詳解MySQL機能優化(一)。本站提示廣大學習愛好者:(詳解MySQL機能優化(一))文章只能為提供參考,不一定能成為您想要的結果。以下是詳解MySQL機能優化(一)正文
1、MySQL的重要實用場景
1、Web網站體系
2、日記記載體系
3、數據倉庫體系
4、嵌入式體系
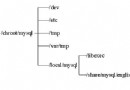
2、MySQL架構圖:

3、MySQL存儲引擎概述
1)MyISAM存儲引擎
MyISAM存儲引擎的表在數據庫中,每個表都被寄存為三個以表名定名的物理文件。起首確定會有任何存儲引擎都弗成缺乏的寄存表構造界說信息的.frm文件,別的還有.MYD和.MYI文件,分離寄存了表的數據(.MYD)和索引數據(.MYI)。每一個表都有且唯一如許三個文件做為MyISAM存儲類型的表的存儲,也就是說不論這個表有若干個索引,都是寄存在統一個.MYI文件中。
MyISAM支撐以下三品種型的索引:
1、B-Tree索引
B-Tree索引,望文生義,就是一切的索引節點都依照balancetree的數據構造來存儲,一切的索引數據節點都在葉節點。
2、R-Tree索引
R-Tree索引的存儲方法和b-tree索引有一些差別,重要設計用於為存儲空間和多維數據的字段做索引,所以今朝的MySQL版原來說,也僅支撐geometry類型的字段作索引。
3、Full-text索引
Full-text索引就是我們長說的全文索引,他的存儲構造也是b-tree。重要是為懂得決在我們須要用like查詢的低效成績。
2)Innodb 存儲引擎
1、支撐事務裝置
2、數據多版本讀取
3、鎖定機制的改良
4、完成外鍵
3)NDBCluster存儲引擎
NDB存儲引擎也叫NDBCluster存儲引擎,重要用於MySQLCluster散布式集群情況,Cluster是MySQL從5.0版本才開端供給的新功效。
4)Merge存儲引擎
MERGE存儲引擎,在MySQL用戶手冊中也提到了,也被年夜家熟悉為MRG_MyISAM引擎。Why?由於MERGE存儲引擎可以簡略的懂得為其功效就是完成了對構造雷同的MyISAM表,經由過程一些特別的包裝對外供給一個單一的拜訪進口,以到達減小運用的龐雜度的目標。要創立MERGE表,不只僅基表的構造要完整分歧,包含字段的次序,基表的索引也必需完整分歧。
5)Memory存儲引擎
Memory存儲引擎,經由過程名字就很輕易讓人曉得,他是一個將數據存儲在內存中的存儲引擎。Memory存儲引擎不會將任何數據寄存到磁盤上,僅僅寄存了一個表構造相干信息的.frm文件在磁盤下面。所以一旦MySQLCrash或許主機Crash以後,Memory的表就只剩下一個構造了。Memory表支撐索引,而且同時支撐Hash和B-Tree兩種格局的索引。因為是寄存在內存中,所以Memory都是依照定長的空間來存儲數據的,並且不支撐BLOB和TEXT類型的字段。Memory存儲引擎完成頁級鎖定。
6)BDB存儲引擎
BDB存儲引擎全稱為BerkeleyDB存儲引擎,和Innodb一樣,也不是MySQL本身開辟完成的一個存儲引擎,而是由SleepycatSoftware所供給,固然,也是開源存儲引擎,異樣支撐事務平安。
7)FEDERATED存儲引擎
FEDERATED存儲引擎所完成的功效,和Oracle的DBLINK根本類似,重要用來供給對長途MySQL辦事器下面的數據的拜訪接口。假如我們應用源碼編譯來裝置MySQL,那末必需手工指定啟用FEDERATED存儲引擎才行,由於MySQL默許是不升引該存儲引擎的。
8)ARCHIVE存儲引擎
ARCHIVE存儲引擎重要用於經由過程較小的存儲空間來寄存過時的很少拜訪的汗青數據。ARCHIVE表不支撐索引,經由過程一個.frm的構造界說文件,一個.ARZ的數據緊縮文件還有一個.ARM的meta信息文件。因為其所寄存的數據的特別性,ARCHIVE表不支撐刪除,修正操
作,僅支撐拔出和查詢操作。鎖定機制為行級鎖定。
9)BLACKHOLE存儲引擎
BLACKHOLE存儲引擎是一個異常成心思的存儲引擎,功效恰如其名,就是一個“黑洞”。就像我們unix體系上面的“/dev/null”裝備一樣,不論我們寫入任何信息,都是有去無回。
10)CSV存儲引擎
CSV存儲引擎現實上操作的就是一個尺度的CSV文件,他不支撐索引。起重要用處就是年夜家有些時刻能夠會須要經由過程數據庫中的數據導出成一份報表文件,而CSV文件是許多軟件都支撐的一種較為尺度的格局,所以我們可以經由過程先在數據庫中樹立一張CVS表,然後將生成的報表信息拔出到該表,便可獲得一份CSV報表文件了。
4、影響MySQLServer機能的相干身分
1貿易需求對機能的影響
典范需求:一個服裝論壇t.vhao.net帖子總量的統計,請求:及時更新。
2體系架構及完成對機能的影響
以下幾類數據都是不合適在數據庫中寄存的:
二進制多媒體數據
流水隊列數據
超年夜文本數據
經由過程Cache技巧來進步體系機能:
體系各類設置裝備擺設及規矩數據;
活潑用戶的根本信息數據;
活潑用戶的特性化定制信息數據;
准及時的統計信息數據;
其他一些拜訪頻仍但變革較少的數據;
3 Query語句對體系機能的影響
需求:掏出某個group(假定id為1)下的用戶編號(id),用戶昵稱(nick_name),並依照參加組的時光(user_group.gmt_create)來停止倒序分列,掏出前20個。
處理計劃一:
SELECT id,nick_name FROM user,user_group WHERE user_group.group_id=1 and user_group.user_id=user.id ORDER BY user_group.gmt_create desc limit 100,20;
處理計劃二:
SELECT user.id,user.nick_name FROM( SELECT user_id FROM user_group WHERE user_group.group_id=1 ORDER BY gmt_create desc limit 100,20)t,user WHERE t.user_id=user.id;
經由過程比擬兩個處理計劃的履行籌劃,我們可以看到第一中處理計劃中須要和user表介入Join的記載數MySQL經由過程統計數據預算出來是31156,也就是經由過程user_group表前往的一切知足group_id=1的記載數(體系中的現實數據是20000)。而第二種處理計劃的履行籌劃中,user表介入Join的數據就只要20條,二者相差很年夜,我們以為第二中處理計劃應當顯著優於第一種處理計劃。
4 Schema設計對體系的機能影響
盡可能削減對數據庫拜訪的要求。
盡可能削減無用數據的查詢要求。
5硬件情況對體系機能的影響
1、典范OLTP運用體系
關於各類數據庫體系情況中年夜家最多見的OLTP體系,其特色是並發量年夜,全體數據量比擬多,但每次拜訪的數據比擬少,且拜訪的數據比擬團圓,活潑數據占整體數據的比例不是太年夜。關於這類體系的數據庫現實上是最難保護,最難以優化的,對主機全體機能請求也是最高的。由於不只拜訪量很高,數據量也不小。
針對下面的這些特色和剖析,我們可以對OLTP的得出一個年夜致的偏向。
固然體系整體數據量較年夜,然則體系活潑數據在數據總量中所占的比例不年夜,那末我們可以經由過程擴展內存容量來盡量多的將活潑數據cache到內存中;
固然IO拜訪異常頻仍,然則每次拜訪的數據量較少且很團圓,那末我們對磁盤存儲的請求是IOPS表示要很好,吞吐量是主要身分;
並發量很高,CPU每秒所要處置的要求天然也就許多,所以CPU處置才能須要比擬微弱;
固然與客戶真個每次交互的數據量其實不是特殊年夜,然則收集交互異常頻仍,所以主機與客戶端交互的收集裝備對流量才能也請求不克不及太弱。
2、典范OLAP運用體系
用於數據剖析的OLAP體系的重要特色就是數據量異常年夜,並發拜訪不多,但每次拜訪所須要檢索的數據量都比擬多,並且數據拜訪絕對較為集中,沒有太顯著的活潑數據概念。
基於OLAP體系的各類特色和響應的剖析,針對OLAP體系硬件優化的年夜致戰略以下:
數據量異常年夜,所以磁盤存儲體系的單元容量須要盡可能年夜一些;
單次拜訪數據量較年夜,並且拜訪數據比擬集中,那末對IO體系的機能請求是須要有盡量年夜的每秒IO吞吐量,所以應當選用每秒吞吐量盡量年夜的磁盤;
固然IO機能請求也比擬高,然則並發要求較少,所以CPU處置才能較難成為機能瓶頸,所以CPU處置才能沒有太刻薄的請求;
固然每次要求的拜訪量很年夜,然則履行進程中的數據年夜都不會前往給客戶端,終究前往給客戶真個數據量都較小,所以和客戶端交互的收集裝備請求其實不是太高;
另外,因為OLAP體系因為其每次運算進程較長,可以很好的並行化,所以普通的OLAP體系都是由多台主機組成的一個集群,而集群中主機與主機之間的數據交互量普通來講都長短常年夜的,所以在集群中主機之間的收集裝備請求很高。
3、除以上兩個典范運用以外,還有一類比擬特別的運用體系,他們的數據量不是特殊年夜,然則拜訪要求及其頻仍,並且年夜部門是讀要求。能夠每秒須要供給上萬乃至幾萬次要求,每次要求都異常簡略,能夠年夜部門都只要一條或許幾條比擬小的記載前往,就好比基於數據庫的DNS辦事就是如許類型的辦事。
固然數據量小,然則拜訪極端頻仍,所以可以經由過程較年夜的內存來cache住年夜部門的數據,這可以或許包管異常高的射中率,磁盤IO量比擬小,所以磁盤也不須要特殊高機能的;
並發要求異常頻仍,比須要較強的CPU處置才能能力處置;
固然運用與數據庫交互量異常年夜,然則每次交互數據較少,整體流量固然也會較年夜,然則普通來講通俗的千兆網卡曾經足夠了。
5、MySQL 鎖定機制簡介
行級鎖定(row-level)
表級鎖定(table-level)
頁級鎖定(page-level)
在MySQL數據庫中,應用表級鎖定的重要是MyISAM,Memory,CSV等一些非事務性存儲引擎,而應用行級鎖定的重要是Innodb存儲引擎和NDBCluster存儲引擎,頁級鎖定重要是BerkeleyDB存儲引擎的鎖定方法。
6、MySQL Query的優化
Query語句的優化思緒和准繩重要提如今以下幾個方面:
1. 優化更須要優化的Query;
2. 定位優化對象的機能瓶頸;
3. 明白的優化目的;
4. 從Explain動手;
5. 多應用profile
6. 永久用小成果集驅動年夜的成果集;
7. 盡量在索引中完成排序;
8. 只掏出本身須要的Columns;
9. 僅僅應用最有用的過濾前提;
10.盡量防止龐雜的Join和子查詢;
公道設計並應用索引
1)B-Tree索引
普通來講,MySQL中的B-Tree索引的物理文件年夜多都是以BalanceTree的構造來存儲的,也就是一切現實須要的數據都寄存於Tree的LeafNode,並且就任何一個LeafNode的最短途徑的長度都是完整雷同的,所以我們年夜家都稱之為B-Tree索引固然,能夠各類數據庫(或MySQL的各類存儲引擎)在寄存本身的B-Tree索引的時刻會對存儲構造稍作改革。如Innodb存儲引擎的B-Tree索引現實應用的存儲構造現實上是B+Tree,也就是在B-Tree數據構造的基本上做了很小的改革,在每個LeafNode下面出了寄存索引鍵的相干信息以外,還存儲了指向與該LeafNode相鄰的後一個LeafNode的指針信息,這重要是為了加速檢索多個相鄰LeafNode的效力斟酌。
2)Hash索引
Hash索引在MySQL中應用的其實不是許多,今朝重要是Memory存儲引擎應用,並且在Memory存儲引擎中將Hash索引作為默許的索引類型。所謂Hash索引,現實上就是經由過程必定的Hash算法,將須要索引的鍵值停止Hash運算,然後將獲得的Hash值存入一個Hash表中。然後每次須要檢索的時刻,都邑將檢索前提停止雷同算法的Hash運算,然後再和Hash表中的Hash值停止比擬並得出響應的信息。
Hash索引僅僅只能知足“=”,“IN”和“<=>”查詢,不克不及應用規模查詢;
Hash索引沒法被應用來防止數據的排序操作;
Hash索引不克不及應用部門索引鍵查詢;
Hash索引在任什麼時候候都不克不及防止表掃面;
Hash索引碰到年夜量Hash值相等的情形後機能其實不必定就會比B-Tree索引高;
3)Full-text索引
Full-text索引也就是我們常說的全文索引,今朝在MySQL中唯一MyISAM存儲引擎支撐,並且也其實不是一切的數據類型都支撐全文索引。今朝來講,唯一CHAR,VARCHAR和TEXT這三種數據類型的列可以建Full-text索引。
索引可以或許極年夜的進步數據檢索效力,也可以或許改良排序分組操作的機能,然則我們不克不及疏忽的一個成績就是索引是完整自力於基本數據以外的一部門數據,更新數據會帶來的IO量和調劑索引而至的盤算量的資本消費。
能否須要創立索引,幾點准繩:較頻仍的作為查詢前提的字段應當創立索引;獨一性太差的字段不合適零丁創立索引,即便頻仍作為查詢前提;更新異常頻仍的字段不合適創立索引;
不會湧現在WHERE子句中的字段不應創立索引;
Join語句的優化
盡量削減Join語句中的NestedLoop的輪回總次數;“永久用小成果集驅動年夜的成果集”。
優先優化NestedLoop的內層輪回;
包管Join語句中被驅動表上Join前提字段曾經被索引;
當沒法包管被驅動表的Join前提字段被索引且內存資本充分的條件下,不要太吝惜JoinBuffer的設置;
ORDER BY,GROUP BY和DISTINCT優化
1)ORDER BY的完成與優化
優化Query語句中的ORDER BY的時刻,盡量應用已有的索引來防止現實的排序盤算,可以很年夜幅度的晉升ORDER BY操作的機能。
優化排序:
1.加年夜max_length_for_sort_data參數的設置;
2.去失落不用要的前往字段;
3.增年夜sort_buffer_size參數設置;
2)GROUP BY的完成與優化
因為GROUP BY現實上也異樣須要停止排序操作,並且與ORDER BY比擬,GROUP BY重要只是多了排序以後的分組操作。固然,假如在分組的時刻還應用了其他的一些聚合函數,那末還須要一些聚合函數的盤算。所以,在GROUP BY的完成進程中,與ORDER BY一樣也能夠應用到索引。
3)DISTINCT的完成與優化
DISTINCT現實上和GROUP BY的操作異常類似,只不外是在GROUP BY以後的每組中只掏出一筆記錄罷了。所以,DISTINCT的完成和GROUP BY的完成也根本差不多,沒有太年夜的差別。異樣可以經由過程松懈索引掃描或許是緊湊索引掃描來完成,固然,在沒法僅僅應用索引即能完成DISTINCT的時刻,MySQL只能經由過程暫時表來完成。然則,和GROUP BY有一點差異的是,DISTINCT其實不須要停止排序。也就是說,在僅僅只是DISTINCT操作的Query假如沒法僅僅應用索引完成操作的時刻,MySQL會應用暫時表來做一次數據的“緩存”,然則不會對暫時表中的數據停止filesort操作。
下篇地址:http://www.jb51.net/article/70530.htm
以上就是本文的全體內容,願望對年夜家的進修有所贊助。