的操作change master to後,會發明有兩個warnings。實際上是兩個平安性正告,不影響正常的同步(有興致的讀者可以看下關於該warning的詳細引見。warning的詳細內容以下:
slave1 [localhost] {msandbox} ((none)) > stop slave;
Query OK, 0 rows affected (0.03 sec)
slave1 [localhost] {msandbox} ((none)) > change master to master_host='127.0.0.1',master_port =21288,master_user='rsandbox',master_password='rsandbox',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.04 sec)
slave1 [localhost] {msandbox} ((none)) > show warnings;
+-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1759 | Sending passwords in plain text without SSL/TLS is extremely insecure. |
| Note | 1760 | Storing MySQL user name or password information in the master info repository is not secure and is therefore not recommended. Please consider using the USER and PASSWORD connection options for START SLAVE; see the 'START SLAVE Syntax' in the MySQL Manual for more information. |
+-------+------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.00 sec)
試驗一:假如slave所須要事務對應的GTID在master上曾經被purge了
依據show global variables like '%gtid%'的敕令成果我們可以看到,和GTID相干的變量中有一個gtid_purged。從字面意思和官方文檔可以曉得該變量中記載的是本機上曾經履行過,然則曾經被purge binary logs to敕令清算的gtid_set。
本節中我們就要實驗下,假如master上把某些slave還沒有fetch到的gtid event purge後會有甚麼樣的成果。
以下指令在master上履行
master [localhost] {msandbox} (test) > show global variables like '%gtid%';
+---------------------------------+----------------------------------------+
| Variable_name | Value |
+---------------------------------+----------------------------------------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | ON |
| gtid_executed | 24024e52-bd95-11e4-9c6d-926853670d0b:1 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+----------------------------------------+
7 rows in set (0.01 sec)
master [localhost] {msandbox} (test) > flush logs;create table gtid_test2 (ID int) engine=innodb;
Query OK, 0 rows affected (0.04 sec)
Query OK, 0 rows affected (0.02 sec)
master [localhost] {msandbox} (test) > flush logs;create table gtid_test3 (ID int) engine=innodb;
Query OK, 0 rows affected (0.04 sec)
Query OK, 0 rows affected (0.04 sec)
master [localhost] {msandbox} (test) > show master status;
+------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.000005 | 359 | | | 24024e52-bd95-11e4-9c6d-926853670d0b:1-3 |
+------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec)
master [localhost] {msandbox} (test) > purge binary logs to 'mysql-bin.000004';
Query OK, 0 rows affected (0.03 sec)
master [localhost] {msandbox} (test) > show global variables like '%gtid%';
+---------------------------------+------------------------------------------+
| Variable_name | Value |
+---------------------------------+------------------------------------------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | ON |
| gtid_executed | 24024e52-bd95-11e4-9c6d-926853670d0b:1-3 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 24024e52-bd95-11e4-9c6d-926853670d0b:1 |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+------------------------------------------+
7 rows in set (0.00 sec)
在slave2上從新做一次主從,以下敕令在slave2上履行
slave2 [localhost] {msandbox} ((none)) > change master to master_host='127.0.0.1',master_port =21288,master_user='rsandbox',master_password='rsandbox',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.04 sec)
slave2 [localhost] {msandbox} ((none)) > start slave;
Query OK, 0 rows affected (0.01 sec)
slave2 [localhost] {msandbox} ((none)) > show slave status\G
*************************** 1. row ***************************
......
Slave_IO_Running: No
Slave_SQL_Running: Yes
......
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 0
Relay_Log_Space: 151
......
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
......
Auto_Position: 1
1 row in set (0.00 sec)
試驗二:疏忽purged的部門,強行同步
那末現實臨盆運用傍邊,偶然會碰到如許的情形:某個slave從備份恢復後(或許load data infile)後,DBA可以工資包管該slave數據和master分歧;或許即便紛歧致,這些差別也不會招致往後的主從異常(例如:一切master上只要insert沒有update)。如許的條件下,我們又想使slave經由過程replication從master停止數據復制。此時我們就須要跳過master曾經被purge的部門,那末現實該若何操作呢?
我們照樣以試驗一的情形為例:
先確認master上曾經purge的部門。從上面的敕令成果可以曉得master上曾經缺掉24024e52-bd95-11e4-9c6d-926853670d0b:1這一條事務的相干日記
master [localhost] {msandbox} (test) > show global variables like '%gtid%';
+---------------------------------+------------------------------------------+
| Variable_name | Value |
+---------------------------------+------------------------------------------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | ON |
| gtid_executed | 24024e52-bd95-11e4-9c6d-926853670d0b:1-3 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 24024e52-bd95-11e4-9c6d-926853670d0b:1 |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+------------------------------------------+
7 rows in set (0.00 sec)
在slave上經由過程set global gtid_purged='xxxx'的方法,跳過曾經purge的部門
slave2 [localhost] {msandbox} ((none)) > stop slave;
Query OK, 0 rows affected (0.04 sec)
slave2 [localhost] {msandbox} ((none)) > set global gtid_purged = '24024e52-bd95-11e4-9c6d-926853670d0b:1';
Query OK, 0 rows affected (0.05 sec)
slave2 [localhost] {msandbox} ((none)) > start slave;
Query OK, 0 rows affected (0.01 sec)
slave2 [localhost] {msandbox} ((none)) > show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
......
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 359
Relay_Log_File: mysql_sandbox21290-relay-bin.000004
Relay_Log_Pos: 569
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
Exec_Master_Log_Pos: 359
Relay_Log_Space: 873
......
Master_Server_Id: 1
Master_UUID: 24024e52-bd95-11e4-9c6d-926853670d0b
Master_Info_File: /data/mysql/rsandbox_mysql-5_6_23/node2/data/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
......
Retrieved_Gtid_Set: 24024e52-bd95-11e4-9c6d-926853670d0b:2-3
Executed_Gtid_Set: 24024e52-bd95-11e4-9c6d-926853670d0b:1-3
Auto_Position: 1
1 row in set (0.00 sec)
可以看到此時slave曾經可以正常同步,並補齊了24024e52-bd95-11e4-9c6d-926853670d0b:2-3規模的binlog日記。
以上所述是小編給年夜家引見的MySQL 5.6 GTID新特征理論,願望對年夜家有所贊助,假如年夜家有任何疑問請給我留言,小編會實時答復年夜家的。在此也異常感激年夜家對網站的支撐!