Oracle9i數據庫的Ultra Search組件能為你的網站提供搜索引擎功能,而且,即使沒有軟件開發經驗的電腦愛好者也可以用不到一天的時間建成自己的搜索引擎。下面就把我制作搜索引擎的全過程展示給大家,下文中所有圖片都來自我的搜索引擎實例。
Ultra Search是Oracle公司數據庫服務器9i版本的功能組件,是數據庫產品的附加功能,它有與其它搜索引擎類似的技術構架,又有自己獨到的功能特性。
Ultra Search提供對於四種數據源的基於Web的搜索應用。
1、Web源。
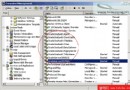
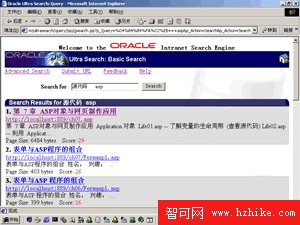
圖1為Ultra Search搜索Web站點的情形。
2、文件源。
文件源是指Ultra Search數據庫計算機可以訪問的文檔集,文件類型為包括Word文件在內的150多種常見格式的文件,也包括圖形圖象文件和視頻剪輯。文檔集位於本地或遠程主機中,這些文檔通過文件協議進行索引,可以根據需要創建任意多不同類型的文件源。Html和純文本是始終要處理的默認文檔類型。圖2為Ultra Search對文件服務器搜索的結果,如圖所示,已經找到一個類型為"file"的PowerPoint文件。文件源通過file://協議索引,Ultra Search使用Oracle Text過濾器從文檔吸取文本和元數據,並自動識別文檔類型。如:Microsoft Office Suite 95/97/2000、Spreadsheet documents(如Microsoft Excel、Lotus 1-2-3)、Word 文件(如Microsoft Word 和 Corel Word Perfect)、Acrobat PDF文件、圖形表現文件(如Microsoft PowerPoint、Lotus Freehand)等。
3、電子郵件源
電子郵件源代表發送到特定郵件地址的所有郵件,可以將Ultra Search配置為從IMAP服務器搜索電子郵件,這個功能對於搜索發送到郵件列表的郵件特別有用。
4、表源
表源是其內容來源於數據庫表的數據源,可創建任意多個新表源,表可來源於多個數據庫鏈接,可以是Oracle數據庫或通過ODBC連接的非Oracle數據庫,可以實現針對表中列的高級搜索。
Ultra Search是一個全面基於Oracle Text的應用程序,它為Oracle Text用戶提供界面友好的Web形式的搜索能力而不需要任何深層的SQL編程,而大量深層技術已被嵌入到轉化和調整Web頁面查詢到底層的基於SQL的Oracle Text查詢的過程中。Ultra Search使用對Oracle Text用戶來說同樣有效的公共接口建立,但增加了相當可觀的專門技術在聚集信息的索引、轉換查詢上,因此有更高質量的查詢性能和可擴展的最優化操作。因為Oracle Text與Oracle數據庫高度集成,所以實現了Ultra Search自由與動態數據交互。
Ultra Search的組成
Ultra Search由3個組件組成:
1、服務器組件
服務器組件是Oracle9i數據庫服務器中的一個組件,它包括:Ultra Search資料庫(Ultra Search數據字典、PL/SQL包、Crawler Java類、Ultra Search產品庫)、Oracle Text和遠程Crawler。
2、Crawler
"Crawler"英文本意是爬行動物,而在搜索引擎中它象蜘蛛一樣爬行在Internet這張網上,爬行過程就是收集信息並建立索引的過程。
3、中間層組件
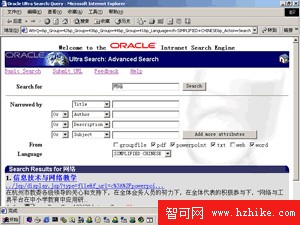
中間層組件是Oracle9i數據庫服務器的一部分並隨著客戶端的安裝被安裝在相同的目錄下(可單獨定制安裝),它包括:管理工具、Java查詢應用程序接口、Java電子郵件應用程序接口和JSP查詢應用程序。管理工具是JSP頁面的Web應用程序,你可以使用它配置和規劃數據庫實例、數據源、Crawler,管理用戶和查詢組。Java應用程序接口使用JDBC連接池實現可伸縮性,Java電子郵件應用程序接口用於訪問和顯示已歸檔的電子郵件。用戶可基於這些接口開發自己的查詢應用程序。Ultra Search已經提供一個功能很強的查詢應用程序,見圖1基礎搜索和圖2高級搜索,它們基於JSP頁面並能工作於任何符合JSP1.0規范的Web服務器引擎。
本文只介紹Ultra Search對Web源和文件源的搜索實現過程。
系統環境為:
● 操作系統:Windows 2000 Advance Server,IIS5.0;
● 數據庫:Oracle9.0.1企業版;
● 運行方式:數據庫服務器、客戶端管理工具和Oracle HTTP Server都運行在同一台主機上。
Oracle9i數據庫企業版可從Oracle網站(www.Oracle.com免費下載,它已經包含了建設Ultra Search搜索引擎所需要的全部軟件組件,另外還需大內存計算機來運行數據庫。
如果你的計算機已經安裝Oracle9i數據庫企業版,則需要設置初始化參數:
不能設置數據庫為多線程服務器(MTS),因為它不支持Oracle Text記錄。
安裝過程很簡單,大多數設置已由系統自動實現。如果你的系統沒有安裝Oracle數據庫,你必須使用Oracle通用安裝器定制安裝數據庫,選擇Ultra Search功能和數據庫客戶端管理工具;反之,需要通過數據庫配置助手(DBCA)在已經運行的數據庫上追加安裝Ultra Search功能,並檢查客戶端管理工具是否完全安裝。安裝數據庫時選擇使用數據庫中的Oracle HTTP Server作為JSP Web服務器引擎。下文約定:ORACLE_HOME代表Oracle數據庫主目錄,WEB_Oracle_HOME代表中間層組件的安裝目錄,本例中二者相同。
硬件要求:
1、內存要求:大於等於256MB。
2、硬盤空間要求:
(1)至少1.4GB硬盤空間安裝Oracle9i服務器;
(2)相當於物理內存大小的臨時表空間;
(3)Ultra Search實例的用戶表空間需求。要明確建立一個數據庫用戶作為Ultra Search的實例用戶,所有搜索引擎需要的表和索引等數據庫對象都存儲在這個用戶模式下,一般要建立與你將要索引的數據源相同大小的表空間作為Ultra Search實例用戶的缺省表空間。
軟件要求:
Oracle9.0.1企業版。當然附加使用Oracle9i Application Server(9iAS,也可免費下載)可得到更多應用,本例中沒采用。
Oracle9i安裝過程中,所有Ultra Search文件都被安裝到Oracle_HOME/ultrasearch目錄下,數據庫用戶wksys/wksys被建立,之後需要明確設定下列環境變量(在同一台主機上安裝有多個Oracle產品,即有多個Oracle主目錄時尤為重要):ORACLE_HOME、ORACLE_SID、PATH(如$Oracle_HOME/bin:$PATH)、TNS_ADMIN(如network/admin)。
Ultra Search中間層組件的安裝及步驟:
本例中中間層組件已隨Oracle客戶端管理工具被安裝,你可以安裝中間層組件到多台Web服務器主機上來平衡大量終端用戶的查詢請求。
1、安裝中間層組件,有三個選擇:
選項1:安裝Ultra Search中間層組件到一個已經安裝Oracle HTTP Server的Oracle數據庫主目錄,那麼安裝過程可以自動配置中間層組件。為了得到Oracle HTTP Server,在Oracle通用安裝器菜單選擇"Server"選項,接下來執行定制安裝並選擇Oracle HTTP Server。
選項2:安裝中間層組件到一個不含Oracle HTTP Server的主機,這個選項允許你使用不同的Web服務器。
選項3:使用9iAS作為Web服務器。
安裝時,啟動Oracle通用安裝器,選擇Oracle9i ClIEnt安裝,選擇定制選項中的管理工具選項,將安裝目錄記為$WEB_Oracle_HOME。
2、配置Web服務器
如果選擇選項1,這一步自動進行;如選擇選項2,則執行以下幾步配置Web服務器。本例選擇選項1,但請按以下幾步檢查:
①把安裝中間層組件時鍵入的安裝目錄記為$WEB_ORACLE_HOME(本例中同$Oracle_HOME)。
②Oracle通用安裝器自動建立Web服務器別名。安裝器編輯文件$WEB_Oracle_HOME/apache/JSp/conf/oJSP.conf,依次加入下面三行:
這些行依次為Ultra Search根文檔、管理工具和查詢應用程序建立Web服務器別名。
③Oracle通用安裝器自動增加產品庫、Java查詢應用程序接口庫和JGL對象庫到Java Servlet引擎。安裝器編輯文件$WEB_Oracle_HOME/apache/Jserv/conf/JServ.propertIEs來包含那些庫文件,以下幾行將被加入到該文件中:
④通用安裝器自動增加目錄包含database.propertIEs文件到Servlet引擎庫中。安裝器編輯文件$WEB_Oracle_HOME/apache/Jserv/conf/JServ.propertIEs,下面一行被加入到該文件中:
3、編輯配置文件database.propertIEs,指定JSP應用程序將要連接的數據庫的信息。配置文件位於$WEB_Oracle_HOME/ultrasearch/JSP/admin/config/,用來指定主機名、端口號和SID。為作到這一點,編輯該文件中以"connection.url"開頭的行:
在
4、測試Ultra Search管理工具
①首先重新啟動Oracle HTTP server。缺省服務器端口號為80,也可在文件$WEB_Oracle_HOME/apache/
apache/conf/httpd.conf中改變端口號。
②浏覽
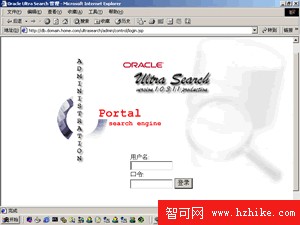
③用帳號wksys/wksys登錄Ultra Search管理工具(第一次訪問管理工具時速度可能會很慢,因為要編譯JSP文件,接下來的訪問會很快)。
④如果成功登錄管理工具,那麼你已經完成了中間層組件的配置,如果出現登錄問題,請按順序檢查下面幾項:確保Web服務已經運行;
確保文件database.propertIEs包含Oracle9i服務器實例的正確描述;
確保Oracle9i服務器實例已經運行;
確保Oracle9i服務器實例監聽程序運行;
確保Oracle9i服務器實例正確安裝Ultra Search服務器組件。
安裝過程中,有些文件是系統自動設置的,如果你使用Windows操作系統,還需要把文件路徑中的"/"改為"\",因為系統自動以unix路徑形式配置這些文件。
登錄管理工具後,你需要設置數據庫實例、Crawler、Web訪問、屬性、數據源、Crawler時間進度表、查詢數據組和用戶。
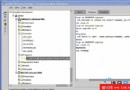
1、首先設置Ultra Search使用的數據庫實例,在這個數據庫實例中存儲所有數據源的索引數據。如圖4所示。
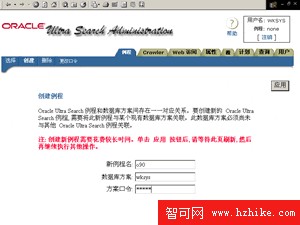
2、然後設置Crawler,如圖5所示。
需要設置:處理器數量、自動語言檢測、默認語言(該設置很重要,因為語言直接決定了文檔的索引方式)、搜索深度(某個Web文檔可能包含與其他Web文檔的鏈接,該設置可指定Crawler將跟蹤的最大嵌套鏈接數,即鏈接層數)、默認字符集、臨時目錄位置及大小、數據庫鏈接字符串。
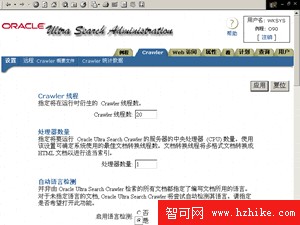
● 處理器數量:指定將要運行 Oracle Ultra Search Crawler 的服務器的中央處理器 (CPU) 數量。使用該設置可確定系統使用的最佳文檔轉換線程數。文檔轉換線程將多格式文檔轉換成 Html 文檔以進行適當索引。本例中設置為1。
● 自動語言檢測:並非由 Oracle Ultra Search Crawler 檢索的所有文檔都指定了編寫文檔所用的語言。對於未指定語言的文檔, Oracle Ultra Search Crawler 將嘗試自動檢測其語言。請指定是否希望打開此功能。本例中設置為"是"。
● 默認語言:如果禁用自動語言檢測或者當某個 Web 文檔未指定語言時, Crawler 將認為編寫該 Web 頁的語言是下面指定的默認語言。該設置很重要,因為語言直接決定了文檔的索引方式。本例中設置為"簡體中文"。
● 搜索深度:某個Web文檔可能包含與其他Web文檔的鏈接,從而可能包含更多的鏈接。使用該設置可指定 Crawler 將跟蹤的最大嵌套鏈接數。本例中設置為3。
● 默認字符集:如果由Crawler處理的某個 Html 文檔沒有指定的字符集,該 Crawler 將認為其使用的是下面的默認字符集。本例中設置為"GB2312-80簡體中文"
● 臨時目錄位置及大小:臨時目錄用於在索引文檔過程中進行間斷存儲。Oracle Ultra Search Crawler 必須能夠訪問臨時目錄。請指定臨時目錄的絕對路徑。其大小是 Crawler在索引過程中使用的最大臨時空間。指定硬盤中的一個目錄即可。
● 數據庫連接字符串:數據庫連接字符串是 Crawler 需要連接到數據庫時使用的標准 JDBC 連接字符串。連接字符串的格式應為: [hostname]:[port]:[SID],本文中是:localhost:1521:o90
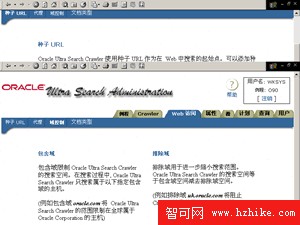
3、設置Web訪問,如圖6所示。可以指定多個搜索空間,並為搜索空間設定包含域和排除域。搜索過程中,Ultra Search只搜索屬於包含域的主機(例如包含域為oracle.com,則搜索范圍限制在全球屬於Oracle公司的主機),排除域用於進一步縮小搜索范圍,搜索空間等於包含域減去排除域(例如排除域為uk.oracle.com將阻止搜索英國的Oracle主機)。
Oracle Ultra Search Crawler 使用種子 URL 作為在 Web 中搜索的起始點。可以添加種子 URL 或從種子 URL 列表中將其刪除。Oracle Ultra Search 當前支持使用 HTTP 協議的種子 URL。
注: 如果種子 URL 列表中沒有條目, Crawler 不會執行搜索操作。
可以添加一個或多個種子 URL。
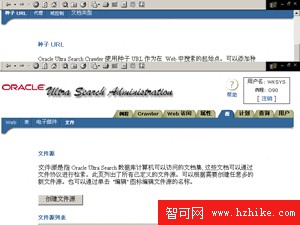
4、指定搜索源。Oracle Ultra Search的強大功能都體現在這個頁面中,可以指定Web頁面源、文件源、電子郵件源和數據庫表源。圖7所示為增加文件源到搜索數據源中,可同時指定多個不同種類的數據源。其它數據源請讀者自行設定。
5、設定查詢計劃。如圖8所示。
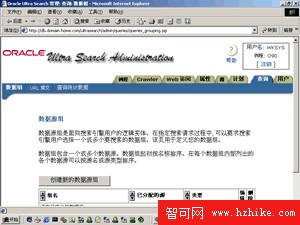
6、設置查詢數據組。如圖9所示。設置URL提交方式,如圖10所示。
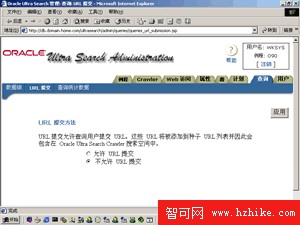
URL提交是指是否允許用戶使用搜索引擎時提交自己網站的網址。如果浏覽過大型搜索引擎網站,有時會發現它允許你把自己網站的網址提交給它,也就是當其他用戶浏覽這個搜索引擎網站時,他會搜索到你的網站的網頁。這裡的設置影響用戶在搜索查詢頁面(如圖1和圖2所示)點擊鏈接"Submit URL"後的效果。你可以讓自己的搜索引擎允許其他用戶提交URL,你也就成為門戶搜索網站了!不過,你的數據庫體積可能會爆炸性增長,因為,你的數據庫裡已經保存了數據源的索引,一般情況來說,這個索引的大小與數據源的大小相當,因此,在為自己的搜索引擎指定數據源時,首先要考慮自己數據庫的大小。
查詢應用程序位於$WEB_Oracle_HOME/ultrasearch/sample/JSp目錄下,首先在所有JSP文件中找到下面兩行:
把它們改為:
否則網頁會顯示登錄錯誤。
另外,在所有JSP文件中找到字符串"charset=iso-8859-1",更改為"charset=gb2312",否則網頁不能正確顯示和查詢中文字詞。
這裡的用戶名和密碼為數據庫安裝Ultra Search組件時自動建立。
然後浏覽
特性:
較高的搜索結果相關度;
完全和數據庫服務器、SQL查詢語言集成,更好地與動態數據交互作用;
帶有業界優秀的語言學技術;
帶有類似概念搜索、主題分析和XML搜索能力的高級特性;
索引所有流行的150多種文件格式;
以Web形式搜索文件服務器;
完美的全球化支持,包括支持中文、日文、朝鮮語和統一字符編碼標准。
Ultra Search的使用體會:
易於安裝、易於管理,可以在不到一天的時間安裝調試完成,普通用戶最好能得到數據庫管理員(DBA)的幫助;
它是一項前台技術,不要求使用者有任何應用程序開發的能力;
高性能、可擴展,提供二次開發平台,你可以輕松改動JSP程序,比如去掉圖1和圖2中的Oracle產品標志,去掉搜索結果相關度分值等。
局限:
搜索Web源的網址中不能含注冊字符串;
只能在一個數據庫中建立Ultra Search數據庫實例,除非你編輯文件database.propertIEs,每次切換到不同的數據庫,因為索引數據量會越來越大;
不容易調整Ultra Search數據庫對象的存儲參數;
Ultra Search暫時沒有在索引數據中存儲數據源快照(副本)的功能。