Oracle數據庫機Exadata自推出以後,因為在減小帶寬占用,快速檢索等方面的優勢而備受業界關注。但是對於具體的技術細節,很多數據庫運維人員並不是很了解。
本文轉載自支付寶架構師馮大輝的博客
原文鏈接:http://www.dbanotes.Net/database/Oracle_exadata.Html
自從 Oracle 和HP 推出Exadata 之後,我就很關注這個產品,之前也寫了一篇Oracle Database Machine介紹它。去年,Oracle和SUN合並後,推出了Oracle Exadata V2,相比較上一代產品有幾個變化:第一,使用SUN的硬件;第二,宣稱支持OLTP應用;第三,Oracle 11g R2 提供了更多的新特性。Exadata Smart Flash Cache
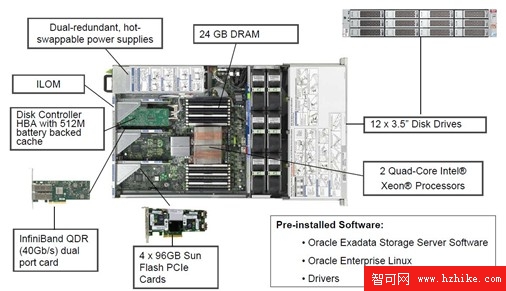
Exadata V2整體架構並沒有太多改變,換用了SUN的硬件,除了采用Intel最新的Nehalem CPU 以外,每台Storage Cell 更是配置了384GB 的Flash,這也是為什麼V2 可以支持OLTP 應用的關鍵。
Flash Cache 完全是自動管理,Oracle會根據數據的訪問情況,決定哪些數據放在 Flash Cache中。所有的數據都是先被寫到普通磁盤上,再根據訪問情況讀入Flash Cache的,所以如果 Flash Card 發生故障,數據不會丟失。當然,Oracle提供了方式,可以讓用戶手動將表或者索引Pin 在 Flash Cache 中。
在自動管理的方式之外,Oracle還允許用戶人工創建flash disks,和普通磁盤一樣,這些Flash Disks通過ASM輸出給數據庫使用,用戶可以把一些訪問非常頻繁的數據文件放在上面。這些 Flash Disks 不僅僅是Cache了,所以 ASM 會在Cell和Cell之間做鏡像。如果某塊卡發生故障,那麼整個Storage Cell上的Flash Disks會offline,保證數據不會丟失。
Smart Scan
Smart Scan是 Exadata最重要的一個功能,它的作用就是把SQL 放在每個Cell 上去運行,然後每個Cell只返回符合條件的數據給數據庫,這樣就極大的降低了數據庫服務器的負載和網絡流量,並充分利用了Cell的計算資源和IO資源。
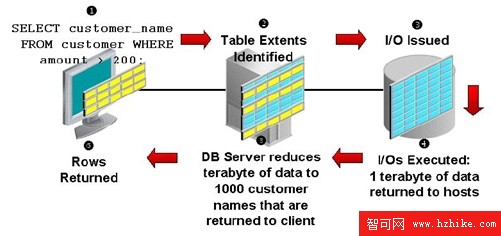
傳統方式:所有的數據都需要返回給數據庫服務器,網絡帶寬要求高,所有的計算在數據庫服務器上完成。
Smart scan:只返回符合條件的數據,減少網絡帶寬,並充分利用了Cell 上的計算和IO資源。
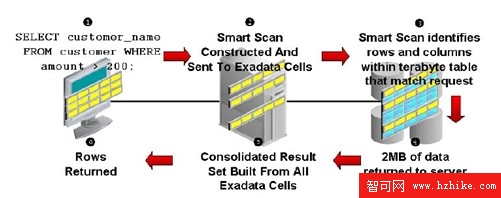
這裡有一點要注意,在使用Smart Scan 時,每個Cell返回給DB Server的是結果集,而不再是傳統的Block, DB Server 完成結果集的處理,並返回給客戶端。
Smart Scan 如何處理 Join ?
這是我一直想要搞清楚的問題。事實上, Smart Scan 只能處理Join filtering,而真正Join的工作必須在DB Server上完成,而且Smart Scan 僅適合於處理 DSS 環境的復雜Join,對於 OLTP 類型的簡單Join,Smart Scan 並不能發揮其優勢。設想下面的查詢:
- select e.ename,d.dname from emp e, dept d where and e.ename='Jacky' and e.deptno=d.deptno;
假設采用nested loops join,Smart Scan 只能完成 e.ename='Jacky' 這個條件的過濾,然後將符合條件的 emp 表的數據返回到 DB server,然後由 DB Server 完成 join 的工作,逐條查詢dept表 (e.deptno=d.deptno) 的數據。所以Smart Scan 並不適合nested loop join(我認為 Smart Scan 只有在適合的條件下才會啟用),只有 DSS 環境的大數據量復雜join才會發揮出優勢。而且 Smart Scan 只能完成filtering的工作,而不能真正完成Join 的工作,這個與Greenplum 數據庫是不同的(有興趣可以看我的文章,Greenplum技術淺析)。設想下面的查詢(emp和dept都是大表):
- select e.ename,d.dname from emp e, dept d where e.deptno=d.deptno;
假設采用Hash Join ,由於沒有任何過濾條件,Smart Scan只能把兩個表的數據全部返回到DB Server 上進行join操作,不過Smart Scan也不是一點用都沒有,至少還可以進行column 的過濾,只返回需要的字段就可以了。
Oracle的文檔中,曾經提到對於一個大表和小表join時,Smart Scan會采用bloom filter來快速定位(可以看我以前的文章,有趣的bloom filter )。方法是把小表build成為bloom filter,然後在每個storage cell上對大表做scan,利用bloom filter快速定位符合條件的結果,並返回給DB Server 作 join。
Storage Index
存儲索引,顧名思義是在存儲級別建立的索引,簡單的說就是為表中的每一列數據建立一個索引,每個index entry記錄一段數據區間的最大值,最小值以及它們的物理位置,文檔上說1MB數據對應一條index entry,見下圖:

如果我們查詢B<2,或者B>8的數據,根據存儲索引,我們就可以跳過這些不在min和max之間的數據塊,極大的提高了掃描的速度,這就是存儲索引的意義。
Hybrid Columnar Compress
首先我們要搞清楚,什麼是行壓縮,什麼叫列壓縮。我們熟悉的數據庫,如Oracle、MySQL等都是基於行的數據庫,就是行的不同字段物理上存放在一起,還有一種是基於列的數據庫,就是每個字段的不同行物理上存放在一起。他們的優缺點同樣突出:
基於行的數據庫,訪問一行非常方便,但是由於同一列的數據是分開存放的,如果要針對某一列進行查詢時,幾乎要掃描整個表才能得到結果。基於行數據庫的壓縮,稱為行壓縮。
基於列的數據庫,因為同一列的數據物理上放在一起,所以訪問一列非常方便,也就是說如果針對某一列進行查詢時,不需要掃描整個表,只需要掃描這一列的數據就可以了,但是訪問一行的全部字段非常不方便(又是廢話)。基於列數據庫的壓縮,稱為列壓縮。
Oracle 通常說的 compress 功能(包括11g R2的Advanced compress),都是行壓縮,因為Oracle是個基於行的數據庫。大概的方法就是在block頭部存放一個symbol table,然後將相同的值放在那裡,每行上相同的數據指向symbol table,以此來達到壓縮的目的。行壓縮的效果通常不好,因為我們知道行與行之間,其實相同的數據並不多。但是列壓縮則不同,因為相同列的數據類型相同,很容易達到很好的壓縮效果。
行壓縮和列壓縮都有其優缺點,而Oracle的混合列壓縮技術,實際上是融合了列壓縮的高壓縮比和行數據庫的訪問特性,將兩者的優點結合起來。Oracle提出了 CU 的概念(compress unit),在一個 CU 內,是一個基於列的存儲方式,采用列壓縮,但是一個 CU 內保存了行的所有字段信息,所以在CU與CU之間,Oracle還是一個基於行的數據庫,訪問某一行,總是只在一個 CU 內(一個CU總是在一個block內)。

所以說混合列壓縮,結合了列壓縮和行訪問的特點,即可以提供非常高的壓縮率,又很好的保證了基於行類型的訪問。
Exadata的另一個重要功能是IO resource management,如果我們在一個Exadata上部署了很多個數據庫,可以用它來管理IO資源,這裡就不作闡述了。
目前,我還沒有了解到在國內有Exadata的應用,而且資料也是比較少的。希望有機會可以真實的測試一下它的性能,我不懷疑他在 DSS 環境下的表現,但是對於OLTP類型的應用,是否真的象Oracle說的那麼強勁,還有待於驗證。