MySQL數據庫的高可用計劃總結。本站提示廣大學習愛好者:(MySQL數據庫的高可用計劃總結)文章只能為提供參考,不一定能成為您想要的結果。以下是MySQL數據庫的高可用計劃總結正文
高可用架構關於互聯網辦事根本是標配,不管是運用辦事照樣數據庫辦事都須要做到高可用。固然互聯網辦事號稱7*24小時不連續辦事,但多若干少有一些時刻辦事弗成用,好比某些時刻網頁打不開,百度不克不及搜刮或許沒法發微博,發微信等。普通而言,權衡高可用做到甚麼水平可以經由過程一年內辦事弗成用時光作為參考,要做到3個9的可用性,一年內只能累計有8個小時弗成辦事,而假如要做到5個9的可用性,則一年內只能累計5分鐘辦事中止。所以雖然說每一個公司都說本身的辦事是7*24不連續的,但現實上能做到5個9的寥寥可數,乃至基本做不到,國際互聯網巨子BAT(百度,阿裡巴巴,騰訊)都有由於毛病招致的停服成績。關於一個體系而言,能夠包括許多模塊,好比前端運用,緩存,數據庫,搜刮,新聞隊列等,每一個模塊都須要做到高可用,能力包管全部體系的高可用。關於數據庫辦事而言,高可用能夠更龐雜,對用戶的辦事可用,不只僅是能拜訪,還須要有准確性包管,是以評論辯論數據庫的高可用計劃時,普通會同時斟酌計劃中數據分歧性成績。明天這篇文章重要評論辯論MySQL數據庫的高可用計劃,引見每種計劃的特征和優缺陷,本文是對各類計劃的總結,願望拋磚引玉,和年夜家一路評論辯論。
1.基於同享存儲的計劃SAN
計劃引見:SAN(Storage Area Network)簡略點說就是可以完成收集中分歧辦事器的數據同享,同享存儲可以或許為數據庫辦事器和存儲解耦。應用同享存儲時,辦事器可以或許正常掛載文件體系並操作,假如辦事器掛了,備用辦事器可以掛載雷同的文件體系,履行須要的恢復操作,然後啟動MySQL。同享存儲的架構以下:

長處:
1.可以免存儲外的其它組件惹起的數據喪失。
2.安排簡略,切換邏輯簡略,對運用通明。
3.包管主備數據的強分歧。
限制或缺陷:
1.同享存儲是單點,若同享存儲掛了,則會喪失數據。
2.價錢比價昂貴。
2.基於磁盤復制的計劃 DRBD
計劃引見:DRBD(Distributed Replicated Block Device)是一種磁盤復制技巧,可以取得和SAN相似的後果。DBRD是一個以linux內核模塊方法完成的塊級別同步復制技巧。它經由過程網卡將主辦事器的每一個塊復制到別的一個辦事器塊裝備上,並在主裝備提交塊之前記載上去。DRBD與SAN相似,也是有一個熱備機械,開端供給辦事時會應用和毛病機械雷同的數據,只不外DRBD的數據是復制存儲,不是同享存儲。DRBD的架構圖以下:
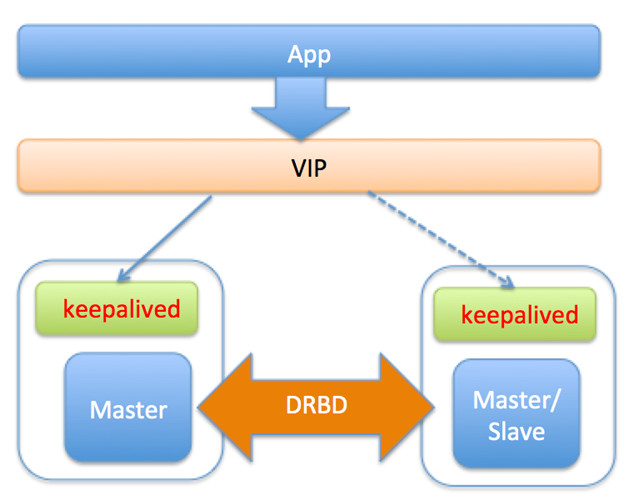
長處:
1.切換對運用通明
2.包管主備數據的強分歧。
限制或缺陷:
1.影響寫入機能,因為每次寫磁盤,本質都須要同步到收集辦事器。
2.普通設置裝備擺設兩節點同步,可擴大性比擬差
3.備庫不克不及供給讀辦事,資本糟蹋
3.基於主從復制(單點寫)計劃
後面評論辯論的兩種計劃分離依附於底層的同享存儲和磁盤復制技巧,來處理MYSQL辦事器單點和磁盤單點的成績。而現實臨盆情況中,高可用更多的是依附MySQL自己的復制,經由過程復制為Master制造一個或多個熱正本,在Master毛病時,將辦事切換到熱正本。上面的幾種計劃都是基於主從復制的計劃,計劃由簡略到龐雜,功效也愈來愈壯大,實行難度由易到難,列位可以依據現實情形選擇適合的計劃。
3.1.keepalived/heartbeat
計劃引見:
keepalived是一個HA軟件,它的感化是檢測辦事器(web辦事器,DB辦事器等)狀況,檢討道理是模仿收集要求檢測,檢測方法包含HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHECK等。關於DB辦事器而言,重要就是IP,端口(TCP_CHECK),但這能夠不敷(好比DB辦事器ReadOnly),是以keepalived也支撐自界說劇本。keepalived經由過程監聽來確認辦事器的狀況,假如發明辦事器毛病,則將毛病辦事器從體系中剔除。keepalived的高可用架構以下圖,分離在主、從辦事器上裝置keepalived的軟件,並設置裝備擺設異樣的VIP,VIP層將真實IP屏障,運用辦事器經由過程拜訪VIP來獲得DB辦事。當Master毛病時,keepalived感知,並將Slave晉升主,持續供給辦事對運用層通明。

長處:
1. 裝置設置裝備擺設簡略
2. Master毛病時,Slave疾速切換供給辦事,而且對運用通明。
限制或缺陷:
1.須要主備的IP在統一個網段。
2.供給的檢測機制比擬弱,須要自界說劇本來肯定Master能否能供給辦事,好比更新心跳表等。
3.沒法包管數據的分歧性,原生的MySQL采取異步復制,若Master毛病,Slave數據能夠不是最新,招致數據喪失,是以切換時要斟酌Slave延遲的身分,肯定切換戰略。關於強分歧需求的場景,可以開啟(semi-sync)半同步,來削減數據喪失。
4.keepalived軟件本身的HA沒法包管。
3.2.MHA
計劃引見:MHA(Master High Availability)是一名日本MySQL年夜牛用Perl寫的一套MySQL毛病切換計劃,來包管數據庫的高可用,MHA經由過程從宕機的主辦事器上保留二進制日記來停止回補,能在最年夜水平上削減數據喪失。MHA由兩部門構成:MHA Manager(治理節點)和MHA Node(數據節點)。MHA可以零丁安排在一台自力的機械上治理多個master-slave集群,MHA Node運轉在每台MySQL辦事器上,重要感化是切換時處置二進制日記,確保切換盡可能少丟數據。MHA Manager會准時探測集群中的master節點,當master湧現毛病時,它可以主動將最新數據的slave晉升為新的master,然後將一切其他的slave從新指向新的master,全部毛病轉移進程對運用法式完整通明。MHA的架構以下:
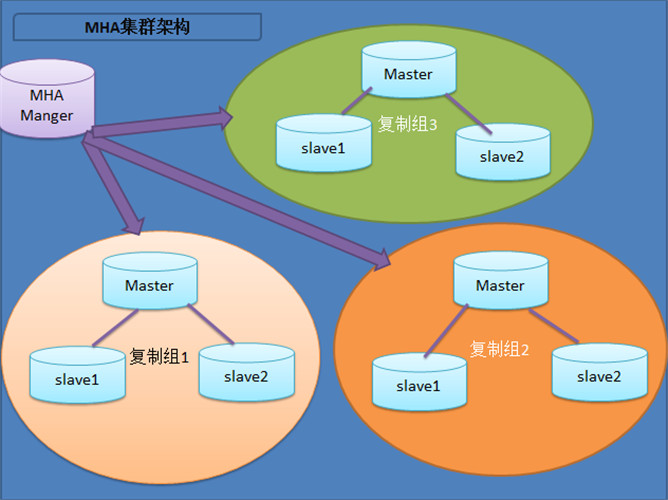
MHA failover進程:
a.檢測到 Master 異常,停止一系列斷定,最初肯定 Master 宕失落;
b.檢討設置裝備擺設信息,枚舉出以後架構中各節點的狀況;
c.依據界說的劇本處置毛病的 Master,VIP漂移或許關失落mysqld辦事;
d.一切 Slave 比擬位點,選出位點最新的 Slave,再與 Master 比擬並取得 binlog 的差別,copy 到治理節點;
e.從候選節點當選擇新的 Master,新的 Master 會和位點最新的 Slave 停止比擬並取得 relaylog 的差別;
f.治理節點把 binlog 的差別 copy 到新 Master,新 Master 運用 binlog 差別和 relaylog 差別,最初取得位點信息,並接收寫要求(read_only=0);
g.其他 Slave 與位點最新的 Slave 停止比擬,並取得 relaylog 的差別,copy 到對應的 Slave;
h.治理節點把 binlog 的差別 copy 到每一個 Slave,比擬 Exec_Master_Log_Pos 和 Read_Master_Log_Pos,取得差別日記;
i.每一個Slave運用一切差別日記,然後 reset slave 偏重新指向新 Master;
j.新 Master reset slave 來消除 Slave 信息。
長處:
1. 代碼開源,便利聯合營業場景二次開辟
2. 毛病切換時,可以修復多個Slave之間的差別日記,終究使一切Slave堅持數據分歧,然後從當選擇一個充任新的Master,並將其它Slave指向它。
3. 可以靈巧選擇VIP計劃或許全局目次數據庫計劃(更改Master IP映照)來停止切換。
缺陷:
1.沒法包管強分歧,由於從毛病Master上保留二進制日記其實不老是可行,好比Master磁盤壞了,或許SSH認證掉敗等。
2.只支撐一主多從架構,請求一個復制集群中必需起碼有三台數據庫辦事器,一主二從,即一台充任master,一台充任備用master,別的一台充任從庫。
3.采取全局目次數據庫計劃切換時,須要運用感知變更,是以對運用不通明,是以要堅持切換對運用通明,仍然依附於VIP。
4.不實用於年夜范圍集群安排,設置裝備擺設比擬龐雜。
5.MHA治理節點自己的HA沒法包管。
3.3.基於zookeeper的高可用
計劃引見:
早年面的評論辯論可以看到,不管是keepalived計劃照樣MHA計劃,都沒法處理HA軟件本身的高可用成績,由於HA自己是單點。那末假如將HA也引入多個正本呢?那末又帶來新的成績,1.HA軟件之間若何包管強同步。2.若何確保不會有多個HA同時停止切換舉措。這兩個成績本質都散布式體系分歧性成績,為此,可認為HA軟件引入相似Paxos,Raft如許的散布式分歧性協定,包管HA軟件的可用性。zooKeeper是一個典范的宣布/定閱形式的散布式數據治理與調和框架,經由過程zookeeper中豐碩的數據節點類型停止穿插應用,合營watcher事宜告訴機制,可以便利地構建一系列散布式運用觸及的焦點功效,好比:數據宣布/定閱,負載平衡,散布式調和/告訴,集群治理,Master選舉,散布式鎖和散布式隊列等。zookeeper是一個很年夜話題,年夜家可以谷歌去找更多的信息,我這裡重要評論辯論zookeeper若何處理HA本身可用性成績。架構圖以下:

圖中每一個MySQL節點下面安排了一個HA client,用於及時向zookeeper報告請示當地節點的心跳狀況,好比主庫crash,經由過程修正zookeeper(以下簡稱zk)上的節點信息,來告訴HA。HA節點在zk上注冊監聽事宜,當zk節點產生變更時會主動讓HA感知,HA節點可以安排一個或多個,重要用於容災。HA節點之間經由過程zookeeper辦事來完成數據的分歧性,經由過程散布式鎖包管多個HA節點不會同時對一個主從節點停止切換。HA自己是無狀況的,一切MySQL節點狀況信息全體保留在zookeeper辦事器上,切換時,HA會對MySQL節點停止復檢,然後切換。我們看看引入zookeeper後的切換流程:
a.HA client 檢測到 Master 異常,停止一系列斷定,最初肯定 Master 宕失落;
b.HA client 刪除 Master在zk上的節點信息;
c.因為監聽機制,HA會感知到有節點被刪除;
d.HA對MySQL節點停止復檢,好比樹立銜接,更新心跳表等
e.確認異常後,則停止切換。
我們再看看這類架構下,能否能包管HA本身的高可用
(1).假如HA-client自己掛了,MySQL節點正常?
HA-Client治理的MySQL節點沒法與zookeeper堅持心跳,zk辦事將節點刪除,HA會感知到這類變更,預備測驗考試一次切換,切換前,會停止復檢,復檢時發明MySQL節點是OK的,則不會切換。
(2).MySQL節點與zookeeper的收集斷了,那末表示若何?
因為HA-Client與節點在統一台主機,是以HA-client沒法再准時向zk報告請示心跳,zk會將對應的MySQL節點信息刪除,HA測驗考試復檢,仍然掉敗,則停止切換。
(3).HA掛了,表示若何?
因為HA無狀況,而且有多個正本,是以一個HA掛了,不會對全部體系形成影響。
長處:
1. 包管了全部體系的高可用
2. 主從的強分歧依附於MySQL自己,好比半同步,或許核心對象的回補戰略,相似MHA。
3. 擴大性異常好,可以治理年夜范圍集群。
缺陷:
1.引入zk,全部體系變得龐雜。
4.基於Cluster(多點寫)計劃
第3節評論辯論的計劃根本是今朝業內應用的主流計劃,這類計劃的特色是,單點寫。固然我們可以借助中央件停止分片(sharding),然則關於統一份數據,仍然只許可一個節點寫,從這個角度來講,下面的計劃是偽散布式。上面評論辯論的兩種計劃算是真正散布式,統一個數據實際上可以在多個節點寫入,相似於Oracle的RAC,EMC的GreenPlum這類散布式數據庫。在MySQL范疇,重要供給了2種處理計劃:基於Galera的PXC和NDB Cluster。MySQL Cluster完成基於NDB存儲引擎,應用許多局限性,而PXC是基於innodb引擎,固然也有局限性,但因為今朝innodb應用異常普遍,所以有必定的參考價值。今朝據我所知,去哪兒公司在他們的臨盆情況中應用了PXC計劃。PXC(Percona XtraDB Cluster)的架構圖以下:

長處:
1.准同步復制
2.多個可同時讀寫節點,可完成寫擴大,較分片計劃更進一步
3.主動節點治理
4.數據嚴厲分歧
5.辦事高可用
缺陷:
1.只支撐innodb引擎
2.一切表都要有主鍵
3.因為寫要同步到其它節點,存在寫擴展成績
4.異常依附於收集穩固性,不實用於遠間隔同步
5.基於中央件proxy的計劃
精確地來講,中央件與高可用沒有特殊年夜的關系,由於切換都是在數據庫層完成,但引入中央層後,使得對運用更通明。在引入中央件之前,一切的計劃,根本都依附於VIP漂移機制,或許不依附於VIP又不克不及包管對運用通明。經由過程參加中央件層,可以同時完成對運用通明和高可用。另外中央層還可以做sharding,便利寫擴大。proxy的計劃許多,好比mysql自帶的mysql-proxy和fabric,阿裡巴巴的cobar和tddl等。我們以fabric為例,其架構圖以下:
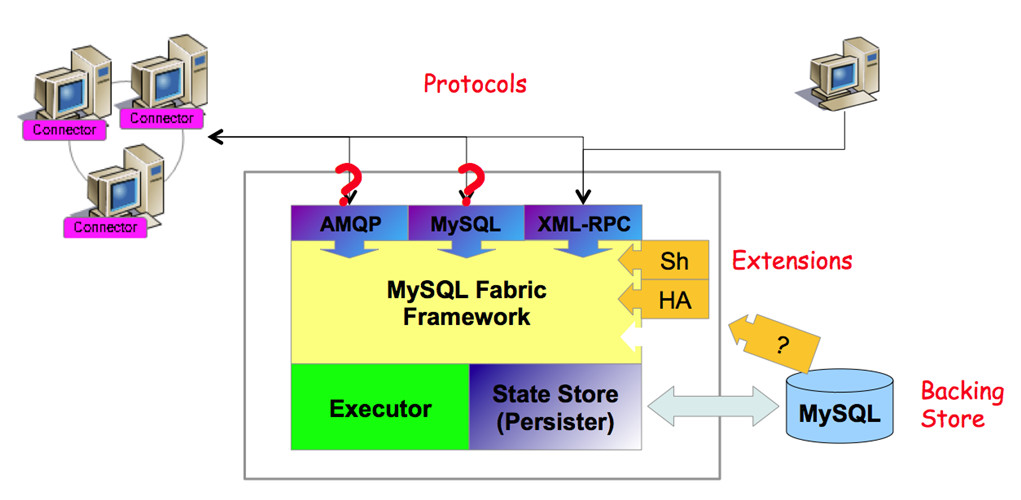
運用都要求 Fabric 銜接器,然後經由過程應用 XML-RPC 協定拜訪 Fabric 節點, Fabric 節點依附於備用存儲 (backing store),外面存儲全部 HA 集群的元數據信息。銜接器讀取 backing store 的信息,然後將元數據緩存到 cache,如許做的利益就是削減每次樹立銜接時與治理節點交互所帶來的開支。Fabric 節點可治理多個 HA Group,每一個 HA Group 裡有一個 Primary 和多個 Secondary(slave),當 Primary 異常的時刻會從 Secondary 當選出最適合的節點晉升為新 Primary,其他 Secondary 都將從新指向新 Primary。這些都是主動操作,對營業是無感知的,HA 切換以後還須要告訴銜接器更新的元數據信息。
長處:
1.切換對運用通明
2.可擴大性強,便利分片擴大
3.可以跨機房安排切換
缺陷:
1.是一個比擬新的組件,沒有許多現實運用場景
2.沒有處理強分歧成績,主備強分歧性依附於MySQL本身(半同步),和回滾回補機制。
總結
以上引見了今朝MySQL幾種典范的高可用架構,包含基於同享存儲計劃,基於磁盤復制計劃和基於主從復制的計劃。關於主從復制計劃,分離引見了keepalived,MHA和引入zookeeper的計劃。關於每種計劃,都從連續可用,數據強分歧性,和切換對運用的通明性停止解釋。小我認為基於MySQL復制的計劃是主流,也異常成熟,引入中央件和引入zookeeper固然能將體系的可用性做地更好,可支持的范圍更年夜,但也對研發和運維也提出了更高的請求。是以,在選擇計劃時,要依據營業場景和運維范圍做決定。