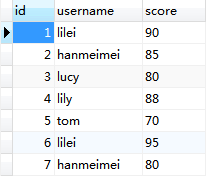
MySQL存儲毫秒數據的辦法。本站提示廣大學習愛好者:(MySQL存儲毫秒數據的辦法)文章只能為提供參考,不一定能成為您想要的結果。以下是MySQL存儲毫秒數據的辦法正文
在我看來,python社辨別為了三個派別,分離是python 2.x組織,3.x組織和PyPy組織。這個分類根本上可以歸根於類庫的兼容性和速度。這篇文章將聚焦於一些通用代碼的優化技能和編譯成C後機能的明顯晉升,固然我也會給出三年夜重要python派別運轉時光。我的目標不是為了證實一個比另外一個強,只是為了讓你曉得若何在分歧的情況下應用這些詳細例子作比擬。
應用生成器
一個廣泛被疏忽的內存優化是生成器的應用。生成器讓我們創立一個函數一次只前往一筆記錄,而不是一次前往一切的記載,假如你正在應用python2.x,這就是你為啥應用xrange替換range或許應用ifilter替換filter的緣由。一個很好地例子就是創立一個很年夜的列表並將它們拼合在一路。
import timeit
import random
def generate(num):
while num:
yield random.randrange(10)
num -= 1
def create_list(num):
numbers = []
while num:
numbers.append(random.randrange(10))
num -= 1
return numbers
print(timeit.timeit("sum(generate(999))", setup="from __main__ import generate", number=1000))
>>> 0.88098192215 #Python 2.7
>>> 1.416813850402832 #Python 3.2
print(timeit.timeit("sum(create_list(999))", setup="from __main__ import create_list", number=1000))
>>> 0.924163103104 #Python 2.7
>>> 1.5026731491088867 #Python 3.2
這不只是快了一點,也防止了你在內存中存儲全體的列表!
Ctypes的引見
關於症結性的機能代碼python自己也供給給我們一個API來挪用C辦法,重要經由過程 ctypes來完成,你可以不寫任何C代碼來應用ctypes。默許情形下python供給了預編譯的尺度c庫,我們再回到生成器的例子,看看應用ctypes完成消費若干時光。
import timeit
from ctypes import cdll
def generate_c(num):
#Load standard C library
libc = cdll.LoadLibrary("libc.so.6") #Linux
#libc = cdll.msvcrt #Windows
while num:
yield libc.rand() % 10
num -= 1
print(timeit.timeit("sum(generate_c(999))", setup="from __main__ import generate_c", number=1000))
>>> 0.434374809265 #Python 2.7
>>> 0.7084300518035889 #Python 3.2
僅僅換成了c的隨機函數,運轉時光減了年夜半!如今假如我告知你我們還能做得更好,你信嗎?
Cython的引見
Cython 是python的一個超集,許可我們挪用C函數和聲明變量來進步機能。測驗考試應用之前我們須要先裝置Cython.
sudo pip install cython
Cython 實質上是另外一個不再開辟的相似類庫Pyrex的分支,它將我們的類Python代碼編譯成C庫,我們可以在一個python文件中挪用。關於你的python文件應用.pyx後綴替換.py後綴,讓我們看一下應用Cython若何來運轉我們的生成器代碼。
#cython_generator.pyx import random def generate(num): while num: yield random.randrange(10) num -= 1
我們須要創立個setup.py以便我們能獲得到Cython來編譯我們的函數。
from distutils.core import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
setup(
cmdclass = {'build_ext': build_ext},
ext_modules = [Extension("generator", ["cython_generator.pyx"])]
)
編譯應用:
python setup.py build_ext --inplace你應當可以看到兩個文件cython_generator.c 文件 和 generator.so文件,我們應用上面辦法測試我們的法式:
import timeit
print(timeit.timeit("sum(generator.generate(999))", setup="import generator", number=1000))
>>> 0.835658073425
還不賴,讓我們看看能否還有可以改良的處所。我們可以先聲明“num”為整形,接著我們可以導入尺度的C庫來擔任我們的隨機函數。
#cython_generator.pyx cdef extern from "stdlib.h": int c_libc_rand "rand"() def generate(int num): while num: yield c_libc_rand() % 10 num -= 1
假如我們再次編譯運轉我們會看到這一串驚人的數字。
>>> 0.033586025238
僅僅的幾個轉變帶來了不賴的成果。但是,有時這個轉變很有趣,是以讓我們來看看若何應用規矩的python來完成吧。
PyPy的引見
PyPy 是一個Python2.7.3的即時編譯器,淺顯地說這意味著讓你的代碼運轉的更快。Quora在臨盆情況中應用了PyPy。PyPy在它們的下載頁面有一些裝置解釋,然則假如你應用的Ubuntu體系,你可以經由過程apt-get來裝置。它的運轉方法是立刻可用的,是以沒有猖狂的bash或許運轉劇本,只需下載然後運轉便可。讓我們看看我們原始的生成器代碼在PyPy下的機能若何。
import timeit
import random
def generate(num):
while num:
yield random.randrange(10)
num -= 1
def create_list(num):
numbers = []
while num:
numbers.append(random.randrange(10))
num -= 1
return numbers
print(timeit.timeit("sum(generate(999))", setup="from __main__ import generate", number=1000))
>>> 0.115154981613 #PyPy 1.9
>>> 0.118431091309 #PyPy 2.0b1
print(timeit.timeit("sum(create_list(999))", setup="from __main__ import create_list", number=1000))
>>> 0.140175104141 #PyPy 1.9
>>> 0.140514850616 #PyPy 2.0b1
哇!沒有修正一行代碼運轉速度是純python完成的8倍。
進一步測試為何還要進一步研討?PyPy是冠軍!其實不全對。固然年夜多半法式可以運轉在PyPy上,然則照樣有一些庫沒有被完整支撐。並且,為你的項目寫C的擴大比擬換一個編譯器加倍輕易。讓我們加倍深刻一些,看看ctypes若何讓我們應用C來寫庫。我們來測試一下合並排序和盤算斐波那契數列的速度。上面是我們要用到的C代碼(functions.c):
/* functions.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/* http://rosettacode.org/wiki/Sorting_algorithms/Merge_sort#C */
inline void
merge (int *left, int l_len, int *right, int r_len, int *out)
{
int i, j, k;
for (i = j = k = 0; i < l_len && j < r_len;)
out[k++] = left[i] < right[j] ? left[i++] : right[j++];
while (i < l_len)
out[k++] = left[i++];
while (j < r_len)
out[k++] = right[j++];
}
/* inner recursion of merge sort */
void
recur (int *buf, int *tmp, int len)
{
int l = len / 2;
if (len <= 1)
return;
/* note that buf and tmp are swapped */
recur (tmp, buf, l);
recur (tmp + l, buf + l, len - l);
merge (tmp, l, tmp + l, len - l, buf);
}
/* preparation work before recursion */
void
merge_sort (int *buf, int len)
{
/* call alloc, copy and free only once */
int *tmp = malloc (sizeof (int) * len);
memcpy (tmp, buf, sizeof (int) * len);
recur (buf, tmp, len);
free (tmp);
}
int
fibRec (int n)
{
if (n < 2)
return n;
else
return fibRec (n - 1) + fibRec (n - 2);
}
在Linux平台,我們可以用上面的辦法把它編譯成一個同享庫:
gcc -Wall -fPIC -c functions.c gcc -shared -o libfunctions.so functions.o
應用ctypes, 經由過程加載”libfunctions.so”這個同享庫,就像我們前邊對尺度C庫所作的那樣,便可以應用這個庫了。這裡我們將要比擬Python完成和C完成。如今我們開端盤算斐波那契數列:
# functions.py
from ctypes import *
import time
libfunctions = cdll.LoadLibrary("./libfunctions.so")
def fibRec(n):
if n < 2:
return n
else:
return fibRec(n-1) + fibRec(n-2)
start = time.time()
fibRec(32)
finish = time.time()
print("Python: " + str(finish - start))
# C Fibonacci
start = time.time()
x = libfunctions.fibRec(32)
finish = time.time()
print("C: " + str(finish - start))
正如我們預感的那樣,C比Python和PyPy更快。我們也能夠用異樣的方法比擬合並排序。
我們還沒有深挖Cypes庫,所以這些例子並沒有反應python壯大的一面,Cypes庫只要大批的尺度類型限制,好比int型,char數組,float型,字節(bytes)等等。默許情形下,沒有整形數組,但是經由過程與c_int相乘(ctype為int類型)我們可以直接取得如許的數組。這也是代碼第7行所要出現的。我們創立了一個c_int數組,有關我們數字的數組並分化打包到c_int數組中
重要的是c說話不克不及如許做,並且你也不想。我們用指針來修正函數體。為了經由過程我們的c_numbers的數列,我們必需經由過程援用傳遞merge_sort功效。運轉merge_sort後,我們應用c_numbers數組停止排序,我曾經把上面的代碼加到我的functions.py文件中了。
#Python Merge Sort
from random import shuffle, sample
#Generate 9999 random numbers between 0 and 100000
numbers = sample(range(100000), 9999)
shuffle(numbers)
c_numbers = (c_int * len(numbers))(*numbers)
from heapq import merge
def merge_sort(m):
if len(m) <= 1:
return m
middle = len(m) // 2
left = m[:middle]
right = m[middle:]
left = merge_sort(left)
right = merge_sort(right)
return list(merge(left, right))
start = time.time()
numbers = merge_sort(numbers)
finish = time.time()
print("Python: " + str(finish - start))
#C Merge Sort
start = time.time()
libfunctions.merge_sort(byref(c_numbers), len(numbers))
finish = time.time()
print("C: " + str(finish - start))
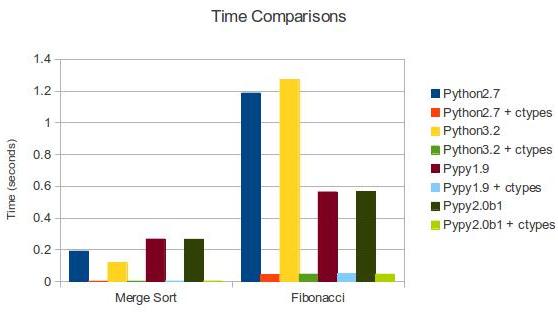
Python: 0.190635919571 #Python 2.7
Python: 0.11785483360290527 #Python 3.2
Python: 0.266992092133 #PyPy 1.9
Python: 0.265724897385 #PyPy 2.0b1
C: 0.00201296806335 #Python 2.7 + ctypes
C: 0.0019741058349609375 #Python 3.2 + ctypes
C: 0.0029308795929 #PyPy 1.9 + ctypes
C: 0.00287103652954 #PyPy 2.0b1 + ctypes
這兒經由過程表格和圖標來比擬分歧的成果。
.