在數據庫的邏輯結構中,表空間將不同類型的數據分別組織在一起,如系統數據、用戶數據、臨時數據、回滾數據等。
在同一個表空間中,數據以數據庫對象為單位組織在一起,一般情況下一個數據庫對象對應一個段,一個表空間中包含多個段。
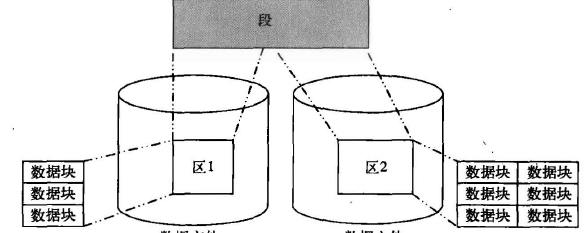
在段中存儲數據庫對象中的數據,數據所占用的存儲空間以區為單位進行分配和回收。
一個數據庫對象占用若干個區,所以段是由若干個區組成的。
當為數據庫對象分配存儲空間時,一次分配一個或多個區。
區是分配和回收存儲空間的基本單位,一個區是由若干個連續的數據塊組成的。
數據塊是邏輯結構中的最小存儲單位,是Oracle讀寫數據的基本單位。
當用戶訪問數據時,服務器進程首先將數據從數據塊讀到數據庫高速緩存中,並存儲在與數據塊大小相同的緩沖區中,然後在緩沖區中對數據進行讀寫。
數據庫中的數據在物理上是存儲在磁盤上的,需要占用一定的操作系統塊。
一個數據塊是由若干個操作系統塊組成的,因此,數據塊的大小是操作系統塊的整數倍。
數據庫服務器對數據塊的讀寫最終將轉化為對多個操作系統塊的讀寫。
段的管理
在表空間中,一個段一般代表一個數據庫對象,對象的所有數據都存儲在對應的段中。
一般情況下段不需要用戶自己創建,在創建數據庫對象將自動產生段。
為段所分配的空間就位於表空間的數據文件中,這些存儲空間由若干個區組成。
段、區和數據塊之間的關系如圖所示。
段的類型
Oracle 11g支持10余種類型的段。
通過查詢數據字典dba_segments ,可以得到當前數據庫中已經存在的段類型。
下面是有關數據字典dba_segments的相關信息:
DBA_SEGMENTS describes the storage allocated for all segments in the database.
Related View
USER_SEGMENTS describes the storage allocated for the segments owned by the current user's objects. This view does not display the OWNER, HEADER_FILE, HEADER_BLOCK, or RELATIVE_FNO columns.
OWNER
VARCHAR2(128)
Username of the segment owner
SEGMENT_NAME
VARCHAR2(128)
Name, if any, of the segment
PARTITION_NAME
VARCHAR2(128)
Object Partition Name (Set to NULL for nonpartitioned objects)
SEGMENT_TYPE
VARCHAR2(18)
Type of segment:
NESTED TABLE
TABLE
TABLE PARTITION
CLUSTER
LOBINDEX
INDEX
INDEX PARTITION
LOBSEGMENT
TABLE SUBPARTITION
INDEX SUBPARTITION
LOB PARTITION
LOB SUBPARTITION
ROLLBACK
TYPE2 UNDO
DEFERRED ROLLBACK
TEMPORARY
CACHE
SPACE HEADER
UNDEFINED
SEGMENT_SUBTYPE
VARCHAR2(10)
Subtype of LOB segment: SECUREFILE, ASSM, MSSM, andNULL
TABLESPACE_NAME
VARCHAR2(30)
Name of the tablespace containing the segment
HEADER_FILE
NUMBER
ID of the file containing the segment header
HEADER_BLOCK
NUMBER
ID of the block containing the segment header
BYTES
NUMBER
Size, in bytes, of the segment
BLOCKS
NUMBER
Size, in Oracle blocks, of the segment
EXTENTS
NUMBER
Number of extents allocated to the segment
INITIAL_EXTENT
NUMBER
Size in bytes requested for the initial extent of the segment at create time. (Oracle rounds the extent size to multiples of 5 blocks if the requested size is greater than 5 blocks.)
NEXT_EXTENT
NUMBER
Size in bytes of the next extent to be allocated to the segment
MIN_EXTENTS
NUMBER
Minimum number of extents allowed in the segment
MAX_EXTENTS
NUMBER
Maximum number of extents allowed in the segment
MAX_SIZE
NUMBER
Maximum number of blocks allowed in the segment
RETENTION
VARCHAR2(7)
Retention option for SECUREFILE segment
MINRETENTION
NUMBER
Minimum retention duration for SECUREFILE segment
PCT_INCREASE
NUMBER
Percent by which to increase the size of the next extent to be allocated
FREELISTS
NUMBER
Number of process freelists allocated to this segment
FREELIST_GROUPS
NUMBER
Number of freelist groups allocated to this segment
RELATIVE_FNO
NUMBER
Relative file number of the segment header
BUFFER_POOL
VARCHAR2(7)
Buffer pool to be used for segment blocks:
DEFAULT
KEEP
RECYCLE
FLASH_CACHE
VARCHAR2(7)
Database Smart Flash Cache hint to be used for segment blocks:
DEFAULT
KEEP
NONE
Solaris and Oracle Linux functionality only.
CELL_FLASH_CACHE
VARCHAR2(7)
Cell flash cache hint to be used for segment blocks:
DEFAULT
KEEP
NONE
See Also: Oracle Exadata Storage Server Software documentation for more information
INMEMORY
VARCHAR2(8)
Indicates whether the In-Memory Column Store (IM column store) is enabled (ENABLED) or disabled (DISABLED) for this segment
INMEMORY_PRIORITY1
VARCHAR2(8)
Indicates the priority for In-Memory Column Store (IM column store) population:
LOW
MEDIUM
HIGH
CRITICAL
NONE
NULL
INMEMORY_DISTRIBUTE1
VARCHAR2(15)
Indicates how the IM column store is distributed in an Oracle Real Application Clusters (Oracle RAC) environment:
AUTO
BY ROWID RANGE
BY PARTITION
BY SUBPARTITION
INMEMORY_DUPLICATE1
VARCHAR2(13)
Indicates the duplicate setting for the IM column store in an Oracle RAC environment:
NO DUPLICATE
DUPLICATE
DUPLICATE ALL
INMEMORY_COMPRESSION1
VARCHAR2(17)
Indicates the compression level for the IM column store:
NO MEMCOMPRESS
FOR DML
FOR QUERY [ LOW | HIGH ]
FOR CAPACITY [ LOW | HIGH ]
NULL
例如:
SELECT DISTINCT segment_type FROM dba_segments;
1.表段(TABLE)
表段是用來存儲表中的數據的,這是最常見的一種段。
在創建表時將自動創建一個同名的段,表中的數據就存儲在數據段中。
2.索引段(INDEX)
索引是依賴於表的數據庫對象,它的功能是加快表的查詢速度。
當用戶執行CREATEINDEX命令創建索引時,在數據庫中將產生一個索引段。
當用戶在表上定義主鍵約束和唯一性約束時也將自動產生索引段。
索引段的名稱與索引相同,索引中的數據就存儲在索引段中。
3.臨時段
當用戶執行排序等操作時,將產生大量的臨時數據。
臨時數據將首先存儲在PGA的排序區中,如果排序區的大小不足以存放這些臨時數據時,將使用臨時段。
一般情況下,用戶在執行以下操作時可能用到臨時段:
SELECT ••• FROM ••• ORDER BY •••
SELECT ••• FROM ••• GROUP BY •••
SELECT DISTINCT ••• FROM •••
SELECT ••• UNION
CREATE INDEX •••
ANALYZE
臨時段一般位於專門的臨時表空間中。
如果沒有專門的臨時表空間,數據庫服務器將把SYSTEM表空間作為用戶的臨時表空間。
臨時段不是一種永久性的段,而是隨著用戶的排序操作的進行而動態產生和消失的。
當排序操作開始時,在臨時表空間中將產生一個臨時段,在排序結束時臨時段將被刪除。
如果在SYSTEM表空間中存儲這些臨時數據,將導致大量的存儲碎片的產生,從而大大降低數據庫服務器的性能。
因此, Oracle建議創建專門的臨時表空間。
4.回滾段(ROLLBACK)
回滾段是用來存儲回滾數據的。
如果使用自動方式管理回滾數據,需要在數據庫中創建一個UNDO表空間,隨著用戶事務的執行,在UNDO表空間中將自動產生回滾段。
5.分區表段(TABLE PARTITION)
在數據庫中可以將一個大表分成幾個分區( PARTITION ),每個分區對應一個段。
這些分區表段可以存儲在同一個表空間中,也可以存儲在不同的表空間中。
分區表主要應用於數據倉庫,它的主要作用是縮小數據庫查詢的范圍,加快查詢的速度。
例如,某公司的客戶表中存儲了上萬條客戶信息,假設將這個表分成13個區,將客戶信息按照其姓名的首字母不同而分別存儲在不同的分區中。
姓名以“A”和“B ”開始的客戶存儲在第一個分區中,以“C”和“D”開始的存儲在第二個區中,依此類推。
這樣一個表中的數據就被分開存儲在13 個分區中,如果要查詢一個客戶的信息,只需要在它所在的分區中查詢即可,查詢的范圍將大約縮小為原來的1/13 。
6.分區索引段(INDEX PARTITION)
與表的分區類似,索引也可以分區。
將一個索引劃分為幾個分區,每個分區對應一個段,索引的數據將分別存儲在這些段中。
對索引進行分區的目的是為了加快查詢索引的速度。
需要注意的是,只有對表進行分區後,才能在表上創建分區索引。
7.LOB段
如果在表中定義了CLOB 或BLOB 類型的列,在表中就可以存儲大文本或二進制數據,如文檔、圖像、聲音等。
LOB數據並不是直接存儲在表段中,而是單獨存放在一個LOB 段中,在表中僅僅存放LOB 段的指針。
8.LOB索引段
如果在表上定義了LOB 類型的列,在數據庫中將自動創建LOB 段,同時自動創建LOB索引段。
LOB索引段的作用是加快LOB 列的查詢速度。
9.簇段(CLUSTER)
簇是一種數據庫對象,它的作用是將邏輯上相關的數據組織在一起,簇中的數據來自一個或多個表。
每個簇對應一個簇段,在創建簇時將自動創建簇段,並且簇段的名稱與簇完全相同。
使用簇可以加快多表查詢的速度。
10.索引組織表(INDEX ORGANIZED TABLE)段
如果經常要根據一個表的主鍵查詢數據,可以將主鍵列上的索引與表放在一個段中,這種表稱為索引組織表,它被存儲在一個表段中,這種表段就是索引組織表段。
索引組織表段的主要作用是加快基於主鍵的查詢速度。
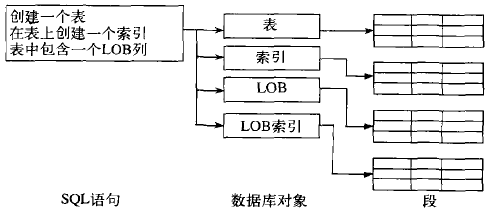
假設在數據庫中創建一個表,在表上創建一個索引,在表中包含一個LOB列,那麼創建表的結果是產生了四個段:表段、索引段、LOB段和LOB索引段。
圖表示這四個段之間的關系。
段空間的管理
一般來說,段不需要用戶專門創建,當用戶創建一個數據庫對象時,在數據庫中將自動產生對應的段。
臨時段和回滾段比較特殊,臨時段位於臨時表空間中,它是隨著用戶的排序等操作的進行而動態創建和消失的。
回滾段位於UNDO表空間中,並且隨著用戶事務的執行而動態產生和消失。
在本地管理表空間中,區的分配策略有自動方式和手工方式兩種。
如果采用自動方式(AUTOALLOCATE ),數據庫服務器將決定區的大小,並自動進行區的分配和回收,區的大小是可變的,默認的區大小為64KB 。
如果采用手工方式,則需要通過UNIFORM 指定區的大小,默認為1MB 。
在創建本地管理表空間時,還可以使用SEGMENT SPACE MANAGEMENT子句指定段空間的管理方式。
如果采用手工方式,則表空間將為每個段維護一個空閒列表( Free List ),它位於數據文件的頭部,在空閒列表中記錄當前數據文件中所有的空閒塊,段利用空閒列表管理塊的分配和回收。
如果選擇自動方式,段將采用位圖的方式管理塊的分配和回收。
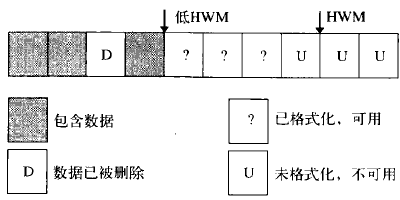
為了對段中數據塊的使用進行控制,在段中設置了一個HWM (High Water Mark )。
HWM可以認為是一個指針,在段剛被創建時, HWM位於段的開始位置。
在HWM之上是沒有被格式化,尚不能寫入數據的數據塊,而在HWM之下的數據塊有以下幾種情況:
·已經包含數據。
·以前曾經包含數據,但後來數據被刪除。
·已經被格式化,且狀態為空閒的。
·尚未被格式化。
為了給用戶數據分配數據塊,在段中還設置了一個低HWM ,位於低HWM之下的數據塊要麼是已經包含數據的,要麼是曾經包含數據,但後來數據被刪除的。
對一個用戶事務而言,可用的數據塊就是那些位於低HWM 和HWM之間的數據塊。
當用戶向段中寫入數據時,服務器進程將在低HWM 和HWM之間查找那些已經被格式化的數據塊,將數據寫入這些數據塊。
如果沒有足夠的數據塊可用,服務器進程將在這個范圍內查找那些尚未被格式化的數據塊,對其進行格式化,然後將數據寫入。
如果這樣的數據塊還不能滿足要求,服務器進程將把HWM 向上移動,為這次事務分配其他尚未格式化的數據塊,然後對其進行格式化,並將數據寫入。
在將數據寫入數據塊之後,服務器進程將把低HWM 向上移動,使其指向第一個可用的數據塊。
數據塊的分配情況如圖所示。
區的管理
區是Oracle 為數據庫對象分配存儲空間的基本單位。
當用戶創建表、索引、簇等數據庫對象時,數據庫服務器將為該對象對應的段分配若干個區,以存儲該對象的數據。
當段的空間被消耗完時,可以進行擴展,數據庫服務器將為該段分配新的區。
當一個數據庫對象被刪除時,它所占用的區將被釋放,數據庫服務器負責回收這些區,並在適當的時機將這些空閒區分配給其他數據庫對象。
區的分配
在本地管理表空間中,區的大小要麼由數據庫服務器自動指定,要麼由數據庫管理員指定。
當在表空間中創建表、索引等數據庫對象時,數據庫服務器將按照指定的大小為段分配相應數量的區,在默認情況只分配一個初始區,盡管在這個區中還沒有包含數據,但這個區不能分配給其他數據庫對象。
當初始區被寫滿後,數據庫服務器將根據需要為段分配其他的區。
在表空間的每個數據文件的頭部,都有一個位圖,用來控制塊的分配。
當為段分配一個區時,數據庫服務器將在位圖中查找可用的數據塊,將它們分配這個區。
首先我們執行下面的語句來創建本地管理表空間ts4:
CREATE TABLESPACE TS4 DATAFILE 'C:\Users\john\Desktop\tbs\ts4_1.dbf' SIZE 1M
EXTENT MANAGEMENT LOCAL AUTOALLOCATE;
由於采用了自動分配方式( AUTOALLOCATE ),因此在表空間ts4 中所有區的大小默認都是64KB 。
接下來我們在表空間ts4 中創建表tab3:
CREATE TABLE tab3 (col INT) TABLESPACE ts4;
這樣將為段TAB3分配一個區,大小為64KB ,占用8個數據塊(每個數據塊大小為8KB )。
執行下面的查詢語句,將得到為段TAB3 分配得區的信息:
SELECT bytes, blocks, extents FROM dba_segments WHERE segment_name='TAB3';
一個段所占用的區的詳細信息可以通過查詢數據字典DBA_EXTENTS獲得。
下面是有關數據字典DBA_EXTENTS的信息。
DBA_EXTENTS describes the extents comprising(構成) the segments in all tablespaces in the database.
Note that if a data file (or entire tablespace) is offline in a locally managed tablespace, you will not see any extent information. If an object has extents in an online file of the tablespace, you will see extent information about the offline data file. However, if the object is entirely in the offline file, a query of this view will not return any records.
Related View
USER_EXTENTS describes the extents comprising the segments owned by the current user's objects. This view does not display the OWNER,FILE_ID, BLOCK_ID, or RELATIVE_FNO columns.
OWNER
VARCHAR2(128)
Owner of the segment associated with the extent
SEGMENT_NAME
VARCHAR2(128)
Name of the segment associated with the extent
PARTITION_NAME
VARCHAR2(128)
Object Partition Name (Set to NULL for nonpartitioned objects)
SEGMENT_TYPE
VARCHAR2(18)
Type of the segment: INDEX PARTITION, TABLE PARTITION
TABLESPACE_NAME
VARCHAR2(30)
Name of the tablespace containing the extent
EXTENT_ID
NUMBER
Extent number in the segment
FILE_ID
NUMBER
File identifier number of the file containing the extent
BLOCK_ID
NUMBER
Starting block number of the extent
BYTES
NUMBER
Size of the extent in bytes
BLOCKS
NUMBER
Size of the extent in Oracle blocks
RELATIVE_FNO
NUMBER
Relative file number of the first extent block
例如,下面的SELECT語句用於查詢段TAB3所占用的區的ID 、大小、區中所包含數據塊的數目以及第一個數據塊的ID:
SELECT extent_id, bytes/1024 ||'K' KBytes, blocks, block_id FROM dba_extents WHERE segment_name='TAB3';
區的回收
在一般情況下,從段中刪除數據時,數據所占用的空間並沒有被釋放,除非這個數據庫對象被刪除。
在以下幾種情況中,會發生區的回收:
·一個對象被刪除。
.對表進行整理。
·對索引進行重建或合井。
·在表上執行TRUNCATE命令。
·手工執行命令釋放段中HWM以下未使用的空間。
在這裡需要注意的是, TRUNCATE命令的執行結果是將表中的數據刪除,從表面上來看類
似於DELETE ,但是這兩條命令有很大的區別。在執行TRUNCATE命令時,表段中的HWM被
移動到段的開始位置,這就意味著下次寫數據是從段的開始位置進行的,以前的數據所占用的
空間被釋放。而在執行DELETE命令時, HWM井沒有移動,這就意味著數據雖然被刪除了,
但是數據所占用的空間並沒有被釋放。